用 MinIO 赢得 RAG 权利


人们常说,在人工智能时代,数据就是你的护城河。为此,构建一个生产级别的 RAG 应用需要一个合适的 数据基础设施,用于存储、版本控制、处理、评估和查询构成你的专有语料库的数据块。由于 MinIO 采用数据优先的方法来构建人工智能,对于此类项目,我们默认的初始基础设施建议是建立一个现代数据湖 (MinIO) 和一个向量数据库。虽然可能需要在此过程中插入其他辅助工具,但这两个基础设施单元是基础。它们将成为将你的 RAG 应用投入生产过程中所遇到的几乎所有任务的重心。
但你陷入了困境。你以前听说过 LLM 和 RAG 这些术语,但由于未知,你并没有深入研究。但如果有一个“Hello World”或样板应用可以帮助你入门,难道不妙吗?
别担心,我之前也和你一样。所以在这篇博文中,我们将演示如何使用 MinIO 使用商品硬件构建一个基于检索增强生成 (RAG) 的聊天应用。
- 使用 MinIO 存储所有文档、处理后的数据块以及使用向量数据库的嵌入。
- 使用 MinIO 的存储桶通知功能,在向存储桶添加或删除文档时触发事件。
- Webhook 消费事件并使用 Langchain 处理文档,并将元数据和分块文档保存到元数据存储桶。
- 为新添加或删除的分块文档触发 MinIO 存储桶通知事件。
- 一个 Webhook 消费事件并生成嵌入,并将其保存到持久化在 MinIO 中的向量数据库 (LanceDB) 中。
使用的主要工具
- MinIO - 对象存储,用于持久化所有数据
- LanceDB - 无服务器开源向量数据库,将数据持久化到对象存储中
- Ollama - 在本地运行 LLM 和嵌入模型 (与 OpenAI API 兼容)
- Gradio - 用于与 RAG 应用交互的界面
- FastAPI - 用于接收来自 MinIO 的存储桶通知并公开 Gradio 应用的服务器
- LangChain & Unstructured - 用于从我们的文档中提取有用的文本并将其分块以进行嵌入
使用的模型
- LLM - Phi-3-128K (3.8B 参数)
- 嵌入 - Nomic Embed Text v1.5 (Matryoshka 嵌入/ 768 维度,8K 上下文)
启动 MinIO 服务器
如果你还没有 MinIO 二进制文件,可以从 这里 下载。
启动 Ollama 服务器 + 下载 LLM 和嵌入模型
从 这里 下载 Ollama。
使用 FastAPI 创建一个基本的 Gradio 应用来测试模型
测试嵌入模型
摄取管道概述
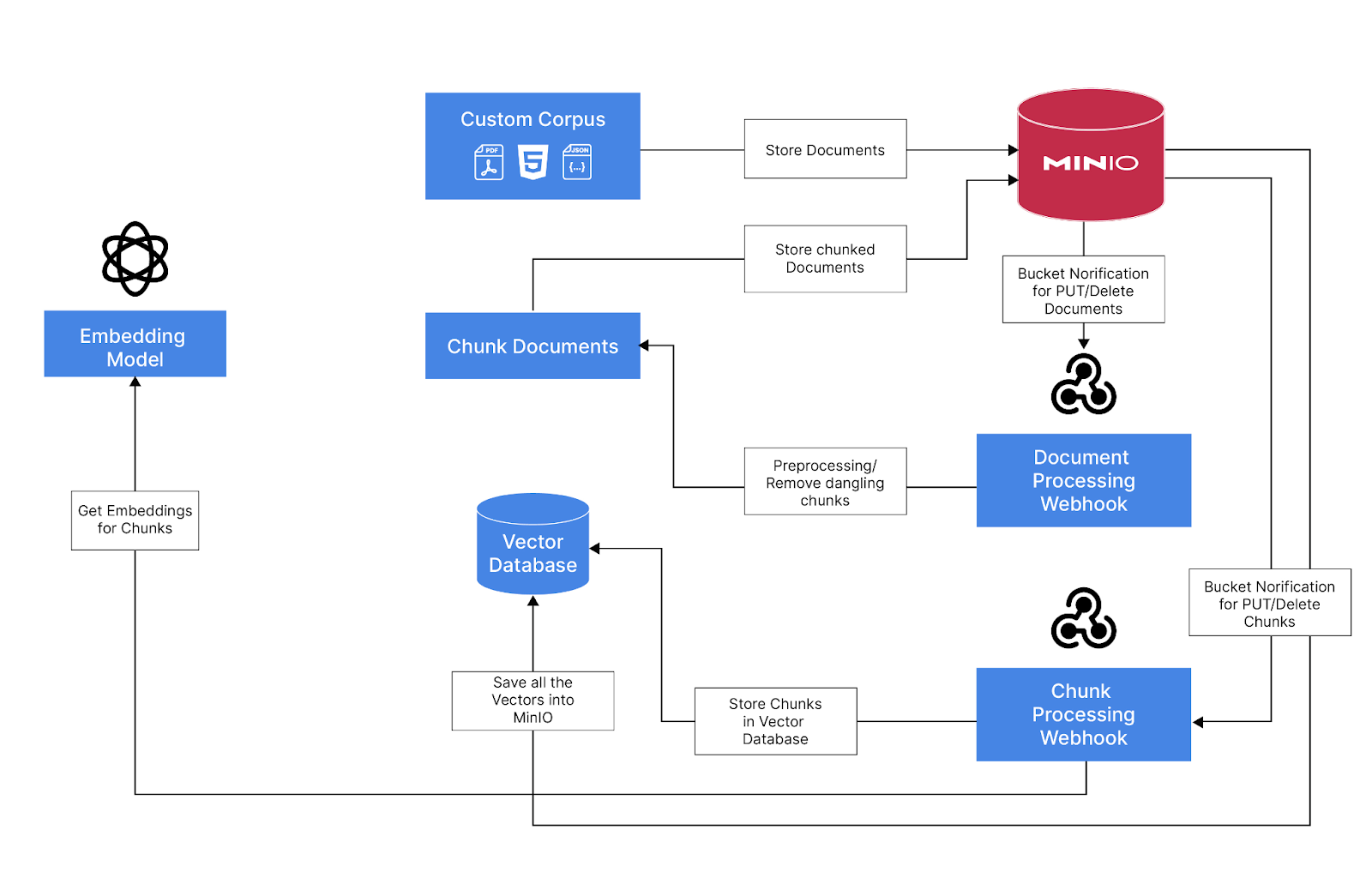
创建 MinIO 存储桶
使用 mc 命令或从 UI 中进行
- custom-corpus - 用于存储所有文档
- warehouse - 用于存储所有元数据、数据块和向量嵌入
创建消费来自 custom-corpus 存储桶的存储桶通知的 Webhook
创建 MinIO 事件通知并将它链接到 custom-corpus 存储桶
创建 Webhook 事件
在控制台中,转到事件 -> 添加事件目标 -> Webhook
使用以下值填写字段并点击保存
标识符 - doc-webhook
端点 - https://:8808/api/v1/document/notification
在提示时,点击顶部的重新启动 MinIO。
(注意:你也可以使用 mc 来完成此操作)
将 Webhook 事件链接到 custom-corpus 存储桶事件
在控制台中,转到存储桶 (管理员) -> custom-corpus -> 事件
使用以下值填写字段并点击保存
ARN - 从下拉列表中选择 doc-webhook
选择事件 - 选中 PUT 和 DELETE
(注意:你也可以使用 mc 来完成此操作)
我们已经设置了第一个 Webhook。
现在通过添加和删除对象进行测试。
从文档中提取数据并进行分块
我们将使用 Langchain 和 Unstructured 从 MinIO 中读取对象并将文档拆分为多个数据块。
将分块逻辑添加到 Webhook
将分块逻辑添加到 Webhook,并将元数据和数据块保存到 warehouse 存储桶
使用新逻辑更新 FastAPI 服务器
添加新的 webhook 来处理文档元数据/分块
现在我们有了第一个 webhook,下一步是获取所有带有元数据的分块,生成嵌入并将它们存储在向量数据库中。
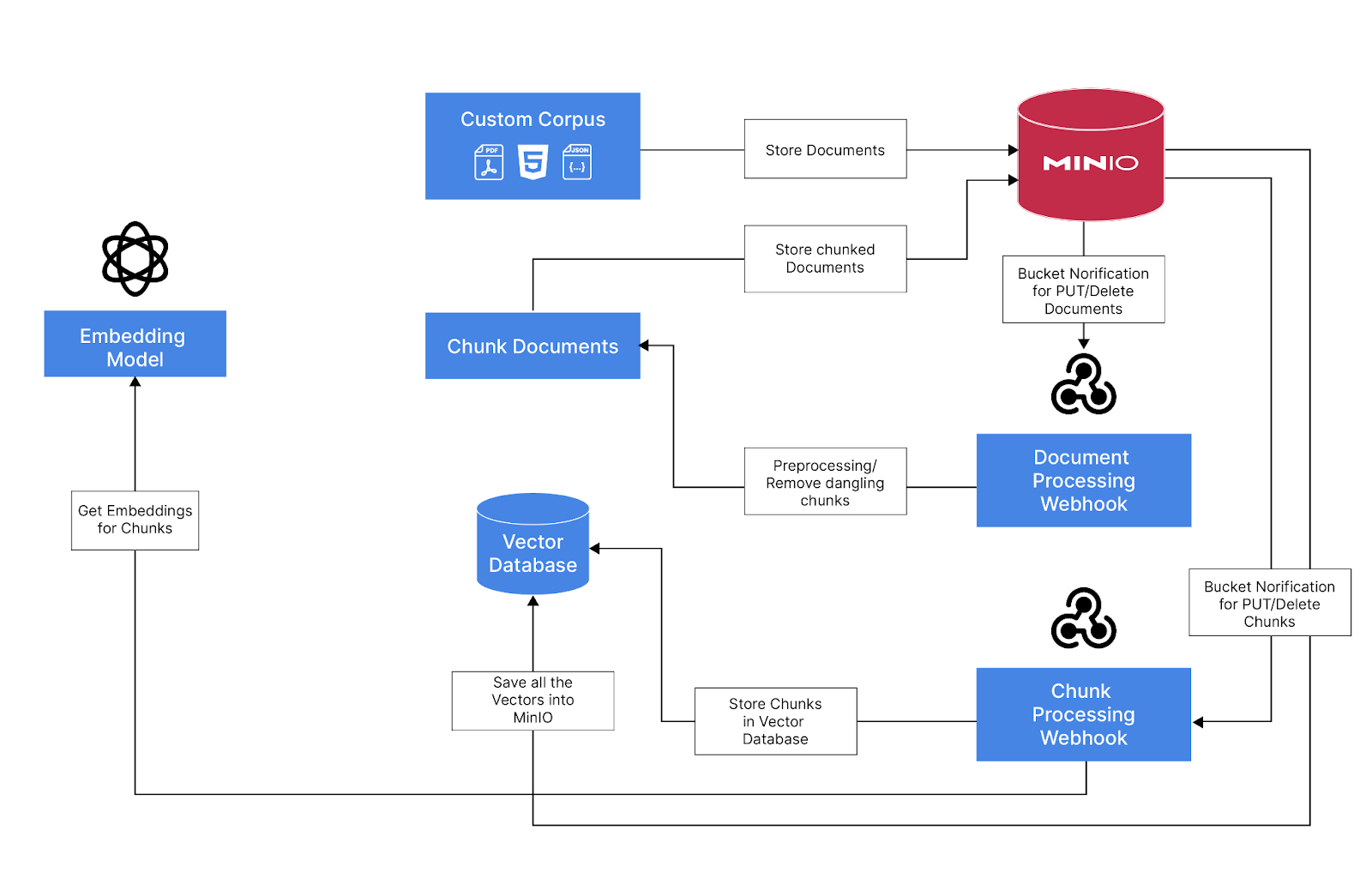
创建 MinIO 事件通知并将其链接到仓库桶
创建 Webhook 事件
在控制台中,转到事件 -> 添加事件目标 -> Webhook
使用以下值填写字段并点击保存
标识符 - metadata-webhook
端点 - https://:8808/api/v1/metadata/notification
提示时点击顶部的重新启动 MinIO
(注意:你也可以使用 mc 来完成此操作)
将 Webhook 事件链接到 custom-corpus 存储桶事件
在控制台中转到桶(管理员)-> 仓库 -> 事件
使用以下值填写字段并点击保存
ARN - 从下拉菜单中选择 metadata-webhook
前缀 - metadata/
后缀 - .json
选择事件 - 选中 PUT 和 DELETE
(注意:你也可以使用 mc 来完成此操作)
我们已经设置了第一个 Webhook。
现在通过在 custom-corpus 中添加和删除对象来测试此 webhook 是否被触发
在 MinIO 中创建 LanceDB 向量数据库
现在我们已经有了基本的 webhook,让我们在 MinIO 仓库桶中设置 lanceDB 向量数据库,我们将在其中保存所有嵌入和额外的元数据字段
将存储/删除数据从 lanceDB 添加到 metadata-webhook
添加一个调度程序来处理队列中的数据
使用向量嵌入更改更新 FastAPI
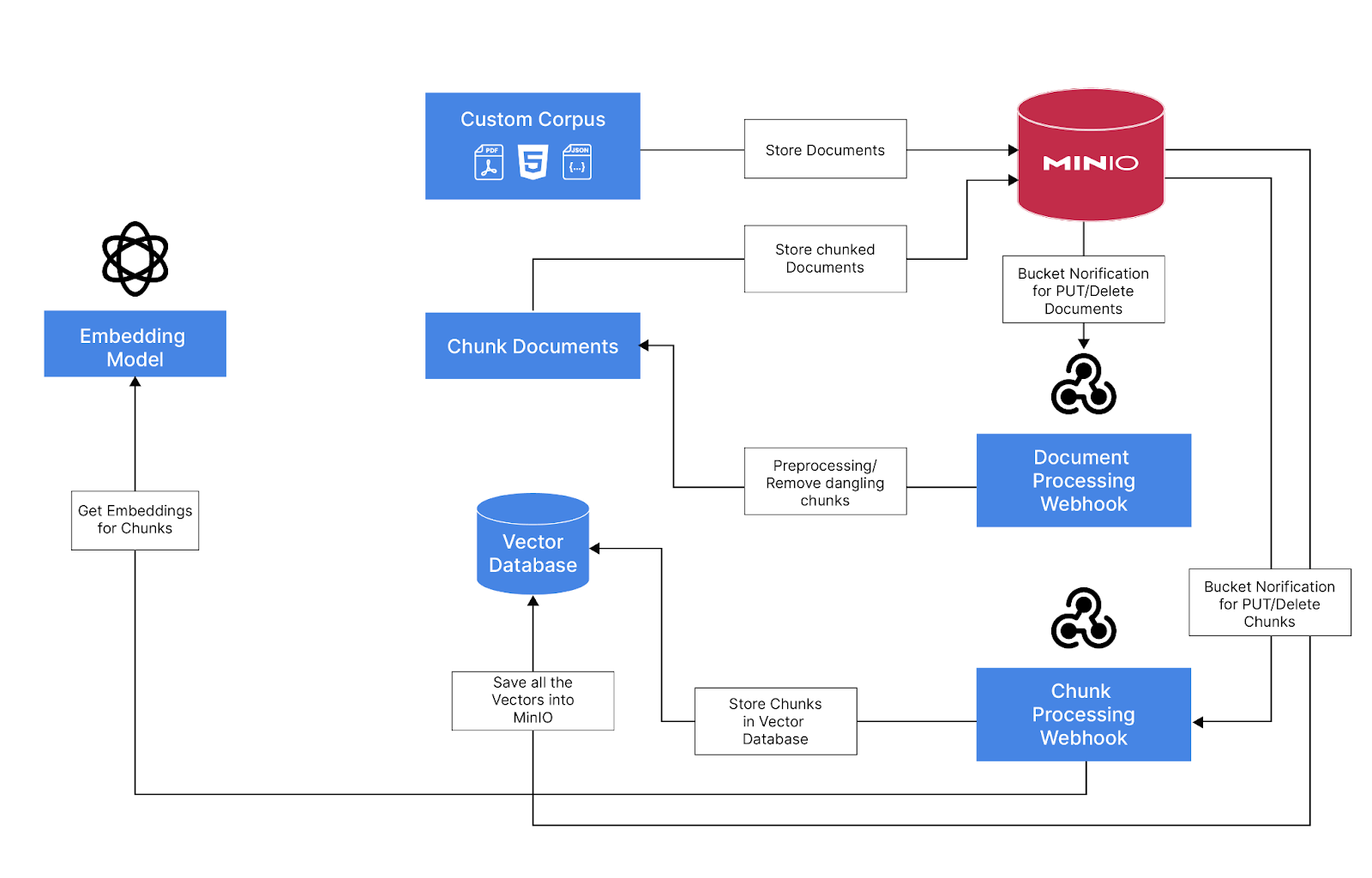
现在我们已经有了摄取管道,让我们集成最终的 RAG 管道。
添加向量搜索功能
现在我们已经将文档摄取到 lanceDB 中,让我们添加搜索功能
提示 LLM 使用相关文档
更新 FastAPI 聊天端点以使用 RAG
您是否能够完成并实现基于 MinIO 作为数据湖后端的 RAG 聊天?在不久的将来,我们将围绕同一主题举办网络研讨会,我们将为您现场演示如何构建这个基于 RAG 的聊天应用程序。
RAGs-R-Us
作为专注于 MinIO 人工智能集成的开发人员,我一直在探索如何将我们的工具无缝集成到现代人工智能架构中,以提高效率和可扩展性。在这篇文章中,我们向您展示了如何将 MinIO 与检索增强生成 (RAG) 集成以构建聊天应用程序。这只是冰山一角,可以帮助您在构建 RAG 和 MinIO 的更多独特用例方面的探索中获得优势。现在您拥有构建它的基础。让我们一起行动吧!
如果您对 MinIO RAG 集成有任何疑问,请务必在 Slack 上联系我们!