基于 Snorkel 和 MinIO 的数据中心 AI

如今,业界都在谈论大型语言模型,包括它们的编码器、解码器、多头注意力层以及数十亿(很快将达到万亿)个参数,这很容易让人认为优秀的AI仅仅是模型设计的结果。不幸的是,情况并非如此。优秀的AI不仅仅需要一个设计良好的模型,还需要构建良好的训练和测试数据。
在这篇文章中,我将介绍数据中心AI的概念,这个术语最初由Snorkel AI团队提出。我还会介绍Snorkel Flow,这是一个用于数据中心AI的平台,并展示如何将其与MinIO结合使用,创建一个高性能的训练管道,并能够扩展到任何所需的AI工作负载。
在定义数据中心AI之前,让我们先快速回顾一下模型中心AI的工作原理。
模型中心AI
模型中心AI是一种人工智能方法,专注于提高AI模型本身的性能。这种方法优先考虑改进和增强模型中使用的架构和技术,以提高性能。模型中心AI的关键方面包括
- 算法开发:创建和优化算法以提高模型的性能。
- 架构创新:设计新的神经网络架构或修改现有架构以增强性能。
- 参数调整:调整超参数以实现最佳模型性能。
- 训练技术:采用先进的训练方法,例如迁移学习、微调、集成学习或强化学习,以改进模型。
让我们来定义数据中心AI。
数据中心AI
数据中心AI是一种人工智能开发方法,专注于提高用于训练AI模型的数据的质量和效用。数据中心AI强调高质量、良好标记和多样化的数据集对增强模型性能的重要性,而不是主要集中在改进算法或模型架构上。数据中心AI基于这样的前提:即使使用更简单的模型,高质量的数据也能显著提高AI性能。这种方法在处理现实世界应用时尤其有效,因为在现实世界应用中,数据通常存在噪声或不平衡。
模型中心AI非常适合于您获得已完美标记的干净数据的情况。不幸的是,这种情况仅在您使用通常出于教育目的而创建的知名开源数据集时才会发生。在现实世界中,数据是原始且未标记的。让我们看看一些需要更多关注数据而不是模型中心AI方法允许的现实世界用例。
现实世界用例
在本节中,我将回顾一些通用用例,这些用例突出了对AI数据中心方法的需求。在您查看以下各种场景时,务必记住,相关数据非常原始,目标是以编程方式标记数据。这听起来可能很奇怪,并且会引发一个问题——如果您有标记数据的逻辑,那么为什么还需要模型?只需使用您的“标记逻辑”进行预测即可。我将在下一节关于标记函数和弱监督的部分直接解决此问题。目前,简短的答案是标记逻辑不精确且存在噪声,而使用不精确标签的模型在进行预测方面仍然比直接使用标记逻辑做得更好。
**统计数据分析:** 通常情况下,重要的信息隐藏在包含重要标记线索的文档中。例如,根据美国证券交易委员会 (SEC) 的要求,上市公司每年都需要填写一份10-K 报告。10-K 包含与财务业绩相关的信息:财务报表、每股收益和高管薪酬,仅举几例。在加拿大,公司会提交SEC 表格 40-F 以提供类似的信息。如果需要手动处理这些文档以提取模型训练所需的信息,那么这将是一个艰巨且容易出错的过程。
**关键词分析:** 通常,文档中的关键词足以标记文档。例如,如果一个组织需要良好的公众舆论才能开展业务,那么它通常会监控其品牌在互联网上的情况。这些组织应该每天监控新闻,寻找对它不满意的群体甚至个人。这需要处理新闻源以查找公司名称的提及,然后在文档中查找指示情绪的关键词。这可能很简单,例如查找表示情绪的简单词语,如“糟糕”、“可怕”、“很棒”和“极好”,但可能还应该使用特定领域的关键词。
**对主题专家 (SME) 的需求:** 确定标签所需的逻辑可能并不简单。相反,可能需要一位了解数据所有信息的专家来确定正确的标签。例如,医疗图像和医疗记录需要医生来确定正确的诊断。
**数据查找:** 通常情况下,一个组织可能还有另一个应用程序或数据库,其中包含有助于确定正确标签的其他信息。例如,一个客户数据库包含每个客户的人口统计数据。这可以用来确定任何以客户为中心的的数据集的标签,例如目标广告和产品推荐。
根据上面描述的假设示例,我们可以得出一些结论。首先,如果上面描述的标记必须手动完成,那么创建标签将非常昂贵且耗时。当需要查找其他系统并需要主题专家时,尤其如此。主题专家可能难以找到,并且可能忙于其他任务。
更好的方法是找到一种方法以编程方式完成上述操作,以便以代码的形式捕捉主题专家的专业知识。这就是标记函数和弱监督发挥作用的地方。
标记函数
标记函数是一种捕获标记逻辑的方法,以便可以以编程方式应用它。例如,如果您一开始手动标记数据集,您会注意到您正在重复对数据集中每个记录(或文档)执行相同的操作。将其应用于我们上面的场景;这可能是从文档中收集多条统计数据以确定标签,查找相同的关键词-标签关联,查找其他系统以获取带外数据,甚至困在主题专家大脑中的高级逻辑通常也可以在标记函数中表达。
Snorkel Flow 中的标记函数 (LF) 允许以编程方式捕获上述逻辑。LF 只是一个任意函数,它接收一个数据点并输出标签或放弃。您可以在 LF 中执行任何操作。如果您能想到一种以编程方式标记数据子集的方法,其精度高于随机,那么请将其编码到 LF 中。这使您可以捕捉您的领域知识。
许多 LF 采用通用形式。对于这些通用的 LF,Snorkel Flow 提供了一个无代码模板库,您只需提供领域知识的要点即可完成它。例如,提供您要查找的特定关键词——从那里,Snorkel Flow 将模板代码与您的信息要点结合起来,创建一个可执行的 LF。下面显示了一个示例。
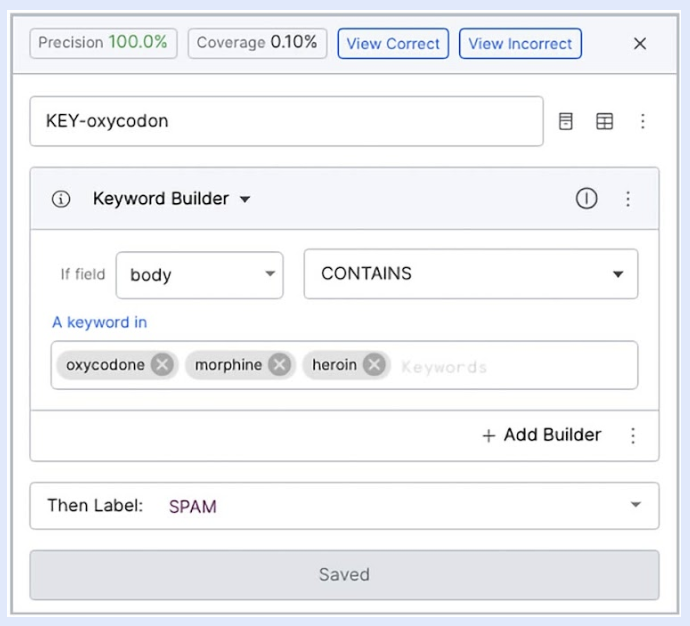
在某些情况下,您可能希望表达一种非常特殊的信号类型,该信号还没有相应的模板,或者使用您唯一可以访问的闭源库——在这种情况下,您可以使用 Python SDK 在 Snorkel Flow 集成笔记本中定义自定义 LF,如下所示。
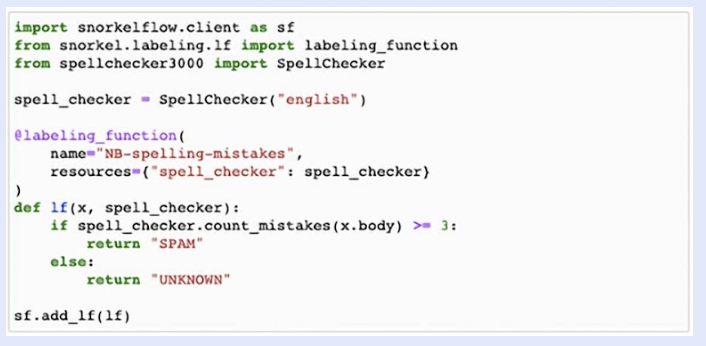
现在我们已经了解了标记函数及其各种使用场景——让我们看看完整的端到端机器学习工作流程。
将 MinIO 集成到整个流程中
下面显示了使用 MinIO 和 Snorkel Flow 的机器学习工作流程。
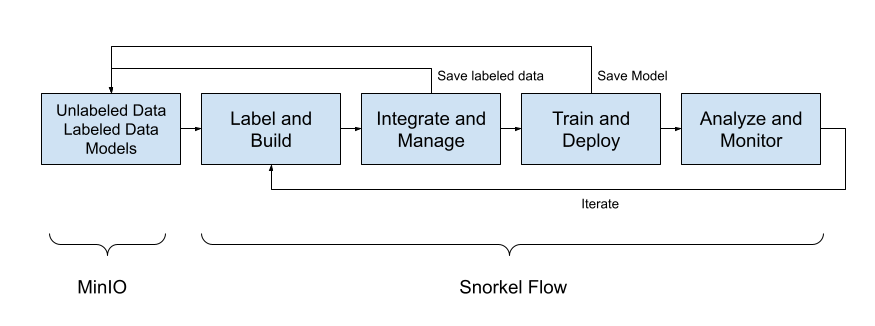
**原始数据:** MinIO 是收集和存储原始非结构化数据的最佳解决方案。此外,如果您不使用文档并且拥有结构化数据,则可以在现代数据湖的上下文中使用 MinIO。查看我们关于现代数据湖的参考架构以获取更多信息。MinIO 还拥有许多用于数据导入的优秀工具。(这在我们的参考架构的摄取层中完成。)
**标记和构建:** 标记和构建阶段创建您的标记函数。无论它们是通过模板创建还是由工程师手写,都将在此阶段进行聚合和准备。
集成和管理: 一旦您所有 LF 就位,就可以运行它们来生成标签。考虑手动标记数据的一个小子集。这些手动标记的数据被称为您的基本事实,您可以将 LF 的结果与您的基本事实进行比较以衡量其性能。一旦准备好进入模型训练阶段,您应该将新标记数据的副本保存回 MinIO 以确保安全。
训练和部署: 一旦您拥有一个完全标记的数据集,下一步就是训练模型。您可以使用 Snorkel Flow 的模型训练界面,它与 Scikit-Learn、XGBoost、Transformers 和 Flair 等兼容。如果您愿意,也可以离线训练自定义模型,然后通过 Snorkel Flow SDK 上传预测以进行分析。
分析和监控: 模型训练完成后,您需要使用适合您问题的指标(准确率、F1 等)来评估其性能。如果需要提高质量(这几乎总是您初始实验中的情况),请查看模型产生错误预测的位置。很可能是程序生成的标签需要校正。这就是数据中心 AI。您首先通过改进数据来改进模型。只有当您的模型在正确标记的数据上产生错误预测时,才应考虑改进模型本身。一旦性能足够,您就可以部署模型。考虑随着时间的推移监控其性能。随着现实世界条件的变化,模型性能随着时间推移下降是很常见的。此时,迭代此过程以微调您的 LF 和模型。
总结
在这篇文章中,我定义了模型中心 AI 并介绍了数据中心 AI。数据中心 AI 并不是模型中心 AI 的替代品。数据中心 AI 遵循这样的前提:在尝试改进模型之前,您应该改进数据及其标签。如果您仔细思考,这很有道理。如果您在拥有糟糕数据时尝试改进模型,您将白费力气。您的模型将尝试拟合糟糕的数据和标签。您最终会得到一个为糟糕数据设计的模型。更好的方法是先修复数据,然后用好的数据设计您的模型。
我还使用 Snorkel Flow 和 MinIO 提供了数据中心 AI 的高级概述。将 Snorkel Flow 与 MinIO 结合使用提供了一种方法来进行数据实验,并使用能够存储大量原始数据以及所有实验结果的存储解决方案。
如果您有任何疑问,请务必在 Slack 上联系我们!