基于 MinIO、Presto、R 和 S3 Select 功能构建本地化机器学习生态系统

摘要
在任何数字化转型过程中,采用机器学习技术都是一项关键挑战。鉴于工具和框架的爆炸式增长,很难知道从哪里开始以及哪些选择会排除以后的其它选择。企业希望在可扩展性、可维护性、安全性以及成本方面进行联合优化。
本文旨在帮助企业开始使用机器学习或人工智能,并为未来的发展铺平道路。本文假设读者具有一定的 Java 知识。我们将一起进行一些代码开发、集成工作以及配置。
在本文中,我们将对 Hadoop 进行比较和对比——了解为什么不需要那种复杂性和可维护性。需要明确的是,我并不反对 Hadoop,我热爱 Hadoop,但是有更好、更简单以及更现代的方法来实现企业级的分析性能。这些更现代的方法使团队免于进行乏味的周末加班,例如 重新平衡文件系统,维护 擦除编码,以及需要和理解外部工具(例如 Apache Ranger,Apache Sentry 等)以进行外围安全等等。对于元数据管理,您将需要寻求一些其他工具的帮助,例如 Apache Atlas。
您是否见过世界上任何一个元数据存储在另一个数据库中的稳定数据库?我不太确定为什么 Hive 的设计是这样的。您需要将一个外部数据库配置为您的 Hive 元存储——可能是 Derby 或 MySQL。如果您的数据在 HDFS 中丢失,您的大型元存储仍然存在!让我们对所有这些麻烦说“不”,并尝试将元数据与数据一起存储,避免在拟议的机器学习平台中安装 Hadoop 或 Hive。是的,我们将使用 Hive,只是作为将数据投影为定义明确的关系和元组的接口(对于外行来说,这些是表和行)。
我们将把本文内容划分为以下部分:
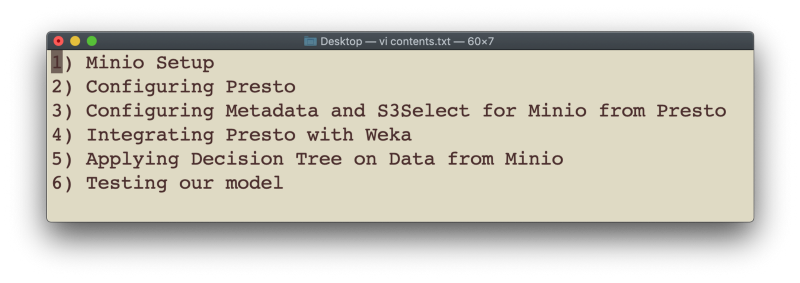
1. MinIO 设置
我不会在这方面花费任何时间,MinIO 成为全球增长最快的本地对象存储系统的原因之一是它非常易于启动和运行——以任意数量的配置。MinIO 稳定、可扩展、容错、安全且可持续。您无需为 MinIO 进行磁盘平衡 :)。您无需担心擦除编码或安全性——这些功能都内置于密钥和机密中,并且通过组合适当的 ACL,您可以拥有一个健壮的系统。MinIO 完全兼容 AWS S3 API。
对于 MinIO 新手,我建议您阅读我的另外两篇文章,第一部分和第二部分,以详细了解该技术。
如果您尚未安装,请获取正确的 下载 并按照 快速入门指南进行操作。
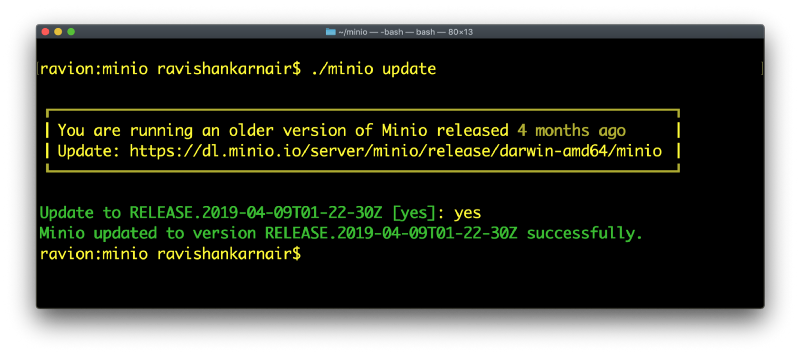
这体现了第一个 Hadoop 比较/对比时刻。当您想要升级基于 Hadoop 的生态系统时,您的组织花费或将要花费的时间范围是多少?几个月?这可能假设一切进展顺利。MinIO——即使对于 PB/EB 级别的基础设施,也只需几分钟。
看,当我开始使用 MinIO 时发生了什么?我有一个旧的副本。更新到最新版本并开始工作不到一分钟。
现在,您可以按照指南启动服务器。
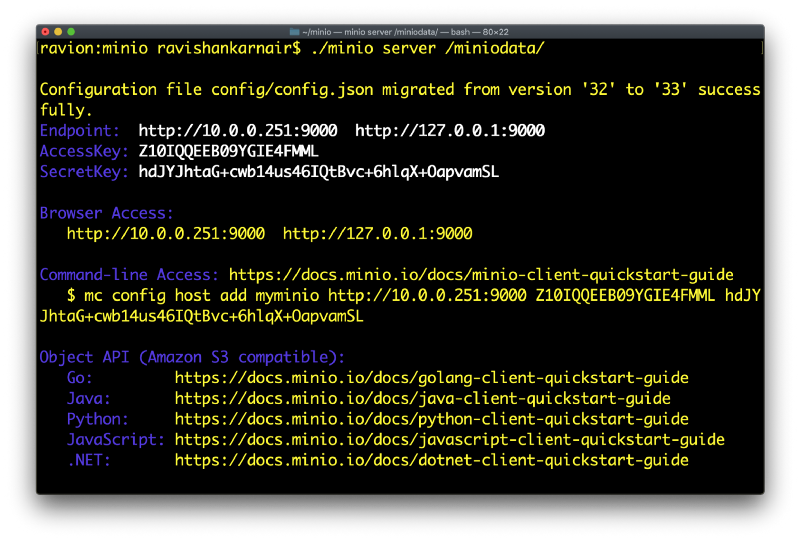
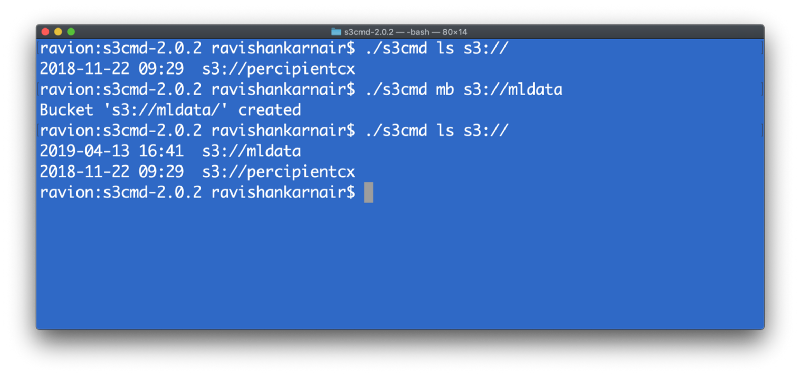
您可以使用 MinIOClient (mc) 或 S3CMD 创建存储桶并使用 MinIO。在我之前的文章中,我使用了“mc”。在这里,我使用 s3cmd 来演示 MinIO 的灵活性。让我们使用 s3cmd 创建一个名为“mldata”的新存储桶。不要忘记在本地机器上创建 .s3cfg 文件,其中包含您在上述屏幕上显示的 MinIO 服务器详细信息。
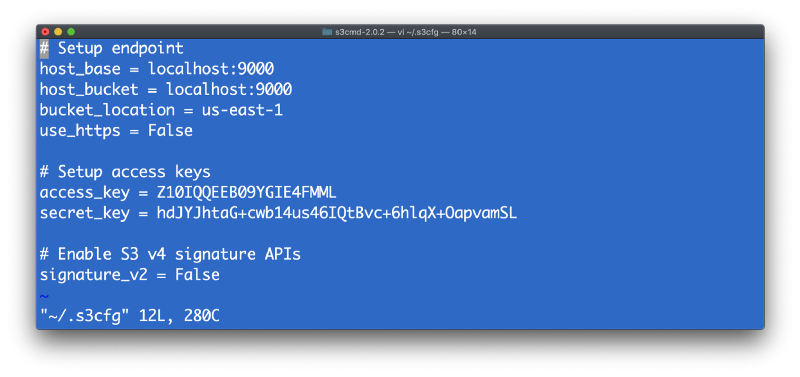
现在创建一个目录,并通过列出目录来确保它存在。
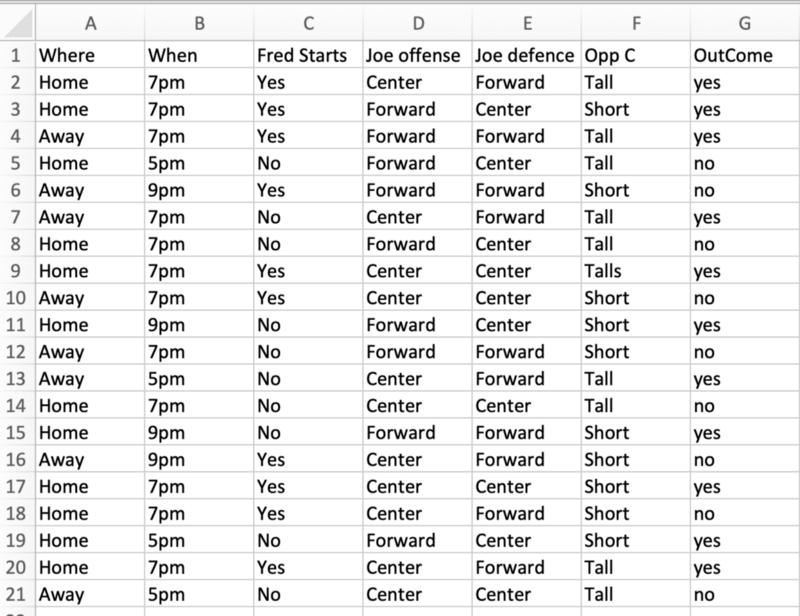
在本文后面,我们将使用一个文件进行机器学习,特别是用于决策树。我们不会解释任何关于机器学习的内容,因为机器学习方面有很多文档。
我正在使用过去的篮球比赛统计结果进行训练,以预测未来的比赛是“胜利”(结果为是)还是“失败”(结果为否)。
这是该文件的快照。出于演示目的,我们使用了一个小文件。在理想情况下,这可能是数千万甚至数亿个元组。
下一步是将这些数据放入我们的存储桶中。为了方便创建表,我们可以跳过标题行并将我们的 CSV 文件称为 input.csv。像 **sed** 这样的少量 Unix 命令将在这里帮助我们。
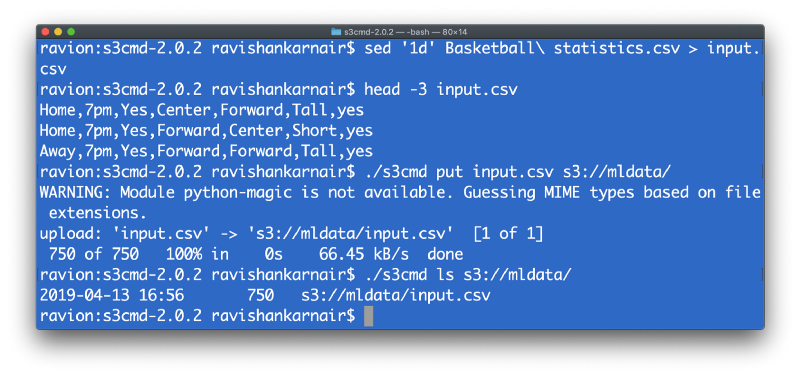
您可以删除这些数据,因为我们将在本文后面使用 Presto 从 MySQL 动态创建表。
2. Presto 设置
接下来我们将使用 Presto。要开始使用,请访问 Presto 的 GitHub 页面 并将以下文件下载到您的系统中。
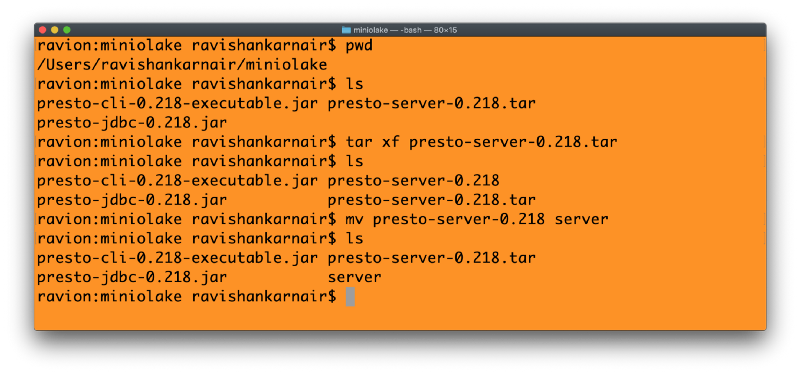
我将这些文件放在一个名为“MinIOlake”的目录中。将上面的服务器 (1) 解压缩到此文件夹中。这里有很好的说明 在这里 供您参考。步骤如下所示:
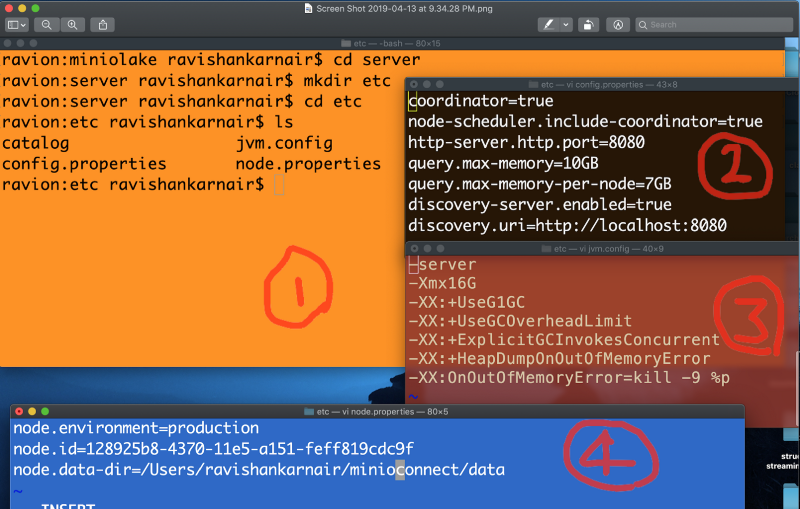
您需要三个配置文件,以及一个名为“catalog”的目录,该目录必须位于一个新创建的名为“etc”的目录中,该目录必须位于解压缩的服务器文件夹中。步骤和文件如下所示。
3. 配置 Presto 以使用文件元存储和 S3Select
现在是精彩的部分。我们现在将目录“catalog”保持为空。这是 Presto 需要所有连接器的地方。您可以配置 Hive 连接器并连接到 MinIO——我在我的 第二部分文章中介绍过。要使用 Hive 元存储,Hive 需要运行并且元存储服务需要启动。我们从未有机会启用 S3Select 以启用下推谓词 到底层的 MinIO。现在这种方法已经过时了 :)。我们将改进架构以适应最新和最佳实践。让我们从在我们的目录“catalog”中编写一个 MinIO.properties 文件开始,以包含文件元存储和 S3Select。如下所示:
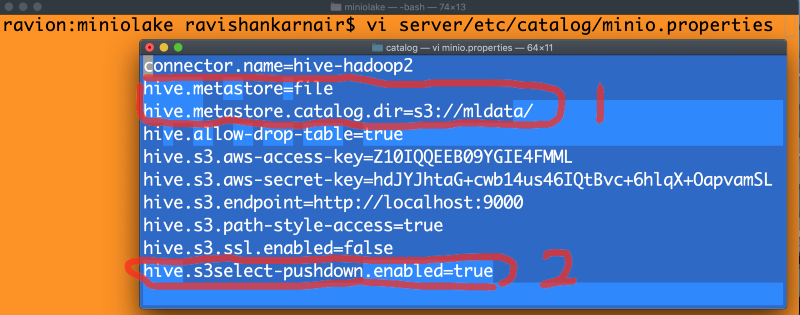
以上配置是本文最重要的部分。最好注意标记为 1 的两行和最后一行标记为 2 的行。其他行都是不重要的。
在第 1 行中,我们在 Presto 中使用了 hive-hadoop2 连接器,但我们说的是,不要使用传统的基于 Thrift 的 Hive 元存储,而是使用 MinIO S3 存储桶(在步骤 1 中创建)作为元存储。通过这样做,您无需在您的机器学习或数据生态系统中安装任何 Hadoop 或 Hive 的痕迹。
在第二部分中,我们在 Presto 中启用了 S3Select。只需一行代码,MinIO 就可以处理下推谓词请求。如果您没有启用它,那么所有数据都将传到 Presto,包括过滤,这会对查询的性能产生负面影响,尤其是在查询包含条件和来自存储在存储桶中的多个表的联接时。
关闭文件。现在您可以启动 Presto 服务器。我假设您的 MinIO 服务器正在运行。通过从服务器目录发出以下命令来启动 Presto。
我们现在创建了一个一流的数据湖。
接下来,我们将创建一个指向文件“input.csv”的表,该文件存在于步骤 1 中创建的“mldata”存储桶中。我们将使用 Presto CLI(命令行界面,我们已经在我们的“MinIOlake”目录中下载了此 jar 文件)。输入以下命令以创建表。在这里,我假设我们在 MySQL 中有一个名为“games”的模式下的表。
(使用标准 SQL 从我们之前讨论的篮球比赛统计数据创建表),我们将使用 Presto 的 CTAS(创建表为...)命令在 MinIO 中创建等效的表。这突显了 Presto 从现有数据库获取数据并将这些数据迁移到 MinIO 的强大功能。操作如下所示:
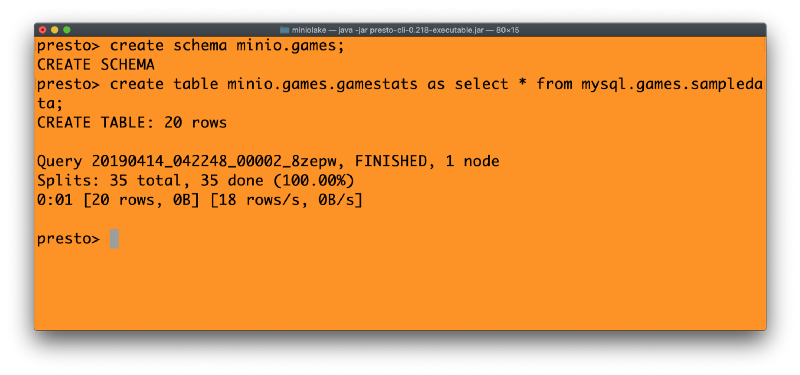
现在我们有了存储在 S3://mldata 中的表格,可以进行下一步操作了。请注意上面的表名 - MinIO.games.gamestats,这意味着我们使用了 MinIO 连接器(指向 S3://,即 MinIO 存储),一个名为“games”的模式,以及该模式中名为“gamestats”的表。元数据存储显然位于 MinIO 存储桶“mldata”中。
完全没有 Hive 元数据存储、Hadoop,因此无需外部启动元数据存储服务。
最后,在 Presto 中运行以下命令,并查看输出。
explain select * from MinIO.games.gamestats where outcome = ‘yes’
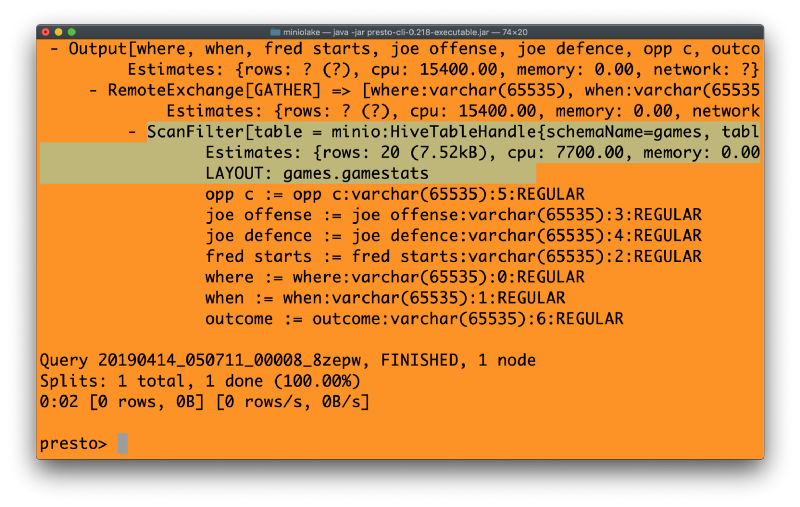
请注意上面代码中高亮的部分。我们看到的是使用“scanfilter”而不是“tablescan”。由于 Presto 仅操作相关信息,因此分析工作流程效率大大提高。这就是谓词下推逻辑的强大之处,也是 S3 Select 如此有效的原因。
此示例使用三台 DL-380 机器,每台机器配备 6 个 CPU、1 TB 内存和 32 GB RAM,用于在 MinIO 上对不同数据大小的过滤查询进行性能测试。X 轴表示查询的大小(以 GB 为单位),Y 轴表示时间。为了在网络上提供最佳性能,我使用了节点之间的专用 RDMA 和 NVMe 磁盘。网络带宽接近 65 GB/s。以下是结果。
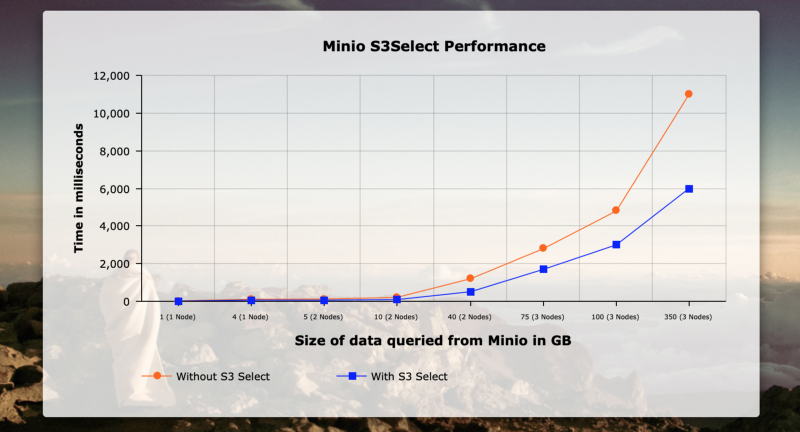
可以看出,随着数据大小的增长,性能提升开始显现,最终在仅 350 GB 的数据量下实现了 40% 到 50% 的提升。
4. 将 Weka 集成到 Presto JDBC 中
让我们更进一步。我们现在将在 Java 中编写一些代码,将 Weka 与 Presto 集成,Presto 已经准备好了具有 S3Select 功能的 MinIO 连接器。我们需要对 Weka 代码进行一些调整,以便无缝集成 Presto JDBC。下面说明了实现此目的的步骤。
步骤 1:确保已安装 Java 8 SDK。从 这里下载 Weka 快照。解压缩下载的文件以获取以下文件。
步骤 2:进入 **weka** 目录。按如下方式解压缩 weka-src.jar 文件。
步骤 3:将 presto-jdbc jar 文件从您的 MinIOlake 目录复制到解压缩源代码中的 lib 文件夹。
步骤 4:回到步骤 2,weka 文件夹。打开 build.xml。找到名为“compile”的 ant 目标(Apache ANT 是 Weka 用于构建发行版 jar 的构建工具)。添加以下几行以将 JDBC jar 文件扩展到类中,以便最终的 jar 文件也包含我们的 JDBC。添加高亮部分。如果您知道如何在 Java 中操作类路径,则可以省略此步骤。
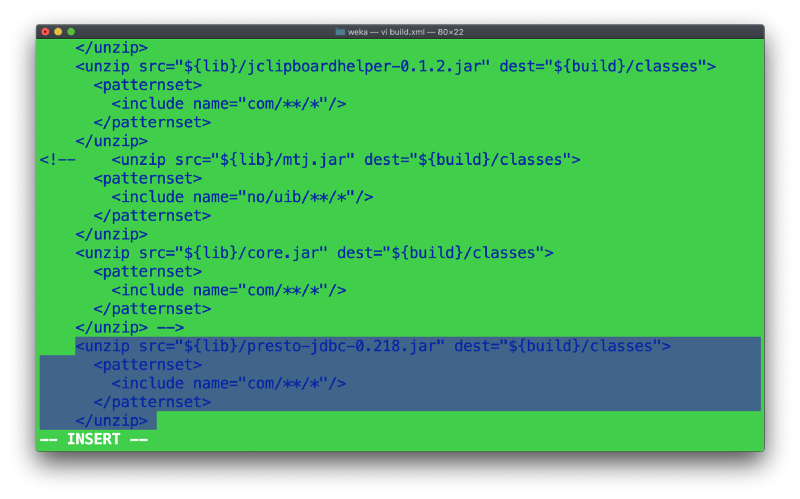
步骤 5:创建以下文件的副本。
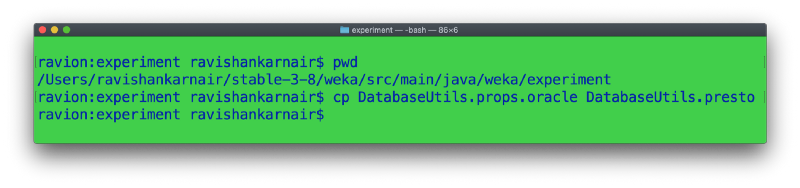
这里需要解释一下。Weka 并不理解宇宙中所有数据库的所有数据类型。我们需要提供一个映射文件,该文件指定如何解释源数据库类型。此外,驱动程序名称和部分也在此文件中指定。由于我们的数据类型与 Oracle 非常相似,因此我们创建了一个副本。高级用户可以创建自己的文件。
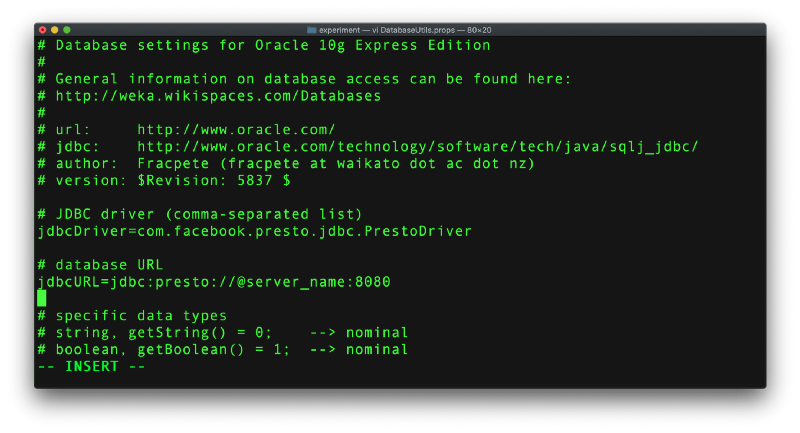
步骤 6:编辑上述文件,添加驱动程序名称和服务器/端口详细信息,如下所示,并将文件保存为 DatabaseUtils.props。请检查数据类型,如下一张截图所示。Weka 将拥有此文件,但请随意覆盖。

步骤 7:构建一个全新的 jar 文件。转到步骤 2,weka 文件夹,然后键入“ant exejar”。假设:您已安装 ANT。如果您没有安装,请 按照这里的说明操作。
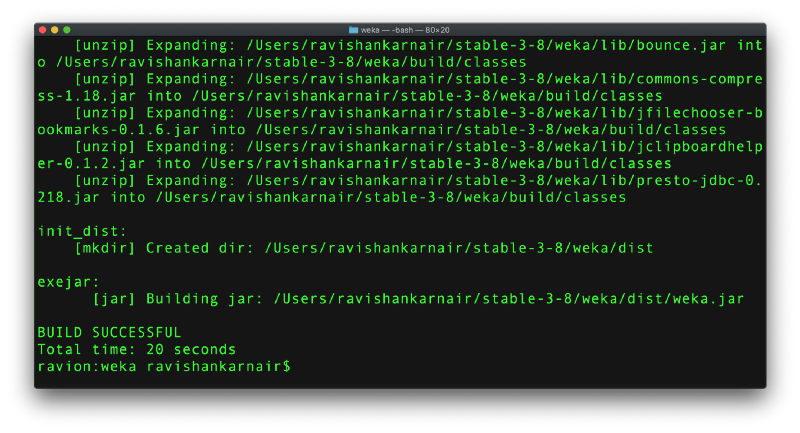
如您所见,ANT 创建了一个名为 dist 的新文件夹,并提供了一个名为 weka.jar 的 jar 文件。此 jar 文件是我们将在后续步骤中使用的文件。
5. 机器学习:使用 Weka 对 MinIO 中的数据进行决策树分析
此时,我们构建了一个强大且现代化的数据湖和分析平台。让我们对我们的样本数据应用主要的分类算法之一——决策树,并使用 Weka 进行分析。由于我们已创建了 Presto 连接器,因此 Weka 将连接到 Presto,并从 MinIO 中提取数据。在继续下一步操作之前,快速检查一下:您必须同时运行 MinIO 和 Presto。
步骤 1:从我们创建分发 jar 的 dist 目录启动 Weka。
java -jar weka.jar
点击“Explorer”(资源管理器)
继续到窗口下方。
您将看到一个 SQL 查看器窗口。URL 将显示 jdbc:presto://@servername:8080。将 @servername 更改为 localhost,因为我们的 Presto 在本地运行。您可以点击右侧的第一个按钮来设置用户名和密码。输入任意用户名(在我的例子中是 MinIO),并将密码留空。如果您在 Presto 中启用了身份验证并配置了 https,则需要提供有效的用户 ID 和密码。
步骤 2:点击“确定”后,再点击右侧的第二个按钮,您将看到“信息”窗格显示状态。现在编写我们的查询。
select * from minio.games.gamestats //结尾不要加分号
点击执行按钮。瞧!**我们的第一个 MinIO 浏览器正在运行。**
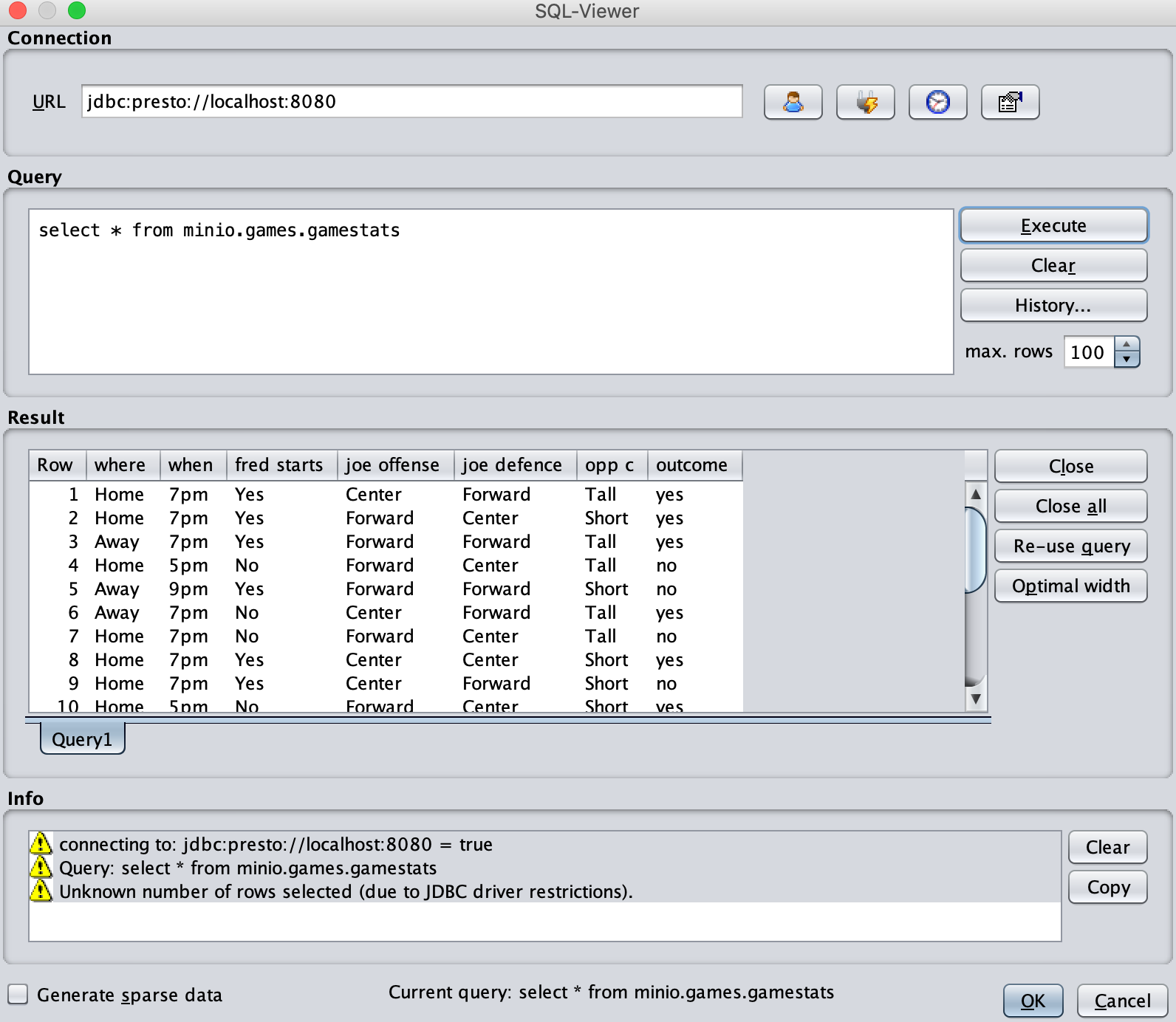
现在点击“确定”按钮。您不应该收到任何与数据类型相关的错误。如果您看到错误,请回顾我们之前更改过的 DatabaseUtils.props 文件,并再次仔细检查。
现在,您将获得强大的 Weka“预处理”屏幕,您将在其中看到
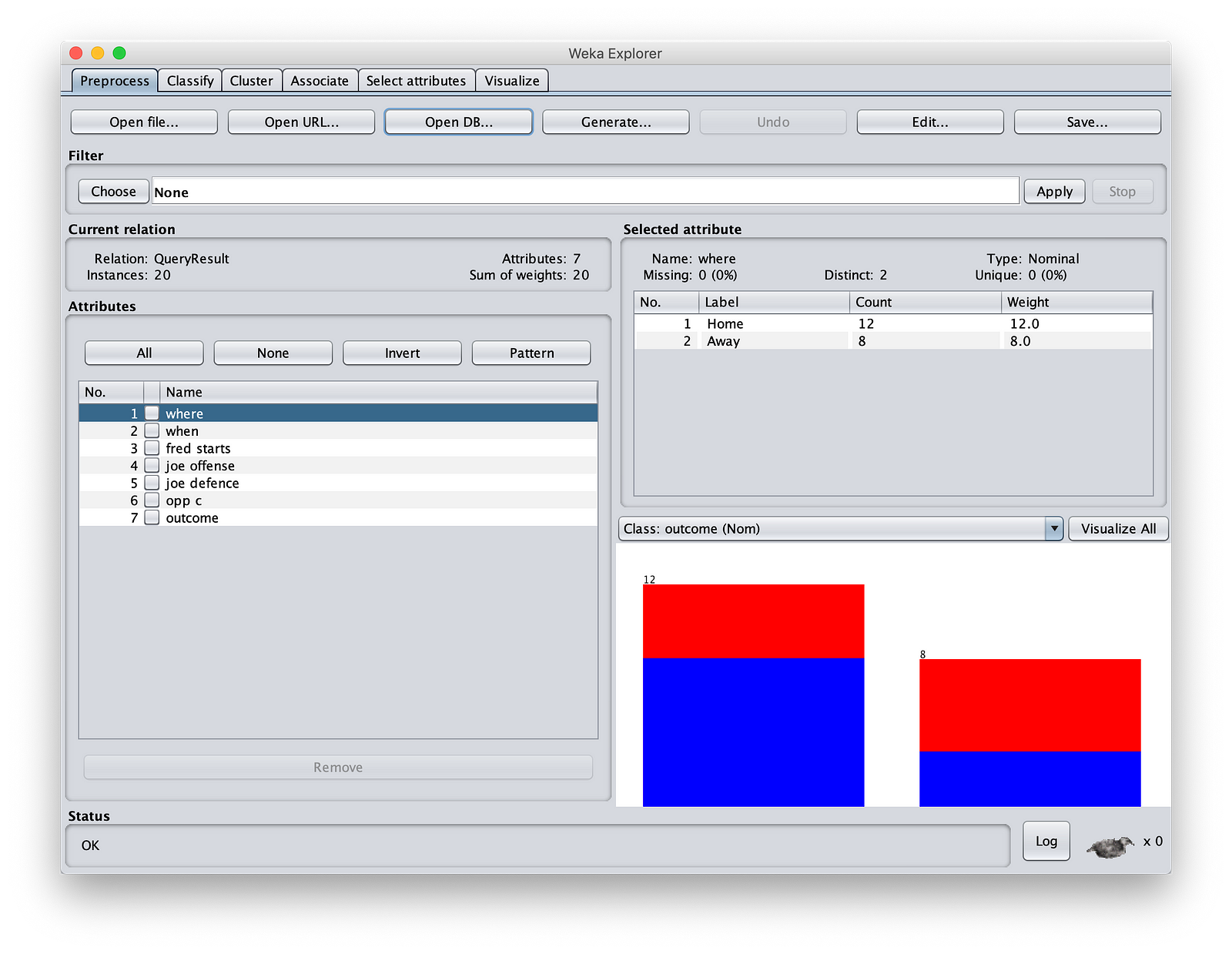
步骤 3:让我们开始我们的机器学习操作。通常,当您像上面那样引入数据时,列可能混合了不同数据类型。一些列可能是分类的(列出可能的值,通常是字符串)或连续的(离散数字)。您可能需要进行数据清理和转换。Weka 通过一系列惊人的过滤器支持此操作。您可以通过点击“Filter”(过滤器)来查看。我们甚至可以使用选项将某些值替换为空值(如果您的数据稀疏),或者可以删除可能不会为您的机器学习逻辑添加任何价值的无关值。例如,员工 ID 可能在贷款申请结果预测中不起任何作用。您可以在 Spark 中使用 StringIndexer 来转换数据类型。
对于决策树,请点击“classify”(分类)按钮。您将在左侧看到一个窗口,其中包含 Weka 支持的所有类型的算法。选择“trees”(树)并选择 J48。
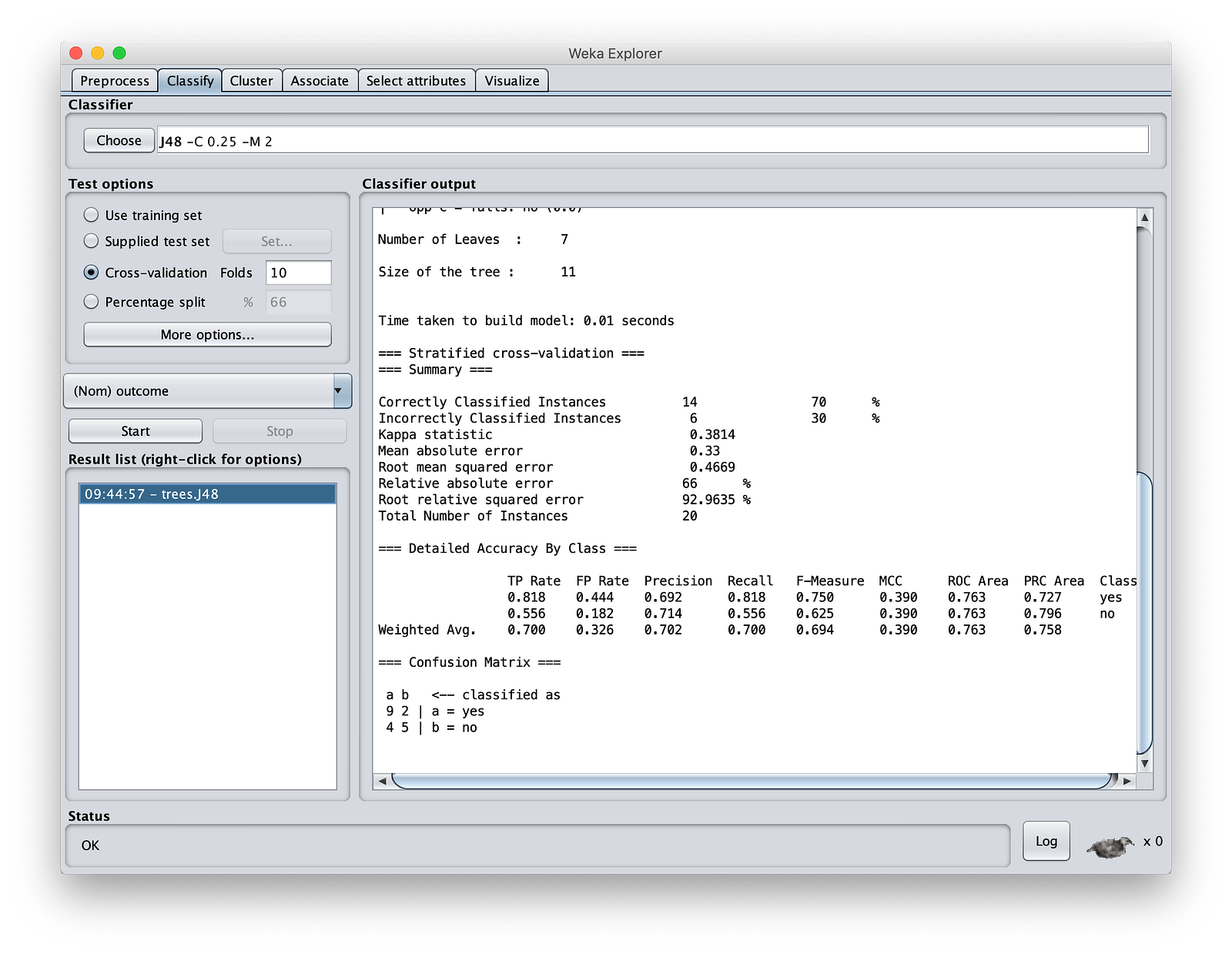
点击“Start”(开始)。让其余选项保持默认值。作为机器学习专家,您知道这些选项是什么。请注意,我们创建了一个准确率为 70% 的模型。对于像我们这样的一小组实验数据,这很好,因为我不打算进一步调整它。
将模型保存在您的 MinIOlake 文件夹中(不要保存在 MinIO 存储中,因为 Weka 无法读取 S3:// 协议)。将其命名为“MinIOdtree.nodel”。
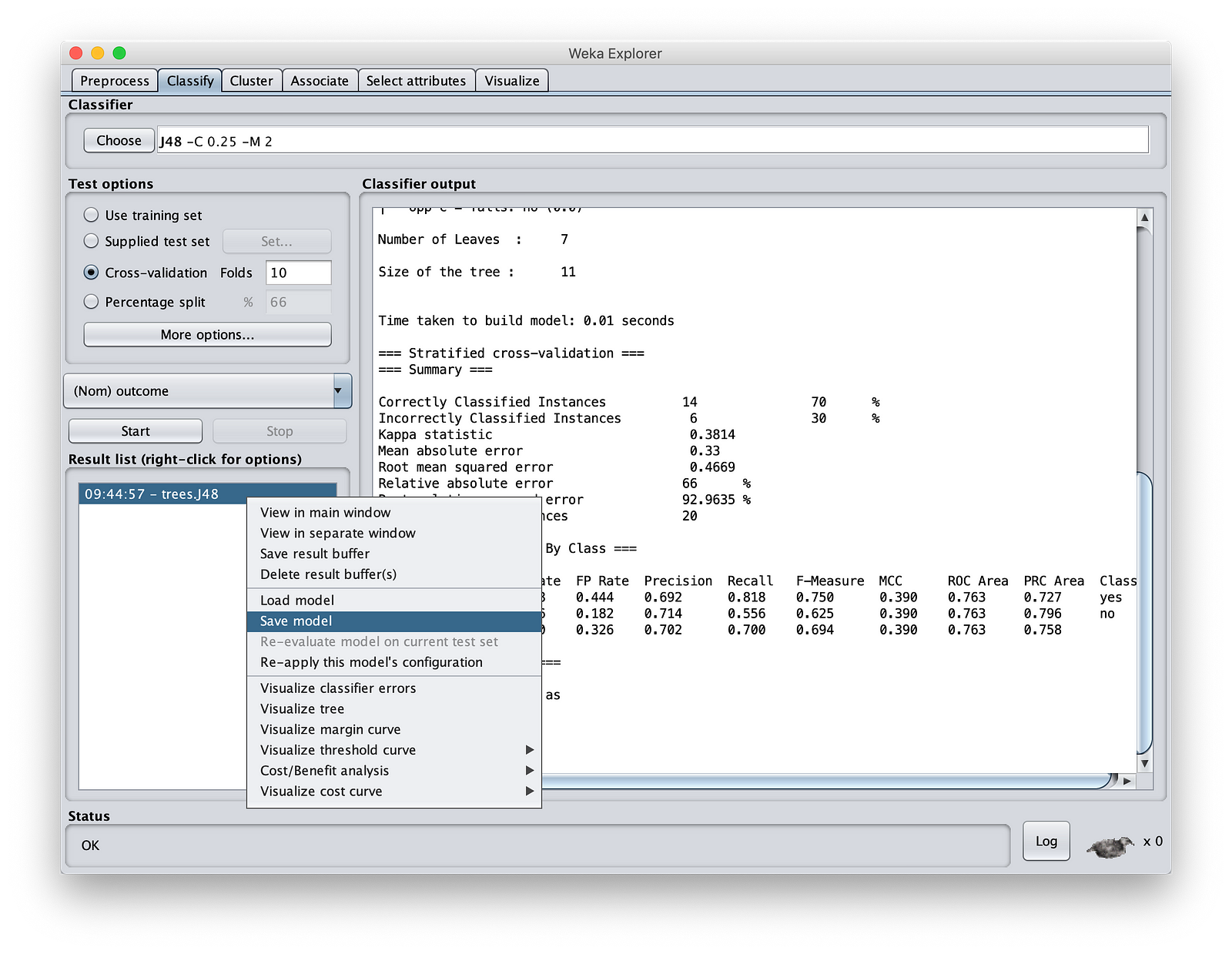
6. 测试我们的决策树模型
现在让我们测试我们的模型。为此,我们将创建一个包含两行的文件,其中我们不知道我们的预测结果。将该文件命名为 Test.csv。如下所示。
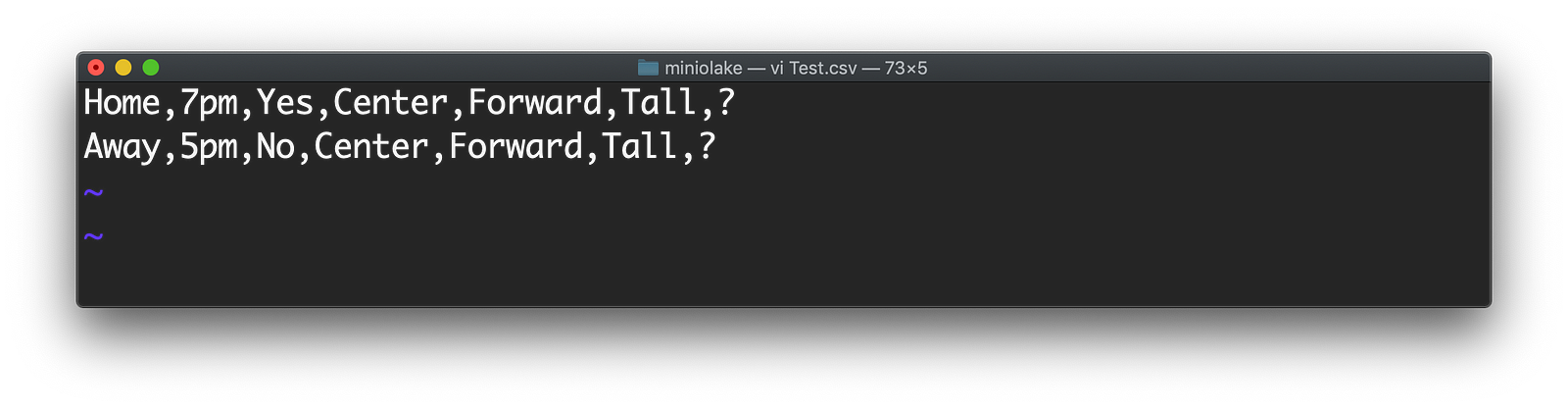
观察“?”标记。我们不知道结果会是什么,我们希望 Weka 使用我们创建的模型告诉我们。
步骤 1:启动 Weka。只需点击“文件”按钮,并提供任意文件。我们不会使用此文件。如果您正在读取 CSV 文件,请更改文件类型。在 Weka 中,除非您提供一些输入文件,否则您无法打开“Classify”(分类)部分。在“Classify”(分类)中,转到“Result List”(结果列表)窗口,右键单击并加载您在上一步中保存的模型。如下所示。
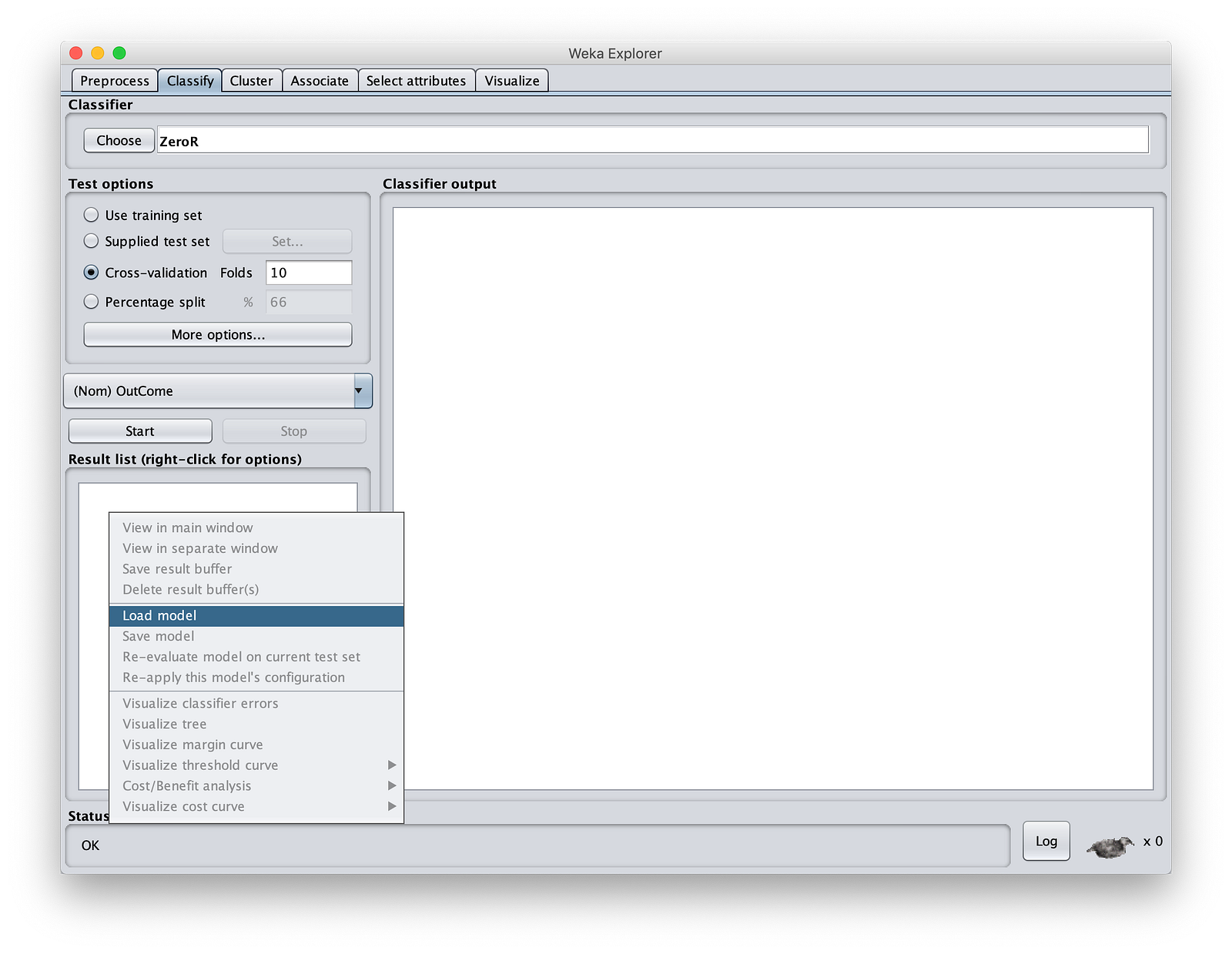
选择“MinIOdtree.model”。然后点击“Test Options”(测试选项)中的“Supplied test set”(提供的测试集)。转到 MinIOlake 文件夹,并将“Test.csv”作为输入。
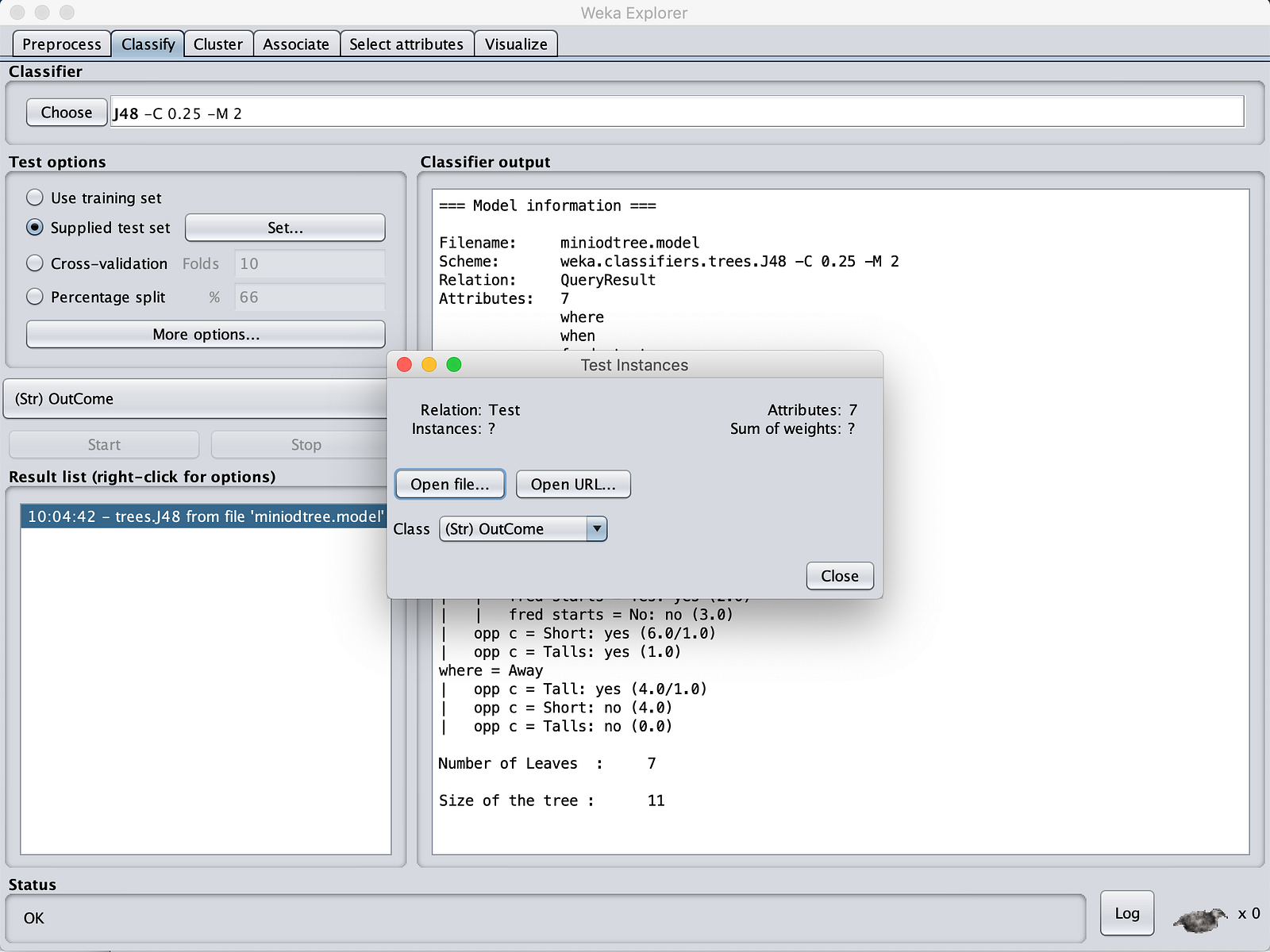
现在点击“More Options”(更多选项)。确保输出类型为“Plain Text”(纯文本)。
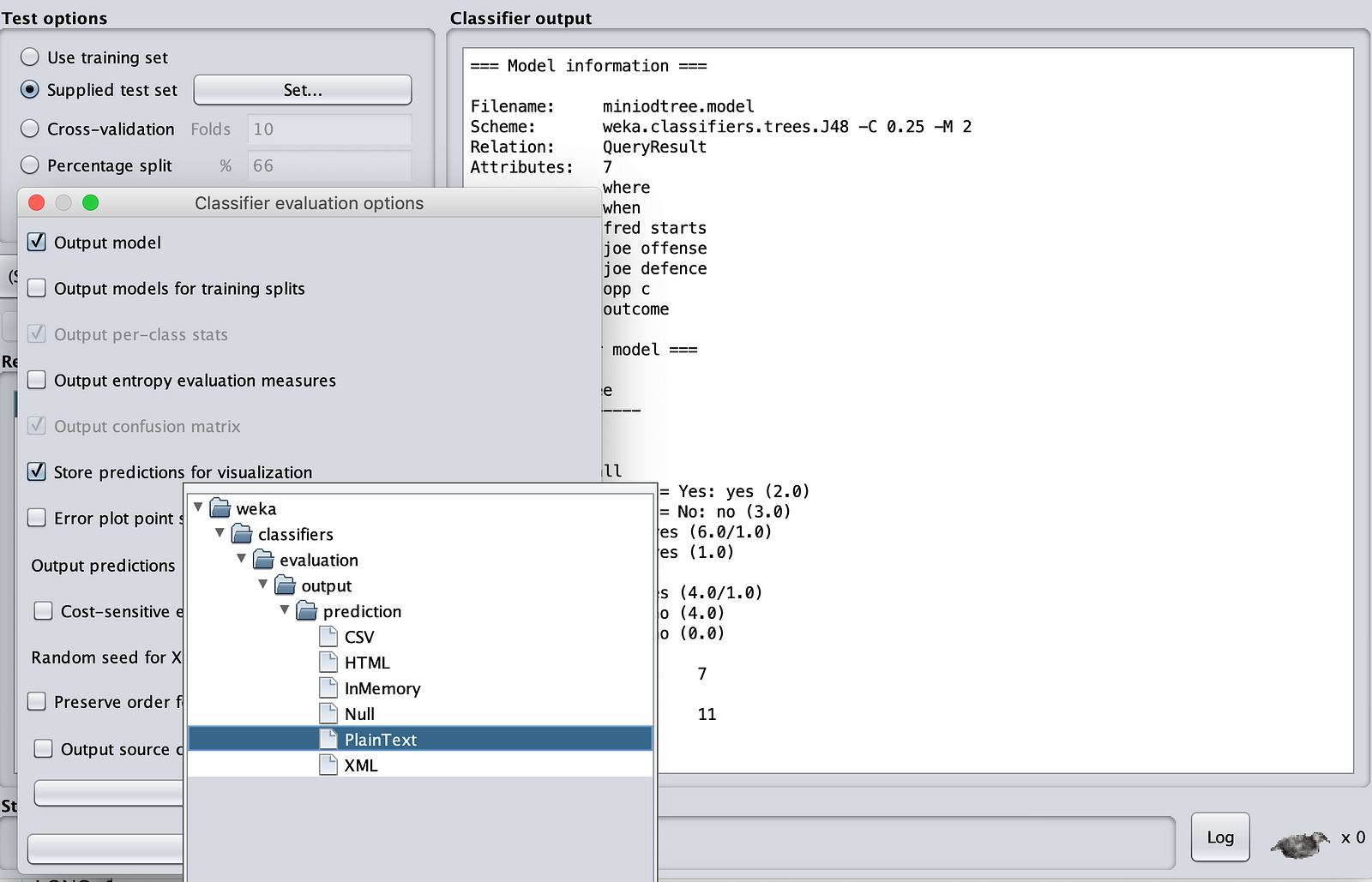
完成此操作后,右键单击“Result List”(结果列表)窗格。点击“Re-evaluate model on current test set”(在当前测试集上重新评估模型)。
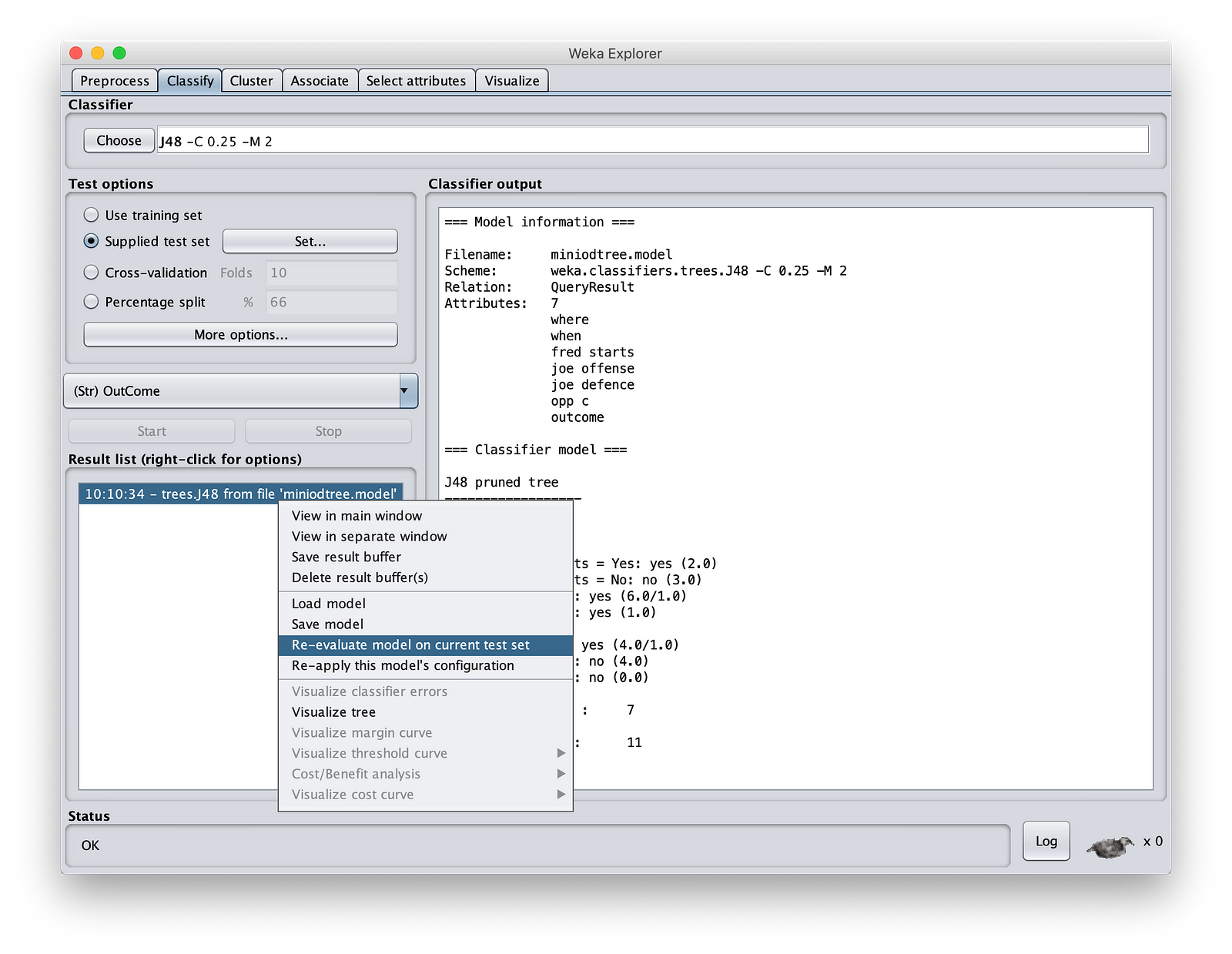
就是这样。您已经使用我们的模型预测了结果。
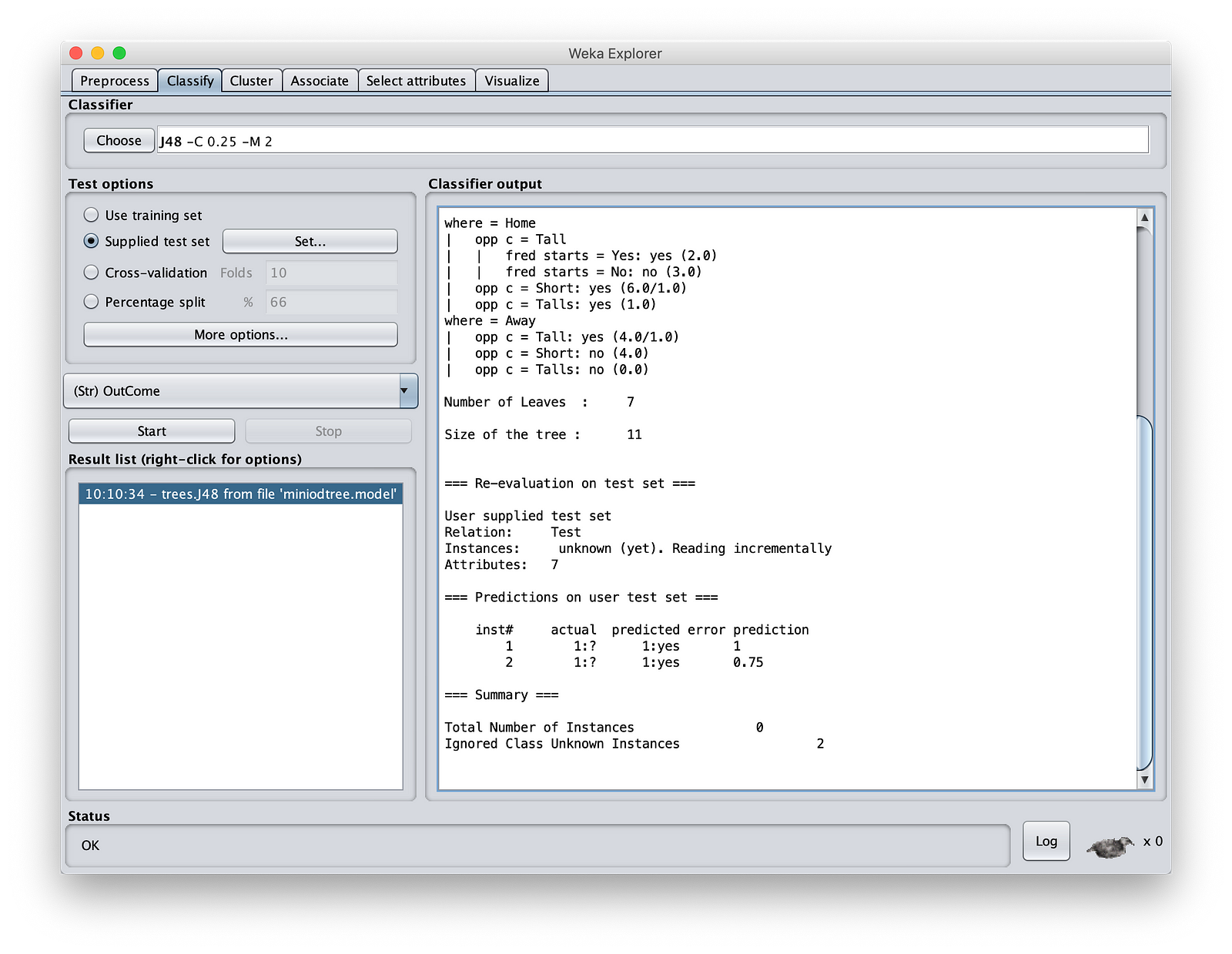
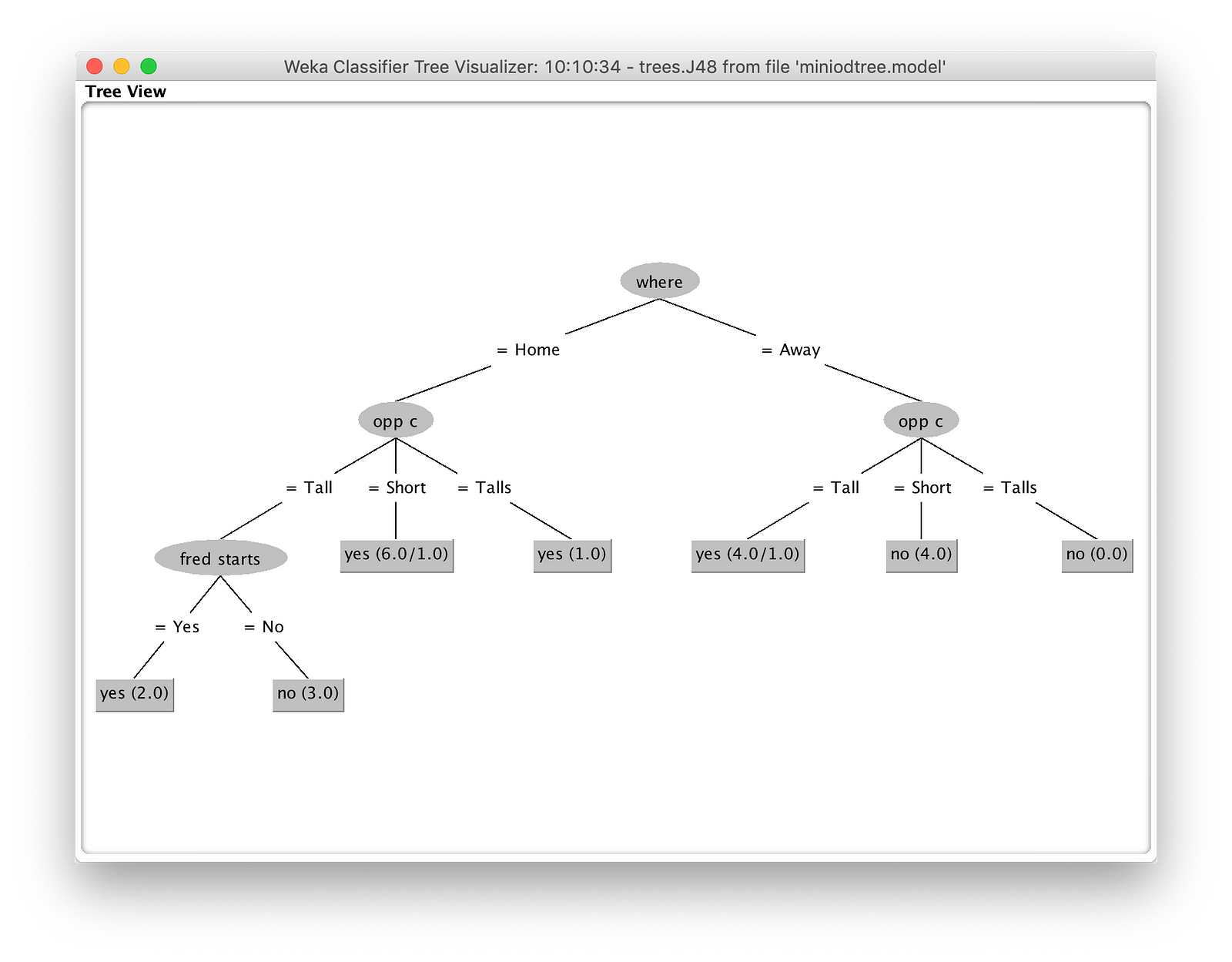
最后,您可以在 Wek 中可视化树。右键单击“Result List”(结果列表)窗格,然后选择“Visualize Tree”(可视化树)以查看模型将如何评估。
额外内容:从 R 连接 MinIO
你们中的一些人可能是铁杆 R 程序员,引入 Weka 对他们来说可能没有多大兴趣。对于那些 R 爱好者,这里有一个想法。
- 下载 RPresto 包并安装到您的 R 环境中。
- 请确保 Presto 和 MinIO 正在运行。同样,没有 Hive。
- 以下是代码。
install.packages(“RPresto”)
install.packages(“dplyr”)
install.packages(“dbplyr”)
my_db <- src_presto(catalog = “MinIO”, schema = “games”, user = “ravi”, host = “localhost”, port = 8080, session.timezone=’US/Eastern’)
my_tbl <- dplyr.tbl(my_db, “gamestats”)
my_tbl
4. 生成了以下输出。
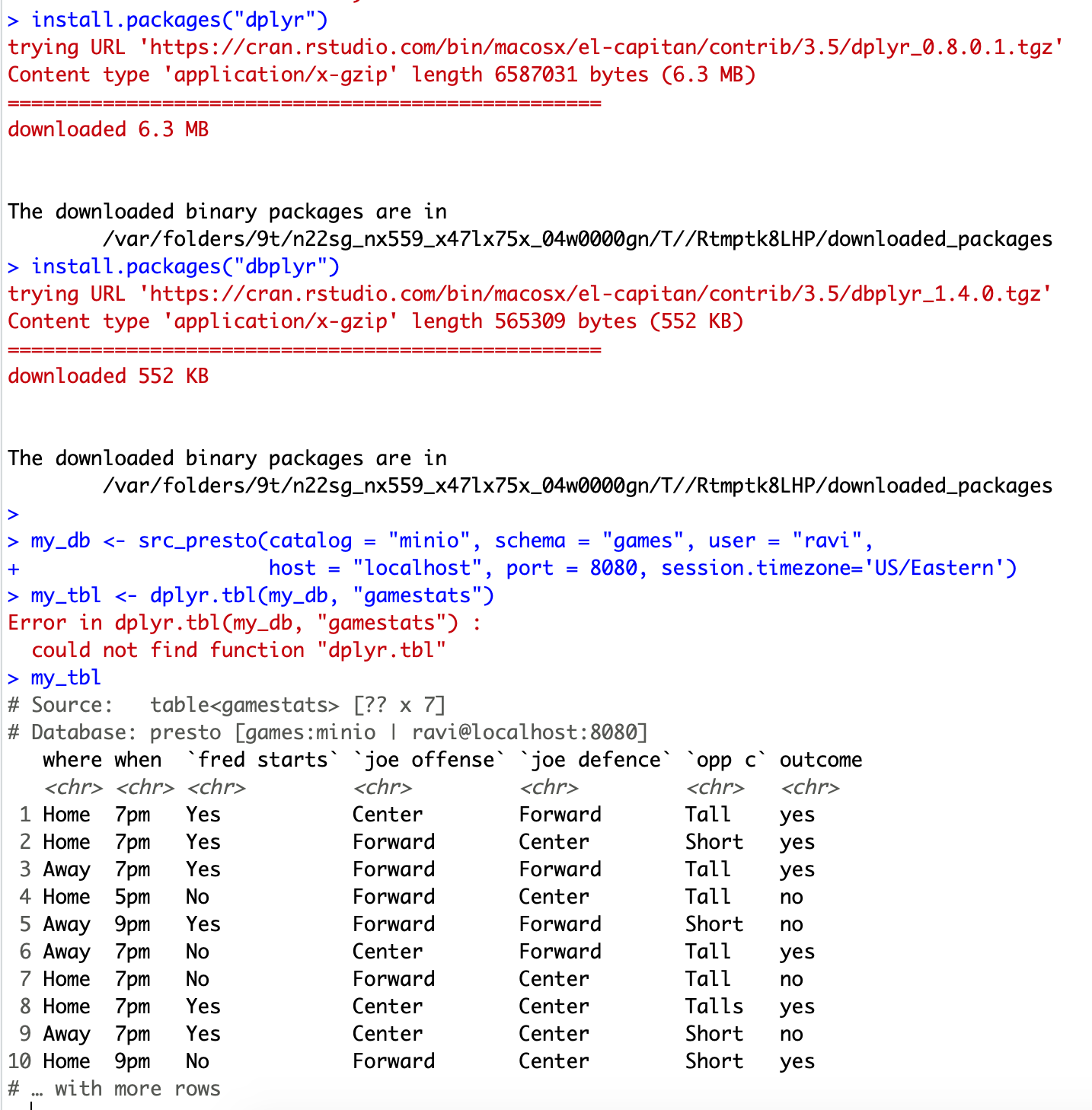
使用变量 my_tble,现在您可以在 R 中编写所有您喜欢的代码。
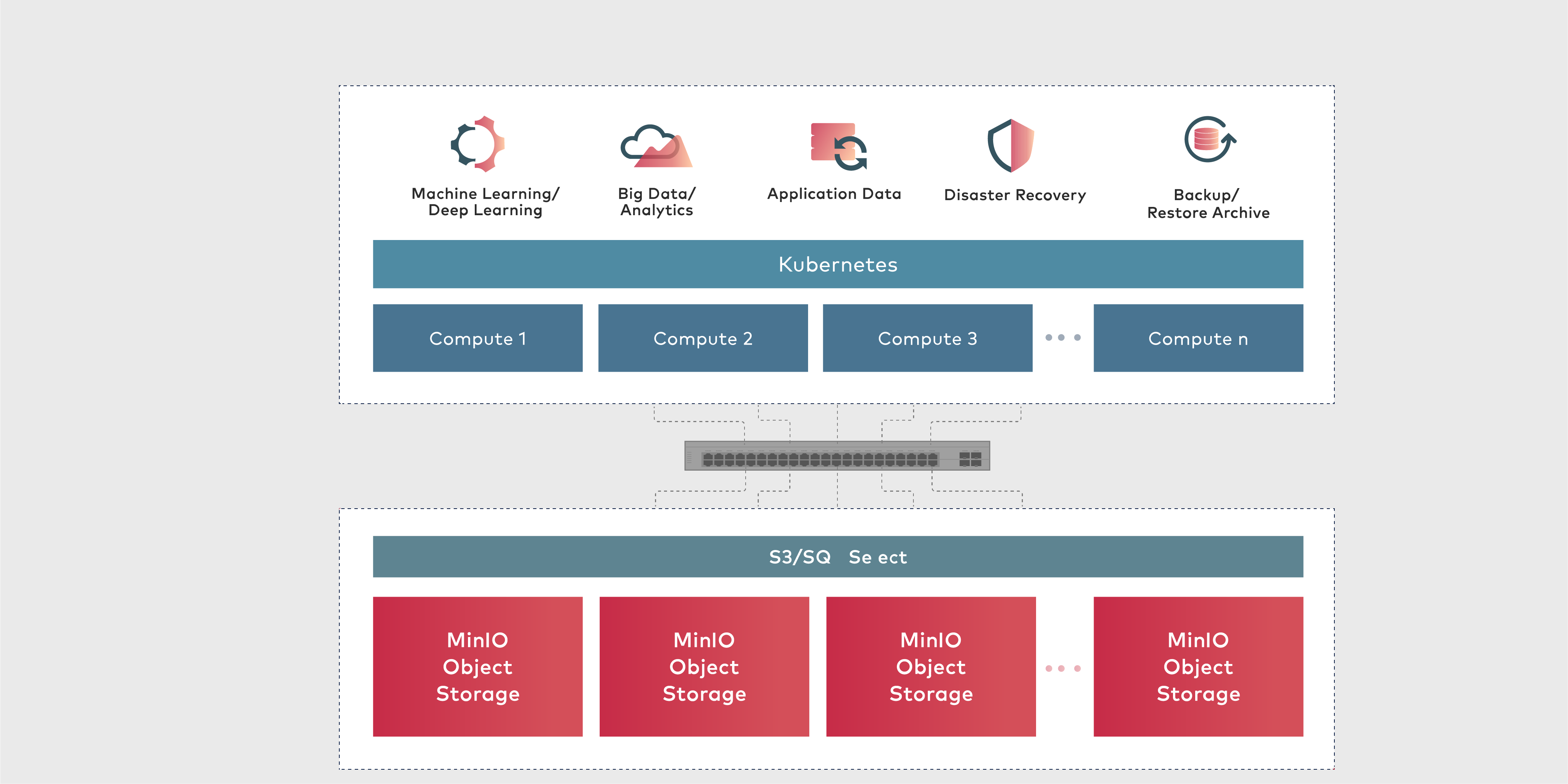
为了总结,让我们绘制一个我们所做工作的架构图。
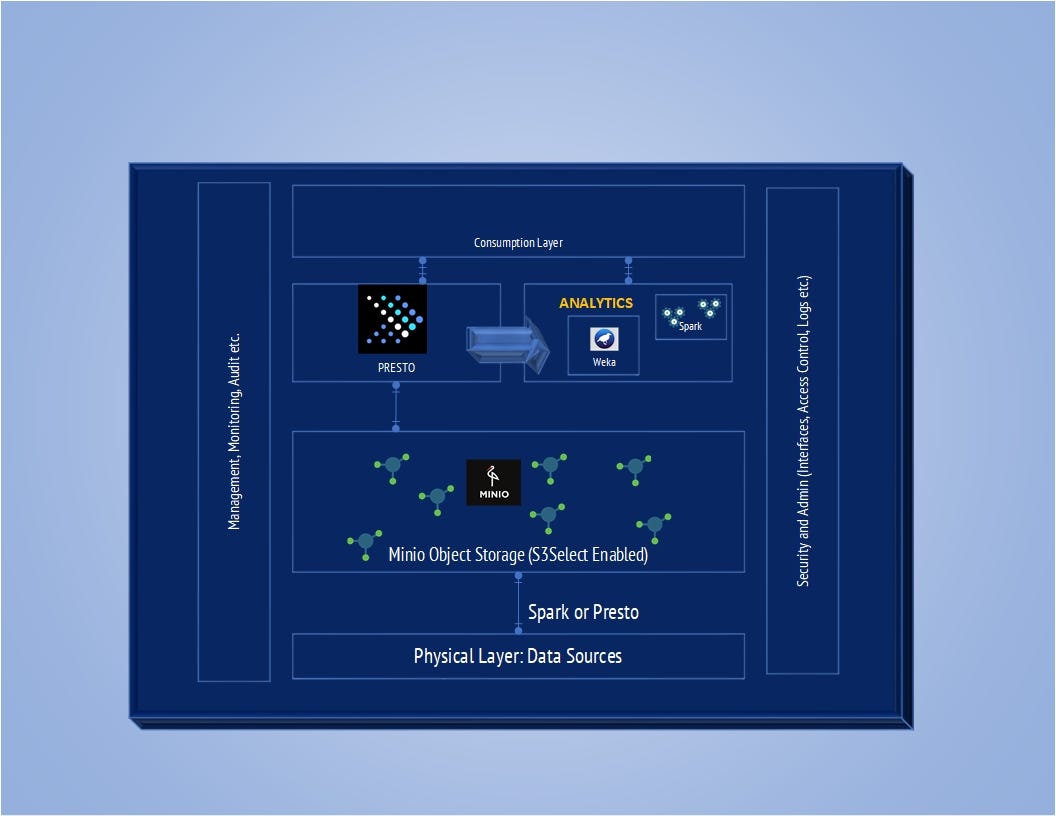
我使用了一台 64 GB 的服务器,可以对大约 12 亿行 8 个属性的数据进行建模。您可以集群 MinIO、集群 Presto 以获得更多改进。您可以使用带有 RDMA 连接器的 NVMe 磁盘以获得更快的吞吐量。
希望这篇文章已经证明了具有 MinIO 对象存储功能的高级分析框架是多么简单且强大。如果您需要更多支持或想继续讨论,请通过 LinkedIn 与我联系。