使用 MinIO 的 Apache Iceberg 开发人员入门

简介
开放式表格格式 (OTF) 是数据分析领域的一种现象,近年来发展势头强劲。OTF 的承诺在于提供一种解决方案,利用分布式计算和分布式对象存储,提供超过数据仓库所能实现的功能。 这些格式的开放性使组织在选择计算和存储方面拥有了更多选择。理论上,它们可以取代昂贵的数据仓库和超负荷的关系数据库,这些数据库已经超过了其功能。
Apache Iceberg 是三种流行的开放式表格格式 (OTF) 之一。另外两种是 Apache Hudi 和 Delta Lake。这三种格式都拥有令人印象深刻的血统 - Iceberg 来自 Netflix,Uber 最初开发了 Hudi,而 Databricks 设计了 Delta Lake。我们还为 Hudi 和 Delta Lake 提供了类似的教程:使用 Hudi 和 MinIO 构建流式数据湖 和 Delta Lake 和 MinIO 用于多云数据湖。
在这篇文章中,我将介绍 Apache Iceberg 表格式。我将首先介绍 Iceberg 规范。从那里,我将介绍 Iceberg 规范的实现,并展示如何使用 Docker Compose 在开发机器上安装它。 在设置好开发机器后,我将创建一个表,向其中添加数据,并介绍 Apache Iceberg 的三个元数据级别。
什么是 Apache Iceberg?
Apache Iceberg 是一种表格格式,最初由 Netflix 在 2017 年创建。该项目开源并于 2018 年 11 月捐赠给了 Apache 软件基金会。2020 年 5 月,Iceberg 项目晋升为顶级 Apache 项目。
但“开放式表格格式”究竟是什么?简单来说,开放式表格格式是组织包含相同信息的多个文件的规范,使它们呈现为一个单一的“表”。这是一个厚重且复杂的陈述。让我们进行调查,以便我们完全理解所陈述的内容。首先,术语“表”来自关系数据库世界。我们所暗示的是,我们希望所有这些文件都可查看和可更新,就好像它们是一个单一的实体——表一样。换句话说,您希望以与在数据库中与表交互相同的方式与这组文件交互。从较高层次来看,这是目标——将文件转换为表格。请记住,它只是一个规范。各方必须实现此规范才能生成可用的软件。 让我们深入探讨,看看需要实现什么。
为了实现 Apache Iceberg 规范,我们需要三件事
- 一个目录来跟踪所有相关的元数据文件。
- 一个处理引擎,它将像查询引擎一样运行。
- 一个高速、可扩展的存储解决方案,用于存储所有相关的数据文件。(理想情况下,目录也使用对象存储来存储元数据文件,但这不是 Apache Iceberg 规范的要求。)
下面显示了这三个组件的逻辑图。
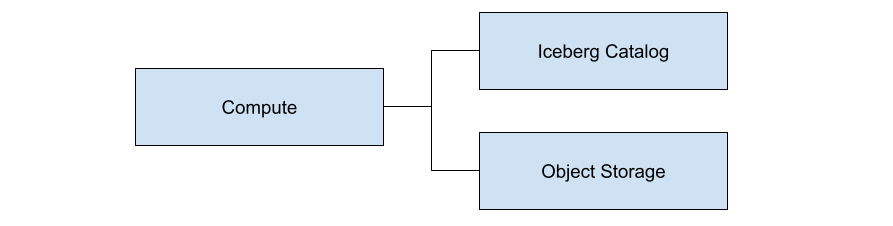
请注意,正是计算节点将所有内容联系在一起。作为程序员,您将向计算节点发出命令,用于创建表、将数据插入表和查询表。在向计算节点发出请求后,计算节点的工作是使用目录确定相关文件,然后查询对象存储以检索这些文件。
让我们看一下此逻辑图的具体实现。下图显示了我们在本文中将安装的内容。Rest 目录使用 MinIO 来存储元数据。
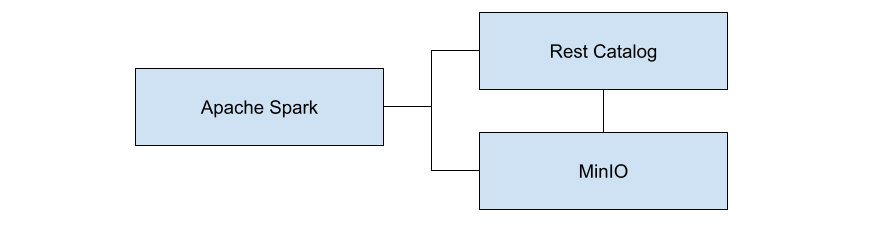
MinIO 是 Iceberg 最佳的对象存储——无论您为处理引擎和目录选择什么。构成 Iceberg 解决方案的数据和元数据的文件可能是一堆小文件,也可能是一些非常大的文件。这对 MinIO 来说并不重要。此外,MinIO 是一种性能优异的对象存储(在 32 个 NVMe 节点上,GET 速度为 349 GB/s,PUT 速度为 177 GB/s),能够为即使是最苛刻的 数据湖、分析 和 AI/ML 工作负载提供支持。数据写入 MinIO 时具有强一致性,并使用 不可变 对象。所有对象都受到内联 擦除编码、位腐烂散列 和 加密 的保护。
使用 Rest 目录和 MinIO 安装 Apache Iceberg
Apache Iceberg Spark 快速入门 推荐使用下面的 Docker Compose 文件来安装 Rest 目录、支持 Iceberg 的 Spark 处理引擎以及用于对象存储的 MinIO。
上面的 Docker Compose 文件来自 Tabular 的团队——这是他们的 Github 存储库,其中包含有关所用镜像的更多详细信息。如果您希望获得此存储库的副本以供参考,请使用以下命令克隆它。(注意 - 您无需克隆此存储库。独立的 Docker-Compose 文件副本将起作用,因为所有镜像都已构建。)
如果您研究了上面列出的服务,您会得出结论,没有配置告诉 Spark-Iceberg 服务如何连接到 Rest 目录。深入研究此存储库会发现 配置(在配置文件中),Spark-Iceberg 服务使用它来连接到 Rest 目录。
请注意,Iceberg-rest 服务和 Spark-Iceberg 服务都连接到 MinIO。在此实现中,Iceberg-rest 服务使用 MinIO 来保存所有元数据文件,而 Spark-Iceberg 服务使用 MinIO 来保存所有数据文件。
在与上面的 Docker-Compose 文件相同的目录中运行下面的 docker 命令,以便在 Docker 中安装这些服务。您第一次启动这三项服务时,需要几分钟的时间。
完成后,导航到 localhost:8888。这是 Spark 服务公开的一个端口,它包含一个 Jupyter Notebook 服务器。它应该看起来像下面的屏幕截图。
我们几乎准备好了创建表、插入数据和运行查询。但在我们这样做之前,让我们了解一下 Iceberg 的数据架构。
Iceberg 的数据架构
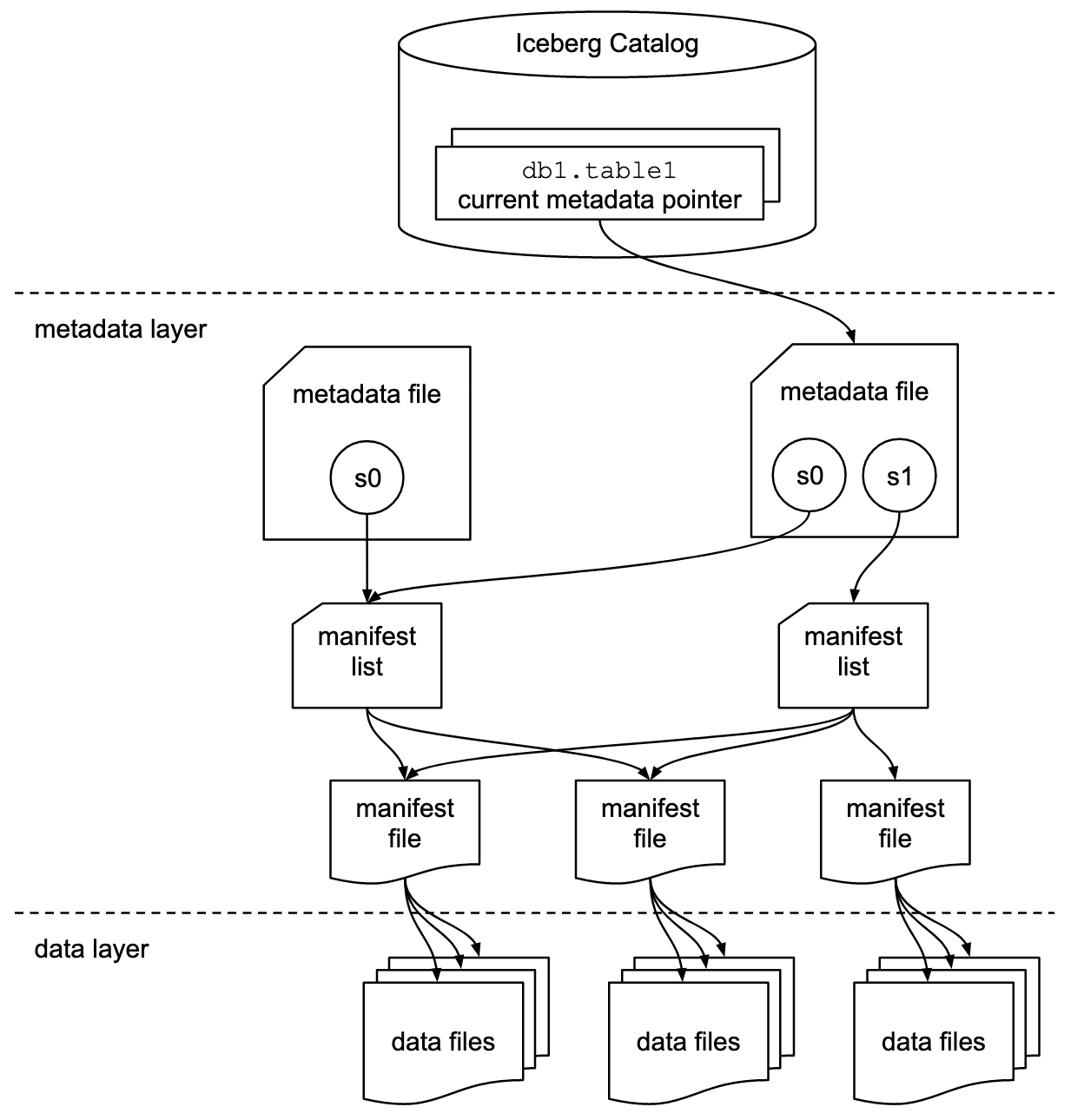
下图来自 Apache Iceberg 规范,它最能说明 Iceberg 实现维护的不同元数据级别。
来源:https://iceberg.apache.org/spec/
浏览每个级别是一个深入了解 Iceberg 的好方法。当我们浏览每个层时,请记住,目标是生成一种设计,允许轻松实现以下功能
- 模式演变 - 允许在不丢失数据的情况下更改表设计。换句话说,添加、删除、更新或重命名列。
- 隐藏分区 - 数据架构师不应创建列以允许对表进行分区。例如,添加一个月份列,该列是从日期时间字段生成的,以便快速检索月度报告。
- 分区布局演变 - 随着时间的推移,表可能会在分区之间出现不平衡的容量——或者分区之间的查询模式可能会发生变化。需要有一种方法来修改表布局(分区),以处理容量变化和查询模式变化。
- 时光倒流 - 时光倒流是指在查询中指定过去的一个日期,并获取该日期表的外观视图的能力。时光倒流使对不断更新的表进行可重复查询成为可能。这对机器学习工作负载也很重要,您可能需要查看模型在过去的表现情况。这也是创建训练集和测试集的好方法。
- 版本回滚 - 允许数据架构师将表回滚到先前状态,如果新设计不好或新数据损坏或不准确。
如果您之前使用过关系型数据库,您就会知道这些设计目标并不容易实现。
让我们从概念上逐层了解 Iceberg 的数据架构,以理解 Iceberg 如何实现上述目标。在下一节中,当我们从头创建一个表时,我们将查看实际的元数据文件来巩固我们对这些概念的理解。
Iceberg 目录 - 处理引擎连接到目录以获取所有表的列表。对于每个表,目录跟踪所有元数据文件。
元数据文件 (级别 1) - 包含模式和分区信息。这也可以包括之前的模式和分区,如果它们发生过更改。元数据文件还包含快照列表。每次以任何方式更改表时,都会基于之前的元数据文件创建一个新的元数据文件 - 更改被放置在一个快照中,新的快照被添加到新的元数据文件中。元数据文件允许表被版本化,并在必要时回滚。它们还包含模式演化、分区布局演化和隐藏分区所需的元数据。
清单列表 (级别 2) - 可以将单个清单列表视为快照本身 - 它提供了一种方法来收集给定快照的所有数据。快照允许进行时间旅行。在上图中,如果需要表的最新版本,则使用 `s1` 快照。但是,如果想使用在创建 `s0` 快照时存在的表,则使用此快照。
清单文件 (级别 3) - 清单文件指向一个或多个数据文件。这是架构中可能看起来不必要的部分 - 但它对于高效的查询执行非常重要。清单文件跟踪数据文件中数据所属的分区。正是这些信息允许在规划查询时消除整个文件组。清单文件还包含与每个文件中的值相关的列级信息。例如,如果列包含温度读数,则清单文件将维护每个数据文件的最大值和最小值。这也便于高效的查询规划。
数据文件 - 最后,我们得到数据。数据文件包含数据。它们通常采用 Parquet 格式,但也可以是处理引擎可以解析的任何格式。
我已经让你等了很长时间才开始编码,但至少现在你将理解我们在创建表、向其中添加数据然后查询表时幕后发生的一切。
有关 Iceberg 的整体架构的更多信息,请查看 使用 Iceberg 和 MinIO 的湖仓架构终极指南.
创建表
转到我们之前安装的 Jupyter Notebook,并创建一个新的笔记本。我们将创建一个新数据库和一个只有一个分区的简单表。要创建数据库,请将下面的代码放在一个单元格中。这将创建一个名为 `climate` 的数据库。
要创建一个名为 `weather` 的表,请使用以下 SQL 代码。此表按天分区。
在将数据添加到此表之前,让我们看一下 MinIO 中发生了什么。上述命令完成后,将创建一个元数据文件 - 这是 Iceberg 数据架构中元数据的第一个层级。打开 MinIO,可以在 localhost:9001 找到它。回顾 Docker Compose 文件,所有内容都将转到 `warehouse` 存储桶。深入到该存储桶,您应该会看到类似于下面截图的内容。这是 weather 表的元数据文件。请注意,Rest Catalog 使用数据库名称和表名称作为此文件路径的一部分。
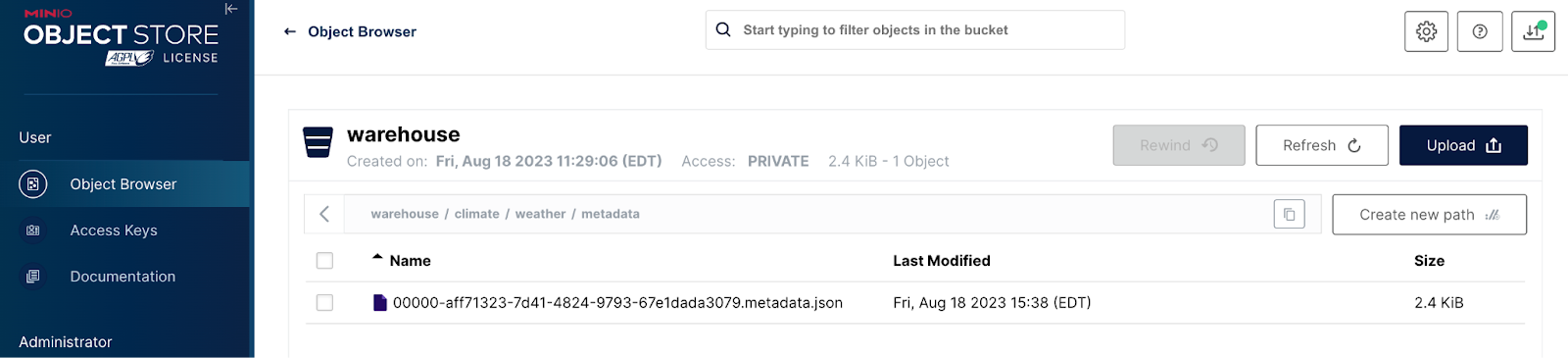
由于我们尚未将任何数据添加到表中,因此这是目前 MinIO 中存在的唯一元数据文件。在添加数据后,我们将打开一个元数据文件。
添加数据
以下 PySpark 代码将向新创建的表中添加三行。请注意,由于日期落在三天不同的日期,因此它们将位于不同的分区中。
现在我们有了数据,让我们打开表的元数据文件。下面是一张图片,显示了在数据被添加到表之后,`weather` 表的元数据文件的内容。为了简洁起见,它已折叠。请注意,它具有当前模式、当前分区、以前模式、以前分区和快照的占位符。当前快照指向一个清单文件列表,该列表是该表的某个时间点的快照。
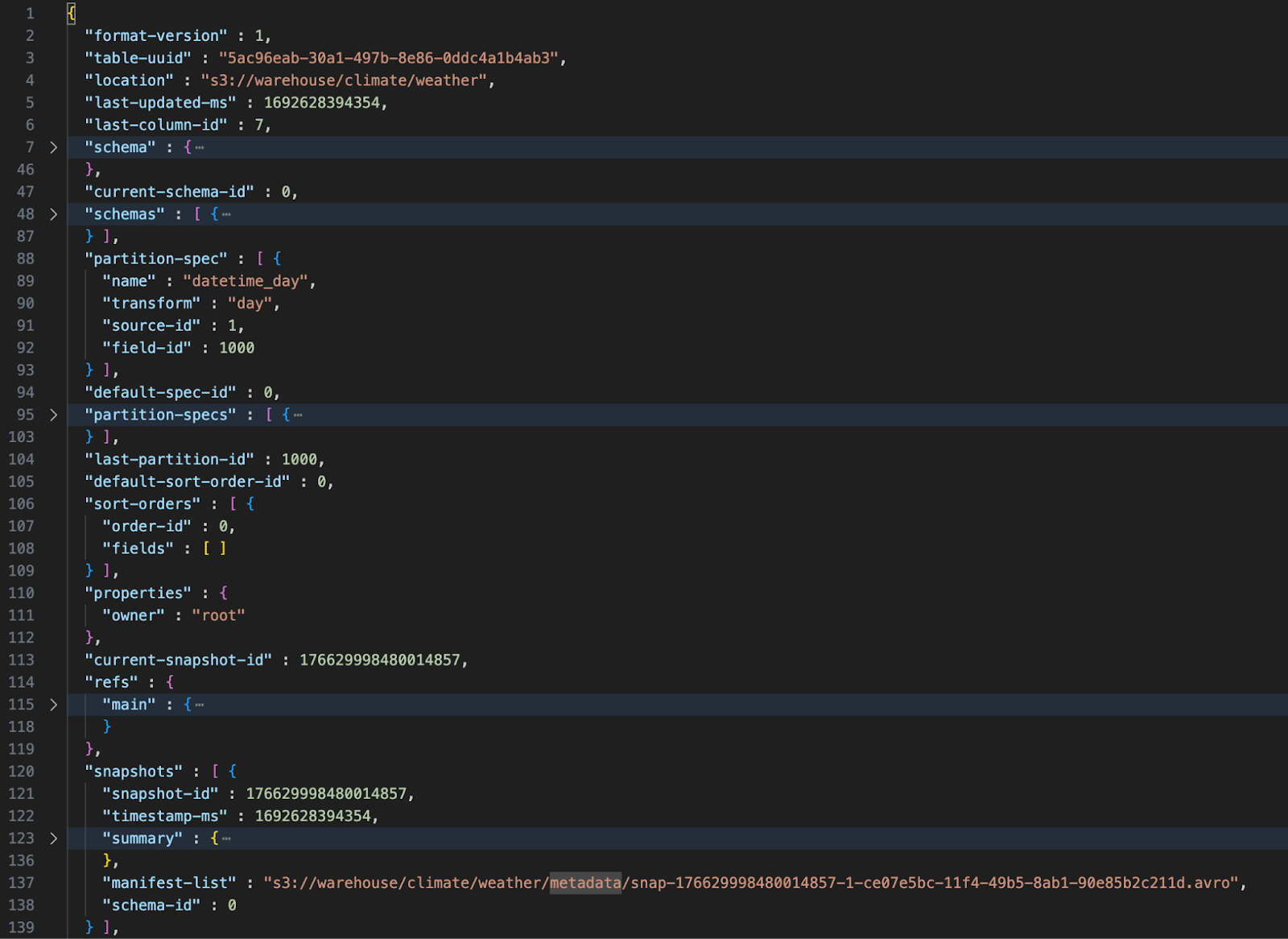
Iceberg 元数据文件 - 第 1 级
清单(或快照)是一个 Avro 文件。(将其转换为 JSON 可能很棘手 - 请使用此网站进行转换 - https://dataformat.net/avro/viewer-and-converter。)此文件显示在下方。
Iceberg 清单文件 - 级别 2
这是 Iceberg 数据架构中的第 2 级。清单文件相对简单。它们的主要目的是跟踪表在某个时间点的状态。它们通过指向一个或多个清单文件来做到这一点。在我们的简单示例中,我们只有一个清单文件。清单文件可能变得很大 - 尤其是在您的数据分布在许多分区中的情况下。我们清单文件的折叠部分显示在下方。
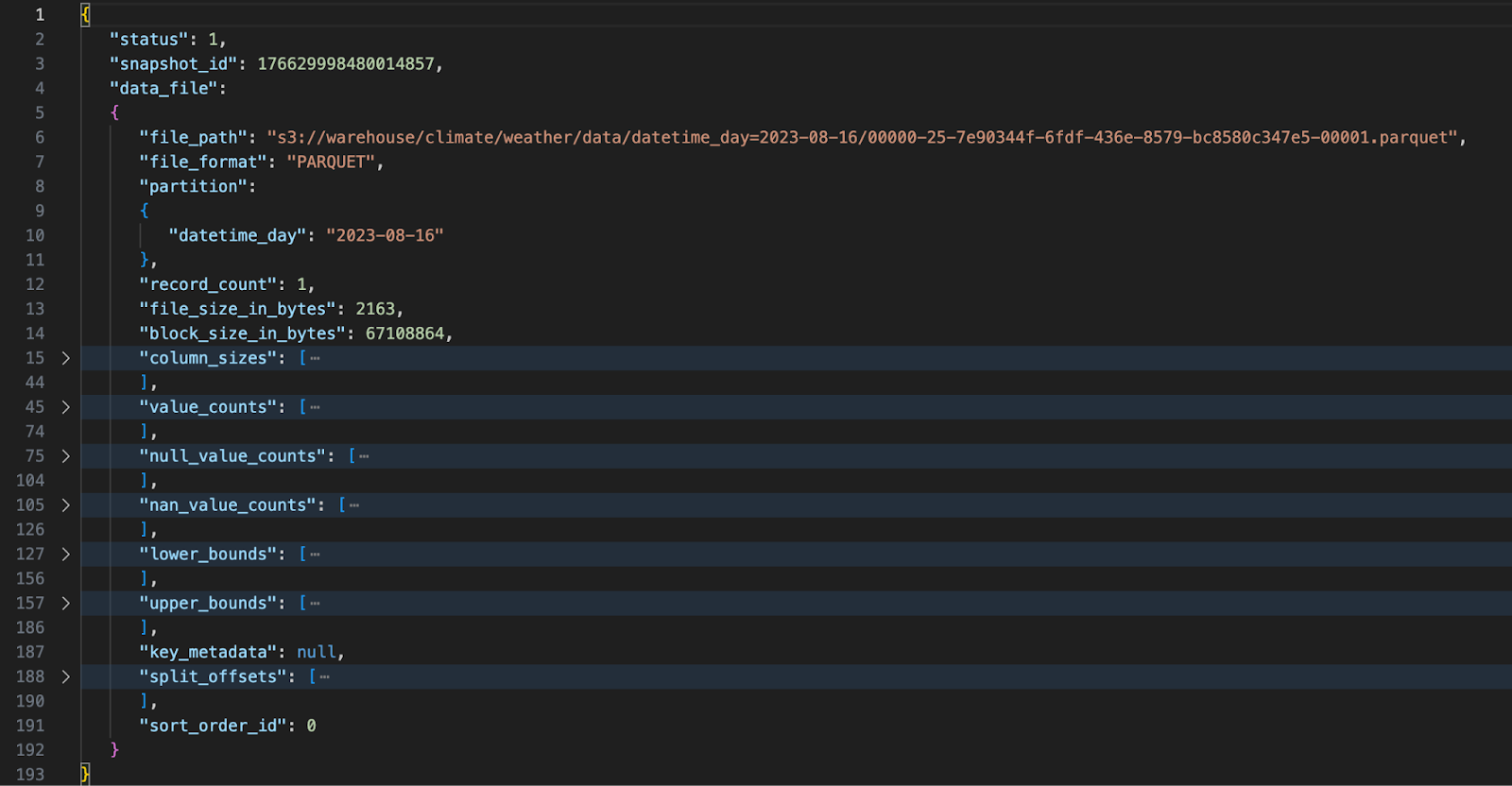
Iceberg 清单文件 - 级别 3
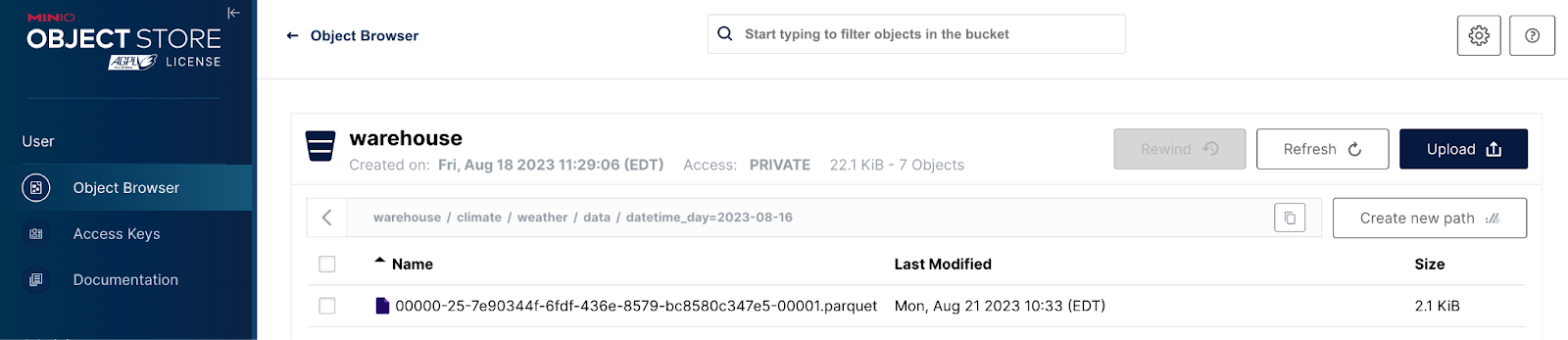
清单文件代表 Iceberg 数据架构中的第三层也是最后一层。因此,它们指向数据文件。数据文件通常采用 Parquet 格式,并且仅包含数据。下面是一个屏幕截图,显示了 `warehouse` 存储桶中的 `data` 路径。
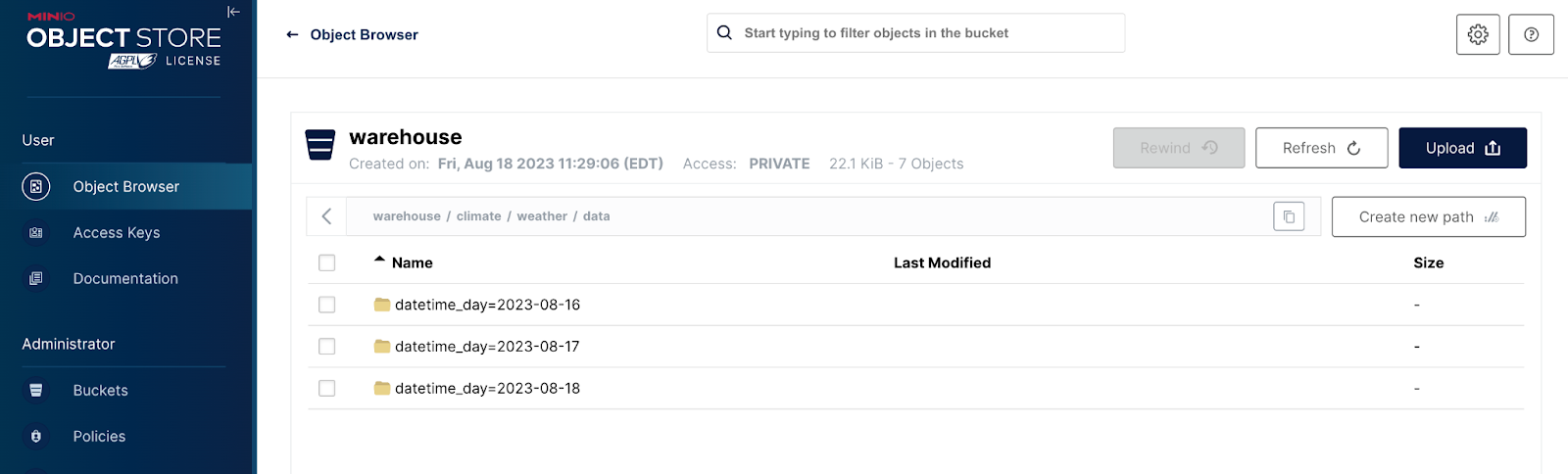
请注意,到目前为止,每个分区都有一条路径 - 我们将三个不同日期的数据添加到按日期分区的表中。以这种方式组织数据文件不是 Iceberg 规范的一部分 - 它是使用 MinIO 等对象存储时获得的优势。深入其中一个分区,我们可以看到 Parquet 文件。
现在我们的 Iceberg 表中有一些数据了,让我们通过查询数据来结束开发人员调查。
查询表
为了展示在 Iceberg 中查询数据的容易程度,我将使用一个相当新的 Python 库 - PyIceberg。PyIceberg 的承诺是提供一种在不需要 JVM 的情况下查询 Iceberg 表的方法。不幸的是,在撰写本文时,PyIceberg 只能用于查询数据 - 它不能用于添加、更新或删除数据。请查看 PyIceberg 网站,了解有关未来发展的新闻。
PyIceberg 预安装在我们通过 Docker Compose 文件创建的 Spark 服务中。以下代码在我们的笔记本中放入新单元格时有效。它将返回 `weather` 表中 `datetime` 字段大于或等于 2023 年 8 月 1 日的所有行。
输出将类似于下面的图像。

请注意,此查询利用了我们创建的分区,因为我们正在按 `datetime` 字段进行过滤。
总结
在这篇文章中,我介绍了 Apache Iceberg 的开发人员导览。我展示了如何使用 Docker Compose 在开发机器上运行 Apache Iceberg 的实现。该实现使用 Spark 作为处理引擎,MinIO 作为存储,以及 Rest Catalog。我使用的 Rest Catalog 的优点是它使用 MinIO 作为元数据。其他目录使用分布式文件系统或数据库作为 Iceberg 元数据 - 但这不是现代解决方案,并且会不必要地在部署中引入额外的存储技术。更好的方法是将元数据和数据都保存在高速、可扩展的对象存储中。这就是 MinIO 提供的。
我还介绍了 Iceberg 的目标,并通过创建表并向其添加数据来介绍 Iceberg 的数据架构。然后,我介绍了 Iceberg 为每个表维护的三级元数据。最后,我介绍了 PyIceberg - 一个无需 JVM 即可查询 Iceberg 数据的新库,PySpark 需要 JVM。
在 MinIO,我们喜欢 开放式表格格式,因为它们有助于释放您的数据,并使您能够使用最新的云原生分析和 AI/ML 框架。