SingleStore 是一个为数据密集型工作负载设计的云原生数据库。它是一个分布式、关系型 SQL 数据库管理系统,支持 ANSI SQL,并因其在数据摄取、事务处理和查询处理方面的速度而得到认可。SingleStore 可以存储关系型、JSON、图和时间序列数据,满足混合工作负载(如 HTAP)以及 OLTP 和 OLAP 使用案例。它将 SQL 查询编译成机器代码,并可以部署在各种环境中,包括本地安装、公有/私有云以及通过 Kubernetes 运算符部署在容器中。
现代数据湖架构
在现代数据湖架构中,SingleStore 恰好位于处理层。这一层是处理引擎(用于转换、为其他工具提供数据、数据探索和其他用例)所在的位置。处理层工具(如 SingleStore)与其他工具协同工作:通常多个处理层工具会从同一个数据湖中获取数据。通常,这种设计是在工具专业化的情况下实现的。例如,像 SingleStore 这样具有混合向量和全文搜索功能的超高速内存中数据处理平台,针对 AI 工作负载进行了优化,尤其是生成式 AI 使用案例。
先决条件
要完成本教程,您需要安装一些软件。以下是您需要安装的内容
安装:如果您是全新开始,Docker Desktop 安装程序提供了一种方便的一站式解决方案,用于在您的特定平台(Windows、macOS 或 Linux)上安装 Docker 和 Docker Compose。这通常比单独下载和安装它们更容易。
安装 Docker Desktop 或 Docker 和 Docker Compose 的组合后,您可以在终端中运行以下命令来验证它们的存在
docker-compose --version
您还需要 SingleStore 许可证,您可以在此处获取。
请记下您的许可证密钥和根密码。您的帐户将分配一个随机的根密码,但您可以使用 SingleStore UI 更改根密码。
开始使用
本教程依赖于此存储库。将存储库克隆到您选择的任意位置。
此存储库中最重要的文件是 docker-compose.yaml,它描述了一个包含 SingleStore 数据库(singlestore)、MinIO 实例(minio)和一个依赖于 MinIO 服务的 mc 容器的 Docker 环境。
mc 容器包含一个 entrypoint 脚本,该脚本首先等待 MinIO 可访问,将 MinIO 添加为主机,创建 classic-books 桶,上传包含图书数据的 books.txt 文件,将桶策略设置为公开,然后退出。
version: '3.7'
services:
singlestore:
image: 'singlestore/cluster-in-a-box'
ports:
- "3306:3306"
- "8080:8080"
environment:
LICENSE_KEY: ""
ROOT_PASSWORD: ""
START_AFTER_INIT: 'Y'
minio:
image: minio/minio:latest
ports:
- "9000:9000"
- "9001:9001"
volumes:
- data1-1:/data1
- data1-2:/data2
environment:
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadmin
command: ["server", "/data1", "/data2", "--console-address", ":9001"]
mc:
image: minio/mc:latest
depends_on:
- minio
entrypoint: >
/bin/sh -c "
until (/usr/bin/mc config host add --quiet --api s3v4 local http://minio:9000 minioadmin minioadmin) do echo '...waiting...' && sleep 1; done;
echo 'Title,Author,Year' > books.txt;
echo 'The Catcher in the Rye,J.D. Salinger,1945' >> books.txt;
echo 'Pride and Prejudice,Jane Austen,1813' >> books.txt;
echo 'Of Mice and Men,John Steinbeck,1937' >> books.txt;
echo 'Frankenstein,Mary Shelley,1818' >> books.txt;
/usr/bin/mc cp books.txt local/classic-books/books.txt;
/usr/bin/mc policy set public local/classic-books;
exit 0;
"
volumes:
data1-1:
data1-2:
使用文档编辑器,将占位符替换为您的许可证密钥和根密码。
在终端窗口中,导航到您克隆存储库的位置,并运行以下命令以启动所有容器
docker-compose up
打开浏览器窗口,导航到https://:8080/,并使用用户名“root”和您的根密码登录。
检查 MinIO
导航到http://127.0.0.1:9001以启动 MinIO WebUI。使用用户名和密码 minioadmin:minioadmin 登录。您将看到 mc 容器已创建了一个名为 classic-books 的桶,并且该桶中有一个对象。

使用 SQL 探索
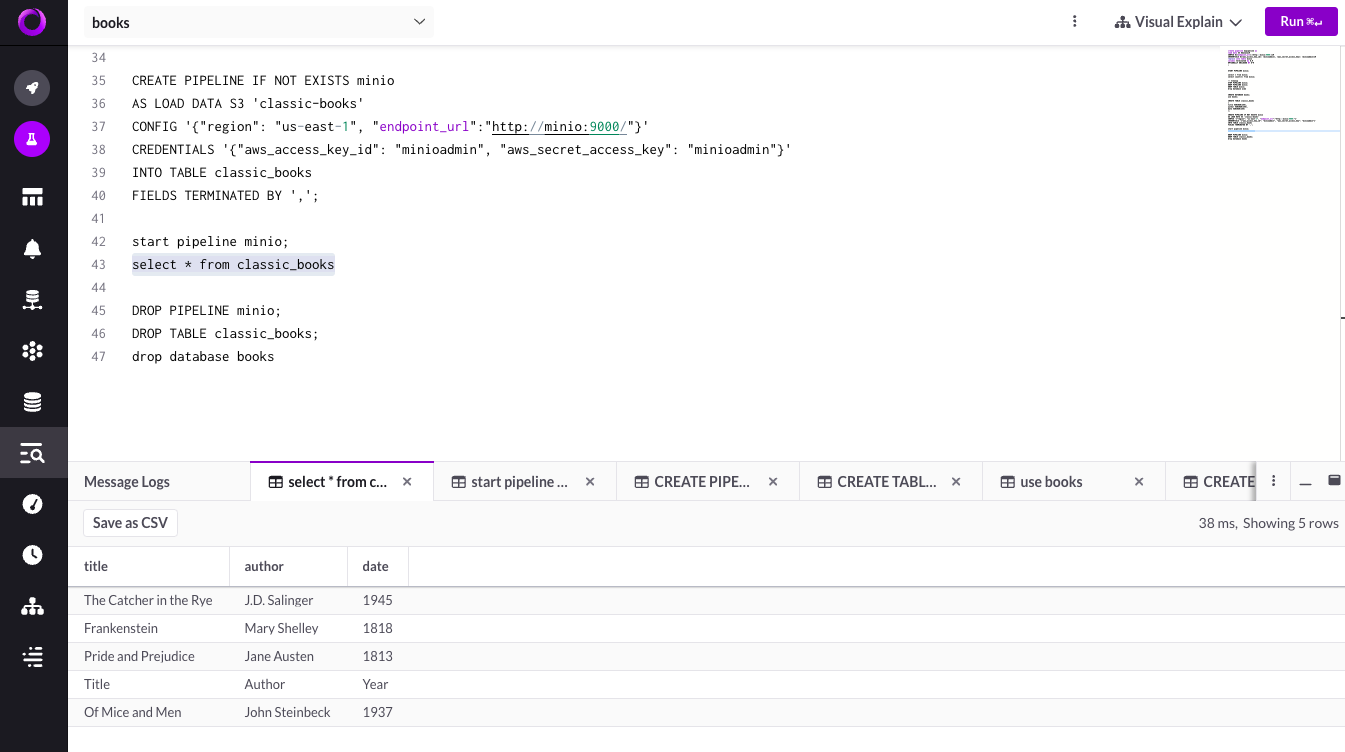
在 SingleStore 中,导航到 SQL 编辑器并运行以下命令
-- Create a new database named 'books'
CREATE DATABASE books;
-- Switch to the 'books' database
USE books;
-- Create a table named 'classic_books' to store information about classic books
CREATE TABLE classic_books
(
title VARCHAR(255),
author VARCHAR(255),
date VARCHAR(255)
);
-- Define a pipeline named 'minio' to load data from an S3 bucket called 'classic-books'
-- The pipeline loads data into the 'classic_books' table
CREATE PIPELINE IF NOT EXISTS minio
AS LOAD DATA S3 'classic-books'
CONFIG '{"region": "us-east-1", "endpoint_url":"http://minio:9000/"}'
CREDENTIALS '{"aws_access_key_id": "minioadmin", "aws_secret_access_key": "minioadmin"}'
INTO TABLE classic_books
FIELDS TERMINATED BY ',';
-- Start the 'minio' pipeline to initiate data loading
START PIPELINE minio;
-- Retrieve and display all records from the 'classic_books' table
SELECT * FROM classic_books;
-- Drop the 'minio' pipeline to stop data loading
DROP PIPELINE minio;
-- Drop the 'classic_books' table to remove it from the database
DROP TABLE classic_books;
-- Drop the 'books' database to remove it entirely
DROP DATABASE books;
此 SQL 脚本启动了一系列操作来处理与经典书籍相关的数据。它首先建立一个名为 books 的新数据库。在这个数据库中,创建了一个名为 classic_books 的表,用于保存标题、作者和出版日期等详细信息。
接下来,设置了一个名为 minio 的管道,用于从标记为 classic-books 的 S3 桶中提取数据并将其加载到 classic_books 表中。此管道的配置参数(包括区域、端点 URL 和身份验证凭据)已定义。
随后,激活“minio”管道以开始数据检索和填充过程。数据成功加载到表中后,SELECT 查询将检索并显示存储在 classic_books 中的所有记录。
完成数据提取和查看后,将停止并删除 minio 管道,从 books 数据库中删除 classic_books 表,并删除 books 数据库本身,确保环境干净,并结束数据管理操作。此脚本应该可以帮助您开始在 SingleStore 中使用 MinIO 中的数据。
在此栈上构建
本教程快速设置了一个强大的数据栈,允许实验在对象存储中存储、处理和查询数据。SingleStore(一个以其速度和多功能性而闻名的云原生数据库)与 MinIO 的集成构成了现代数据湖栈的重要组成部分。
随着行业趋势转向存储和计算的分离,此设置使开发人员能够探索创新的数据管理策略。无论您是对构建数据密集型应用程序、实施高级分析还是实验 AI 工作负载感兴趣,本教程都将作为您的起点。
我们邀请您在此数据栈上构建,实验不同的数据集和配置,并释放数据驱动应用程序的全部潜力。如有任何疑问或想法,请随时通过 hello@min.io 与我们联系或加入我们的Slack 频道。

