使用 MinIO 和 Redpanda 构建流式 CDC 管道到 Snowflake


数据驱动的组织通常需要将数据从传统的关联数据库管理系统 (RDMS) 迁移到现代数据湖中,用于分析工作负载、从云端回迁数据、作为集中式数据策略的一部分以及其他原因。变更数据捕获 (CDC) 是一种实现此目标的关键模式,它通过将 RDMS 中的更改复制到数据湖仓储,然后将这些更改提供给云原生分析和 AI/ML 应用程序。
毫无疑问,Apache Kafka 在十年前发布时具有开创性意义。Kafka 仍然嵌入在许多数据架构和集体意识中。但是,处理 Zookeeper 和 JVM 的现实问题可能会很乏味且困难。随着时间的推移,出现了新的参与者,他们消除了这种额外的复杂性,Redpanda 就是一个突出的替代方案。
在本博文中,我们将演示如何使用 Redpanda 和 MinIO 设置一个流式 CDC 管道,其中 MinIO 成为数据湖存储,用于通过外部表访问Snowflake。本教程基于Redpanda 的 GitHub 项目。克隆此存储库以继续学习。
介绍我们的 CDC 架构
在我们深入编码之前,让我们先从更高的层次思考一下此 CDC 模式中的组件,以便了解各个组件以及它们如何协同工作。
- PostgreSQL 作为源数据库的替代。
- Redpanda 作为流式数据平台。
- Debezium 作为变更数据捕获 (CDC) 代理。
- MinIO 作为对象存储。
- Snowflake 作为云原生分析引擎。
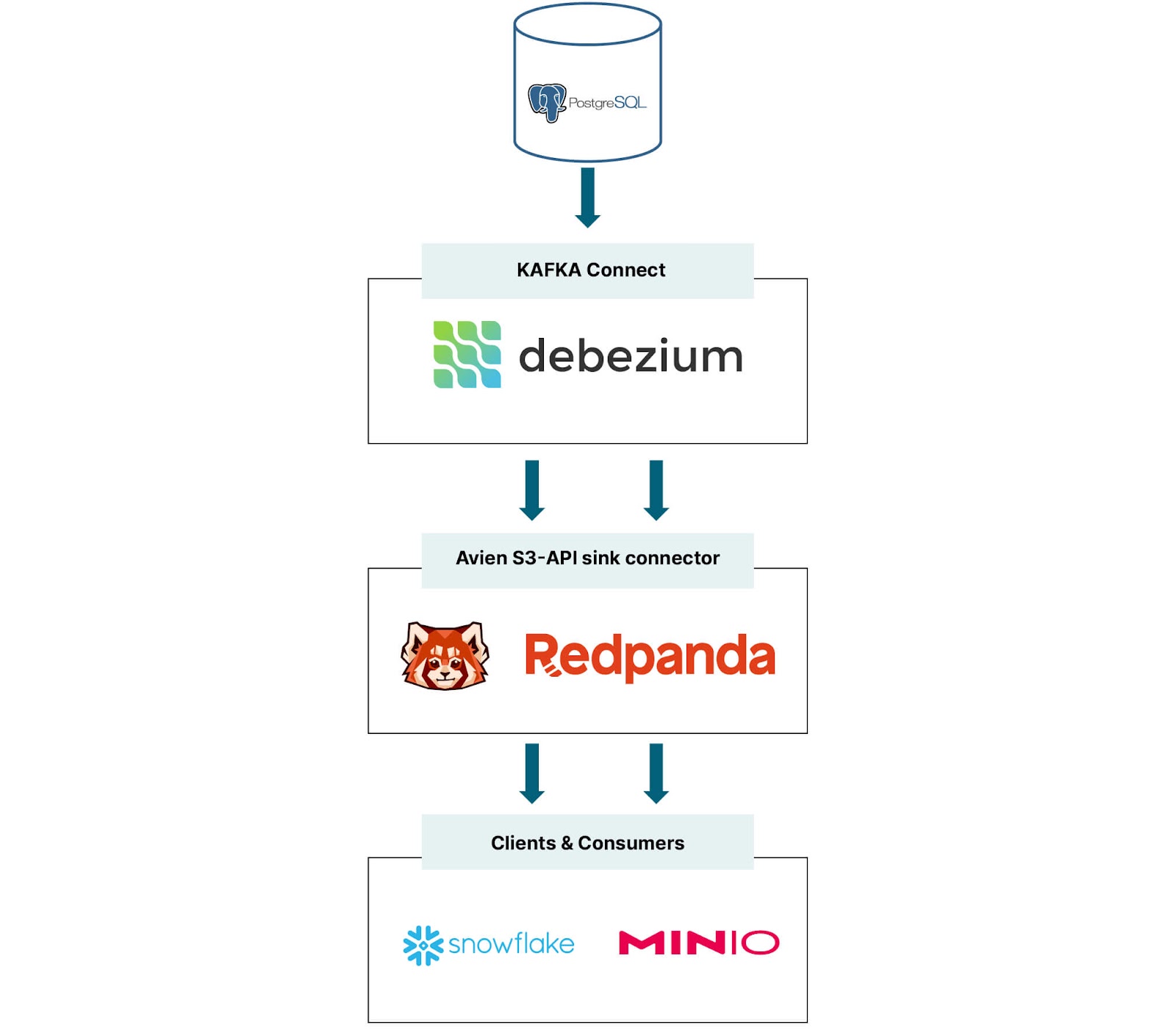
Redpanda 是一个轻量级、单二进制、与 Kafka API 兼容的流式平台。Redpanda 非常适合从 RDMS 进行 CDC,原因还有几个。首先,Redpanda(与 Kafka 不同)采用了列式数据存储格式,此选择提高了存储效率,并实现了更快的查询响应时间,并允许他们在流式数据上支持类似 SQL 的查询。这些功能应该让用户在 Redpanda 中轻松使用 SQL。其次,Redpanda 在可扩展性方面表现出色,可以适应水平和垂直扩展,确保您的基础设施能够随着数据量和团队规模的增长而增长。
Debezium 通过维护一个事务日志来履行其职责,该日志勤勉地跟踪对数据库中每个表所做的所有更改。这使得 Redpanda 等应用程序能够高效地访问和读取必要的事务日志,确保它们按事件发生的精确顺序接收事件。
MinIO 在其架构和操作的简单性、性能 和可扩展性方面与 Redpanda 保持一致。利用 MinIO 作为来自关键任务 RDMS 的更改数据的存储与现代数据湖结构无缝对齐,该结构允许在数据驻留的任何位置访问数据,而无需进行摄取;无论是在本地、私有云或公有云、边缘还是裸机上。
Snowflake 充当我们的分析引擎,位于 MinIO 之上,访问与 S3 API 兼容的存储以检索用于分析的数据,而无需直接摄取。云原生且安全,MinIO 构成了强大的云策略的基础,该策略使数据保持在您的控制之下。
先决条件
您需要Docker Compose。您可以分别安装 Docker Engine 和 Docker Compose 的二进制文件,也可以在 Docker Desktop 中一起安装。
通过运行以下命令检查您是否已安装 docker compose
docker compose version数据生成
在本教程中,我们将假设您有一个功能齐全的关系数据库,其中包含您想要捕获的 CRUD 操作(插入、更新或删除)。在本教程中,我们将使用 PostgreSQL 作为系统的替代。
在将 PostgreSQL 用于 CDC 时,请将“wal_level”参数配置为“logical”。此调整使您能够利用 PostgreSQL 的逻辑复制功能。需要注意的是,此设置使 Debezium 能够访问和解释数据库的事务日志,从而实现更改事件的生成。
如果您想使用自己的数据库而不是 PostgreSQL,则不必运行下一部分,但您必须修改硬编码在pg-src.json 文件中的连接详细信息。
要使用替代数据库,请首先在您克隆教程文件所在的目录中运行以下命令。
docker-compose up -d postgres datagen此命令将启动一个 Postgres 容器,创建两个名为“user”和“payment”的测试表,并执行一个 Python 脚本,该脚本将每隔几秒钟开始使用随机数据填充这些表。
SELECT * FROM public.user LIMIT 3;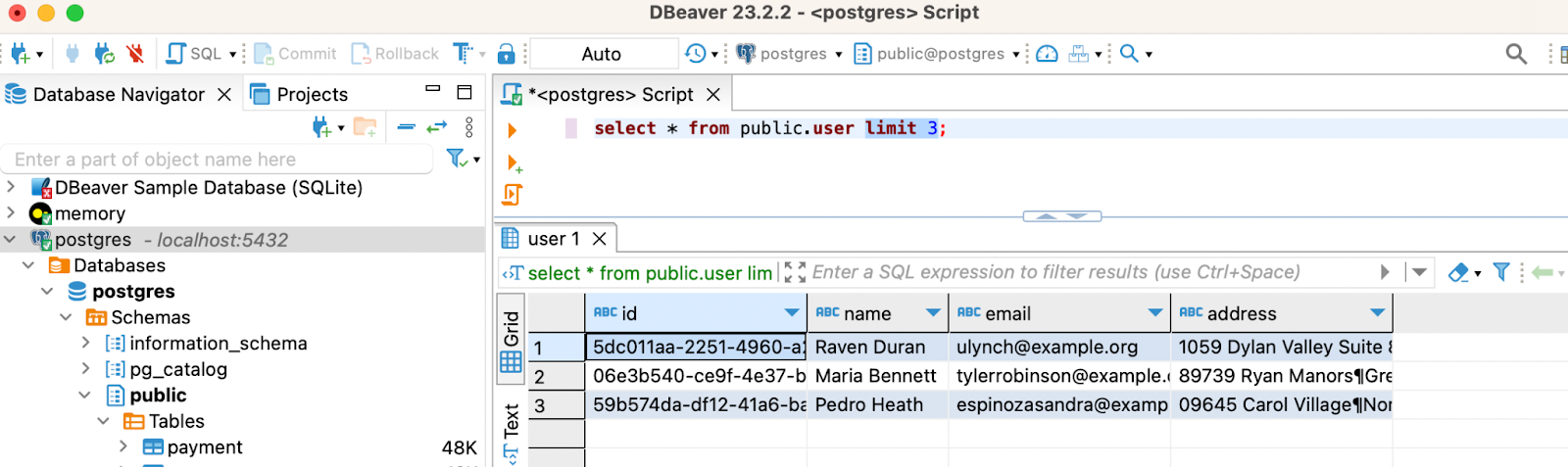
您应该会看到表中填充了数据。
设置 Redpanda 和 Debezium
Redpanda、Debezium 及其所有依赖项都组合在docker-compose.yml 中。使用以下命令在教程目录中启动 Redpanda 和 Redpanda 控制台。
docker-compose up -d redpanda redpanda-console connect您可以通过导航到https://:8080 上的控制台来检查您的 Kafka Connect 集群是否正在运行。
验证 Redpanda 正在运行后,进入 connect 容器。
docker exec -it connect /bin/bash然后运行以下命令以创建 Debezium PostgreSQL 连接器和 Avien(如下所述)连接器。
curl -X PUT -H "Content-Type:application/json" localhost:8083/connectors/pg-src/config -d '@/connectors/pg-src.json'
curl -X PUT -H "Content-Type:application/json" localhost:8083/connectors/s3-sink/config -d '@/connectors/s3-sink.json'刷新并导航到“连接器”面板以查看您的新连接器。
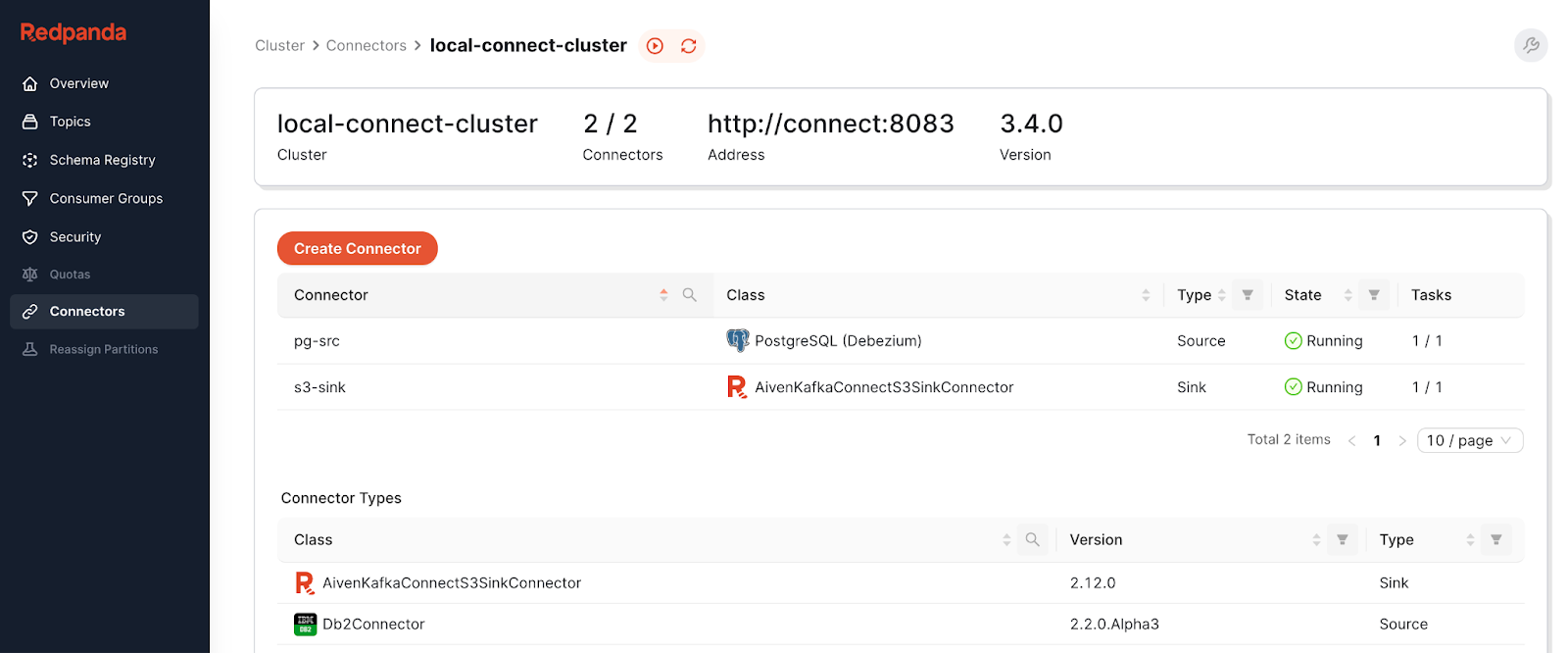
我们已经探讨了 Debezium 在此模式中的功能,但到目前为止,Avien 尚未提及。Avien 创建了一个S3-API 接收器连接器,允许您将数据从 Kafka 集群(如 Redpanda)移动到与 S3 兼容的存储中,例如 MinIO。
设置 MinIO
您可能已经有一个 MinIO 服务器正在运行。如果是这种情况,并且您想使用此服务器,请确保它可供您创建的 Redpanda 容器使用,编辑s3-sink.json 中的连接详细信息,并跳过以下步骤。
如果您想使用教程的容器,请运行以下命令以启动一个单节点 MinIO 服务器
docker-compose up -d minio mc导航到“localhost:9000”并登录。此项目中 .yml 中的默认凭据是用户名:minio,密码:minio123。您将开始看到对象填充您的存储桶。
使用 Snowflake 查询数据
现在,我们将偏离原始 Redpanda 教程,探索外部表 与 Snowflake 的结合。首先,我们需要在 MinIO 中为 Snowflake 创建访问密钥。在生产环境中,最佳实践是为每个服务使用不同的存储桶和凭据。
要创建访问密钥,请导航到“访问密钥”面板,然后单击“创建访问密钥”。
一些注意事项:MinIO 必须设置为允许DNS 样式访问,并且存储桶必须设置为公开。此外,区域设置必须设置为“NULL”或与您的 Snowflake 实例的区域匹配。请参阅此博文以获取使用 MinIO 与 Snowflake 的更多技巧和窍门。
您可以在 Snowflake 控制台或 Snowflake CLI 中运行以下命令,以从 MinIO 中的文件设置外部表。
create database minio;
use database minio;
use warehouse compute_wh;
create or replace stage minio_stage
url = 's3compat://<your-bucket-name>'
endpoint = '<your-minio-endpoint>'
credentials=(
AWS_KEY_ID='<your-access-key>',
AWS_SECRET_KEY='<your-secret-key');
create or replace external table user_payments
with location = @minio_stage
file_format = (type = parquet)
auto_refresh=false
refresh_on_create=false;
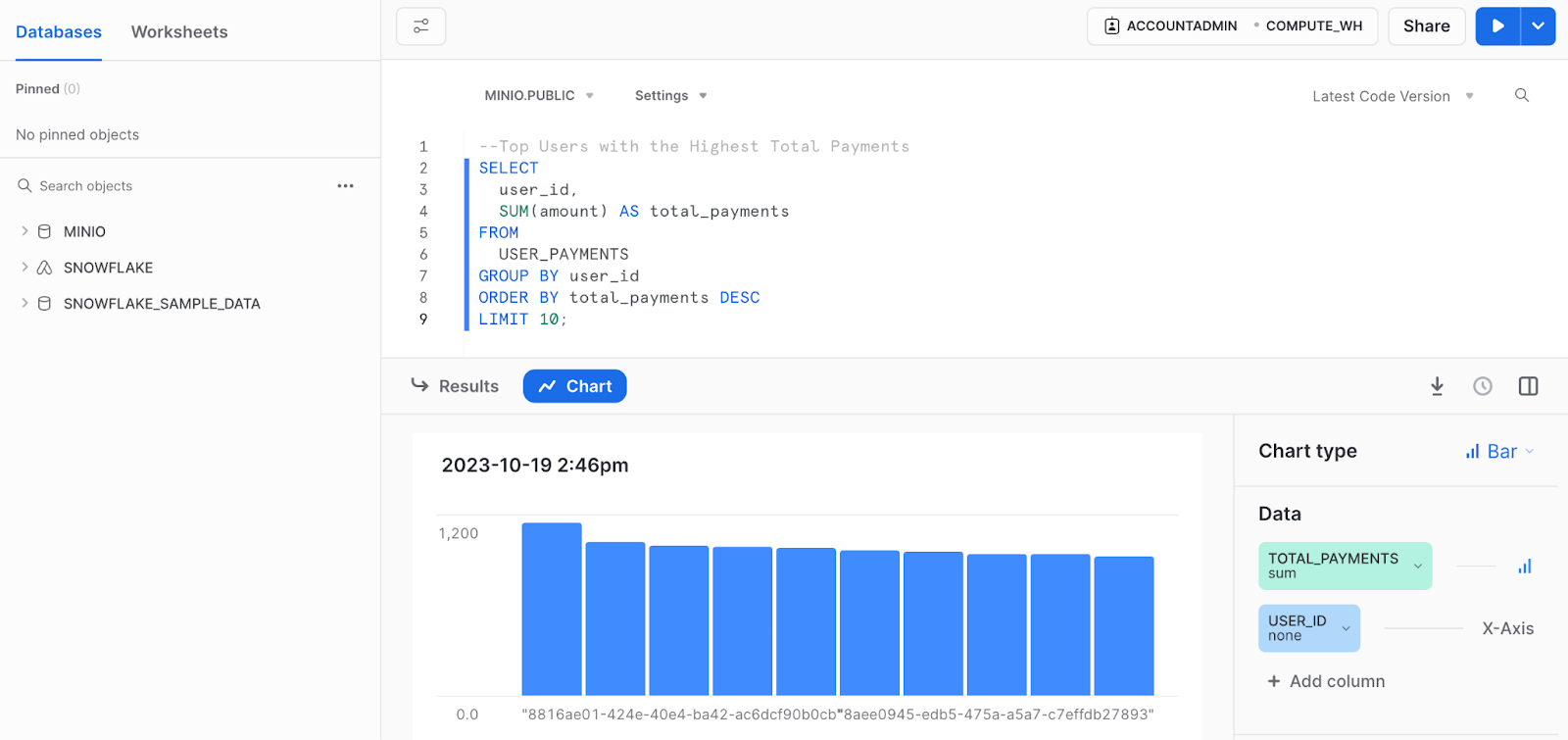
现在,您可以像查询任何其他表一样查询外部表,而无需将数据直接加载到 Snowflake 中。
结论
本文探讨了使用 Redpanda 和 MinIO 实现流式变更数据捕获 (CDC) 模式的实现,最后与 Snowflake 集成。在数据驱动型组织不断发展的环境中,此解决方案提供了一种强大、高效且可扩展的方法来实现数据同步和分析。
如果您对实施此设计有任何疑问,请发送邮件至 hello@min.io 或加入Slack 社区。