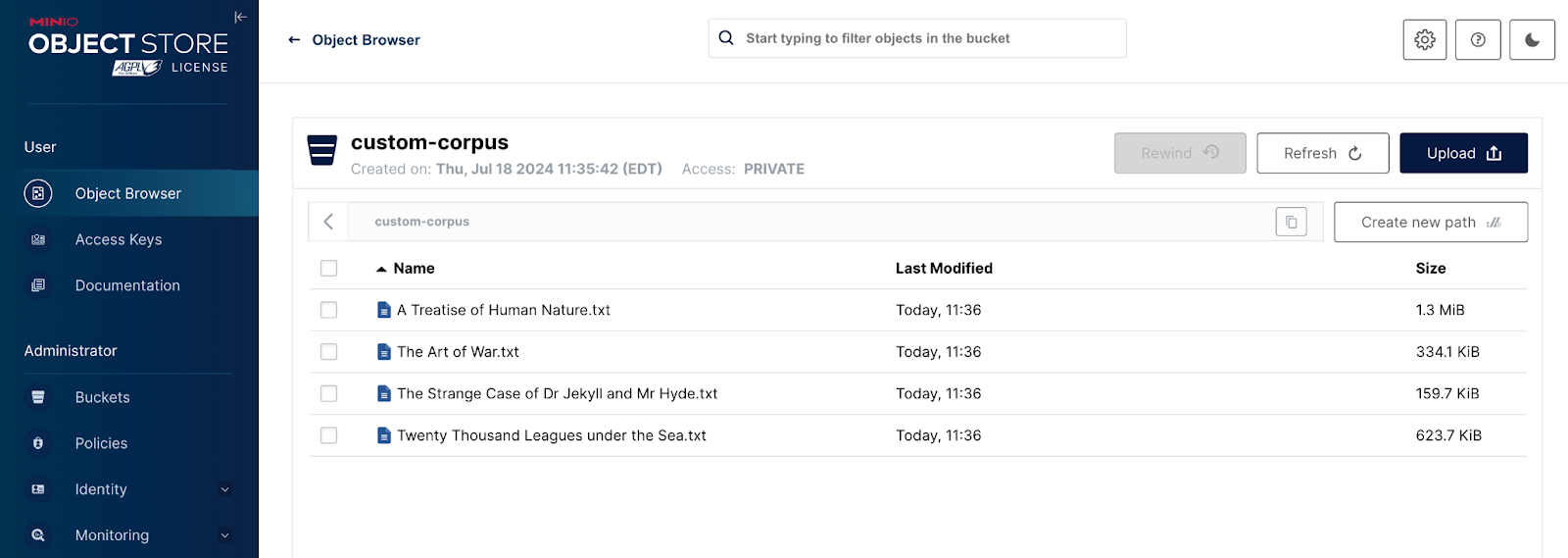
不要被模型的名称所迷惑。它一点也不小。它有 1.4GB。我们需要下载此模型并将其上传到 MinIO。这是一个一次性设置任务,以便在分布式环境中为实验准备此模型。不幸的是,我们需要的 Hugging Face 函数(snapshot_download)没有 S3 接口,因此我们将使用 MinIO Python SDK 将模型上传到 MinIO。另一个复杂之处在于 Hugging Face 模型不是单个文件。它是一组文件,这些文件会被下载到指定的目录中。我们必须将整个目录上传到 MinIO,并使用 MinIO 路径保留文件夹结构。这使用下面显示的“upload_model_to_minio”函数完成。
from huggingface_hub import snapshot_download defupload_model_to_minio(bucket_name: str, full_model_name: str, revision: str) -> None: ''' Download a model from Hugging Face and upload it to MinIO. This function will use the current systems temp directory to temporarily save the model. ''' # Create a local directory for the model. #home = str(Path.home()) temp_dir = tempfile.gettempdir() base_path = f'{temp_dir}{os.sep}hf-models' os.makedirs(base_path, exist_ok=True) # Get the user name and the model name. tmp = full_model_name.split('/') user_name = tmp[0] model_name = tmp[1] # The snapshot_download will use this pattern for the path name. model_path_name=f'models--{user_name}--{model_name}' # The full path on the local drive. full_model_local_path = base_path + os.sep + model_path_name + os.sep + 'snapshots' + os.sep + revision # The path used by MinIO. full_model_object_path = model_path_name + '/snapshots/' + revision print(f'Starting download from HF to {full_model_local_path}.') snapshot_download(repo_id=full_model_name, revision=revision, cache_dir=base_path) print('Uploading to MinIO.') upload_local_directory_to_minio(full_model_local_path, bucket_name, full_model_object_path) shutil.rmtree(full_model_local_path)
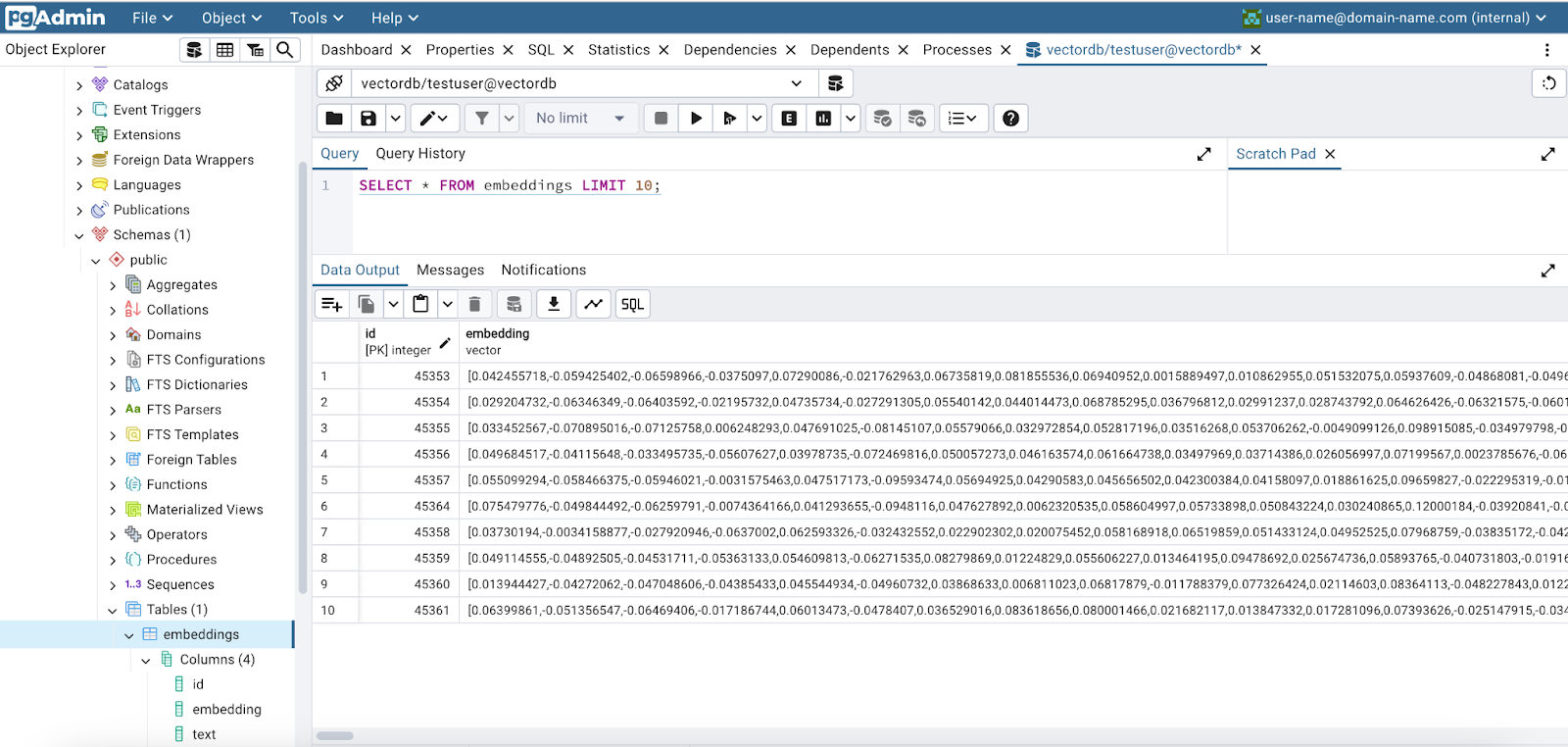
'The Strange Case of Dr Jekyll and Mr Hyde.txt') file = open(temp_file, 'r') data = file.read() chunks = chunker.split_text(data) print('Number of chunks:', len(chunks)) print('Length of the first chunk:', len(chunks[0])) embeddings = embedding_model.encode(chunks, batch_size=BATCH_SIZE).tolist() print('Number of embeddings:', len(embeddings)) print('Length of the first embedding:', len(embeddings[0])) eu.save_embeddings_to_vectordb(chunks, embeddings)
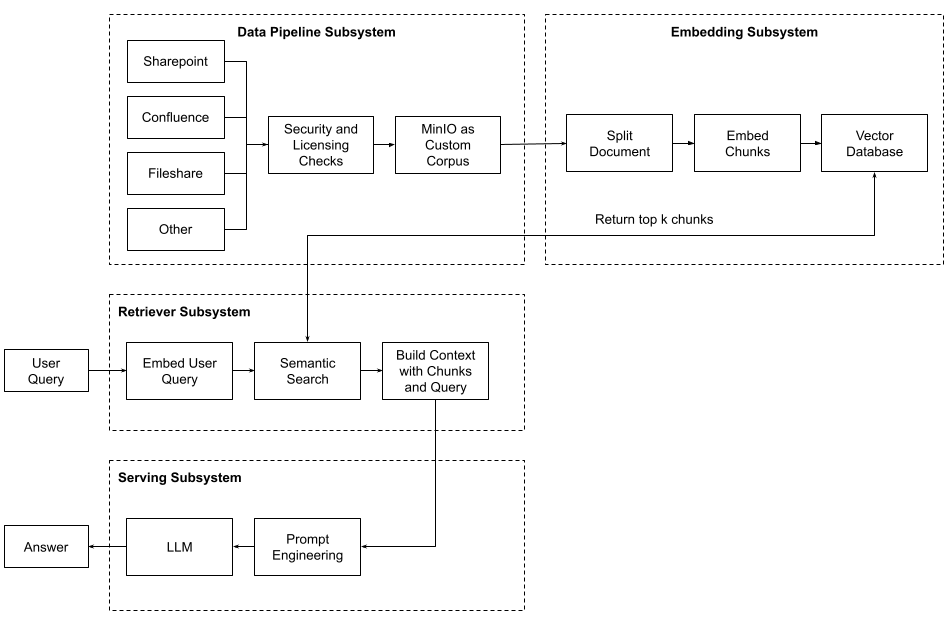
在我们的演示中,我们正在创建一个本地 Ray 实例。我没有使用 Kubernetes 集群。这是在迁移到真实集群之前使代码工作的最佳方法。我们还没有创建任何 Ray Actor,但我们正在发送 Ray 配置信息,这些信息告诉 Ray 每个 Actor 需要哪些环境变量和库。
接下来,我们创建一个 Ray 数据集来保存我们想要发送到 Embed 类实例的所有数据,这些实例将在每个 Ray Actor 中运行。在我们的例子中,每个 Ray Actor 将接收存储在 MinIO 中的对象引用列表(文档的路径)。我们将使用我们上面描述的函数库中的 “get_object_list” 函数。从 “ray.data.from_items()” 返回的 Ray 数据集包含逻辑,该逻辑将把此列表转换为较小的批次,以便在启动分布式嵌入过程时将其发送到每个 Actor。
# 嵌入类需要 bucket_name 和 document_name 对 - 因此将 bucket name 添加到列表中的每个条目。 document_list = eu.get_object_list(BUCKET_NAME) list_for_ray = [[BUCKET_NAME, doc] for doc in document_list] ray_ds = ray.data.from_items(list_for_ray) print(type(ray_ds)) print(ray_ds.schema)
我们几乎准备好进行一些分布式计算,但还有一个编码任务需要完成。我们需要将 Ray 数据集映射到我们的 Embed 类,并告诉 Ray 如何为该工作负载设置我们之前初始化的集群。这是使用 Ray 数据集的 “map_batches” 方法完成的。您可以向 “map_batches” 发送函数或可调用类。如果您发送函数,Ray 数据将使用无状态 Ray 任务。对于类,Ray 数据将使用有状态 Ray Actor。
请注意,我们正在传入需要为每个 Actor 实例化的 Embed 类。我们还指定了 Actor 的数量、对每个 Actor 的调用的批次大小,以及最后每个 Actor 可访问的 GPU 和 CPU 的数量。map_batches 方法返回另一个 Ray 数据集 (ds_embed),该数据集包含所有 Actor 的所有返回值。这是一个来自 Embed 中 “__call__” 方法的返回值的集合。
最后,我们准备启动分布式嵌入作业。您可能已经注意到,之前的命令运行得非常快。这是因为还没有发生任何计算。Ray 中的转换 (map_batch 被认为是一种转换) 是 “延迟的”。它们只有在您通过迭代数据集、保存数据集或检查数据集的属性来触发数据消耗时才会执行。因此,我们需要向 ds_embed 请求我们 Actor 的返回值。这是在下面完成的。下面的代码段将需要一些时间来运行。
[('A Treatise of Human Nature.txt', 75.08733916282654), ('The Art of War.txt', 21.960258722305298), ('The Strange Case of Dr Jekyll and Mr Hyde.txt', 10.052802085876465), ('Twenty Thousand Leagues under the Sea.txt', 39.24100613594055)]