利用 SVE 将 ARM 整合到 MinIO 的 AI 数据基础设施中

MinIO 性能如此出色的原因之一是,我们完成了其他人不愿或无法完成的细致工作。从 SIMD 加速到 AVX-512 优化,我们都处理了最棘手的问题。最近针对 ARM CPU 架构(特别是可扩展矢量扩展 (SVE))的开发,为我们提供了机会,可以在性能和效率方面获得显著提升,超越以往几代产品,并使 ARM 成为 AI 数据基础设施生态系统中的一等公民。
这篇博文将概述 ARM SVE 是什么以及它对 MinIO 服务器的重要性,以及我们是如何实现它的。
ARM 粉丝
我们一直是 ARM CPU 架构的粉丝,因此从 MinIO 的早期阶段就开始支持 ARM。由于当时没有提供 ARM CPU 的云实例,因此最初的开发实际上是在 Pine64 开发板上完成的。大部分工作包括添加 128 位 NEON 矢量指令,以加速 MinIO 的一些核心算法,最值得注意的是擦除编码部分、位腐烂检测(Highway Hash)和各种散列技术,如 Blake2b 和 SHA256。
我们发布了一些关于这些主题的博文,例如 在 ARM 上将 Golang 中的 SHA256 加速 100 倍。此外,我们在 2020 年对 Intel (amd64) 和 ARM (arm64) 平台进行了一些基准测试,请参阅 英特尔与 ARM CPU 性能对对象存储的影响。我们鼓励您了解这项工作,因为它在该领域具有开创性。
云端的发展:从 AWS 到 GCP 和 Azure
随着 2019 年 Graviton 1 的推出,AWS 是第一家开始基于 ARM 架构设计自己 CPU 的云供应商。从那时起,又推出了三个版本,最新版本是 Graviton 4,它提供 96 核。
最近今年,谷歌和微软也纷纷效仿,宣布了谷歌的 Axion 处理器以及 Azure 的 Cobalt 100 处理器。对于这两家供应商来说,这样做的主要驱动力是提供更好的性能和更高的能效。
最后但并非最不重要的一点是,英伟达正在与 ARM 密切合作,首先是 GH200 Grace Hopper,现在是 GB200 Grace Blackwell 超级芯片。这两种超级芯片都将双 GPU 与支持 SVE2 的 72 核 ARM CPU 相结合。
英伟达正在投资的另一个领域是“智能”网络控制器或 DPU(数据处理单元)方面,鉴于计算和存储的异构性,这是一个关键组件。最新一代的 BlueField3 NIC 将一个集成的 16 核 ARM CPU 作为网络控制器卡本身的一部分。这有可能通过将 NVMe 驱动器直接连接到网络卡并完全绕过任何(主服务器)CPU 来简化服务器设计。
关于 SVE 的简要介绍
NEON 已经存在了 10 多年,并且“仅”支持 128 位宽的矢量指令(仅比常规的 64 位指令宽 2 倍),而首先是 SVE,最近是 SVE2,提供了更广泛的功能范围。
最有趣的是(与 Intel/amd64 SIMD 架构相比),SVE/SVE2 是一种长度无关的 SIMD 架构。这意味着相同的机器代码指令可以在具有不同大小矢量单元的硬件实现上运行。例如,AWS 上的 Graviton 3 实现是 256 位宽,而 Fujitsu A64FX 处理器是 512 位宽的实现。
除此之外,SVE 还通过预测执行支持通道屏蔽,从而可以更有效地利用矢量单元。对散射和收集指令的广泛支持使得能够以灵活的方式有效地访问内存。
SVE 以及现在的 SVE2 与 NEON 相比,具有更广泛的指令集和类型系统,从而可以应用于更广泛的应用。另请注意,SVE 不是 NEON 的超集,而是一个全新的 ISA(指令集架构)。
MinIO 的 ARM SVE 支持
我们很高兴地宣布,我们通过为两种关键算法(即擦除编码和位腐烂检测)添加 SVE 支持,扩展了对 ARM CPU 架构的支持,如下所述。
里德-所罗门码
对于版本 v1.12.2,我们为 MinIO 对象存储服务器使用的擦除编码库贡献了广泛的 ARM SVE 支持。“模仿”AVX2 实现,我们现在能够利用为 ARM SVE 完成的所有优化工作。
一般来说,新的 SVE 实现比以前的实现快大约 2 倍,如该图所示
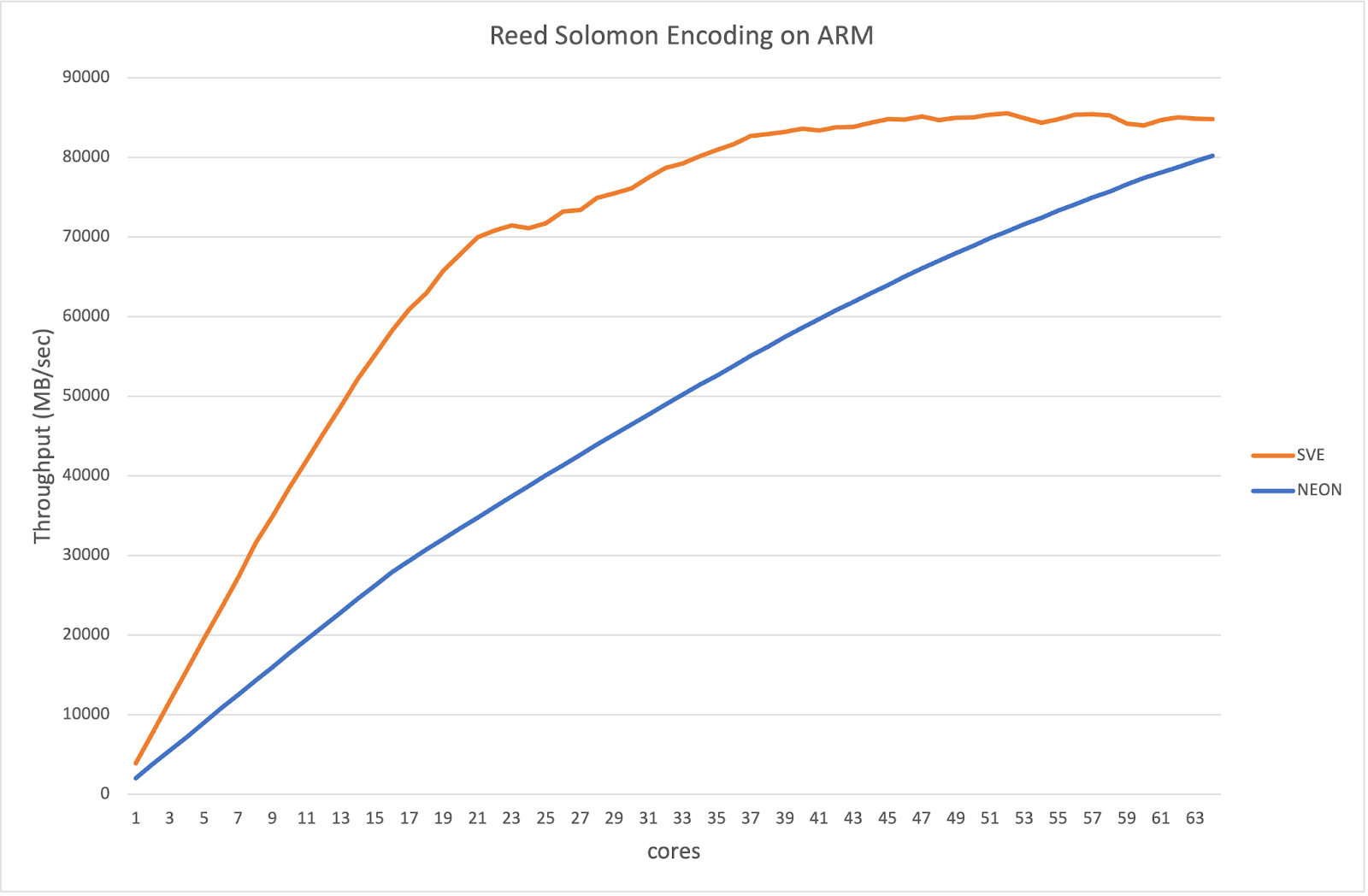
可以看出,在仅使用四分之一的可用核心(大约 16 个)时,就已经消耗了内存带宽的一半(这在大约之前需要一半的核心数)。性能继续扩展,并在使用 64 个核心中的 32 个左右时开始达到峰值。
Highway Hash
MinIO 使用 Highway Hash 算法进行位腐烂检测,该算法在 GET(读取)和 PUT(写入)操作期间都非常频繁地运行。在这里,我们也为核心散列更新函数添加了 SVE 支持,结果如下
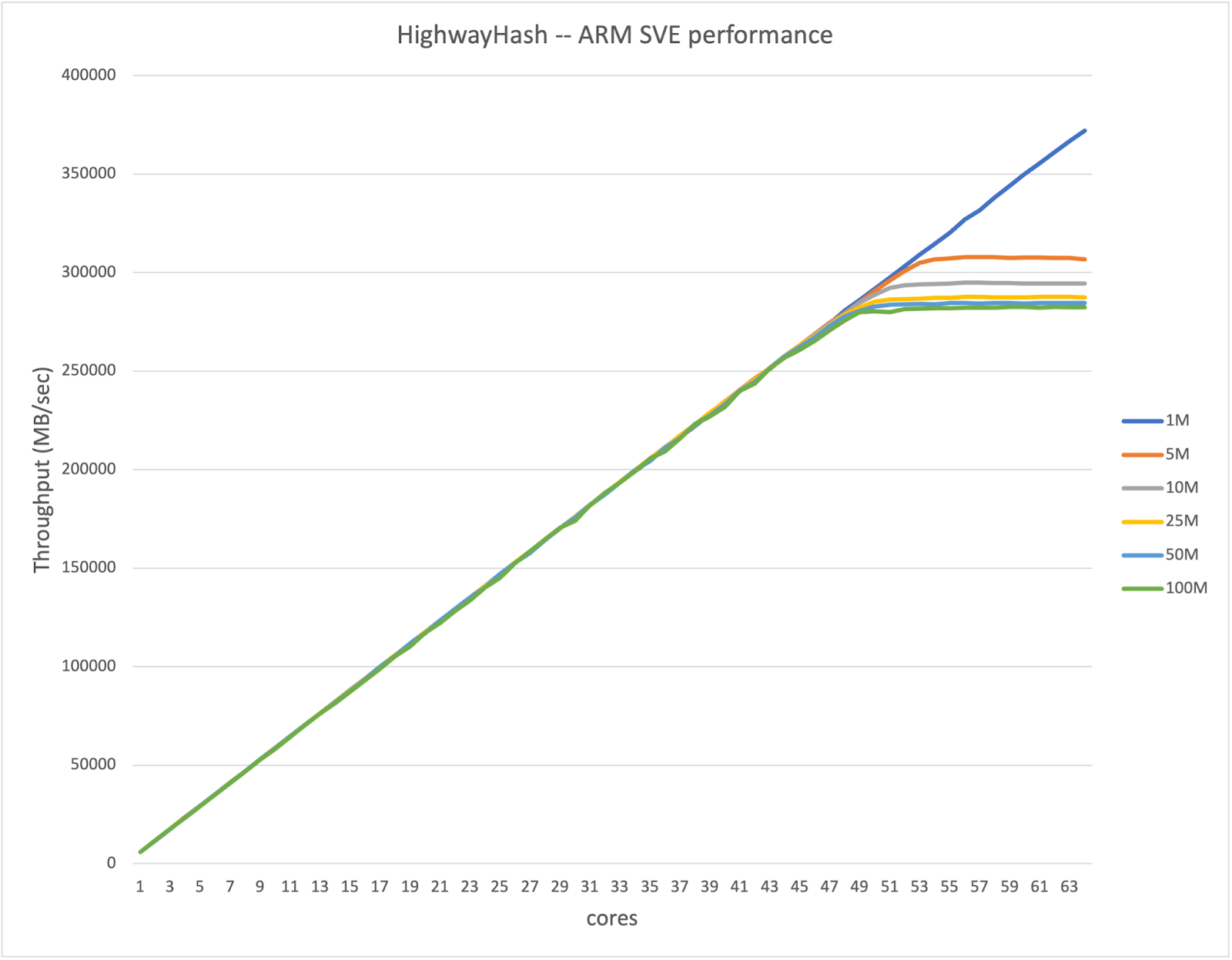
从图表中可以明显看出,随着核心数量的增加,性能完美地线性扩展,并且对于较大的块大小,在 50 到 52 个核心左右开始达到内存带宽限制。
请注意,还有一个稍微更快的 SVE2 算法,我们尚未在硬件中进行测试(仅通过 armie 指令模拟器)。因此,这应该会将性能再提高 10% 左右。
更多内容即将推出
我们正在研究一些进一步的优化,例如最近出现在 Linux 内核中的一些优化,敬请期待。
结论
ARM SVE 标志着一项重大的技术改进,它可以为对象存储和 AI 数据基础设施带来实际的性能提升。随着越来越多的基于 ARM SVE 的解决方案进入市场,我们很高兴看到这项技术将如何继续发展和改进。