持续集成与持续交付基础

你是否曾经想过那些拥有数百个应用程序和数百万用户的巨头是如何管理他们的持续集成(构建)和持续交付(部署)工作流程?在我们之前的一些博文中,我们在编写 Kafka 消费者,使用 Jaeger 观察跟踪和使用 OpenTelemetry 收集指标时编写了不少代码。如果我们能将这些应用程序之一与MinIO捆绑在一起并部署,那是不是很酷?
我们将讨论如何在分布式设置中部署 MinIO,这将使我们能够在本地环境中对其进行测试,并在开发环境中进一步验证,并在最终将其投入生产云环境之前添加监控和修改。
如果你所在的组织每周部署一次,这意味着每次部署可能都是一场盛况,你需要有专门的部署工程师,他们的唯一职责就是确保部署顺利进行。将部署管道想象成数学;如果你没有每天练习,即使是数学老师也会忘记它的运作方式。这是因为部署频率低,很难预测和修复错误。当部署不按计划进行时,团队中的每个工程师都需要知道如何回滚新版本,并重新部署旧版本。
另一方面,那些每天部署多次,并且在一个版本中包含多个工程师提交的组织不会像每周一次的管道那样感到“CI/CD 疲劳”。他们不需要部署工程师,因为在部署发生时会将这项任务分配给现有的工程师,而无需专门分配一个角色。但我之前说过,并非所有部署都会按计划进行,因为可能会出现部署后才发现的错误或安全漏洞,现在团队中的任何工程师都可以回滚。
在这篇博文中,我们将深入探讨 CI/CD 周围的一些概念,以及如何通过从上游源构建应用程序,一直到在裸机、GCP、AWS 甚至 Kubernetes 上以标准化方式将应用程序部署到多个云,将这些概念应用于在分布式设置中部署 MinIO 集群以及你的应用程序。通过你在这里学到的知识,你的管道将有潜力构建数千个构件。我们不仅会尽可能地使用开源工具,还会使用行业标准工作流程来实现这一点。

概念
在我们深入研究工作流程和管道之前,让我们谈谈一些重要的概念和术语。
构件
构件是代码库的版本化捆绑包,可以是 Docker 镜像、Amazon Machine Image、VMDK 或简单的 ISO。在某些情况下,它也可以是 RubyGems、Python PIP 包和/或 NVM 包,以及许多其他包。捆绑包可以是当前部署的版本,过去进行的部署,或者尚未发布的未来部署。
构件库
构建构件后,需要以版本控制的方式使用它们。我们希望能够上传同一代码库的不同版本,因为我们不想删除生产中使用的构件,以防我们需要重新部署或在部署新版本后回滚。MinIO 可以替换任何支持 AWS S3 SDK 和 API 的库,这也被称为“构件注册表”;这两个术语可以互换使用,如下所示。
持续集成
我喜欢将持续集成视为“持续构建”。当您提交代码更改时,您希望尽快构建构件,以便能够及时测试和修复错误,然后再将代码发送到生产环境。
- 工程师将代码提交到 Git 仓库。
- 自动化工具会选择代码库并对其进行广泛测试。
- 构建构件,进行版本控制并上传到构件库。
持续交付
构建构件后,需要将它们交付或“持续部署”到相应的开发环境中,以便在准备部署到生产环境之前对其进行测试。这就是工程师不仅对代码库,而且对代码与其余基础设施如何交互的信心来源。
- 将构建的构件部署到开发环境。
- 对数据库和存储等其他组件进行集成和压力测试。
- 将测试过的代码库部署到生产环境。
管道
从构建、测试和部署到各种环境,构件需要被组织成可重复使用的工作流程,这些工作流程会端到端地自动执行工作流程。这些 CI/CD 工作流程也被称为管道。管道通常被分成几个步骤,以便工程师在完成每个步骤时对 CI/CD 过程充满信心。他们对该过程越有信心,他们就能对代码库进行越多的测试,最终部署到生产环境的过程也会更加顺利。该领域中可用的工具包括
- GitHub Actions
- GitLab CI/CD
- Jenkins(OG)
- AWS CodePipeline
- GCP Cloud Build
- CircleCI
SLA 倒置
构建和部署管道依赖于各种基础设施,这些基础设施反过来会决定管道的 SLA。例如,在构建构件时,代码仓库、上游仓库和/或 DNS 的可用性会决定构建管道的 SLA,而 GCP、AWS 和/或 VMware 的可用性会决定部署管道的 SLA。您可以在此处了解更多关于 SLA 倒置的信息。
基础设施即代码
基础设施即代码 (IaC) 是可执行的文档。它列出了由应用程序读取的指令,用于创建资源(裸机、AWS、GCP),而无需实际使用任何 GUI 或 CLI。基础设施中的任何更改都需要进行编码和测试。在编写基础设施代码时,单元测试、集成测试和验收测试至关重要。您可以在此处了解更多关于 IaC 的信息。
供应器
供应器会从注册表中拉取构件,并使用元数据来供应资源。使用基础设施即代码可以让你对代码库进行编码和版本控制。
烘焙和油炸
- 烘焙是指为特定应用程序专门构建的构件。
- 油炸是指可以跨多个应用程序使用的通用构件。
这可以通过一个例子来说明。一位工程师需要在本地机器上测试 MinIO。他们每次启动 VM 时,都会安装 MinIO 包并在运行时拉取依赖项。这就是油炸。过去,每个新 VM 启动都需要大约 7 分钟,这变得相当繁琐。为了解决这个问题,我们“烘焙”了一个新的 VM 镜像,其中包含所有拉取的依赖项,并在构建期间安装了 MinIO 依赖项。烘焙完这个新的 VM 后,它现在包含所有预安装的依赖项,MinIO 集群大约在 7 秒内启动。作为额外的好处,它稳定且可重复使用。如果你注意到,我们说的是烘焙和油炸,而不是烘焙与油炸。您不必在这两者之间选择,因为镜像可以部分烘焙,然后剩余部分进行油炸,根据应用程序选择最合适的方法并进行相应的调整。通常,镜像烘焙得越深,与油炸的镜像相比,它们就越稳定。
十二要素应用
应用程序可以以多种不同的方式设计,以便与 CI/CD 管道的各个部分进行交互。其中之一就是十二要素应用程序设计。需要考虑的一些关键事项包括
- 使用声明性格式进行设置自动化,以最大程度地减少新开发人员加入项目所需的时间和成本
- 与底层操作系统建立清晰的契约,提供在执行环境之间最大程度的可移植性
- 应用程序适合部署在现代云平台上,避免了对服务器和系统管理的需求
- 最大程度地减少开发和生产之间的差异,实现持续部署,以获得最大的敏捷性
- 并且可以在无需对工具、架构或开发实践进行重大更改的情况下进行扩展。
工具
到目前为止,我们讨论了许多概念,但这些概念如何在实际中发挥作用呢?让我们简要谈谈一些可以用来驱动你的管道的工具。这些工具范围从你可以安装在本地的数据中心的开源工具,到你可以用最低开销使用的SaaS工具。这个管道的目标是尽可能少地使用包装脚本将它们粘合在一起,这样就不会有需要维护或为其招募人员的内部解决方案。
Packer
Packer 允许你定义用于构建工件的步骤,以版本控制的基础设施即代码形式。Packer 从上游直接拉取 Docker 镜像、AWS 机器镜像或 ISO,并构建一个自定义工件,然后可以将其上传到各种工件存储库。
Vagrant
构建完工件后,你需要一种方法来在你的笔记本电脑上本地测试它。Vagrant 允许你从注册表部署自定义工件,无论是作为虚拟机还是作为 Docker 镜像。这样,你就可以避免使用云中的资源,并将开发保留在你的笔记本电脑上。
供应器
配置器本质上是 API 驱动的、与云无关的工具,它们通常只能与具有 API 来启动基础设施的资源进行交互。配置器以声明式方式用 JSON 或 YAML 编写,允许我们在 AWS、GCP 或裸机上配置资源,只要有 API 来处理请求即可。它是声明式的,因为代码定义了基础设施的最终结果。你并不一定关心它如何到达那个状态,也不应该需要关心。一些常见的配置工具有:
- Terraform
- Pulumi
- AWS Cloudformation
- GCP Deployment Manager
服务发现和 KV 存储
虽然大多数设置可以在构建过程中配置,但某些内容(例如基于数据中心或区域的主机名或数据库设置)只能在部署阶段构建工件后配置。我们还需要这些服务可以被发现,以便可以自动生成配置和服务依赖关系。在这个领域可用的工具有:
- etcd
- Consul
Vault
Vault 使用 Consul 键值存储作为后端来存储密钥。出于安全和其他原因,这些密钥不能在构建过程中硬编码。事实上,Consul 和 Vault 服务器都可以运行在同一个实例上。
工件存储库
还有很多其他存储库,但以下是一些最受欢迎的:
- Docker Hub
- Jfrog Artifactory
- Harbor
- Quay
- AWS Elastic Container Registry (ECR)
- GCP Container Registry (GCR)
MinIO
MinIO 在与管道中其他部分集成方面非常灵活。MinIO 可以充当 Harbor 的 S3 后端 来存储工件,事实上,MinIO 也可以充当 Artifactory 的 S3 后端。
此外,当你使用 Terraform 而不是将状态存储在本地磁盘上时,你可以使用 Vagrant 在瞬间配置一个 MinIO 集群,并将 Terraform 状态数据存储在那里,这允许多个用户访问 Terraform 状态。当然,在生产环境中,请确保你使用 分布式设置 使用 Terraform 来运行它。
管道
下面的工作流程突出显示了该过程的构建管道部分。正如你所看到的,Base/L1 可以重复使用来创建 App/L2 工件。除了初始源、上游与注册表之外,工作流程保持不变。
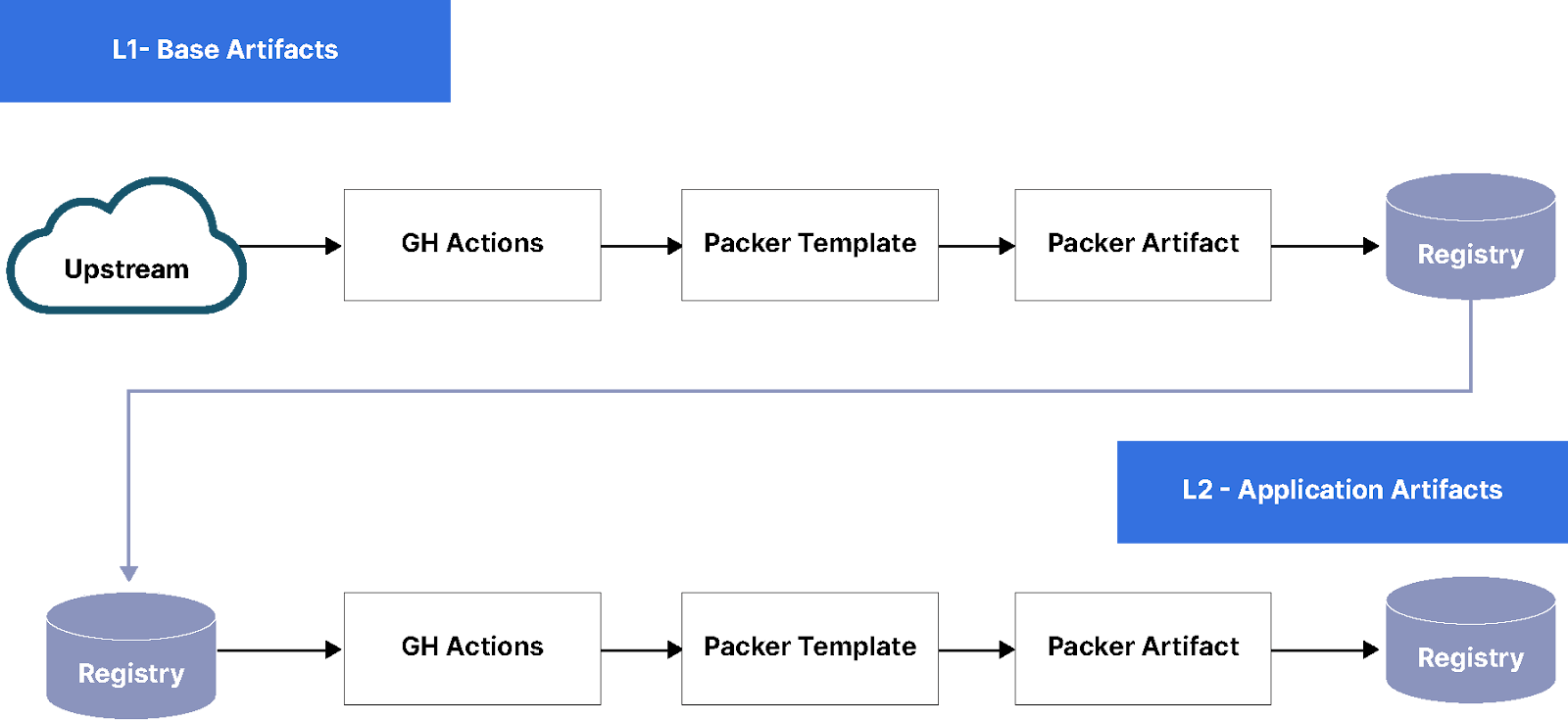
层 0 (L0),基础工件:基础是 Canonical、RedHat、Docker 甚至 AWS 和 GCP 发布的 ISO、Docker 镜像、AMI。这些是来自任何公共存储库的基本标准 Linux 发行版。例如 Ubuntu 20.04 和 22.04 或基本最小 Python Docker 镜像。
层 1 (L1),基础工件:这是组织特定的操作系统与安装了基本软件包、监控和安全最佳实践的地方。这些在所有应用程序中共享。例如指标、监控和日志记录。我们不应该有超过几个这样的工件;这些工件通常由基础设施团队构建和维护。
层 2 (L2),应用程序工件:特定于应用程序的配置、软件包、GPU 驱动程序。例如数据科学、Web、Redis、MinIO、Memcache 或类似的特定于应用程序的组件。基础工件 (L1) 可以重复使用来生成新的 MinIO 服务器工件。不要太惊讶,如果你最终得到很多 L2 工件。这些工件也可能由开发人员创建,这样他们就可以在 Vagrant 中测试他们的 Docker 容器,然后再在生产环境中使用。
注意:一般来说,L0 和 L1 之间的比率应为 1:1,应用程序工件 (L2) 不应重复使用来烘焙新的工件 (L3 或更高),因为依赖链将变得难以管理。
例如,假设在 MinIO 的某个版本中存在安全漏洞。如果 L1 工件容易受到攻击,那么任何从该工件创建的 L2 工件也容易受到攻击。假设你有一个 L3 工件,那是另一层也需要打补丁。如果你只有几个工件,这可能不是问题,但这个管道有可能生成数千个工件:试试看是否能弄清楚那个依赖链!另一个例子是内核安全补丁。如果 L1 有漏洞,那么任何从中构建的 L2 工件也都有漏洞,需要打补丁。
基础设施目标与应用程序目标不同。从基础设施的角度来看,所有环境,即使是开发环境,也被认为是“生产环境”。为什么?哦,我很高兴你问。如果开发或阶段环境中的 MinIO 宕机,最终会影响开发人员,因此从 DevOps 的角度来看,它们被认为是“生产环境”。同时,MinIO 需要在部署到生产环境之前进行测试,我们也不能直接将它部署到开发人员使用的环境中。
我们通过将 MinIO 集群分离到不同的环境来实现这一点。
基础设施环境
- 沙盒
- 金丝雀
- 实时
应用程序环境
- 开发
- 暂存
- QA
- 生产
- 运维(所有应用程序环境共用的通用服务)
每个基础设施环境都可以拥有所有(或部分)应用程序环境;层次结构如下:
沙盒
- 开发
- 暂存
金丝雀
- 开发
- 暂存
- QA
- 生产
- 运维
实时
- 开发
- 暂存
- QA
- 生产
- 运维
这样,我们实际上可以在将更改应用于实时环境之前,在金丝雀环境中应用生产更改。
牛群与独角兽
资源的命名和设计应该更适合牛群,而不是独角兽。如果我们想开始像对待牛群一样对待资源,那么名称应该提供足够的信息,以便你知道 MinIO 运行在哪里,但同时也要尽可能随机,这样就不会出现冲突。这样做的优势是,你可以避免出现独特的“雪花”,这使得自动化变得困难,因为没有模式。
一个建议是使用以下格式:
ROLE-UUID.APP-ENV.INFRA-ENV.REGION.fqdn.com
示例
minio-storage-f9o4hs83.dev.canary.ap-south-1.fqdn.combase-web-l0df54h7.prd.live.us-east-1.fqdn.com
最后的想法
让我们回顾一下我们在本文中讨论的内容。我们深入探讨了一些 CI/CD 概念、涉及的工作流程以及一些可以用来驱动管道的工具。我们向你展示了 MinIO 在构建过程和部署过程中的不同集成方式。
我们在这里讨论的只是冰山一角,我们鼓励你实施自己的版本。在未来的博文中,我们将向你展示当你使用我们讨论过的工具实施时,它会是什么样子,以便让你全面了解端到端管道视图。
事实上,如果你最终实施了自己的版本,请在 Slack 上给我们留言!