使用Hudi、MinIO和HMS构建现代数据湖


Apache Hudi 已成为管理现代数据湖的首要开源表格式之一,它直接在现代数据湖中提供了核心仓库和数据库功能。这在很大程度上归因于Hudi提供了诸如表、事务、Upsert/Delete、高级索引、流式数据摄取服务、数据聚类/压缩优化和并发控制等高级功能。
我们已经探索过MinIO 和 Hudi 如何协同构建现代数据湖。这篇博文旨在在此基础上,提供一种利用Hive 元数据存储服务 (HMS) 的 Hudi 和 MinIO 的替代实现方案。部分原因是 HDFS 生态系统中的起源故事,许多大规模 Hudi 数据实现方案仍然利用 HMS。从传统系统迁移的故事通常涉及某种程度的混合,因为所有相关产品的最佳功能都被用于取得成功。
Hudi 在 MinIO 上:强强联合
Hudi 从依赖 HDFS 到云原生对象存储(如 MinIO)的演进,与数据行业从单体和不合适的传统解决方案转向的趋势完美契合。MinIO 的性能、可扩展性和经济高效性使其成为存储和管理 Hudi 数据的理想选择。此外,Hudi 对Apache Spark、Flink、Presto、Trino、StarRocks等现代数据工具的优化,可以与 MinIO 无缝集成,实现云原生的大规模高性能。这种兼容性代表了现代数据湖架构中的重要模式。
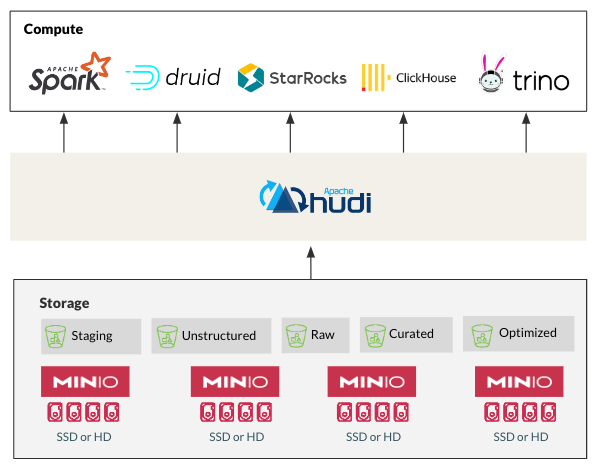
HMS 集成:增强的数据治理和管理
虽然 Hudi 提供了开箱即用的核心数据管理功能,但与 HMS 集成可以增加另一层控制和可见性。以下是 HMS 集成如何使大规模 Hudi 部署受益:
- 改进的数据治理:HMS 集中管理元数据,能够在整个数据湖中实现一致的访问控制、血缘跟踪和审计。这可以确保数据质量和合规性,并简化治理流程。
- 简化的模式管理:在 HMS 中为 Hudi 表定义和执行模式,确保数据管道和应用程序之间的数据一致性和兼容性。HMS 模式演变功能允许在不中断管道的情况下适应不断变化的数据结构。
- 增强的可见性和发现:HMS 为所有数据资产(包括 Hudi 表)提供了一个中央目录。这便于分析师和数据科学家轻松发现和探索数据。
入门:满足先决条件
要完成本教程,您需要设置一些软件。以下是您需要的内容:
- Docker Engine:这个强大的工具允许您将应用程序打包并以标准化的软件单元(称为容器)运行。
- Docker Compose:它充当协调器,简化了多容器应用程序的管理。它有助于轻松定义和运行复杂的应用程序。
安装:如果您是新手,Docker Desktop 安装程序提供了一种便捷的一站式解决方案,用于在您的特定平台(Windows、macOS 或 Linux)上安装 Docker 和 Docker Compose。这通常比单独下载和安装它们更容易。
安装 Docker Desktop 或 Docker 和 Docker Compose 的组合后,您可以在终端中运行以下命令来验证它们是否存在:
docker-compose --version请注意,本教程是为 linux/amd64 构建的,为了使其适用于 Mac M2 芯片,您还需要安装 Rosetta 2。您可以在终端窗口中运行以下命令来执行此操作:
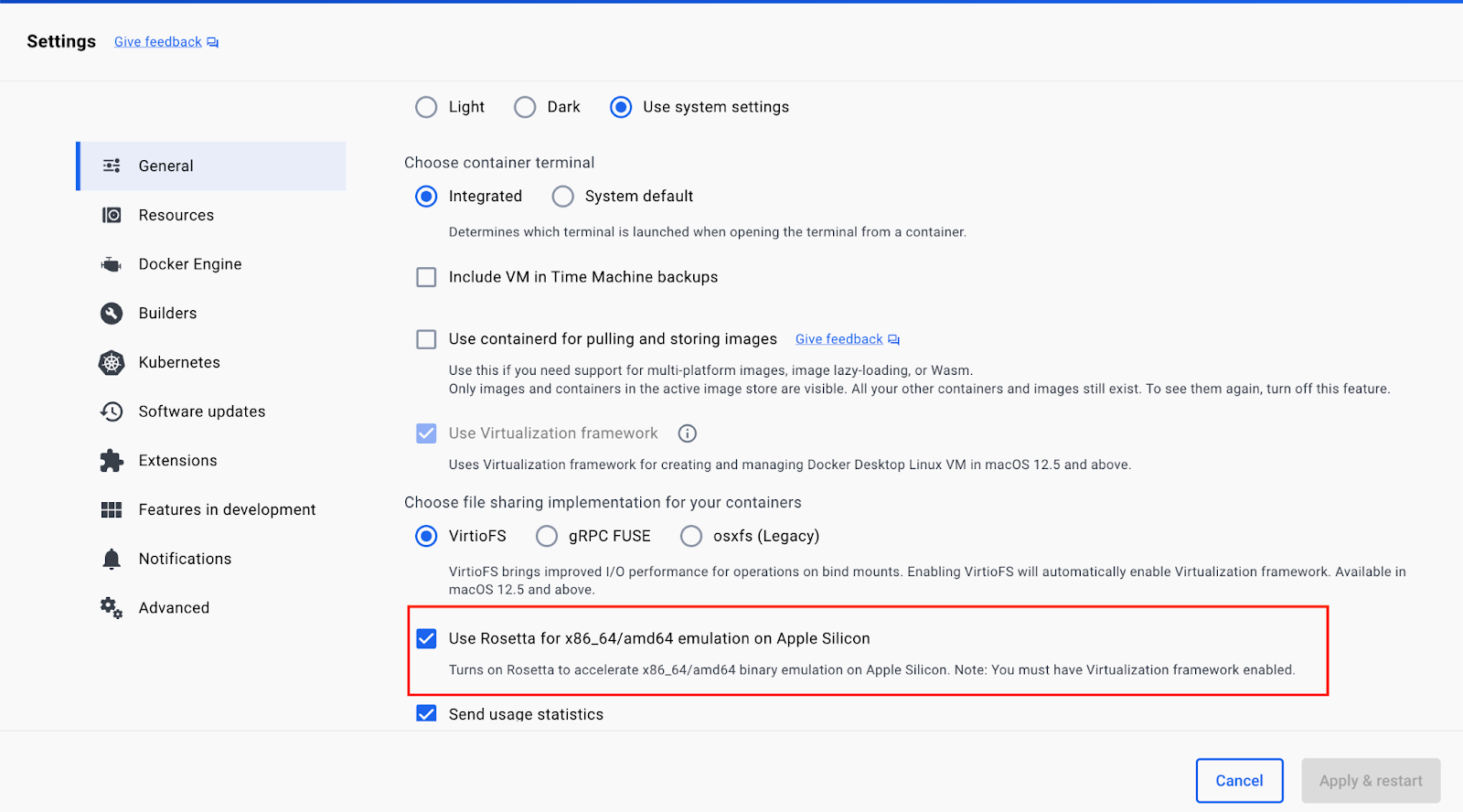
softwareupdate --install-rosetta在 Docker Desktop 设置中,您还需要启用对 Apple Silicon 上 x86_64/amd64 二进制模拟的支持。为此,请导航到“设置”→“常规”,然后选中 Rosetta 复选框,如下所示。
将 HMS 与 MinIO 上的 Hudi 集成
本教程使用 StarRock 的演示仓库。克隆此处找到的仓库此处。在终端窗口中,导航到 documentation-samples 目录,然后导航到 hudi 文件夹并运行以下命令
docker compose up运行上述命令后,您应该会看到 StarRocks、HMS 和 MinIO 正在运行。
访问 MinIO 控制台 https://:9000/ 并使用凭据 admin:password 登录,以查看桶 warehouse 是否已自动创建。
使用 Spark Scala 插入数据
运行以下命令以访问 spark-hudi 容器内的 shell
docker exec -it hudi-spark-hudi-1 /bin/bash然后运行以下命令,它将带您进入 Spark REPL:
/spark-3.2.1-bin-hadoop3.2/bin/spark-shell进入 shell 后,执行以下 Scala 代码行以创建数据库、表并将数据插入该表
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import scala.collection.JavaConversions._
val schema = StructType(Array(
StructField("language", StringType, true),
StructField("users", StringType, true),
StructField("id", StringType, true)
))
val rowData= Seq(
Row("Java", "20000", "a"),
Row("Python", "100000", "b"),
Row("Scala", "3000", "c")
)
val df = spark.createDataFrame(rowData, schema)
val databaseName = "hudi_sample"
val tableName = "hudi_coders_hive"
val basePath = "s3a://warehouse/hudi_coders"
df.write.format("hudi").
option(org.apache.hudi.config.HoodieWriteConfig.TABLE_NAME, tableName).
option(RECORDKEY_FIELD_OPT_KEY, "id").
option(PARTITIONPATH_FIELD_OPT_KEY, "language").
option(PRECOMBINE_FIELD_OPT_KEY, "users").
option("hoodie.datasource.write.hive_style_partitioning", "true").
option("hoodie.datasource.hive_sync.enable", "true").
option("hoodie.datasource.hive_sync.mode", "hms").
option("hoodie.datasource.hive_sync.database", databaseName).
option("hoodie.datasource.hive_sync.table", tableName).
option("hoodie.datasource.hive_sync.partition_fields", "language").
option("hoodie.datasource.hive_sync.partition_extractor_class", "org.apache.hudi.hive.MultiPartKeysValueExtractor").
option("hoodie.datasource.hive_sync.metastore.uris", "thrift://hive-metastore:9083").
mode(Overwrite).
save(basePath)
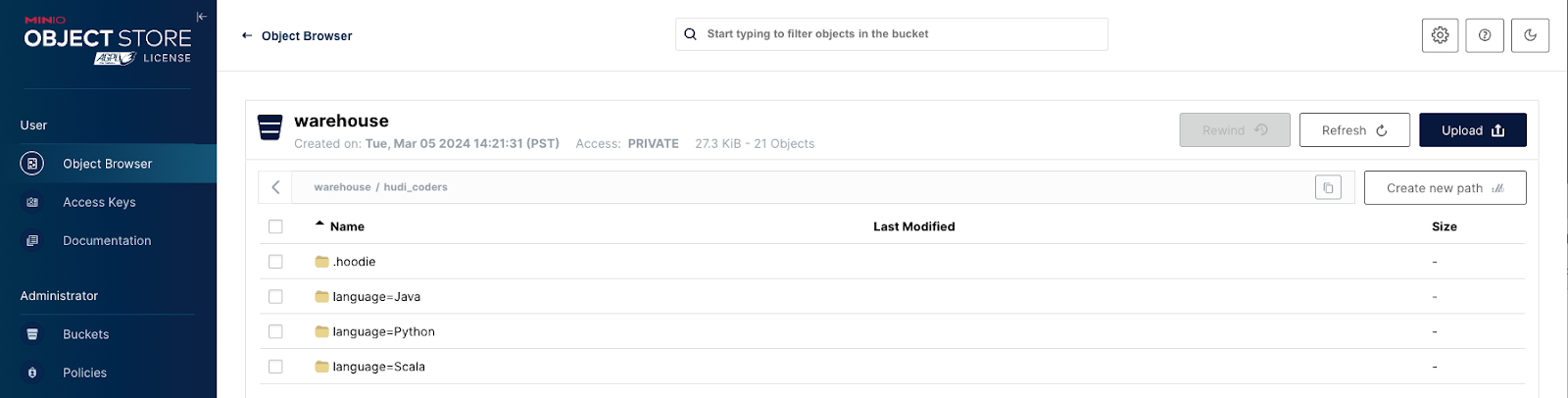
就是这样。您现在已设置了一个带有 Hudi 和 HMS 的 MinIO 数据湖。导航回https://:9000/以查看您的 warehouse 文件夹是否已填充。
数据探索
您可以选择使用以下 Scala 在同一 Shell 中进一步探索您的数据。
val hudiDF = spark.read.format("hudi").load(basePath + "/*/*")
hudiDF.show()
val languageUserCount = hudiDF.groupBy("language").agg(sum("users").as("total_users"))
languageUserCount.show()
val uniqueLanguages = hudiDF.select("language").distinct()
uniqueLanguages.show()
// Stop the Spark session
System.exit(0)
立即开始构建您的云原生现代数据湖
Hudi、MinIO 和 HMS 协同工作,为构建和管理大规模现代数据湖提供了一个全面的解决方案。通过集成这些技术,您可以获得构建敏捷、可扩展和安全的数据湖所需的优势,从而释放数据的全部潜力。如有任何疑问,请联系我们 hello@min.io 或访问我们的Slack 频道。