在我之前所有关于 MinIO 的文章中,如果需要编写代码,我都会使用 MinIO 的 Python SDK,其文档在此。我更喜欢这个 SDK,因为它易于使用,并且提供了对 MinIO 企业功能的编程访问,例如生命周期管理、对象锁定、Bucket 通知和站点复制。(在我的文章AI/ML 对象管理中,我展示了如何使用代码设置生命周期管理和对象锁定。)如果您的应用程序正在以编程方式设置 Bucket 并且需要这些功能,那么 MinIO SDK 是一个不错的选择。但是,MinIO 兼容 S3,您可以使用任何实现 S3 的 SDK 连接到 MinIO。
另一个流行的 S3 访问 SDK 是亚马逊的S3 客户端,它是其botocore库的一部分——一个到 AWS 上许多服务的低级接口。此库也适用于 MinIO,并且提供了访问我之前提到的所有企业功能。如果您正在考虑迁移应用程序及其数据从 AWS 到您本地数据中心的 MinIO,那么您无需更改任何代码。只需更改配置中的 URL、访问密钥和密钥,即可完成。
还有一个选择是S3fs 库。它不提供对 MinIO SDK 和 S3 客户端等企业功能的访问,但易于使用,许多其他库和工具(如 PyArrow 和 MLFlow)使用其类来设置 S3 数据源。
在这篇文章中,我将使用 S3fs Python 库与 MinIO 交互。为了使事情更有趣,我将创建一个小型数据湖,用市场数据填充它,并为希望分析股票市场趋势的人创建股票走势图。
本文中显示的所有代码都可以在此处找到。
安装所需的库
除了 s3fs 库之外,我们还需要 Yahoo Finance 库来下载历史市场数据。我还要使用 Seaborn 和 Matplotlib 来绘制股票图表。可以使用以下命令安装这四个库。
pip install matplotlib pip install s3fs pip install seaborn
pip install yfinance |
下载市场数据
在过去十年中,市场观察人士习惯于发明新术语来指代最热门的股票。2013 年,吉姆·克莱默创造了 FANG 这个词——一个指代 Facebook、亚马逊、Netflix 和谷歌的首字母缩略词。2017 年,投资者开始将苹果纳入该组,首字母缩略词变成了 FAANG。当 Facebook 将其名称更改为 Meta 并且 Google 重塑品牌为 Alphabet 时,首字母缩略词进一步发展为 MAMAA。
现在,在 2024 年,我们有一个新的标签:七巨头。七巨头由苹果、亚马逊、Alphabet、Meta、微软、英伟达和特斯拉组成。让我们使用 Yahoo Finance 库下载 2023 年全年七巨头的市场数据。
import datetime
import os import yfinance as yf
start_date = datetime.datetime(2023, 1, 1)
end_date = datetime.datetime(2023, 12, 31)
download_dir = os.path.join(os.getcwd(), 'marketdata')
magnificient_seven = ['AAPL', 'AMZN', 'GOOGL', 'META', 'MSFT', 'NVDA', 'TSLA']
for ticker_string in magnificient_seven:
ticker = yf.Ticker(ticker_string)
historical_data = ticker.history(start=start_date, end=end_date)
file_path = os.path.join(download_dir, f'{ticker_string}.parquet')
historical_data.to_parquet(file_path)
print(f'{ticker_string} 下载完成.') |
如果成功,输出结果将为
AAPL 下载完成.
AMZN 下载完成.
GOOGL 下载完成.
META 下载完成.
MSFT 下载完成.
NVDA 下载完成.
TSLA 下载完成. |
设置 S3 连接
首先,我们需要创建一个 S3FileSystem 对象。与 S3 数据源交互所需的所有方法都挂载在这个对象上。以下代码将从环境变量中获取 MinIO 的端点、访问密钥和密钥,并创建一个 S3FileSystem 对象。
from s3fs import S3FileSystem
key = os.environ['MINIO_ACCESS_KEY']
secret = os.environ['MINIO_SECRET_ACCESS_KEY']
endpoint_url = os.environ['MINIO_URL']
s3 = S3FileSystem(anon=False, endpoint_url=endpoint_url,
key=key,
secret=secret,
use_ssl=False) |
创建存储桶
一旦我们拥有了一个 S3FileSystem 对象,就可以使用它来创建存储桶。makedir() 函数可以完成此操作。下面的代码首先检查存储桶是否存在,然后再创建它。makedir() 函数有一个 exist_ok 参数,你可能会认为如果存储桶已存在,则此参数将允许 makedir 成功完成。不幸的是,我发现事实并非如此。如果存储桶已存在,无论此参数如何设置,此函数都会抛出异常。因此,最好显式检查存储桶是否存在,并且仅在存储桶不存在时才调用 makedir()。
bucket_name = 'market-data'
if not s3.exists(bucket_name):
s3.makedir(f's3://{bucket_name}', exist_ok=True) |
上传市场数据
要将对象上传到我们新创建的存储桶,我们将使用 s3fs 的 put_file() 函数。此函数会将单个文件上传到 S3 对象存储中的目标位置,在本例中为 MinIO。它以本地源文件和远程路径作为参数。
magnificient_seven = ['AAPL', 'AMZN', 'GOOGL', 'META', 'MSFT', 'NVDA', 'TSLA']
for ticker_string in magnificient_seven:
local_file_path = os.path.join(download_dir, f'{ticker_string}.parquet')
remote_object_path = f'{bucket_name}/{ticker_string}.parquet'
s3.put_file(local_file_path, remote_object_path)
print(f'{ticker_string} 已上传。) |
S3fs 还提供了一个 put() 函数,该函数会将本地目录的全部内容上传到指定路径。如果您的本地目录包含子文件夹,它甚至还具有递归开关。
上述代码完成后,您的 MinIO 存储桶将如下面的屏幕截图所示。
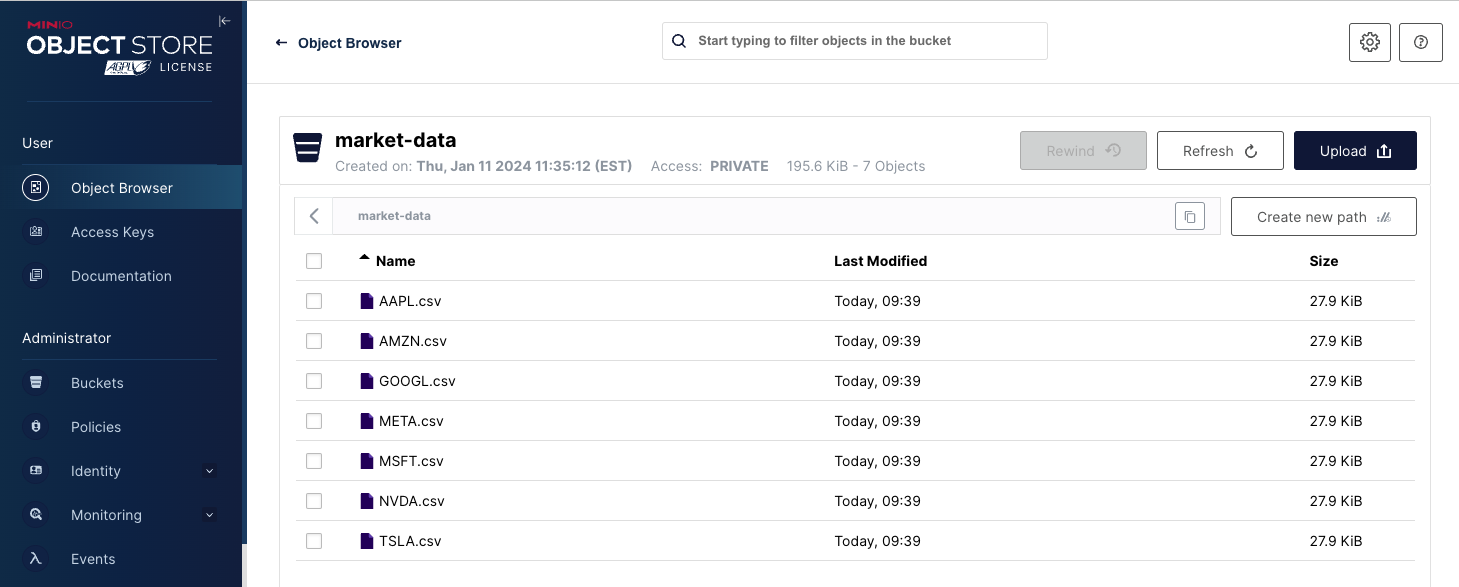
列出对象
列出存储桶中的对象非常简单。s3fs 对象有一个 ls() 方法,它以远程位置作为参数。如下所示。
object_list = s3.ls(f's3://{bucket_name}', detail=False)
object_list |
当您调用 detail 参数设置为 False 的 ls() 方法时,返回值将是一个简单的 Python 列表,其中包含路径中所有对象的完整路径引用。当您需要一个循环遍历的列表时,请使用此版本的 ls()。下面显示了 Magnificent Seven 对象的列表。
['market-data/AAPL.csv',
'market-data/AMZN.csv',
'market-data/GOOGL.csv',
'market-data/META.csv',
'market-data/MSFT.csv',
'market-data/NVDA.csv',
'market-data/TSLA.csv'] |
如果您需要此函数返回更多详细信息,则将 detail 参数设置为 True。下面显示了显示详细信息的示例输出。(为简洁起见已截断。)
[{'Key': 'market-data/AAPL.parquet',
'LastModified': datetime.datetime(2024, 1, 12, 14, 39, 12, 124000, tzinfo=tzutc()),
'ETag': '"03e6abc232e58b1d83aa0b175ae04cf3"',
'Size': 28612,
'StorageClass': 'STANDARD',
'type': 'file',
'size': 28612,
'name': 'market-data/AAPL.csv'}, ... |
Pandas 集成
如前所述,许多第三方库使用 s3fs 的 S3FileSystem 类来与兼容 S3 的对象存储进行交互。以下代码展示了如何使用 Pandas 将 MinIO 中的对象读取到 Pandas DataFrame 中。
import pandas as pd
ticker_string = 'NVDA'
storage_options={
'key': key,
'secret': secret,
'endpoint_url': endpoint_url,
}
historical_data = pd.read_csv(f's3://{bucket_name}/{ticker_string}.parquet', storage_options=storage_options)
historical_data.tail(10) |
输出结果
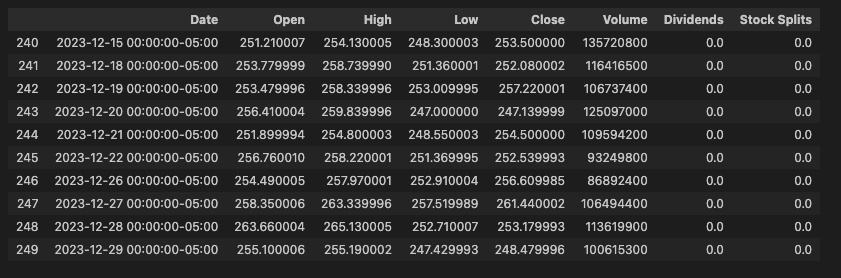
以上代码根本不需要文件系统就能将 MinIO 中的数据获取到 Pandas DataFrame 中。对于需要从原始数据创建数据集的数据科学家来说,这是一个非凡的功能。对于量化分析师来说,这也是一个强大的功能,因为 Pandas 基于 NumPy,可以创建数学算法来识别交易机会。
PyArrow 是另一个流行的库,它利用 s3fs 访问对象存储中的 S3。如果您正在处理大型对象,请考虑使用 PyArrow 的 S3 接口。
绘制市场数据
在结束之前,让我们再玩一点。我现在想做的是从 MinIO 中提取所有市场数据并将其加载到一个 DataFrame 中。这可以通过下面的代码使用 Panda 的 concat 函数来完成。请注意,我还需要添加一个股票代码列。
storage_options={
'key': key,
'secret': secret,
'endpoint_url': endpoint_url,
}
df_list = []
for ticker_string in magnificient_seven:
new_data = pd.read_parquet(f's3://{bucket_name}/{ticker_string}.parquet', storage_options=storage_options)
new_data['Ticker'] = ticker_string
df_list.append(new_data[['Ticker', 'Close']])
historical_data = pd.concat(df_list, axis=0)
historical_data[historical_data['Ticker']=='AMZN'].head() |
输出
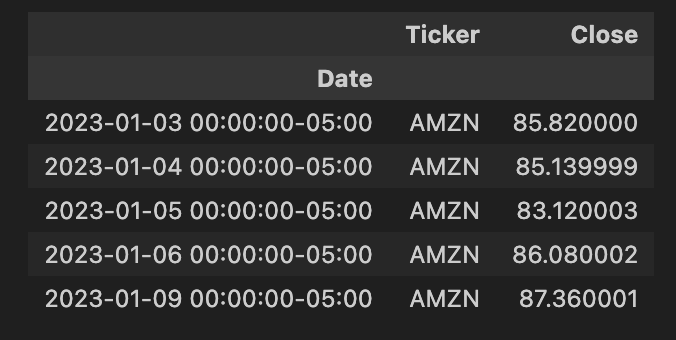
接下来,我们需要根据股票代码值对数据进行透视。
historical_data = historical_data.reset_index()
pt = historical_data.pivot(columns='Ticker', index='Date', values='Close')
pt.head() |
现在,我们透视后的数据看起来像下面的屏幕截图。
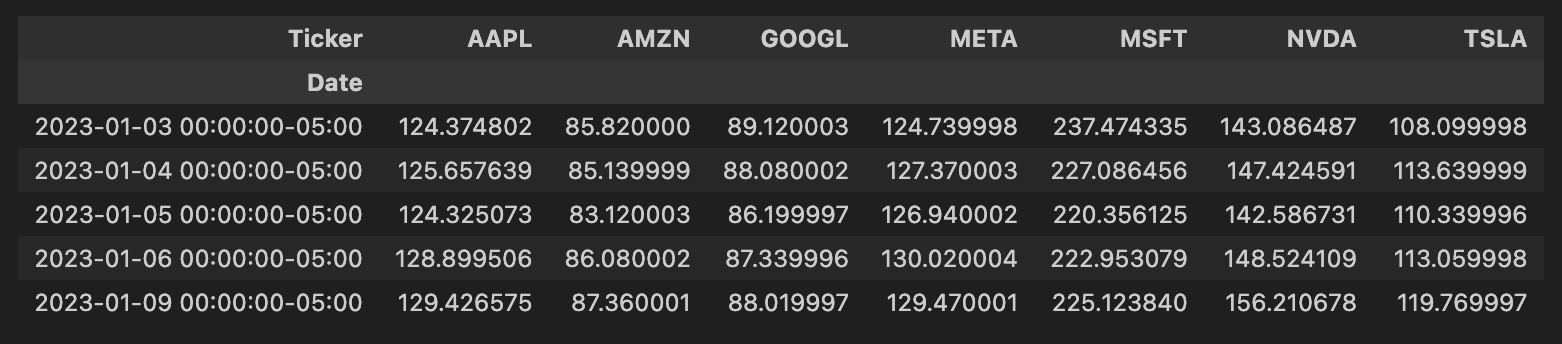
现在,我们可以使用下面的代码绘制“Magnificient Seven”。
import matplotlib.pyplot as plt
import seaborn as sns
# 使用 Seaborn 设置样式。
sns.set_style('ticks')
# 将所有收盘价绘制为累积收盘值。
((pt.pct_change()+1).cumprod()).plot(figsize=(10, 7))
plt.legend()
plt.title('七宗最')
# 定义标签
plt.ylabel('累积收盘价')
plt.xlabel('日期')
# 绘制网格线
plt.grid(True)
sns.despine()
plt.show() |
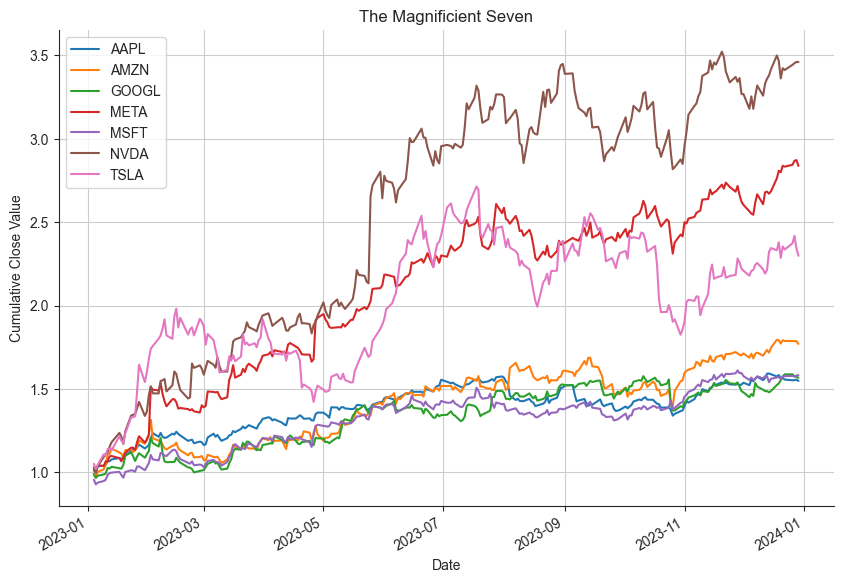
摘要
在这篇文章中,我们使用 MinIO 和 s3fs 库进行了一些有趣的尝试。我们下载了一些市场数据,使用 s3fs 库将其上传到 MinIO,然后再次使用 MinIO 的 S3 接口将数据集成到 Pandas 中。最后,我们使用 Matplotlib 和 Seaborn 对数据进行了可视化。
后续步骤
如果您一直关注我们的博客,那么您就会知道,我们像喜欢数据湖一样喜欢现代数据湖(也称为数据湖仓)。现代数据湖是一种集数据仓库和数据湖于一体的解决方案。这得益于开放式表格式(OTF),例如 Iceberg、Hudi 和 Deltalake。现代数据湖建立在对象存储之上,并允许与数据湖直接集成,同时提供一个处理引擎,能够通过 SQL 进行高级数据操作。如果您喜欢这篇文章中的内容并希望更进一步,那么请考虑构建一个现代数据湖。几个月前,我在这篇博文中展示了如何做到这一点:使用 Apache Iceberg 和 MinIO 构建数据湖仓。
立即下载MinIO,了解构建数据湖仓有多么容易。如果您有任何疑问,请随时在Slack上联系我们!
