使用 Apache Flink 和 MinIO 进行流处理
机器学习、深度学习、人工智能和物联网等现代技术趋势,推动了对可靠、可扩展的存储平台的需求,该平台必须足够通用,以满足这些应用程序生成的大量数据流。
在这篇文章中,我们将介绍 Apache Flink,它是当今最流行的流处理引擎之一,并尝试了解其价值,使其被全球各地的企业广泛采用。稍后,我们还将探讨 Minio 如何与 Flink 协同工作,为各种用例构建私有云数据管道。
什么是流处理?
流处理能够分析连续的数据流。在这种方法中,数据被视为一个连续的流,处理引擎会摄取、分析数据,并在很短的时间内(几毫秒到几分钟)返回响应。
响应时间通常基于用例和响应时间的关键程度。例如,您期望来自核反应堆的物联网传感器数据在比用户网站访问数据短得多的时间范围内进行处理。
在某些情况下,与批处理分析相比,流式处理数据分析方法更适合。
- 随着现代技术(物联网、交易日志、应用程序日志、活动日志、访问日志)生成连续的数据流,以类似的连续方式处理这些数据是自然的方法。
- 批处理获取大量数据并一次性处理它们,而流处理则在数据到达时处理它们,从而将处理分散到一段时间内。这使得流处理与批处理相比,可以使用更少的计算资源。
- 有时数据量太大,存储所有数据在经济上并不合理。流处理允许您处理大型“消防水带”式数据,并保留仅有用的部分。
- 流处理允许检测模式、检查结果,并轻松查看来自多个流的数据。这意味着您可以在更短的时间内获得近似的结果。相反,对于批处理,您需要处理多个批次并在这些批次中聚合结果以获得更好的结果,但这需要更长的时间。
流处理用例
正如我们所讨论的,流处理在需要快速(有时是近似)答案的场景中非常有用,同时处理数据。现在让我们看看流处理方法的一些常见的现实世界应用。
异常检测:流式分析可以应用于连续的数据流并实时检测异常。例如,在金融交易数据流中,欺诈交易可以被认为是异常——流处理可以检测这些异常,从而保护银行和客户免受经济损失。
业务流程监控:业务流程涉及特定领域内的多个事件,例如,在电子商务业务中,从CHECK_OUT_FROM_CART到ITEM_RECEIVED_BY_CUSTOMER的所有事件都可以被认为是一个业务流程——一个至关重要的流程。流处理可用于监控此类流程中的异常,例如未在规定时间内完成、交付合作伙伴处理不当的商品等。
基于规则的警报:流处理可用于根据某些规则触发警报。这意味着,一旦满足特定条件,警报就会发送到不同的目标。
在Apache Flink 网站上阅读更多关于流处理用例的信息。
Apache Flink
Apache Flink 是一个分布式处理引擎,用于对数据流进行有状态计算。Flink 擅长处理无界和有界数据集。
Flink 旨在在所有常见集群环境中运行,以内存速度和任何规模执行计算。
虽然 Apache Spark 以提供流处理支持作为其功能之一而闻名,但流处理在 Spark 中是事后才想到的,并且在幕后,Spark 以使用小批次来模拟流处理而闻名。
另一方面,Apache Flink 从一开始就被设计成一个流处理引擎。这意味着 Flink
- 可以更好地管理内存并避免内存使用量偶尔出现峰值。
- 通过允许迭代处理在同一节点上发生而不是让集群独立运行它们来管理更快的速度。
Minio 与 Apache Flink
Apache Flink 在其典型的处理流程中支持三个不同的数据目标——数据源、接收器和检查点目标。虽然数据源和接收器相当明显,但检查点目标用于在处理期间以一定的间隔持久化状态,以防止数据丢失并从节点故障中一致地恢复。
由于 AWS S3 API 支持是 Apache Flink 的一等公民,因此所有三个数据目标都可以配置为与任何与 AWS S3 API 兼容的对象存储一起使用,当然也包括 Minio。
Minio 可以通过四种主要方式与 Flink 配合使用,让我们在下面看看这四种方式。
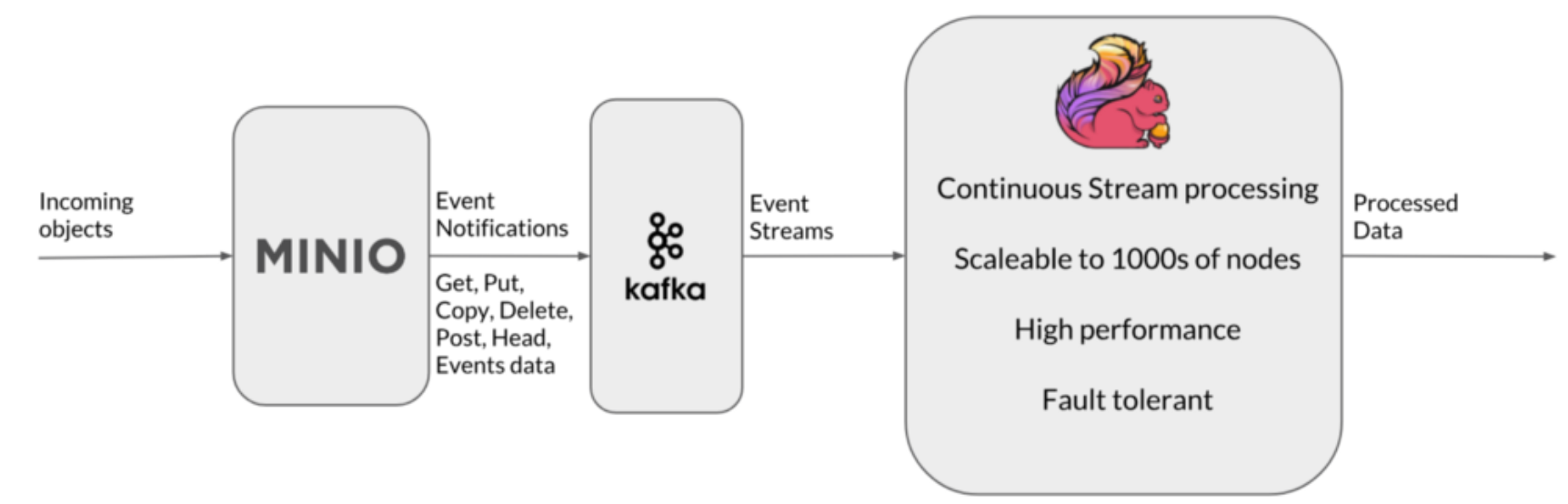
- Minio 事件通知:Minio 的事件日志可以通过 Kafka 作为事件流发送到 Flink。此类事件数据在对象访问日志对于业务了解某些用户行为趋势或数据访问趋势至关重要的场景中非常有用。
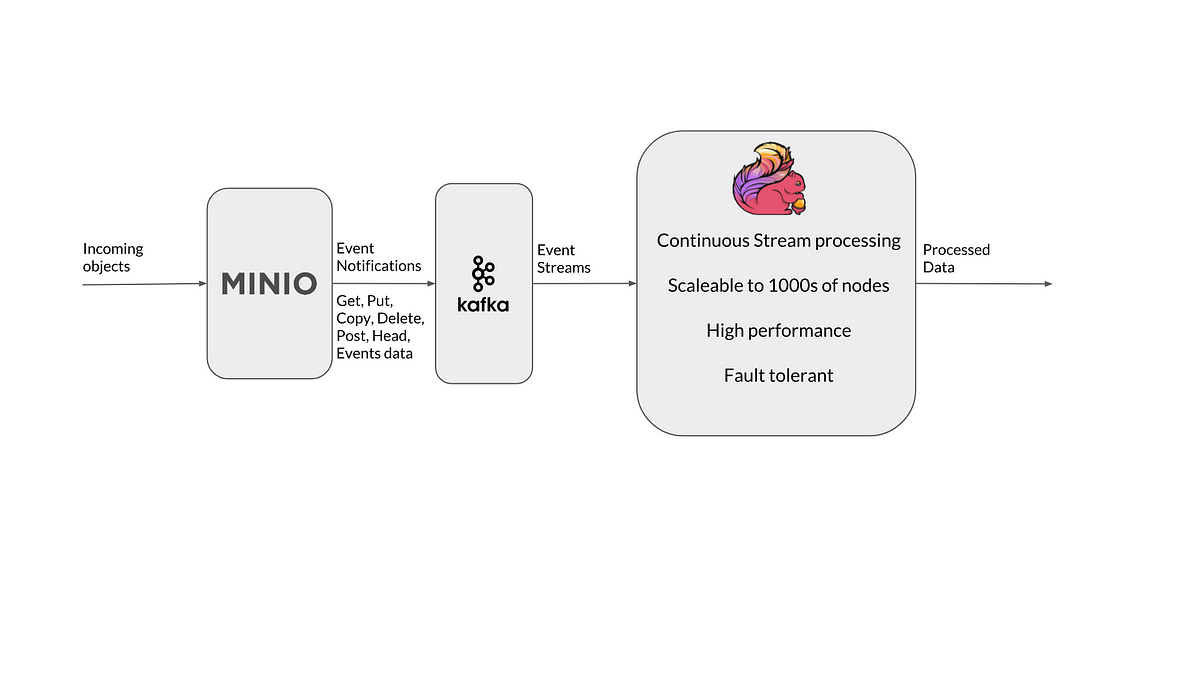
2. Minio 对象数据:Minio S3 SELECT 命令的响应是流式数据,这些数据可以直接馈送到 Flink 以进行进一步分析和处理。
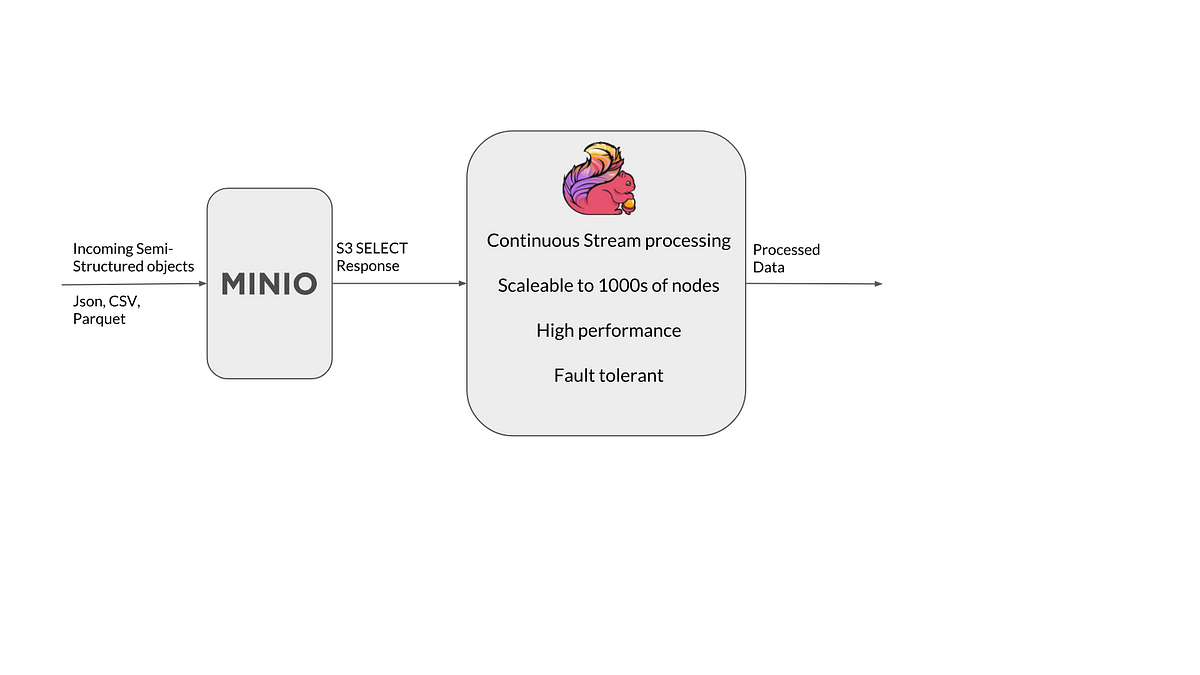
3. 将 Minio 作为 Flink 的检查点:Flink 支持检查点以确保它能够恢复节点故障并从中断的地方继续。可以将 Flink 配置为将这些检查点存储在 Minio 服务器上。
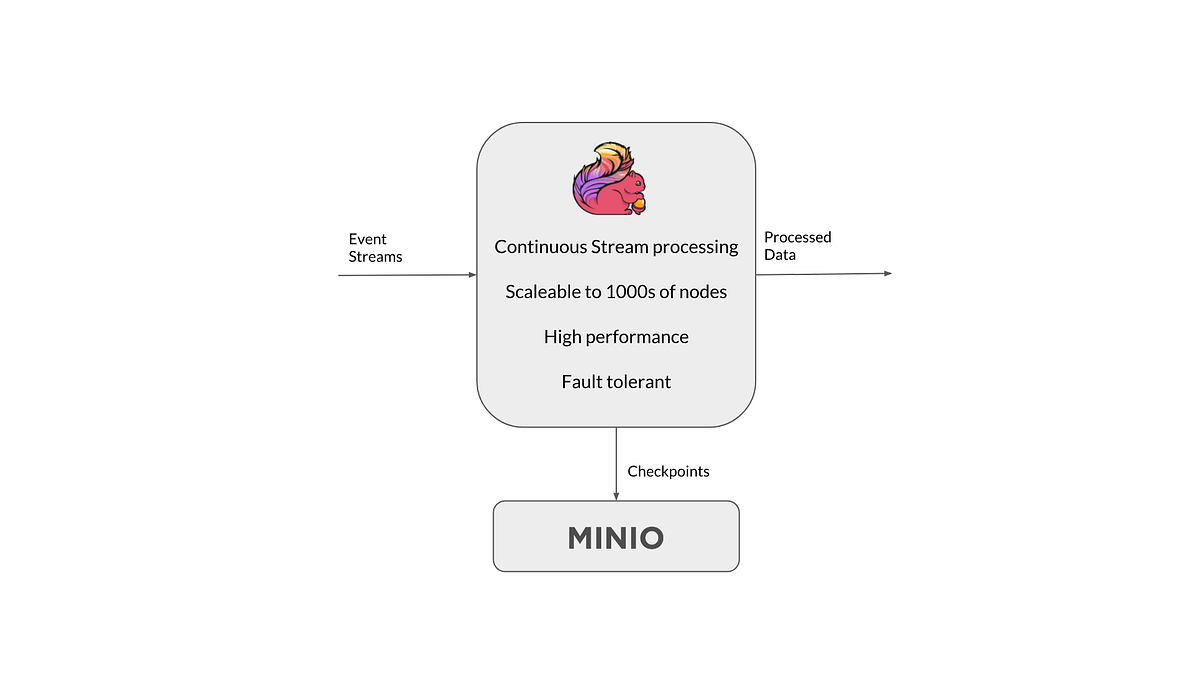
4. 将 Minio 作为 Flink 的接收器:由于 Flink 可以将数据输出到 S3 目标,因此可以使用 Minio 作为 Flink 处理数据输出的接收器。
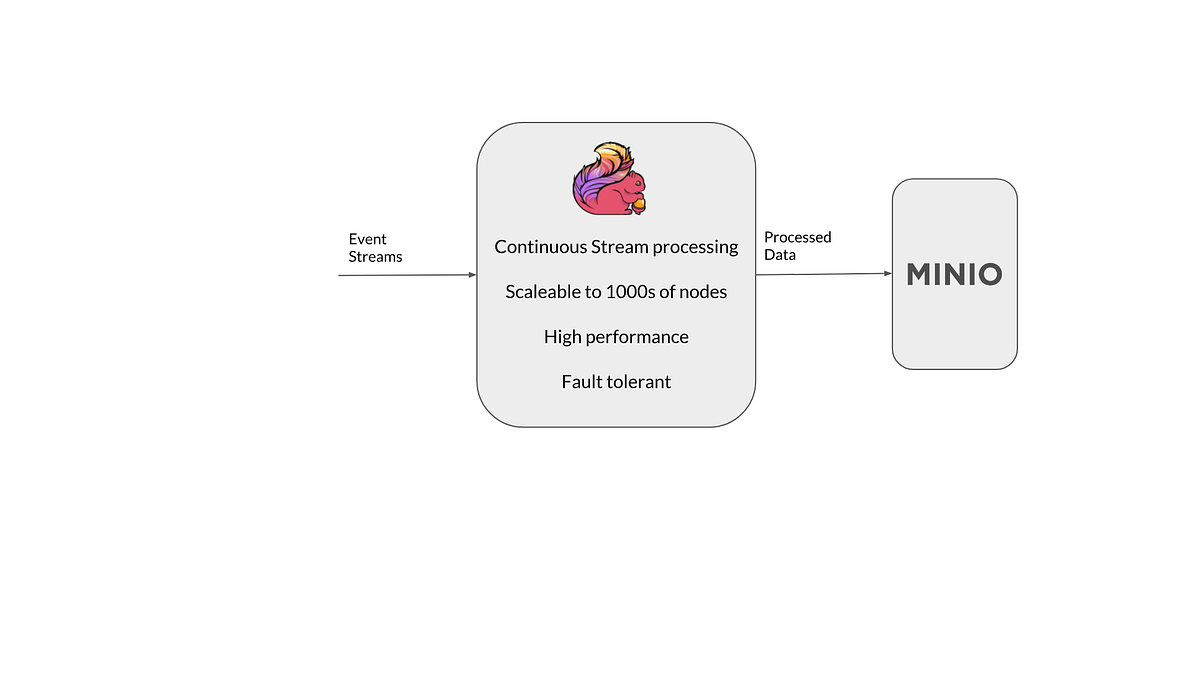
为什么将 Minio 与 Flink 配合使用是一个好主意?
- 像 Minio 这样的远程对象存储目标将状态与 Flink 的计算节点解耦。这意味着 Flink 变得无状态,即可以根据需要自由扩展和缩减(节省成本),同时状态安全地存储在 Minio 上。
- Minio 的性能(每个节点高达 10 GBps)确保即使状态已解耦,它也随时可用,并且不会增加 Flink 处理的延迟。
- 通过可配置的擦除编码、可扩展的设计、服务器端加密,Minio 确保以经济高效的方式安全、可扩展和可靠地存储数据。
- Flink 中的原生 AWS S3 API 支持意味着开箱即用的集成和对 Minio 的支持,从而降低了配置和维护成本。
将 Minio 与 Flink 配合使用
现在让我们看看如何将 Apache Flink 配置为使用 Minio 作为远程存储后端。在此示例中,我们将使用 Minio 作为源和接收器。
首先,您需要部署 Minio 服务器,请参阅此文档以获取详细信息。接下来,按照快速入门文档中的说明下载 Flink 二进制文件。
然后更新$FLINK_DIR/conf/flink-conf.yaml并添加以下部分:state.backend: filesystem
s3.endpoint: http://127.0.0.1:9000
s3.path-style: true
s3.access-key: minio
s3.secret-key: minio123
这里的$FLINK_DIR是您解压缩 Flink tar 文件的目录。此外,不要忘记根据 Minio 服务器部署中的实际情况更新s3.字段。
现在,启动 Flink。该设置现在已准备好使用 Minio 作为默认存储系统。为了测试这一点,我使用了 Flink 文档中的WordCount示例。/bin/flink run examples/batch/WordCount.jar — input s3://input/test.txt — output s3://testbucket/output
这里test.txt是一个示例文本文件(使用任何包含大量文本数据的文件)。作业完成后,您可以在testbucket/output文件中看到字数统计。
结论
在这篇文章中,我们学习了流处理以及它如何帮助企业加快数据处理方法的潜力。我们了解了流处理为何越来越受欢迎,并了解了一些流行的用例。最后,我们了解了 Minio 与 Flink 相结合如何帮助创建基于私有云的流式数据基础设施。
随着流式数据成为使用和处理事件的最流行方式之一,我们希望这篇文章能帮助您了解 Flink 如何非常适合处理此类方法,以及为什么将 Minio 用作此类流式数据基础设施的存储引擎是有意义的。