如今,人工智能和数据管理方面,组织面临的最大挑战之一是获取可靠的基础设施和计算资源。英特尔 Tiber 开发者云专为需要一个用于概念验证、实验、模型训练和服务部署的环境的工程师而设计。与其他可能难以理解和复杂的云不同,英特尔 Tiber 开发者云简单易用。该平台对开发各种类型模型的人工智能/机器学习工程师尤其有价值。使用英特尔的云,人工智能/机器学习工程师可以轻松获取用于运行训练和推理工作负载以及部署应用程序和服务的计算和存储资源。
英特尔选择 MinIO 作为其云的对象存储,因为它带来了简单性、可扩展性、性能以及与云和 AI 生态系统的原生集成。我们很高兴成为首选的对象存储,并很乐意撰写这篇“操作指南”文章,以加快您对该平台的采用。我将展示如何使用英特尔 Gaudi AI 加速器训练模型,以及如何在英特尔 Tiber 开发者云中设置和使用 MinIO(对象存储)。
让我们开始吧。本文的完整代码演示可以在这里找到 这里。
创建账户并启动实例
英特尔的云文档包含有关设置您的账户以及获取人工智能/机器学习实验、优化和部署资源的分步指南。本文中提供的代码假设您已完成以下指南。
入门 - 本指南将引导您完成创建和登录账户的过程。它还将向您展示如何使用云的 Jupyter 服务器。Jupyter Lab 的一个优点是您无需 SSH 密钥即可启动和使用它。
SSH 密钥 - 要创建计算实例,您需要将 SSH 公钥上传到您的账户。本指南将向您展示如何根据云的规范创建密钥并将其上传到您的账户。请务必将公钥和私钥保存在安全的地方。您将需要私钥才能通过 SSH 连接到计算实例。本指南还显示了连接到实例的 SSH 命令。
管理实例 - 本指南展示了如何选择计算节点、启动它以及在您完成实验后将其关闭。
对象存储 - 本指南将引导您完成在账户中创建存储桶的过程。
拥有账户后,您将可以访问硬件、软件和服务选项,如下所示。在本篇文章中,我们将使用计算实例和对象存储。
准备 MinIO 以进行编程访问
下面的屏幕截图显示了用于创建存储桶的对话框。请注意,您的存储桶名称以唯一的标识符作为前缀。这是必要的,因为 MinIO 是英特尔云的平台服务,它支持云区域中的所有账户。因此,唯一的标识符可防止与其他账户的名称冲突。
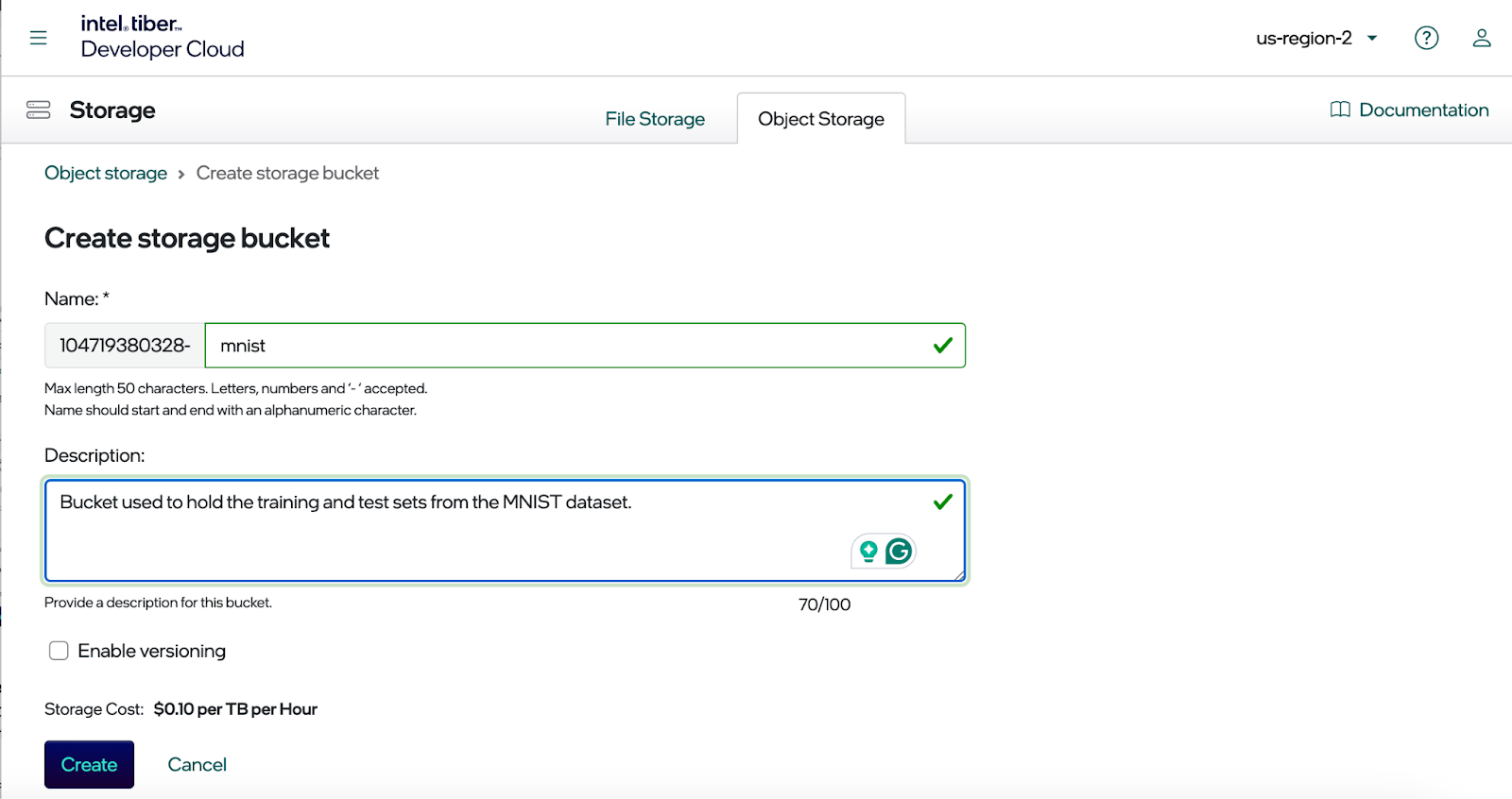
输入存储桶的名称,并在需要时启用版本控制。单击“创建”按钮后,您应该会看到新的存储桶,如下所示。本文将使用 MNIST 数据集并以编程方式访问它来训练模型。因此,需要端点来访问我们的新存储桶、访问密钥和私钥。
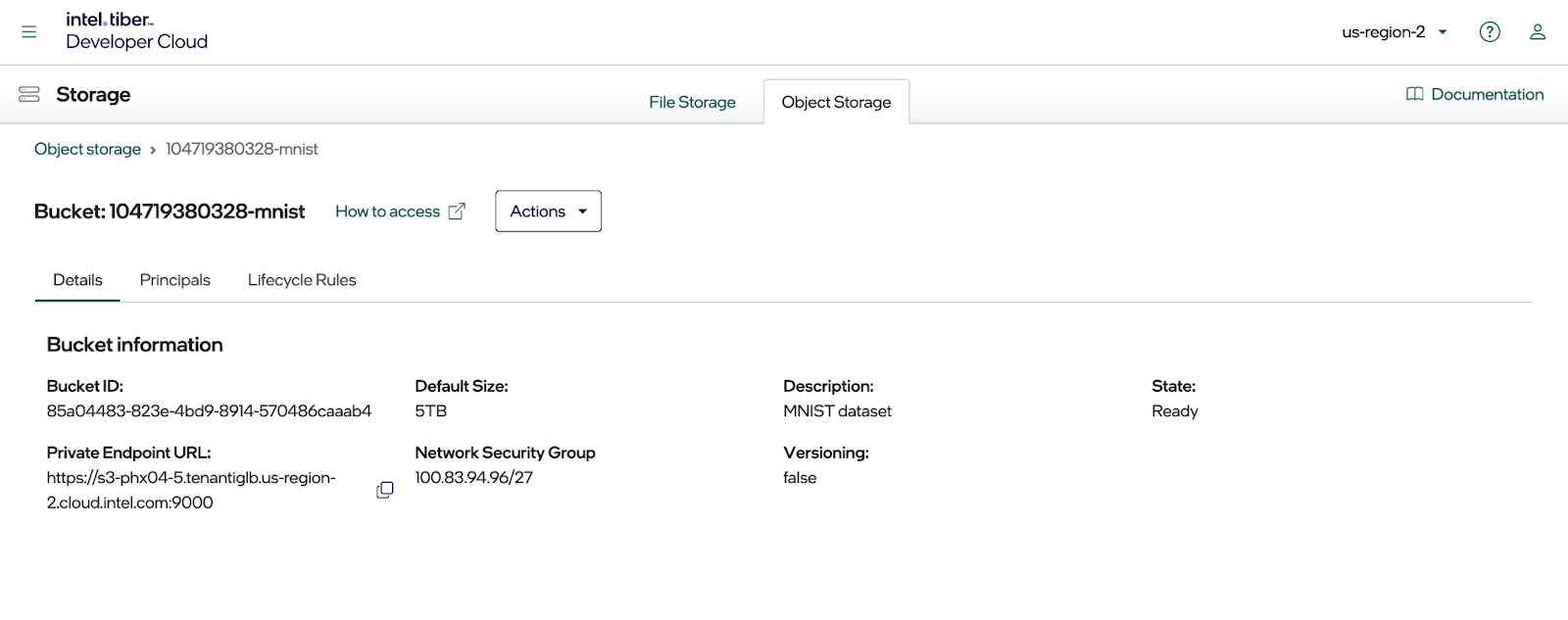
要查看端点地址,请单击新的存储桶,然后选择“详细信息”选项卡,如下面的图像所示。复制此对话框中显示的私有端点,因为在设置 MinIO SDK 配置文件时需要它。
由于您需要以编程方式访问存储桶,因此请创建一个主体并将其与访问密钥和密钥关联。为此,请单击“主体”选项卡。所有现有的主体都将显示。
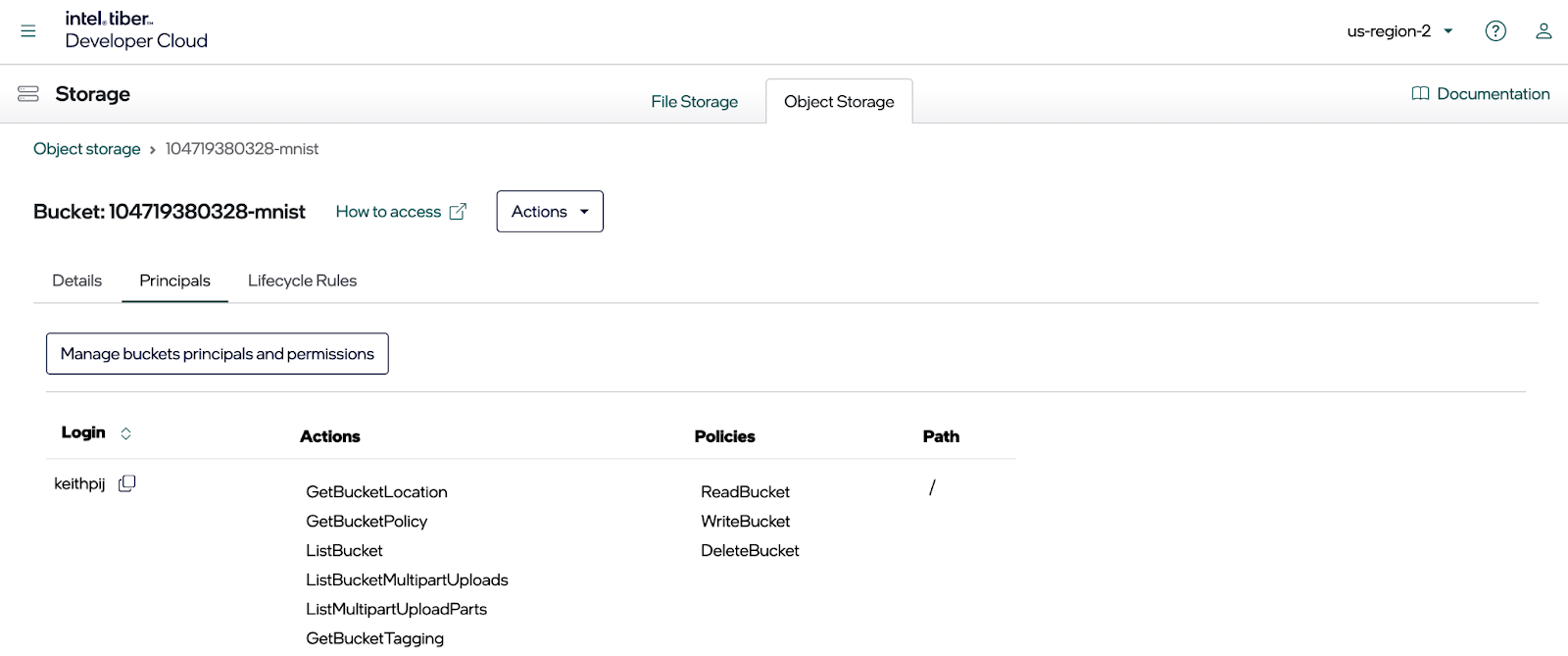
接下来,单击“管理主体和权限”按钮。这将打开一个对话框,您可以在其中编辑上面显示的主体。
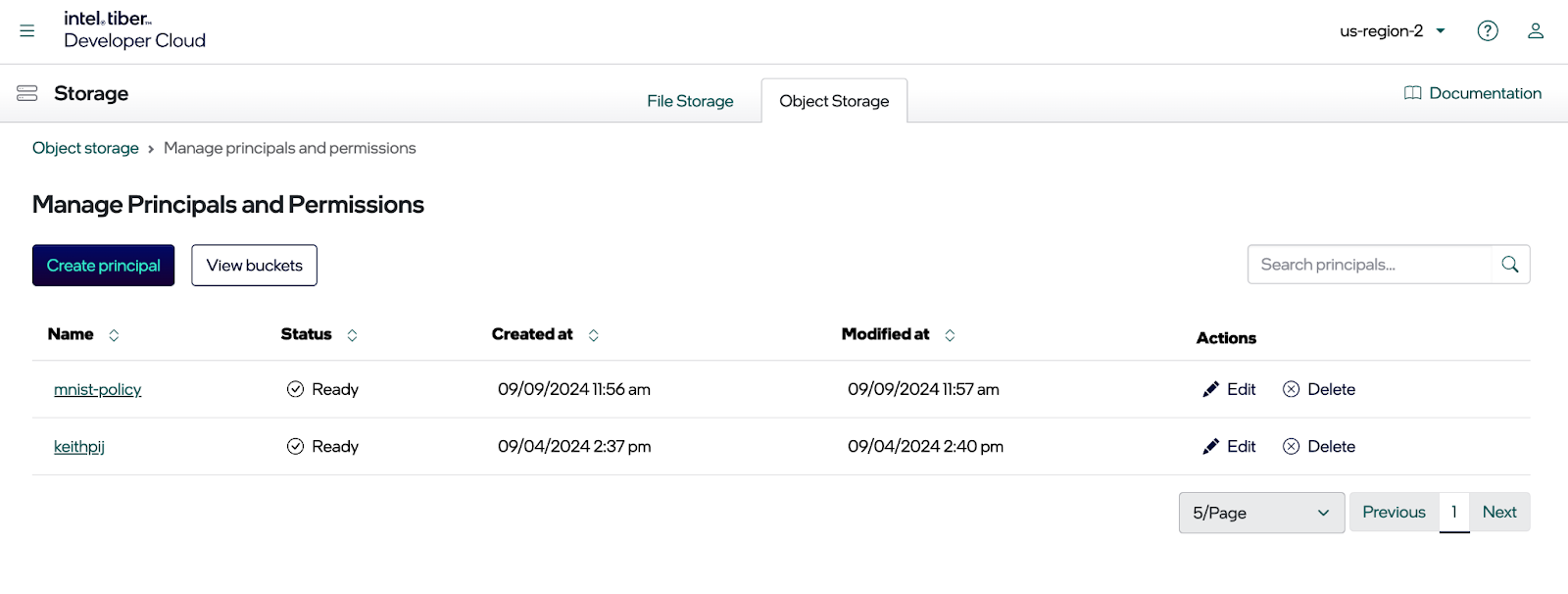
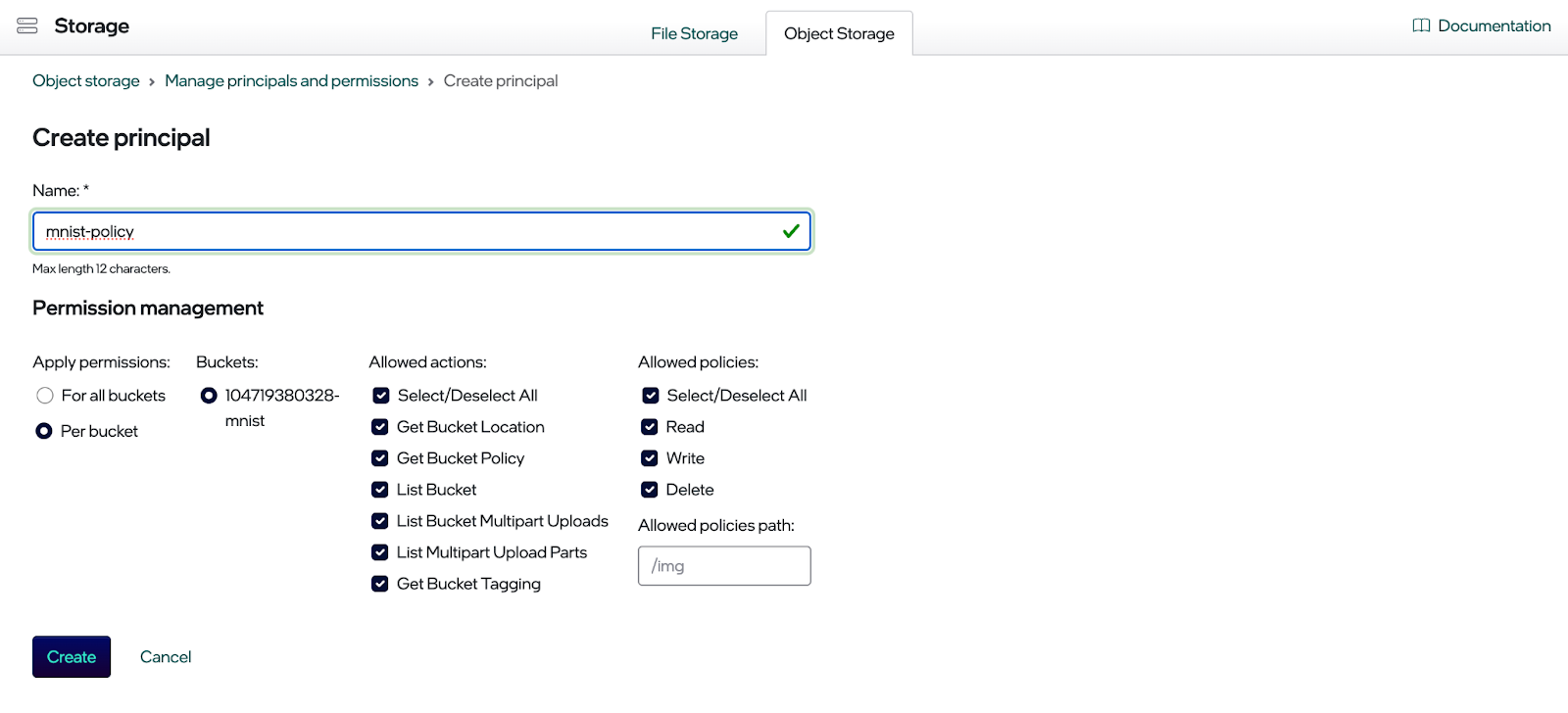
单击“创建主体”按钮。您现在应该会看到创建主体的对话框(见下文)。选择新主体所需的权限,然后单击“创建”按钮。
创建主体后,转到“管理主体和权限”页面,然后单击新创建的主体。
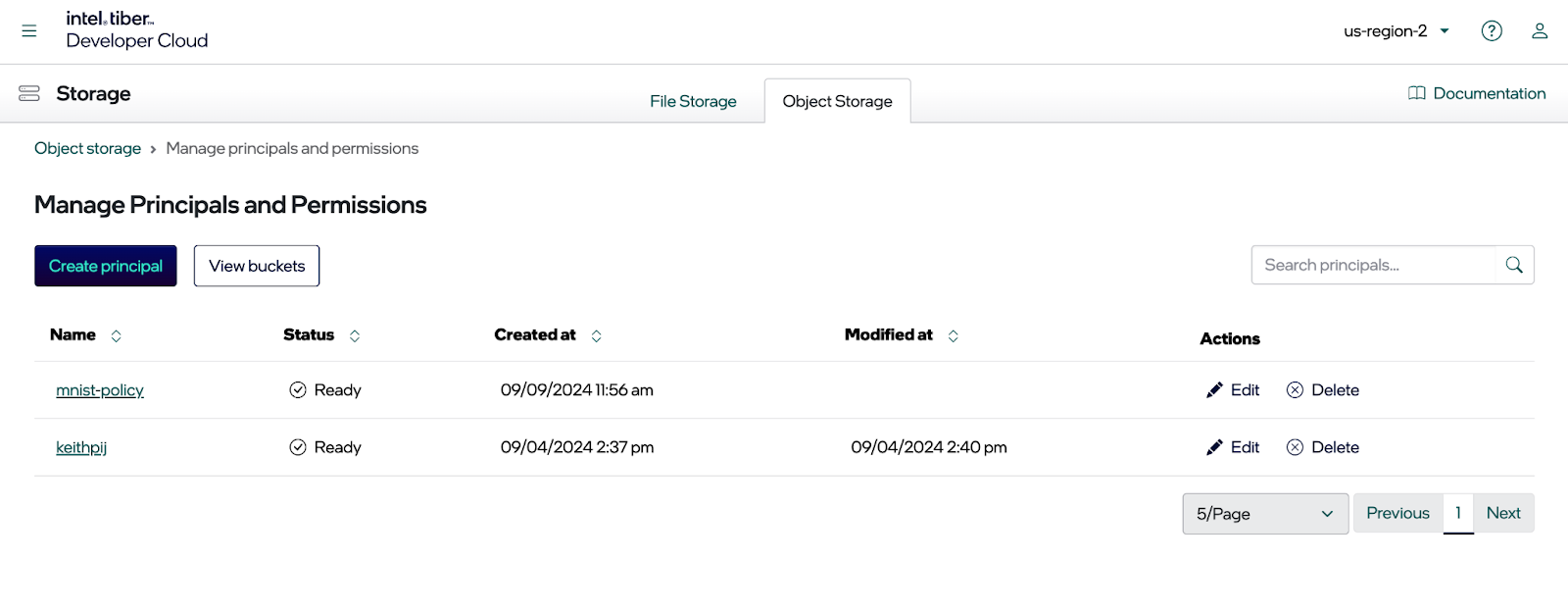
单击主体后,您应该会看到如下所示的对话框。
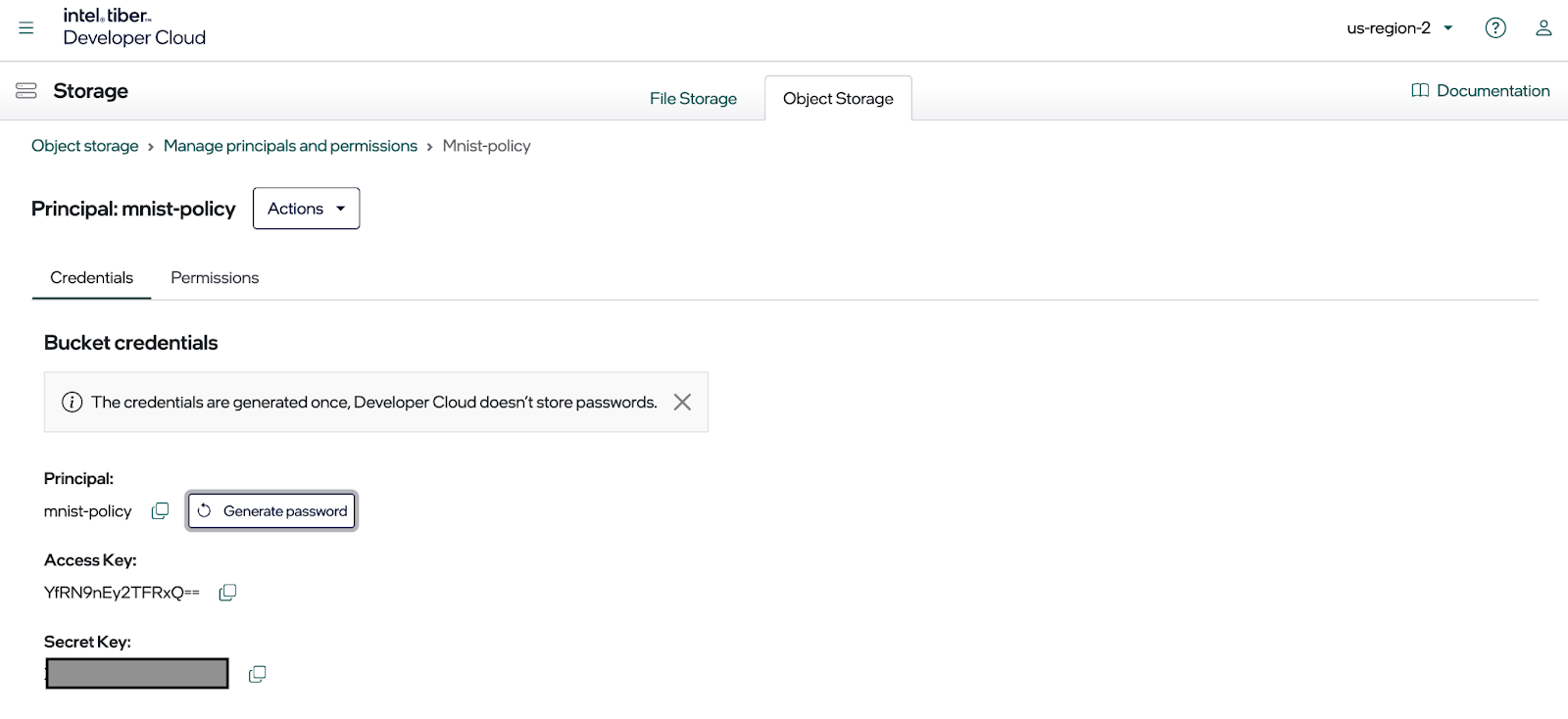
在这里,您可以创建访问密钥和密钥以使用 MinIO SDK(或任何其他符合 S3 的库)访问存储桶。单击“生成密码”按钮以创建密钥,如下所示。立即将它们复制到配置文件中,因为您无法再次显示它们。
本文中代码示例使用的配置文件是 .env 文件,用于设置环境变量。如下所示,将您的私有端点、访问密钥、密钥和存储桶名称放入此文件中。
MINIO_URL=s3-phx04-5.tenantiglb.us-region-2.cloud.intel.com:9000
MINIO_ACCESS_KEY={在此处放置访问密钥。}
MINIO_SECRET_KEY={在此处放置密钥。}
MINIO_SECURE=false
BUCKET_NAME={在此处放置完整的存储桶名称。}
|
现在,创建计算实例和用于训练数据的存储桶后,您就可以编写一些代码了。让我们将 MNIST 数据集上传到我们的新存储桶。
将数据上传到 MinIO
torchvision 包使检索 MNIST 数据集中的图像变得容易。下面的函数使用此包下载一组压缩文件、提取图像并将它们发送到 MinIO。这在下面的代码示例中显示。为了简洁起见,省略了一些支持函数。完整代码可以在本文的代码下载中 data_utlities.py 模块中找到。
import PIL.Image
from dotenv import load_dotenv
from minio import Minio
from minio.error import S3Error
import numpy as np
import PIL
import torch
from torchvision import datasets, transforms
def load_mnist_to_minio(bucket_name: str) -> Tuple[int,int]:
''' Download and load the training and test samples.'''
logger = create_logger()
train = datasets.MNIST('./mnistdata/', download=True, train=True)
test = datasets.MNIST('./mnistdata/', download=True, train=False)
train_count = 0
for sample in train:
random_uuid = uuid.uuid4()
object_name = f'/train/{sample[1]}/{random_uuid}.jpeg'
put_image_to_minio(bucket_name, object_name, sample[0])
train_count += 1
if train_count % 100 == 0:
logger.info(f'{train_count} training objects added to {bucket_name}.')
test_count = 0
for sample in test:
random_uuid = uuid.uuid4()
object_name = f'/test/{sample[1]}/{random_uuid}.jpeg'
put_image_to_minio(bucket_name, object_name, sample[0])
test_count += 1
if test_count % 100 == 0:
logger.info(f'{test_count} testing objects added to {bucket_name}.')
return train_count, test_count
def put_image_to_minio(bucket_name: str, object_name: str,
image: PIL.Image.Image) -> None:
'''
Puts an image byte stream to MinIO.
'''
logger = create_logger()
url, access_key, secret_key, secure = get_minio_credentials()
try:
# Create client with access and secret key
client = Minio(url, # host.docker.internal
access_key,
secret_key,
secure=secure)
image_byte_array = image_to_byte_stream(image)
content_type = 'application/octet-stream'
response = client.put_object(bucket_name, object_name, image_byte_array,
-1, content_type, part_size = 1024*1024*5)
except S3Error as s3_err:
logger.error(f'S3 Error occurred: {s3_err}.')
raise s3_err
except Exception as err:
logger.error(f'Error occurred: {err}.')
raise err |
现在您的数据集已加载到存储桶中,让我们看看如何访问它以训练模型。
从数据加载器使用 MinIO
在您的模型训练管道中,您可以从持久性存储中加载数据有两个地方。如果您的数据完全适合内存,您可以在调用训练函数之前,在训练管道的开头将所有内容加载到内存中。(我们将在下一节中创建此训练函数。)如果您的数据集足够小,可以完全放入内存,则此方法有效。如果您以这种方式加载数据,则您的训练函数将受计算限制,因为它不必进行任何 IO 调用以从对象存储获取数据。
但是,如果您的数据集太大而无法放入内存,则需要在每次将新批次样本发送到模型进行训练时检索数据。这会导致训练函数受 IO 限制。
由于我们想要演示使用 Gaudi 加速器进行模型训练的好处,因此我们将创建一个受计算限制的训练函数。下面显示了创建自定义数据集并将其加载到 Dataloader 中的 Pytorch 代码。请注意,所有数据都加载在 ImageDatasetFull 类的构造函数中。所有 MNIST 图像都从 MinIO 检索并存储在此类创建的对象的属性中。所有这些都在第一次创建对象时发生。如果我们希望在每次将一批数据发送到模型进行训练时加载图像,那么我们需要仅使用对象名称列表创建此对象,并将实际图像的加载移动到 __getitem__() 函数中。
class ImageDatasetFull(Dataset):
def __init__(self, bucket_name: str, X, y, transform=None):
self.bucket_name = bucket_name
self.y = y
self.transform = transform
raw_images = du.get_images_from_minio(bucket_name, X)
images = torch.stack([transform(x) for x in raw_images], dim=0)
self.X = images
def __len__(self):
return len(self.y)
def __getitem__(self, index):
return self.X[index], self.y[index] |
def create_mnist_training_loader(bucket_name: str, loader_type:str, batch_size:int, smoke_test_size: float=0) -> Tuple[Any]:
# 加载时间开始。
start_time = time.perf_counter()
# 定义一个转换函数来标准化数据
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
# 获取对象列表并根据训练集和测试集进行分割。
X_train, y_train, _, _ = du.get_mnist_lists(bucket_name)
如果 smoke_test_size > 0:
train_size = int(smoke_test_size*len(X_train))
X_train = X_train[0:train_size]
y_train = y_train[0:train_size]
train_dataset = ImageDatasetFull(bucket_name, X_train, y_train, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=1)
返回 train_loader, (time.perf_counter()-start_time) |
现在我们已经将数据加载到内存中,让我们看看如何使用 Gaudi2 和 Intel 开发者云来训练模型。
使用 PyTorch 中的 Intel Gaudi 加速器
PyTorch HPU 包支持英特尔的异构计算处理(HPU)工具。通常,HPU 允许开发者编写针对英特尔一系列硬件(例如 CPU、Gaudi 加速器、GPU 以及英特尔可能构建的任何未来加速器)优化的 PyTorch 应用程序。HPU 抽象使用 PyTorch 提供的通用接口。因此,开发者可以编写代码,在不同的硬件加速器之间动态切换,而无需进行大规模重构。本文将使用它来检测 Gaudi 并将张量移动到 Gaudi 的内存中。
使用任何类型的加速器时,一种常见的编码模式是首先检查 GPU 或 AI 加速器是否存在,如果存在,则将模型、训练集、验证集和测试集移动到处理器的内存中。这通常在训练模型的函数中完成。以下函数来自本文的代码下载。(此函数是我之前提到的训练函数。)突出显示的代码显示了如何检查英特尔加速器是否存在并将模型和训练集移动到设备。为了使此检查与 Gaudi 正确配合使用,您需要以下导入。您不会直接使用此模块,但需要导入它。
import habana_frameworks.torch.core as htcore
请注意,将包含特征和标签的张量从训练集中移动的操作是在批处理循环内完成的。PyTorch 数据加载器没有用于将整个数据集移动到目标设备的“to”函数。这样做是有充分理由的:大型数据集会很快耗尽处理器的内存。对于内存比新 GPU 少的旧 GPU 来说,尤其如此。最佳实践是在模型需要它们进行训练之前,仅将当前训练批次所需的张量移动到加速器。
def train_model(model: nn.Module, loader: DataLoader, training_parameters: Dict[str, Any]) -> List[float]:
logger = du.create_logger()
device = torch.device('hpu' if torch.hpu.is_available() else 'cpu')
model.to(device)
logger.info(f'Model created on device {device}')
loss_func = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=training_parameters['lr'], momentum=training_parameters['momentum'])
# Epoch loop.
compute_time_by_epoch = []
for epoch in range(training_parameters['epochs']):
total_loss = 0
batch_count = 0
total_epoch_compute_time = 0
# Batch loop.
for images, labels in loader:
# Start of compute time for the batch.
start = time.perf_counter()
# Move to the specified device.
# shape = [32, 1, 28, 28]
images, labels = images.to(device), labels.to(device)
# Flatten MNIST images into a 784 long vector.
# shape = [32, 784]
images = images.view(images.shape[0], -1)
# Training pass
optimizer.zero_grad()
output = model(images)
loss = loss_func(output, labels)
loss.backward()
optimizer.step()
# Loss calculations
total_loss += loss.item()
batch_count +=1
# Track compute time
total_epoch_compute_time += time.perf_counter() - start
compute_time_by_epoch.append(total_epoch_compute_time)
logger.info(f'Epoch {epoch+1} - Training loss: {total_loss/batch_count}.')
return compute_time_by_epoch |
现在我们已经了解了如何将模型和张量从数据加载器移动到 Gaudi,以及如何从对象存储获取数据,让我们将所有内容整合在一起并运行几个实验。
整合所有内容
下面的函数将所有内容整合在一起。它将创建我们的数据加载器并将它们传递给我们的 train_model 函数。请注意,所有内容都已进行检测,以便从我们的代码中获取性能指标。运行此函数后,我们将看到 IO 时间与计算时间。我们还可以使用仅 CPU 运行相同的代码,然后再次使用 Gaudi 运行。
def setup_local_training(training_parameters: Dict[str, Any], loader_type: str):
logger = du.create_logger()
device = torch.device('hpu' if torch.hpu.is_available() else 'cpu')
logger.info(f'PyTorch Version: {torch.__version__}')
logger.info(f'Using device: {device}')
#train_data, test_data, load_time_sec = ru.get_ray_dataset(training_parameters)
train_loader, load_time_sec = tu.create_mnist_training_loader(
training_parameters['bucket_name'], loader_type,
training_parameters['batch_size'])
logger.info(f'Data Loader Creation Time (in seconds) = {load_time_sec}')
# Train the model and log training metrics.
model = tu.MNISTModel(training_parameters['input_size'],
training_parameters['hidden_sizes'],
training_parameters['output_size'])
start_time = time.perf_counter()
compute_time_by_epoch = train_model(model, train_loader, training_parameters)
training_time_sec = time.perf_counter() - start_time
compute_time_sec = 0
for epoch_time in compute_time_by_epoch:
compute_time_sec += epoch_time
logger.info(f'Compute Time (in seconds) = {compute_time_sec}')
logger.info(f'I/O Time (in seconds) = {training_time_sec - compute_time_sec}')
logger.info(f'Total Training Time (in seconds) = {training_time_sec}')
test_loader, load_time_sec = tu.create_mnist_testing_loader( training_parameters['bucket_name'], loader_type, training_parameters['batch_size'])
tu.test_model_local(model, test_loader, training_parameters) |
下面的代码片段将调用此函数并传入相应的超参数。
# 超参数
training_parameters = {
'batch_size': 32,
'bucket_name': BUCKET_NAME,
'epochs': 3,
'hidden_sizes': [1024, 1024, 1024, 1024],
'input_size': 784,
'lr': 0.025,
'momentum': 0.5,
'output_size': 10,
'smoke_test_size': 0,
'use_gpu': False,
}
setup_local_training(training_parameters, 'full') |
在我们的计算实例上使用 `use_gpu = False` 运行上面的设置函数,得到以下输出。
INFO | 数据集大小:60000 个样本。 INFO | 使用设备:cpu INFO | 模型已移动到设备:cpu INFO | Epoch 1 - 训练损失:0.4534 - 计算时间:15.3998 IO 时间:7.3033。 INFO | Epoch 2 - 训练损失:0.1475 - 计算时间:14.7520 IO 时间:7.4030。 INFO | Epoch 3 - 训练损失:0.1046 - 计算时间:15.1024 IO 时间:7.6316。 INFO | 计算时间(秒)= 45.2544 INFO | I/O 时间(秒)= 22.3410 INFO | 总训练时间(秒)= 67.5955 INFO | 总实验时间(秒)= 67.6832 |
使用 Gaudi 运行相同的代码会产生输出,显示我们的计算时间显著减少。
INFO | 数据集大小:60000 个样本。 INFO | 使用设备:hpu INFO | 模型已移至设备:hpu INFO | Epoch 1 - 训练损失:0.4521 - 计算时间:3.5001 IO 时间:8.0007。 INFO | Epoch 2 - 训练损失:0.1481 - 计算时间:3.4549 IO 时间:7.8584。 INFO | Epoch 3 - 训练损失:0.1035 - 计算时间:3.8153 IO 时间:8.0103。 INFO | 计算时间(秒)= 10.7705 INFO | I/O 时间(秒)= 29.7047 INFO | 总训练时间(秒)= 40.4752 INFO | 总实验时间(秒)= 40.5629 |
以上结果尤其有趣,因为快速的加速器可以将计算受限的训练工作负载(计算时间最长)转变为 IO 受限的训练工作负载(数据访问时间最长)。证明必须将快速加速器与快速网络和快速存储一起使用。
总结
在这篇文章中,我展示了如何为机器学习实验设置 Intel Tiber 开发者云。这包括创建帐户、设置计算实例、创建 MinIO 存储桶和设置 SSH 密钥。创建完资源后,我展示了如何编写一些函数来上传和检索数据。我还讨论了适合内存的小型数据集和不适合内存的大型数据集的数据加载注意事项。
使用英特尔的 Gaudi 加速器非常简单,开发人员会识别 PyTorch 中 hpu 包的接口。我展示了检测 Gaudi 并将张量移动到其中的基本代码。最后,我使用 CPU 和 Gaudi 加速器训练了一个实际模型。这两个实验证明了 Gaudi 的性能提升,并为使用快速加速器时使用快速存储和快速网络提供了依据。
