引言 在我之前的一篇博文中,我介绍了 使用 MinIO 和 Kubeflow v2.0 构建机器学习数据管道 。我创建的数据管道将美国人口普查数据下载到 MinIO 的一个专用实例中。这与 Kubeflow Pipelines (KFP) 内部使用的 MinIO 实例不同。我们可以尝试使用 KFP 的 MinIO 实例——但是,这并不是机器学习模型训练管道的最佳设计。随着 GPU 速度越来越快,GPU 可能完成计算后需要等待新数据。等待的 GPU 是未充分利用的 GPU。您需要一个完全受您控制的高速存储解决方案。下面是我们的 MinIO 部署图,说明了每个实例的目的。
需要注意的是,我的数据管道代码可以很容易地修改为与任何数据源交互——另一个外部 API、SFTP 位置或队列。如果您有一个缓慢且不可靠的外部数据源,并且需要将数据复制到高速弹性存储解决方案中,那么请使用我的代码作为起点,将数据导入 MinIO。
在这篇博文中,我将更进一步,训练一个模型。我假设您熟悉用于创建组件和管道的 Kubeflow 装饰器。我还假设您熟悉组件之间的数据传递。如果您不熟悉这些结构,请查看我之前关于构建数据管道的博文 上一篇博文 。
如果我们要训练一个模型,那么我们需要一些东西来进行预测。换句话说,我们需要一个包含特征和标签的数据集。
数据集 Kaggle 是寻找数据集的好去处。您不仅会发现种类繁多的数据集,而且许多数据集都曾是挑战赛的主题,个人和团队在其中争夺奖品。由于过去挑战赛的结果被保留了下来,我们可以将我们的结果与获胜者进行比较。
我们将使用的数据集来自 GoDaddy - 微型企业密度预测 挑战赛。我喜欢这个数据集有很多原因。首先,本次竞赛的目标是预测美国各县的每月微型企业密度。获胜的模型将被政策制定者用来了解微型企业,从而制定新的政策和计划,以提高这些最小企业的成功率和影响力。其次,数据按美国县划分,因此我们可以用美国人口普查数据(请记住我在上一篇博文中构建的管道)来增强这些数据,以提高准确性。这在比赛中是被允许的——因此,当我们将我们的结果与排行榜进行比较时,我们并没有给自己带来不公平的优势。最后,虽然我们的模型将预测微型企业密度,但它可以很容易地适应于为包含地理信息的数据集提供其他预测。
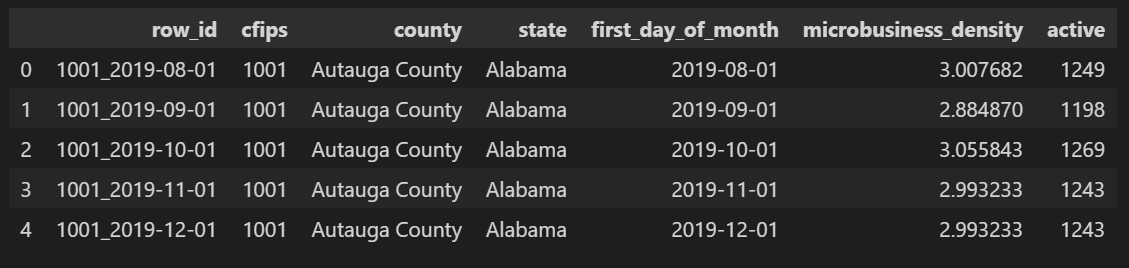
以下是为此挑战赛提供的数据集示例。`microbusiness_density` 列是标签(我们的模型将尝试预测的内容),所有其他列都是潜在的特征。
训练模型实际上是一个将数据通过一系列任务的管道,最终生成一个训练好的模型。这就是为什么 MinIO 和 KFP 是训练模型的强大工具。MinIO 用于高效可靠地访问原始数据,KFP 用于具有记录结果的可重复管道。
让我们在编写代码之前构建管道的逻辑设计。
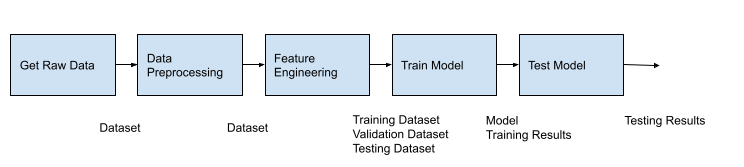
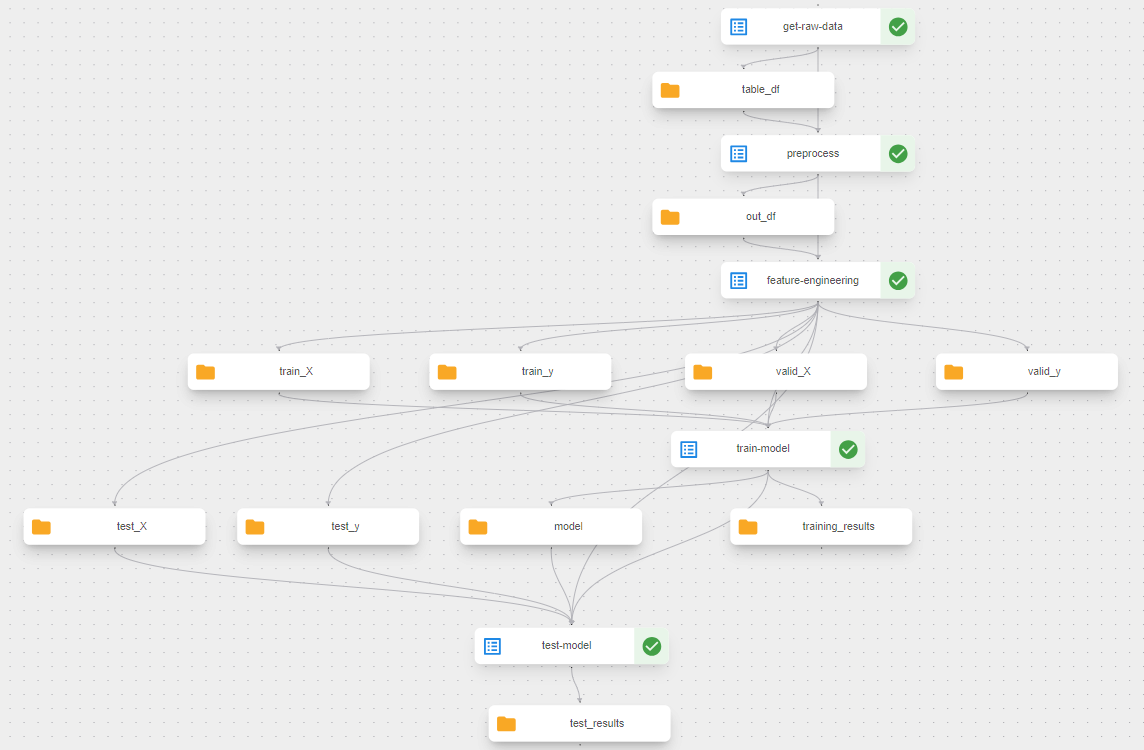
逻辑管道设计 以下是我们管道的逻辑设计。它是自解释的,如果您曾经训练过模型,您之前肯定见过这些任务。
每个块显示了我们管道中的一个高级任务。在构建数据管道时,我们能够独家使用轻量级 Python 组件。 轻量级 Python 组件 由密封函数创建——换句话说,这些函数不会调用其他函数并且需要最少的导入。这些函数被构建成一个镜像,该镜像被部署到一个容器中,并在其中运行。KFP 负责构建、部署和跨容器编排数据。这是在 KFP 中设置代码的最简单方法。但是,如果您有很多依赖项,或者您希望将整个模块(或模块)打包到单个镜像中,那么您可以使用 容器化 Python 组件 。我们将在本管道中使用容器化 Python 组件。训练 Pytorch 模型需要创建一个 DataSet 类、一个模型类,以及一些其他辅助函数来进行验证、测试以及在可用时将数据移动到 GPU。
此外,请注意上图中任务之间传递的工件:数据集、模型和 HTML。我假设您熟悉数据集并在代码中设置它们。(这就是我们如何通过管道的第一部分传递 DataFrames 的方式。)在这篇博文中,我将介绍一些其他工件。
让我们从创建一个容器化 Python 组件开始。
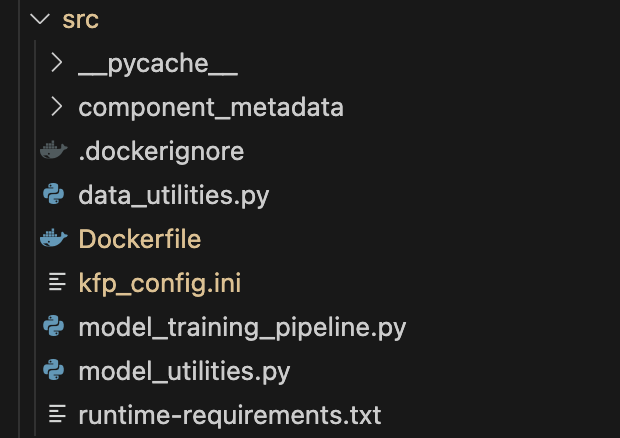
容器化 Python 组件 容器化 Python 组件允许我们指示 KFP 使用的镜像中包含什么内容。让我们来看一个简单的示例,演示如何创建容器化 Python 组件及其优势。您需要做的第一件事是在项目中创建一个子文件夹。我创建了一个名为“src”的子文件夹。下面是一个屏幕截图,显示了我的“src”文件夹以及创建和训练模型所需的所有模块。您放在此子文件夹中的所有模块都将成为 KFP 用于所有管道组件的镜像的一部分。
接下来,考虑下面的函数,该函数位于 `model_utilities.py` 模块中。此函数包含用于训练模型的 epoch 循环。它调用其他函数——`get_optimizer()`、`train_epoch()` 和 `validate_loss()`。它还在此模块中实例化类——特别是 `CountyDataset` 和 `MBDModel`。
def train_model (df_train_X, df_train_y, df_valid_X, df_valid_y,
epochs= 5 , lr= 0.01 , wd= 0.0 ) -> Tuple[nn.Module, List]: config = du.get_config() categorical_cols = config[ 'categorical_cols' ] continuous_cols = config[ 'continuous_cols' ] embedding_sizes = [( 3135 , 50 ), ( 51 , 26 )] model = RegressionModel(embedding_sizes, len(continuous_cols)) # 创建数据集 train_dataset = CountyDataset(df_train_X, df_train_y, categorical_cols) valid_dataset = CountyDataset(df_valid_X, df_valid_y, categorical_cols) # 创建加载器 batch_size = 10 train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle= True ) valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle= True ) optim = get_optimizer(model, lr = lr, wd = wd) results = [] for i in range(epochs): loss = train_epoch(model, optim, train_loader) print( '训练损失: ' , loss) val_loss, val_accuracy = validate_model(model, valid_loader) results.append((loss, val_loss, val_accuracy)) return model, results
如果我们使用轻量级 Python 组件,那么所有这些函数调用都将在另一个容器中发生,并且数据需要跨容器边界进行编组。这不是理想的方案。我们希望模型训练成为在自己的容器中启动的任务,但我们希望上面列出的辅助函数在此同一容器中运行,以便这些调用是本地且快速的。这就是容器化 Python 组件允许我们做到的,我们可以使用下面的函数,它封装了上面的函数。
@dsl.component(base_image='python:3.10.0', target_image= 'docker/model-training-project/model-training:v1' , packages_to_install=[ 'numpy==1.24.3' , 'pandas==1.3.5' , 'torch==1.13.1' ]) def train_model (train_X: Input[Dataset], train_y: Input[Dataset], valid_X: Input[Dataset], valid_y: Input[Dataset], model: Output[Model], training_results: Output[Markdown]) -> None : df_train_X = pd.read_csv(train_X.path) df_train_y = pd.read_csv(train_y.path) df_valid_X = pd.read_csv(valid_X.path) df_valid_y = pd.read_csv(valid_y.path) mbd_model, results = mu.train_model(df_train_X, df_train_y, df_valid_X, df_valid_y) torch.save(mbd_model.state_dict(), model.path) with open(training_results.path, 'w' ) as f: for result in results: epoch_result = f'训练损失: {result[ 0 ]} , 验证损失: {result[ 1 ]} ,
验证准确率: {result[ 2 ]} .<br>' f.write(epoch_result)
您不需要在辅助模块中使用任何 KFP 装饰器。在本示例中,我的辅助模块是 `data_utilities.py` 和 `model_utilities.py`。这些模块是普通的 Python 模块。它们内部没有任何 KFP 特定的内容。以我在这里使用的方式使用辅助函数是一个不错的特性。我在辅助函数中完成了预处理数据和训练模型所需的所有繁重工作,这些函数可以使用普通的 Python 编写。所有需要用 KFP 装饰器装饰的函数都在 `model_training_pipeline.py` 模块中,它们只不过是 KFP 和我的辅助模块之间的桥接器。因此,所有 KFP 特定的代码都封装在一个单独的小模块中。
请注意,我们仍然使用 `dsl.component` 装饰器。当使用容器化 Python 组件时,必须在组件装饰器上设置一些额外的参数。`base_image` 将用于 KFP 为我们的镜像创建的 Dockerfile 中的 FROM 命令。这是可选的,如果未指定,则默认为 Python 3.7。目标镜像参数是一个 URI,它告诉 KFP 将您的镜像放在哪里。此 URI 需要指向一个镜像注册表。我正在 Docker Desktop 中运行此演示,因此我使用的 URI 是 Docker Desktop 中的本地注册表。如果您在公共云中或您的组织有自己的内部注册表,则相应地更改它。以下是一个示例,说明如果我需要将我的镜像放在 GCP 的 Google Cloud Artifact Registry 中,此 URI 将是什么样子(请注意 `gcr.io` URI)。
grc.io/model-training-project/model-training:v1
最后,您仍然需要使用 `packages_to_install` 参数,以便 KFP 可以将任何所需的第三方库安装到您的镜像中。但是,您不再需要在函数内部放置导入语句。这些导入语句现在可以在模块级别进行。其余组件的代码如下所示。为了简洁起见,我没有显示辅助模块,因为它们包含大量代码。但是,您可以在这里获取它们 。它们是普通的 Python 和 Pytorch,如果您想在发送到 KFP 之前进行实验,可以在脚本或笔记本中运行它们。
@dsl.component(base_image='python:3.10.0', target_image= 'docker/model-training-project/model-training:v1' , packages_to_install=[ 'pandas==1.3.5' , 'minio==7.1.14' ]) def get_raw_data (bucket: str, object_name: str, table_df: Output[Dataset]): ''' Return an object as a Pandas DataFrame. ''' df = du.get_object(bucket, object_name) df.to_csv(table_df.path, index= False ) @dsl.component(base_image='python:3.10.0', target_image= 'docker/model-training-project/model-training:v1' , packages_to_install=[ 'numpy==1.24.3' , 'pandas==1.3.5' , 'scikit-learn==1.0.2' ]) def preprocess (in_df: Input[Dataset], out_df: Output[Dataset]) -> None : ''' Preprocess the dataframe. ''' df = pd.read_csv(in_df.path) df = du.preprocess(df) df.to_csv(out_df.path, index= False ) @dsl.component(base_image='python:3.10.0', target_image= 'docker/model-training-project/model-training:v1' , packages_to_install=[ 'numpy==1.24.3' , 'pandas==1.3.5' , 'scikit-learn==1.0.2' ]) def feature_engineering (pre: Input[Dataset], train_X: Output[Dataset], train_y: Output[Dataset], valid_X: Output[Dataset], valid_y: Output[Dataset], test_X: Output[Dataset], test_y: Output[Dataset], validation_size: int= 1 , test_size: int= 1 ) -> None : ''' Feature engineering. ''' logger = logging.getLogger( 'kfp_logger' ) logger.setLevel(logging.INFO) df = pd.read_csv(pre.path) df_train_X, df_train_y, df_valid_X, df_valid_y, df_test_X, df_test_y =
du.feature_engineering(df, validation_size, test_size) df_train_X.to_csv(train_X.path, index= False ) df_train_y.to_csv(train_y.path, index= False ) df_valid_X.to_csv(valid_X.path, index= False ) df_valid_y.to_csv(valid_y.path, index= False ) df_test_X.to_csv(test_X.path, index= False ) df_test_y.to_csv(test_y.path, index= False ) logger.info( '特征工程完成。' )
@dsl.component(base_image='python:3.10.0', target_image= 'docker/model-training-project/model-training:v1' , packages_to_install=[ 'numpy==1.24.3' , 'pandas==1.3.5' , 'torch==1.13.1' ]) def test_model (test_X: Input[Dataset], test_y: Input[Dataset], model: Input[Model],
test_results: Output[Markdown]) -> None : df_test_X = pd.read_csv(test_X.path) df_test_y = pd.read_csv(test_y.path) mbd_model = mu.create_model() mbd_model.load_state_dict(torch.load(model.path)) smape = mu.test_model(df_test_X, df_test_y, mbd_model) with open(test_results.path, 'w' ) as f: f.write( 'Symetric Mean Absolute Percent Error (SMAPE): **' + str(smape) + '**' )
一旦所有需要的模块都位于同一个文件夹中,并且表示管道组件的函数都已正确装饰,您就可以为 KFP 构建镜像。KFP 命令行实用程序使此操作变得容易。
kfp component build src/ --component-filepattern model_training_pipeline.py --push-image
此命令告诉 KFP 包含所有模块的文件夹位置以及包含组件定义的模块。此命令成功完成后,您会注意到子文件夹中添加了几个文件,如下所示。
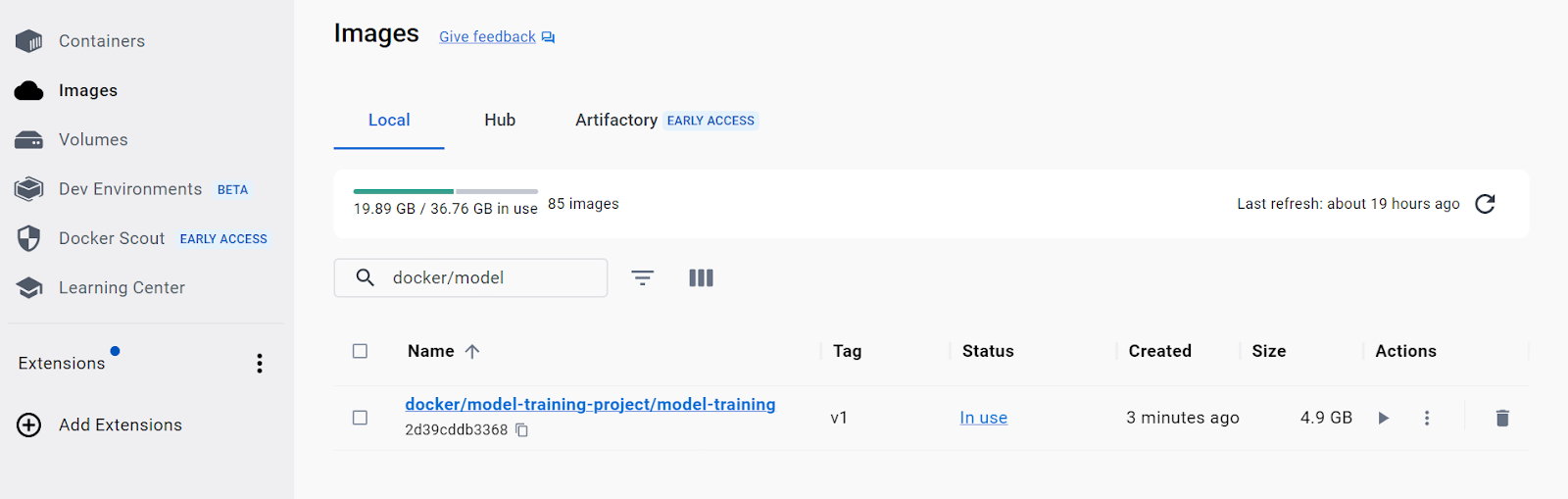
检查这些文件将使您更深入地了解 KFP 的工作原理。基本上,KFP 使用组件装饰器中放置的所有信息来创建这些文件。然后,这些文件用于创建镜像并将其推送到您的注册表。如果您使用 Docker Desktop 并且使用了相同的 `target_image` 参数,那么您将在镜像列表中看到以下内容。
现在,我们准备构建一个管道来协调上面显示的所有被指定为管道组件的函数。
管道 用于将所有内容整合在一起的管道函数如下所示。它非常简单。一个组件的输出是下一个组件的输入。请注意,所有调用的函数都映射到我们概念性管道中的一个任务。
@dsl.pipeline( name= 'model-training-pipeline' , description= '用于训练神经网络的管道。' ) def training_pipeline (bucket: str, object_name: str) -> Markdown: raw_dataset = get_raw_data(bucket=bucket, object_name=object_name) processed_dataset = preprocess(in_df=raw_dataset.outputs[ 'table_df' ]) final_datasets = feature_engineering(pre=processed_dataset.outputs[ 'out_df' ]) training_results = train_model(train_X=final_datasets.outputs[ 'train_X' ],
train_y=final_datasets.outputs[ 'train_y' ], valid_X=final_datasets.outputs[ 'valid_X' ],
valid_y=final_datasets.outputs[ 'valid_y' ]) testing_results = test_model(test_X=final_datasets.outputs[ 'test_X' ],
test_y=final_datasets.outputs[ 'test_y' ], model=training_results.outputs[ 'model' ]) return testing_results.outputs[ 'test_results' ]
要将此管道提交到 KFP,请运行以下代码。
def start_training_pipeline_run (): client = Client() run = client.create_run_from_pipeline_func(training_pipeline,
experiment_name= '容器化 Python 组件' ,
enable_caching= False , arguments={ 'bucket' : 'microbusiness-density' , 'object_name' : 'train.csv' }) url = f' {kfp_endpoint} /#/runs/details/ {run.run_id} ' print(url)
在 KFP 中运行此管道会在 KFP 的“运行”选项卡中生成以下可视化效果。
使用工件报告结果 工件用于在组件之间传递大型或复杂数据。在后台,KFP 将此数据保存到其 MinIO 实例中,使其可用于管道中的任何组件。一个附带好处是,KFP 可以进行类型检查,并在将一个组件的输出传递到另一个组件的输入时告知您数据类型是否不正确。KFP 还提供用于报告结果的工件。让我们进一步探讨这些报告工件。
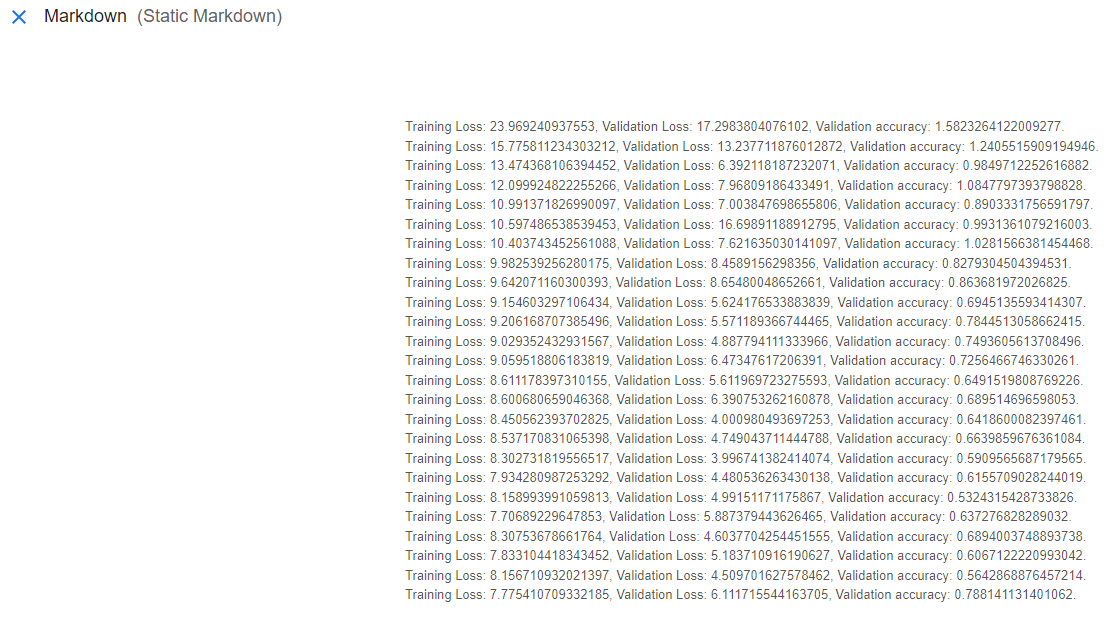
在训练模型时,最佳实践是跟踪损失函数的结果以及模型针对验证集的准确率。“指标”、“HTML”和“Markdown”工件具有可视化组件。这些工件的内容将在 KFP 的 UI 中易于观察。本文使用 Markdown 对象来报告训练和测试期间的模型性能。请参阅 `train_model` 组件中最后几行代码,这些代码创建了一个名为“training_results”的 Markdown 对象。
创建此工件后,它包含的数据将自动显示在 `training_results` 中的“可视化”选项卡中。以下是此可视化的屏幕截图。
最佳实践是在针对测试集测试模型后执行相同的操作。
我想指出本文中使用的模型的一个巧妙功能——即使它与本文主题略微不相关。以下是代码——感兴趣的层已突出显示。此层是嵌入层。它用于了解县和州与微型企业密度的关系。此处使用的嵌入是内存中小型向量数据库。在神经网络的层中,这些向量用于分类特征(或非连续特征),以允许神经网络学习分类或离散数据的有意义表示。了解此层是了解向量数据库的第一步。向量数据库允许根据其向量表示有效检索类似的项目,从而实现诸如查找类似图像、推荐类似产品或搜索类似文档等任务。我们在 MinIO 正在关注向量,并在未来几个月内会有更多内容发布。
class RegressionModel (nn.Module): def __init__ (self, embedding_sizes, n_cont): super(RegressionModel, self).__init__() # 设置嵌入层。 self.embeddings = nn.ModuleList([nn.Embedding(categories, size) for categories,size
in embedding_sizes]) n_emb = sum(e.embedding_dim for e in self.embeddings) #所有嵌入的长度 self.n_emb, self.n_cont = n_emb, n_cont # 设置网络的其余部分。 self.linear1 = nn.Linear(self.n_emb + self.n_cont, 20 , bias= True ) self.linear2 = nn.Linear( 20 , 20 , bias= True ) self.linear3 = nn.Linear( 20 , 1 , bias= True ) def forward (self, x_cat, x_cont): out = [e(x_cat[:,i]) for i,e in enumerate(self.embeddings)] out = torch.cat(out, 1 ) out = torch.cat([out, x_cont], 1 ) out = F.relu(self.linear1(out)) out = F.relu(self.linear2(out)) out = self.linear3(out) return out
摘要 这篇文章承接了我上一篇关于使用 KFP 的数据管道文章。在这篇文章中,我展示了如何使用 KFP 训练模型。我介绍了容器化 Python 组件,它更适合用于训练模型。在训练模型时,您需要创建类并使用辅助函数,这些函数最好在训练发生的同一个容器中运行。
后续步骤 安装 MinIO 、KFP,并下载 代码示例 ,以便您可以进行自己的实验。尝试不同的模型架构,通过特征工程创建新的特征,并查看您的结果与 Kaggle 的 排行榜 相比如何。
如果您有任何疑问或想分享您的结果,请发送邮件至 hello@min.io 或加入我们 通用 Slack 频道 进行讨论。