使用 Apache Iceberg 和 MinIO 构建数据湖仓

简介
在之前的文章中,我介绍了 Apache Iceberg 并展示了它如何使用 MinIO 进行存储。我还展示了如何设置开发机器。为此,我使用 Docker Compose 安装了一个 Apache Spark 容器作为处理引擎,一个 REST 目录,以及 MinIO 用于存储。最后,我提供了一个非常简单的示例,该示例使用 Apache Spark 摄取数据并使用 PyIceberg 查询数据。如果您不熟悉 Apache Iceberg 或需要在开发机器上设置 Apache Iceberg,请阅读这篇 入门文章。
在这篇文章中,我将从上一篇文章结束的地方继续,并研究一个常见的大数据问题——需要一个单一解决方案来为原始数据、非结构化数据和结构化数据(从原始数据中整理出来的数据)提供存储。此外,相同的解决方案应该提供一个处理引擎,允许对整理后的数据进行高效的报告。这就是数据湖仓的承诺——数据仓库对结构化数据的处理能力和数据湖对非结构化数据的处理能力——都在一个集中式解决方案中。
让我们更详细地了解一下我们的这个大数据场景。
一个常见问题
下图描绘了一个常见问题和一个假设的解决方案。数据来自多个位置和多种格式,进入数据中心。需要的是一个集中式解决方案,允许转换原始数据,以便处理引擎能够有效地支持商业智能、数据分析和机器学习。同时,此解决方案还必须能够存储非结构化数据(文本、图像、音频和视频),以进行数据探索和机器学习。它还应该保留以原始格式转换的任何数据,以防需要重放转换或需要调查数据完整性问题。
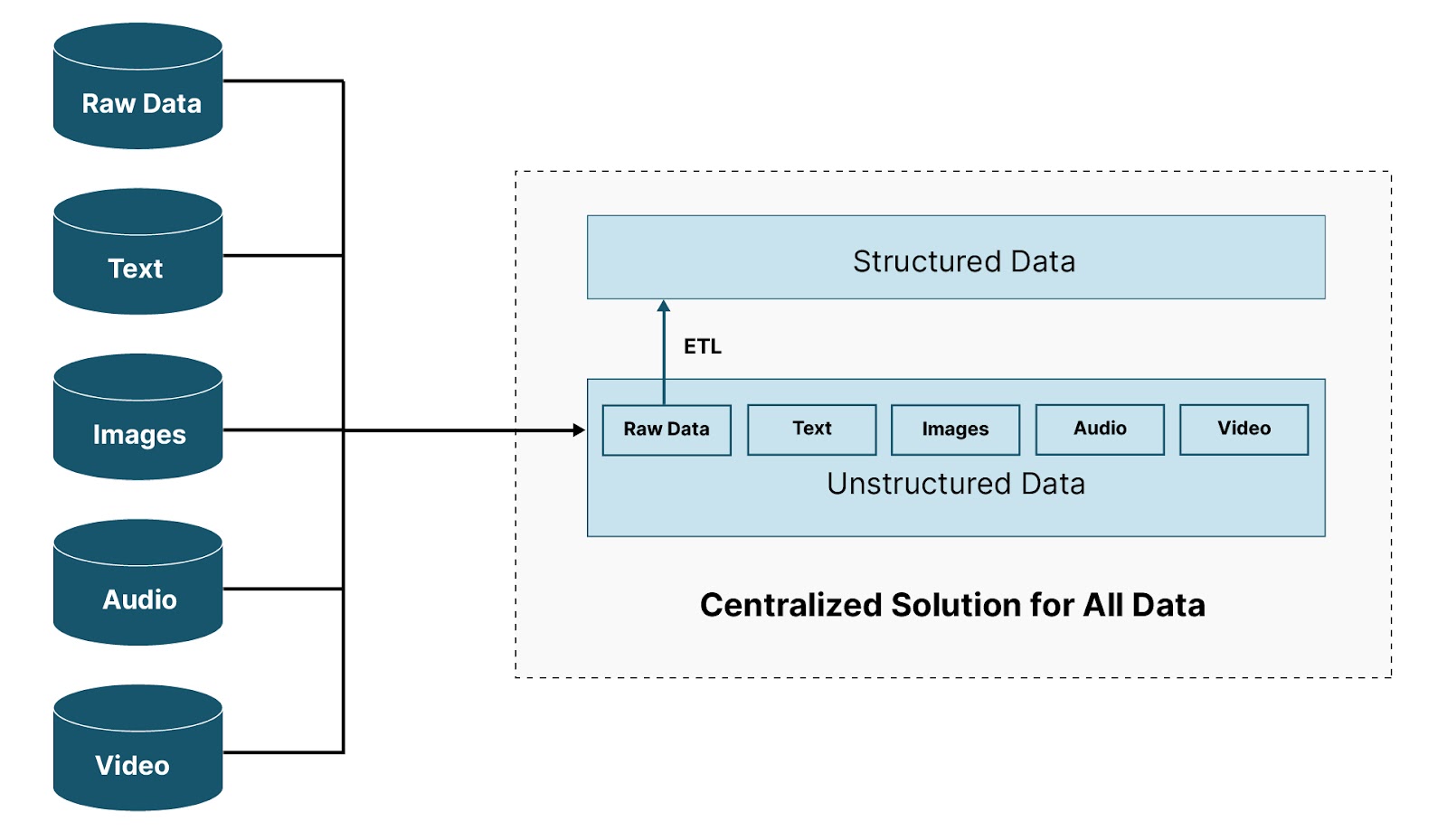
举一个具体的例子,想象一家全球托管银行正在为其客户管理共同基金。代表每个客户每个基金的会计账簿记录和投资账簿记录的数据不断地从世界各地的地理位置流入数据湖仓。从那里,需要进行安全通道检查(是否收到所有发送的内容),并且需要运行数据质量检查。最后,数据可以被分区并加载到另一个存储中,该存储将支持每日开始和每日结束的报告。
或者,也许此图表示一个物联网场景,其中气象站正在发送温度和其他与天气相关的数据。无论场景如何,都需要一种方法以原始格式安全地存储数据,然后转换和处理需要以更结构化方式存储的任何数据——所有这些都在一个集中式解决方案中。这就是数据湖仓的承诺——将数据仓库和数据湖的优点结合到一个集中式解决方案中。
让我们将上面描述的假设解决方案变为现实。这在下图中进行了说明。
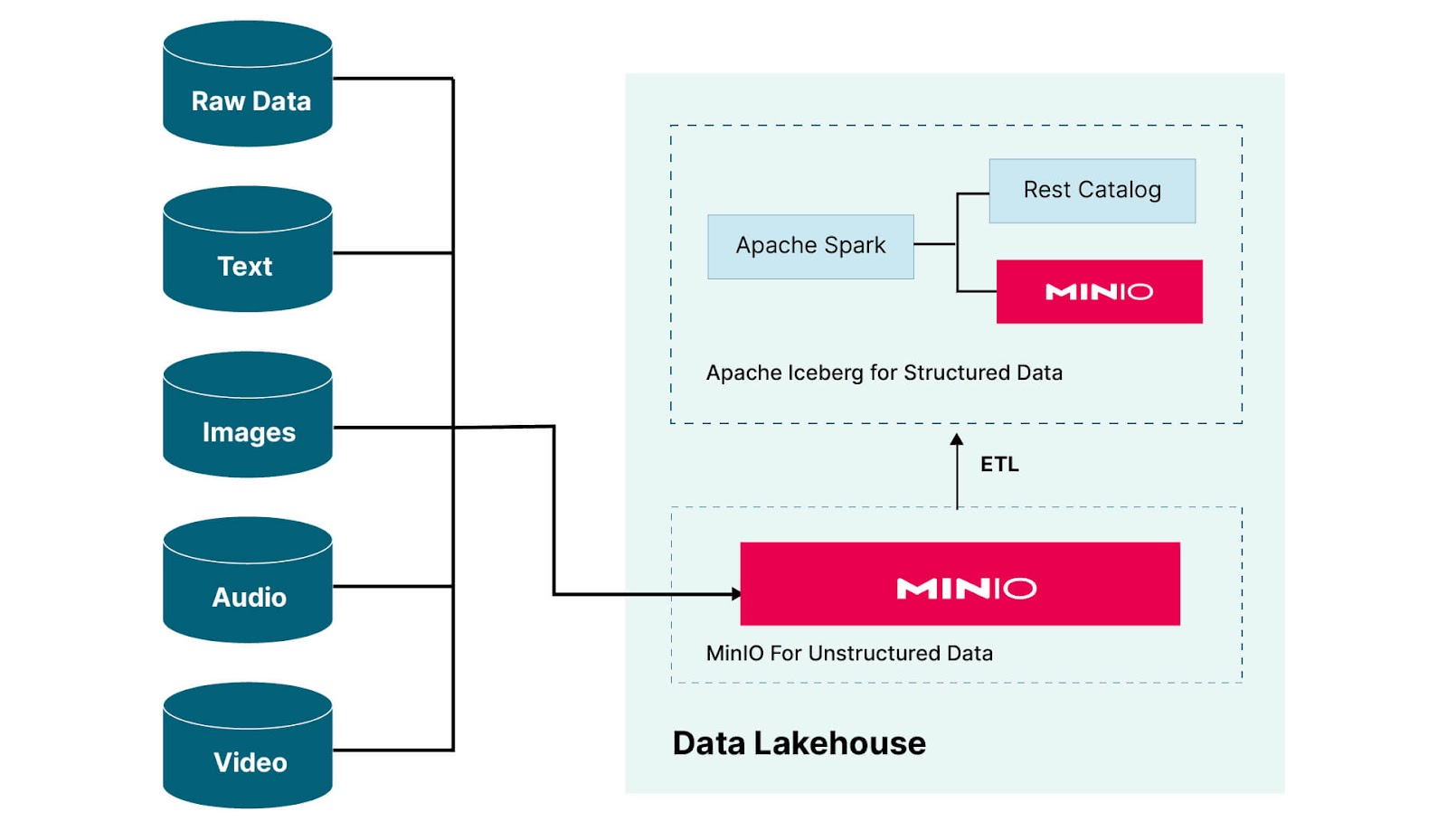
我们的数据湖仓有两个逻辑组件。第一个是 Apache Iceberg 用于结构化数据的实现——相当于数据仓库。(这是我在 上一篇文章 中构建的——所以我不会在这里详细介绍。)第二个逻辑组件是 MinIO 用于非结构化数据——我们数据湖仓的数据湖方面。所有进入湖仓的数据都传递到 MinIO 的这个逻辑实例。实际上,上面显示的 MinIO 的两个逻辑实例可以是数据中心中 MinIO 的同一个实例。如果运行 MinIO 的集群能够处理所有传入数据和 Apache Iceberg 的处理需求,那么这样的部署将节省资金。实际上,这正是我将在本文中所做的。我将使用 Apache Iceberg 的 MinIO 实例中的一个存储桶来保存所有非结构化和原始数据。
让我们通过引入我将在此练习中使用的数据集并将其摄取到 MinIO 中来开始处理数据。
全球每日汇总数据集
我们将在本文中进行实验的数据集是一个称为全球地面每日汇总 (GSOD) 的公共数据集,由美国国家海洋和大气管理局 (NOAA) 管理。NOAA 目前维护着来自全球 9000 多个站点的的数据,而 GSOD 数据集包含来自这些站点的每日汇总信息。您可以 在这里 下载数据。每年有一个 gzip 文件。它从 1929 年开始,到 2022 年结束(截至撰写本文时)。为了构建我们的数据湖仓,我下载了每年的文件并将其放入用于我们的数据湖仓的 MinIO 实例中。我把所有文件都放在一个名为“lake”的存储桶中。我们 MinIO 实例中的两个存储桶如下所示。“warehouse”存储桶是在我们安装 Apache Iceberg 时创建的。

我使用 MinIO 控制台手动摄取了原始数据。在专业的管道中,您需要以自动化方式执行此操作。查看 如何在 Kubernetes 中设置 Kafka 并将数据流式传输到 MinIO,了解如何使用 Kafka 和 Kubernetes 将数据输入 MinIO。
这些文件打包用于下载方便——如果您尝试直接使用它们来创建报表或图表,则这将是一个非常 IO 密集型操作(并且可能也是 CPU 密集型操作)。假设您想绘制指定站点每年平均温度的图表。为此,您必须打开每个文件并搜索每一行,查找与您感兴趣日期的站点匹配的条目。一个更好的选择是使用我们的数据湖仓功能来整理数据并报告整理后的数据。第一步是设置一个新的 Jupyter Notebook。
设置 Jupyter Notebook
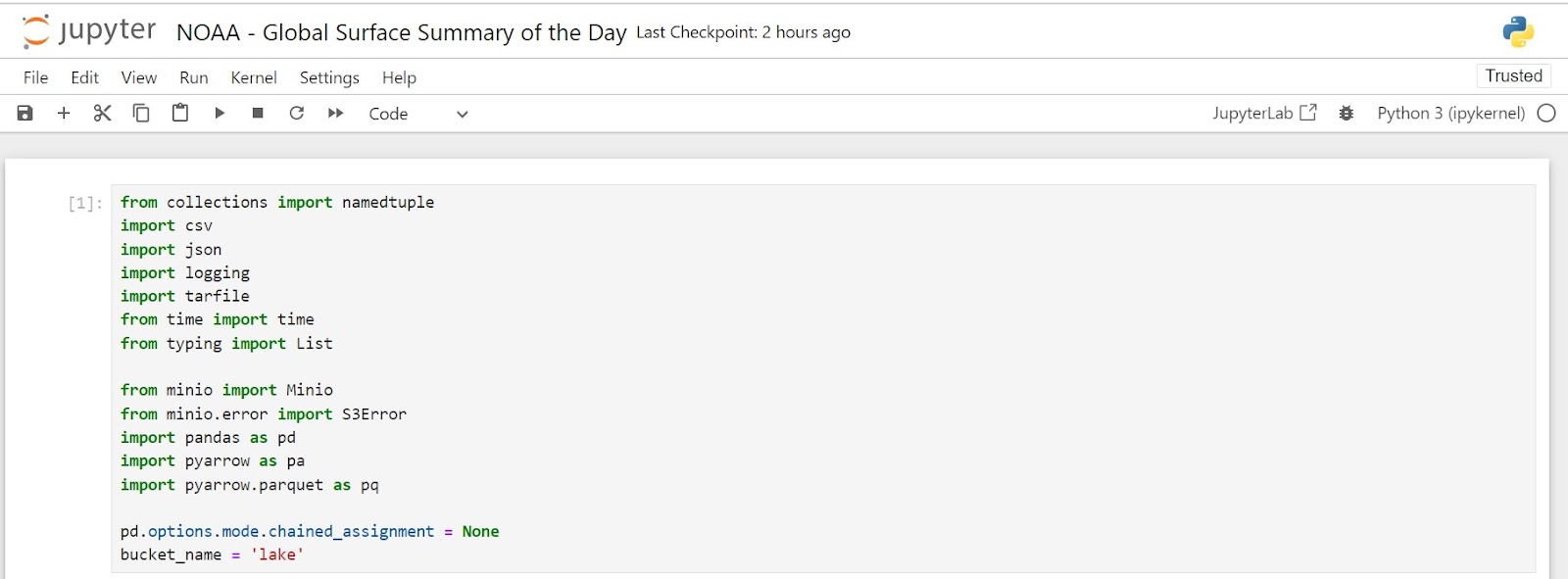
首先,导航到安装在 Apache Spark 处理引擎中的 Jupyter Notebook 服务器。它可以在 https://:8888 找到。创建一个新的 Notebook,并在第一个单元格中添加下面显示的导入。(本文中创建的所有已完成的 Notebook 可以在 此处 找到。)
请注意,我们正在导入 MinIO 库。我们正在构建的笔记本是一个从非结构化存储(MinIO 数据湖)到结构化存储(Apache Iceberg,它在后台使用 MinIO)的 ETL 管道。您的笔记本的开头应该如下所示。
现在,我们可以为我们的数据创建 Iceberg 数据库和表。
创建 Iceberg 数据库和表
为 GSOD 数据集创建数据库和表非常简单。下面的脚本将创建名为“noaa”的数据库。在导入语句之后添加此代码。
下面的脚本将创建 `gsod` 表。
在使用 Apache Iceberg 时,您经常需要删除表以便重新开始实验。以下脚本将删除 `gsod` 表,以便您更改其设置。
从 MinIO 导入数据到 Iceberg
现在我们已经在 Lakehouse 中有了基于年份的原始 zip 文件,我们可以提取、转换和加载它们到我们的数据湖仓中。让我们先介绍一些辅助函数。下面的函数将返回指定存储桶中与前缀匹配的 MinIO 对象列表。
请注意,在上面的代码中,需要一个 MinIO 凭证文件。这可以从 MinIO 控制台获取。如果您不知道如何获取 MinIO 凭证,则本 文章 中有一节内容展示了如何生成和下载它们。
接下来,我们需要一个函数从 MinIO 获取对象。由于这些对象是 tar 文件,因此我们还需要此函数从 tar 存档中提取数据并将其转换为 Pandas DataFrame。这使用以下函数完成。
这两个函数都是通用的实用程序,无论您使用 MinIO 执行什么操作,都可以重复使用。 考虑将它们放在您个人的代码片段集合或组织的 Github Gist 中。
现在,我们准备将数据发送到 Lakehouse 的数据仓库端。 这可以通过以下代码完成,该代码启动一个 Spark 会话,循环遍历所有 GSOD tar 文件,提取、转换并将它们发送到我们的 Iceberg 表。
本节中的代码手动从 MinIO 存储桶加载数据。在生产环境中,您需要将此代码部署到服务中,并使用MinIO 存储桶事件进行自动数据摄取。
使用 PyIceberg 查询 Iceberg 数据湖存储
让我们开始一个新的笔记本进行报表生成。下面的单元格导入了我们需要用到的实用程序。具体来说,我们将使用 PyIceberg 进行数据检索,使用 Pandas 进行数据整理,以及使用 Seaborn 进行数据可视化。
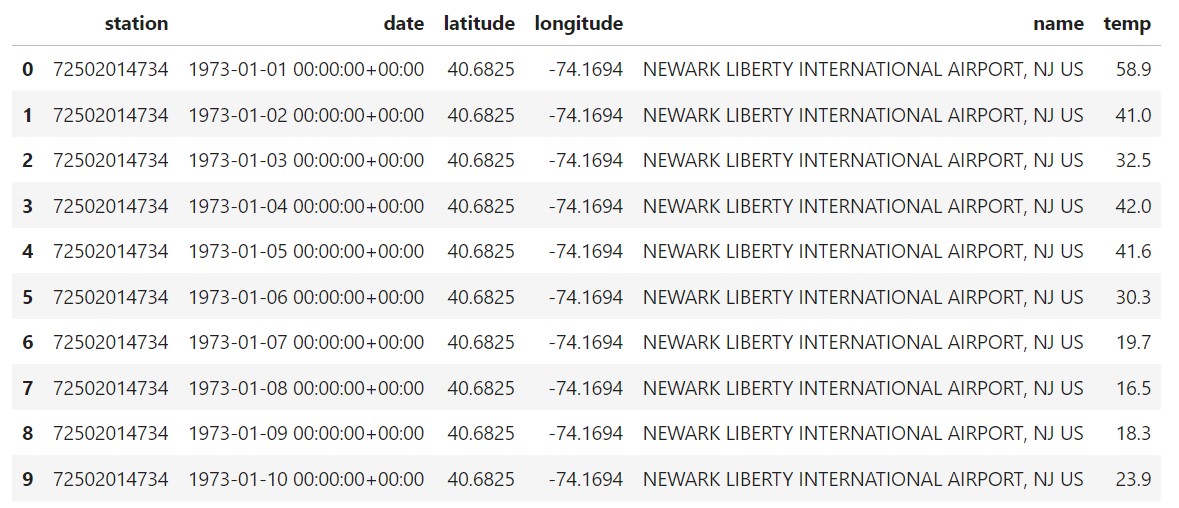
我们想要做的是计算给定气象站每年平均温度。这会为我们提供每年一个数字,并考虑一年中的所有季节。第一步是使用 PyIceberg 查询 Iceberg 以获取给定站的所有数据。这在下面完成。
以上代码中使用的站点 ID 对应于美国新泽西州纽瓦克自由国际机场的一个站点。该站点自 1973 年开始运行(近 50 年的数据)。代码运行后,您将获得以下输出。(我使用 DataFrame 的 head() 函数获取样本。)
接下来,我们需要按年份分组并计算平均值。使用 Pandas,只需几行代码即可完成。无需循环。
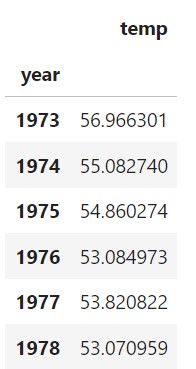
此单元格运行后,您将看到每年的单个值。前几年的数据如下所示。
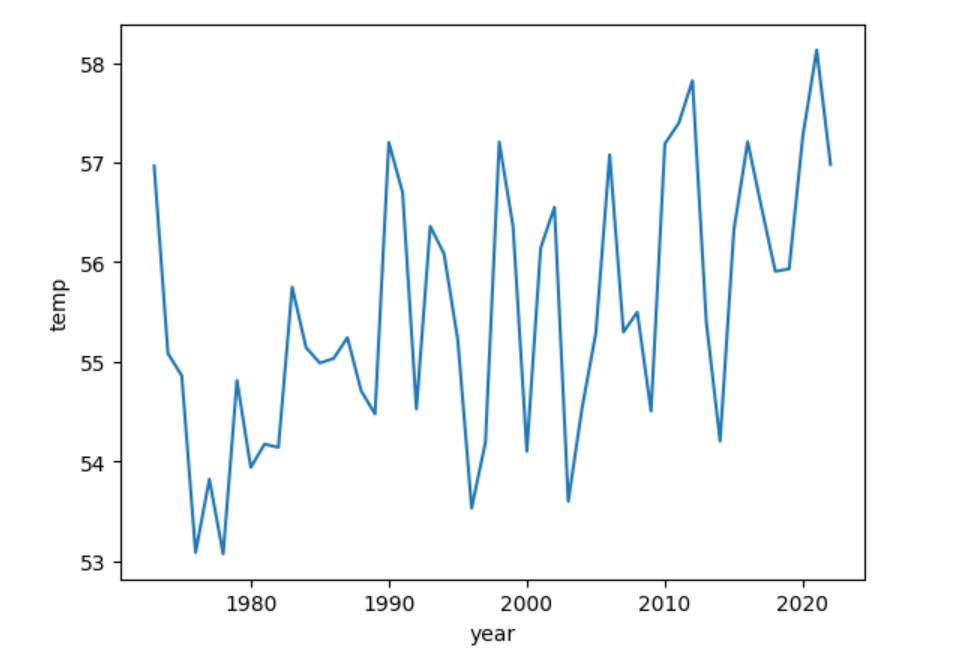
最后,我们可以将每年的平均值可视化。我们将使用 Seaborn 创建折线图。这只需一行代码。
折线图如下所示。
第一次运行报表后,您始终应该运行的另一个命令如下所示。
这是一个列表推导式,它将为您提供 Apache Iceberg 中所有与您的查询匹配的数据文件的列表。即使 Iceberg 的元数据可以过滤掉许多文件,但仍然会显示很多文件。查看所有相关文件可以充分说明高速对象存储是数据湖仓的重要组成部分。
总结
在这篇文章中,我们使用 MinIO 和 Apache Iceberg 构建了一个数据湖仓。我们使用 GSOD 数据集来实现这一点。首先,原始数据上传到数据湖仓的湖端(MinIO)。然后,我们在 Apache Iceberg 中创建了一个数据库和一个表(数据湖仓的数据仓库端)。之后,我们构建了一个简单的 ETL 管道,将数据从湖端移动到数据湖仓内的仓库端。
在 Apache Iceberg 完全填充数据后,我们能够创建年度平均气温报告并将其可视化。
请记住,如果您想在生产环境中构建数据湖仓,则需要 MinIO 的企业级功能。请考虑查看对象生命周期管理、安全最佳实践、Kafka 流式传输和桶事件。