Delta Lake 和 MinIO 用于多云数据湖


Delta Lake 是一个开源的存储框架,用于在 Lakehouse 架构中构建基于对象存储的数据湖。 Delta Lake 支持 ACID 事务、可扩展的元数据处理以及统一的流式和批处理数据处理。Delta Lake 通常用于为 Apache Spark 应用程序提供可靠性、一致性和可扩展性。Delta Lake 运行在现有数据湖存储之上,例如 MinIO,并与 Apache Spark API 兼容。
最初的 Delta Lake 论文 (Delta Lake: 高性能 ACID 表存储在云对象存储上) 描述了它是如何为云对象存储构建的。当 Vertica 测试使用 Delta Lake 用于外部表时,他们依赖于 MinIO。HPE Ezmeral Runtime Enterprise 客户 在 MinIO 上运行 Delta Lake。MinIO 支持 Delta Lake 对持久性的要求,因为 MinIO 在分布式和独立模式下对所有 I/O 操作遵循严格的读后写和列后写一致性模型,并且被广泛认为可以运行 Delta Lake 工作负载。
许多组织依赖于云原生对象存储,例如 MinIO 和 AWS S3,来存储大型结构化、半结构化和非结构化数据集。每个表都存储为一组对象,这些对象是 Parquet 或 ORC,并排列成分区。对大型文件的查询基本上是快速执行的扫描。
如果没有 Delta Lake,更复杂的 Spark 工作负载,特别是那些修改、添加或删除数据的负载,在繁重的多用户/多应用程序负载下将面临性能和正确性的挑战。多对象更新不是原子的,查询也不是隔离的,这意味着如果在一个查询中进行删除,那么其他并发查询将获得部分结果,因为原始查询会更新每个对象。回滚写入很棘手,更新过程中的崩溃可能会导致表损坏。真正的性能杀手是元数据——对于具有数百万个对象的巨型表,这些对象是包含数十亿或万亿条记录的 Parquet 文件,元数据操作会使构建在数据湖上的应用程序停止。

Delta Lake 旨在将数据库的事务可靠性与数据湖的横向可扩展性相结合。Delta Lake 旨在支持使用 ACID 表存储层的 OLAP 风格工作负载,该层位于云原生对象存储(如 MinIO)之上。如论文 Delta lake: 高性能 ACID 表存储在云对象存储上 中所述,“Delta Lake 的核心思想很简单:我们使用一个预写日志来维护有关哪些对象是 Delta 表的一部分的信息,该日志本身存储在云对象存储中。” 对象以 Parquet 格式编码,可以由理解 Parquet 的引擎读取。可以一次更新多个对象,“以序列化方式进行,同时仍然实现高并发的读写性能”。日志包含元数据,例如每个文件的最小值/最大值统计信息,“能够比直接搜索对象存储中的文件快一个数量级地进行元数据搜索”。
Delta Lake 提供以下功能
- ACID 保证: Delta Lake 确保所有对数据的更改都写入存储并提交以实现持久性,同时以原子方式对用户和应用程序可用。您的数据湖中不再存在部分文件或损坏文件。
- 可扩展的数据和元数据处理: 所有使用 Spark(或其他分布式处理引擎)的读写都可以扩展到 PB 级。与大多数其他存储格式和查询引擎不同,Delta Lake 利用 Spark 来扩展所有元数据处理,并且可以有效地处理 PB 级表的数十亿个文件的元数据。
- 审计历史和时间旅行: Delta Lake 事务日志记录对数据进行的每次修改的详细信息,包括更改的完整审计跟踪。数据快照使开发人员能够访问和恢复数据的早期版本,用于审计、回滚或任何其他原因。
- 模式强制和模式演进: Delta Lake 会自动阻止插入与现有表模式不匹配的数据。但是,可以显式且安全地演进表模式以适应数据结构和格式的更改。
- 支持删除、更新和合并: 大多数分布式处理框架不支持对数据湖上的数据进行原子数据修改操作。相反,Delta Lake 支持合并、更新和删除操作,以满足复杂的用例,例如更改数据捕获、缓慢变化维度操作和流式更新。
- 流式和批处理统一: Delta Lake 表能够以批处理模式工作,以及作为流式源和接收器。Delta Lake 在各种延迟范围内工作,包括流式数据摄取和批处理历史回填,以提供实时交互式查询。流式作业以低延迟将小对象写入表,然后以事务方式将它们组合成更大的对象以提高性能。
- 缓存: 依赖对象存储意味着 Delta 表及其日志中的对象是不可变的,并且可以安全地在本地缓存——无论在多云环境中的任何位置。
Lakehouse 架构,尤其是 Delta Lake,为构建在对象存储上的数据湖带来了重要的新功能。Delta Lake 与 Spark、Starburst、Trino、Flink 和 Hive 等大量且 不断增长的应用程序和计算引擎列表 协同工作,还包括用于 Scala、Java、Rust、Ruby 和 Python 的 API。专为云构建的 Kubernetes 原生 MinIO 在边缘、数据中心以及公有/私有云中,实现了高性能、弹性和安全的数据湖应用程序。

Delta Lake 文件
Delta 表是存储在一起的一组文件,这些文件存储在目录(对于文件系统)或存储桶(对于 MinIO 和其他对象存储)中。为了从对象存储中读写,Delta Lake 使用路径的方案来动态识别存储系统,并使用相应的 LogStore 实现来提供 ACID 保证。对于 MinIO,您将使用 S3A,请参阅 存储配置 - Delta Lake 文档。对于 Delta Lake,使用的底层存储系统能够进行并发原子读/写至关重要,而 MinIO 能够做到这一点。
创建 Delta 表实际上就是将文件写入目录或存储桶。Delta 表通过写入(读取)Spark DataFrame 并指定 delta 格式和路径来创建(打开)。例如,在 Scala 中
Delta Lake 依赖于每个表的存储桶,存储桶通常以文件系统路径为模型。Delta Lake 表是包含数据、元数据和事务日志的存储桶。表存储在 Parquet 格式中。表可以被分区成多个文件。MinIO 支持 S3 LIST 以使用文件系统风格的路径有效地列出对象。MinIO 还支持字节范围请求,以便更有效地读取大型 Parquet 文件的子集。

MinIO 是 Delta Lake 表格的绝佳选择,因为它拥有业界领先的性能。MinIO 结合了可扩展性和高性能,让所有工作负载,无论多么苛刻,都能轻松应对。MinIO 能够实现惊人的性能 - 最近的基准测试 在 32 个节点的现成 NVMe SSD 上,GET 操作的吞吐量达到了 325 GiB/s (349 GB/s),PUT 操作的吞吐量达到了 165 GiB/s (177 GB/s)。MinIO 的性能足以满足 Delta Lake 上最苛刻的工作负载的需求。
Delta Lake 存储桶很可能包含许多 Parquet 和 JSON 文件,这与我们为 MinIO 作为数据湖而构建的所有 小文件优化 相得益彰。小对象与元数据一起内联保存,减少了读取和写入小文件(如 Delta Lake 事务)所需的 IOPS。
大多数企业都需要 Delta Lake 的多云功能。MinIO 包含 双活复制 功能,用于在不同位置(内部部署、公共/私有云和边缘)之间同步数据。双活复制使企业能够构建多地域弹性和快速热热故障转移架构。每个存储桶或 Delta Lake 表格都可以单独配置复制设置,以最大程度地提高安全性和可用性。
Delta Lake 的 ACID 事务
为数据湖添加 ACID(原子性、一致性、隔离性和持久性)事务 是件大事,因为现在组织可以更好地控制存储在数据湖中的海量数据,从而对数据更有信心。以前,依赖 Spark 处理数据湖的企业缺乏原子 API 和 ACID 事务,但现在 Delta Lake 使其成为可能。数据可以在捕获和写入后进行更新,并且在 ACID 支持下,如果应用程序在操作过程中出现故障,数据不会丢失。Delta Lake 通过充当 Spark 和 MinIO 之间的中间人来实现此目标,用于读取和写入数据。
Delta Lake 的核心是 DeltaLog,它是一个有序的用户和应用程序执行的事务记录。用户对 Delta Lake 表格执行的每个操作(如 UPDATE 或 INSERT)都是一个原子提交,由多个操作或作业组成。当每个操作都成功完成时,提交将作为一项条目记录在 DeltaLog 中。如果任何作业失败,则提交不会记录在 DeltaLog 中。如果没有原子性,在硬件或软件故障导致数据仅部分写入的情况下,数据可能会损坏。
Delta Lake 将操作分解为以下一个或多个操作:
- 添加文件 - 添加文件
- 删除文件 - 删除文件
- 更新元数据 - 记录对表格名称、模式或分区的更改
- 设置事务 - 记录流作业已提交数据
- 提交信息 - 关于提交的信息,包括操作、用户和时间
- 更改协议 - 将 DeltaLog 更新为最新的软件协议
它不像看起来那么复杂。例如,如果用户向表格添加一个新列并向其中添加数据,那么 Delta Lake 会将其分解为其组成操作(更新元数据以添加列和添加文件以添加每个新文件),并在它们完成时将其添加到 DeltaLog 中。
Delta Lake 依赖乐观并发控制,允许多个读取器和写入器同时对给定表格进行操作。乐观并发控制假设不同用户对表格的更改可以完成而不会发生冲突。随着数据量的增长,用户同时操作不同表格的可能性也会增加。Delta Lake 对提交进行序列化,如果两个或多个提交同时发生,则遵循互斥规则。通过这样做,Delta Lake 达到了 ACID 所需的隔离性,表格在多个并发写入后的外观将与这些写入按顺序独立发生时相同。
当用户对自上次读取以来已修改的打开表格运行新查询时,Spark 会查询 DeltaLog 以确定是否已向表格发布了新的事务,并使用这些新更改更新用户的表格。这确保用户的表格版本与 Delta Lake 中的母表格同步到最新的操作,并且用户不能对表格进行冲突更新。
DeltaLog、乐观并发控制和模式强制(结合模式演变能力)确保了原子性和一致性。
深入研究 DeltaLog
当用户创建 Delta Lake 表格时,该表格的事务日志将自动在 _delta_log 子目录中创建。当用户修改表格时,每个提交将作为 JSON 文件写入 _delta_log 子目录,并按升序排列,即 000000.json、000001.json、000002.json 等。

假设我们从数据文件 1.parquet 和 2.parquet 中向表格添加新记录。该事务将添加到 DeltaLog 中,并保存为文件 000000.json。稍后,我们删除这些文件并添加一个新的文件 3.parquet。这些操作将记录为一个新文件 000001.json。

在添加 1.parquet 和 2.parquet 后,它们被删除了。事务日志中包含这两个操作,即使它们互相抵消。Delta Lake 保留所有原子提交,以启用完整的审计历史记录和时间旅行功能,让用户可以查看表格在特定时间点的状态。此外,这些文件不会很快从存储中删除,直到执行 VACUUM 作业。MinIO 的 版本控制 提供了另一层防范意外删除的保障。
Delta Lake 和 MinIO 的持久性
Delta Lake 通过在持久性介质上存储表格和事务日志来实现持久性。文件永远不会被覆盖,必须主动删除。写入存储的所有数据更改都将按发生顺序以原子方式提供给用户。部分文件和损坏文件将成为过去。Delta Lake 不会将表格和日志长时间保存在内存中,而是直接写入 MinIO。只要提交数据已记录在 DeltaLog 中,并且 JSON 文件已写入存储桶,数据在系统或作业崩溃时将保持持久性。
MinIO 通过多种机制保证表格及其组件写入后的持久性。
- 擦除编码 将数据文件拆分为数据块和奇偶校验块,并对其进行编码,以便即使编码数据的一部分不可用,也可以恢复主数据。横向扩展的分布式存储系统依赖擦除编码来通过在多个驱动器和节点上保存编码数据来提供数据保护。如果驱动器或节点发生故障或数据损坏,则可以从保存在其他驱动器和节点上的块中重建原始数据。
- 位腐烂保护 动态捕获和修复损坏的对象,以消除对数据持久性的这种无声威胁。
- 存储桶和对象不变性 使用对象锁定、保留和其他治理机制的组合来保护保存到 MinIO 的数据免遭删除或修改。写入 MinIO 的对象永远不会被覆盖。
- 存储桶和对象版本控制 进一步保护对象。MinIO 会维护每个对象的每个版本的记录,即使它被删除,也使您能够追溯时间(类似于 Delta Lake 的时间旅行)。版本控制是 数据生命周期管理 的关键组件,它允许管理员在层之间移动存储桶,例如使用 NVMe 处理性能密集型工作负载,并为版本设置过期日期,以便将它们从系统中清除以提高存储效率。
MinIO 使用加密保护 Delta Lake 表格,并使用 IAM 和基于策略的访问控制的组合来调节对它们的访问。MinIO 对数据进行加密,在传输过程中使用 TLS 进行加密,在驱动器上使用细粒度对象级加密,使用现代的行业标准加密算法,例如 AES-256-GCM、ChaCha20-Poly1305 和 AES-CBC。MinIO 与外部 身份提供者(如 ActiveDirectory/LDAP、Okta 和 Keycloak)集成以进行 IAM。然后,当用户和组尝试访问 Delta Lake 表格时,将受到 AWS IAM 兼容的 PBAC 的约束。
Delta Lake 和 MinIO 教程
本部分介绍如何使用单集群模式快速开始在 MinIO 上读取和写入 Delta 表格。
先决条件
- 下载并安装 Apache Spark。
- 下载并安装 MinIO。记录 IP 地址、TCP 端口、访问密钥和秘密密钥。
- 下载并安装 MinIO 客户端。
- 需要以下 jar 文件。您可以将 jar 文件复制到 Spark 计算机上的任何所需位置,例如
/home/spark。 - Hadoop -
hadoop-aws-2.6.5.jar- Delta Lake 需要来自hadoop-aws包的org.apache.hadoop.fs.s3a.S3AFileSystem类,该类为 S3 实现了 Hadoop 的FileSystemAPI。确保此包的版本与构建 Spark 的 Hadoop 版本相匹配。 - AWS -
aws-java-sdk-1.7.4.jar
使用 Delta Lake 设置 Apache Spark
启动带有 Delta Lake 的 Spark shell(Scala 或 Python),并以交互方式运行代码片段。
在 Scala 中
在 Apache Spark 上配置 Delta Lake 和 AWS S3
运行以下命令启动支持 Delta Lake 和 S3 的 Spark shell,用于 MinIO
在 MinIO 中创建存储桶
使用 MinIO 客户端为 Delta Lake 创建存储桶
在 MinIO 上创建一个测试 Delta Lake 表
试一下,使用 Scala 创建一个简单的 Delta Lake 表
您将看到一些输出,表明 Spark 已成功写入表。
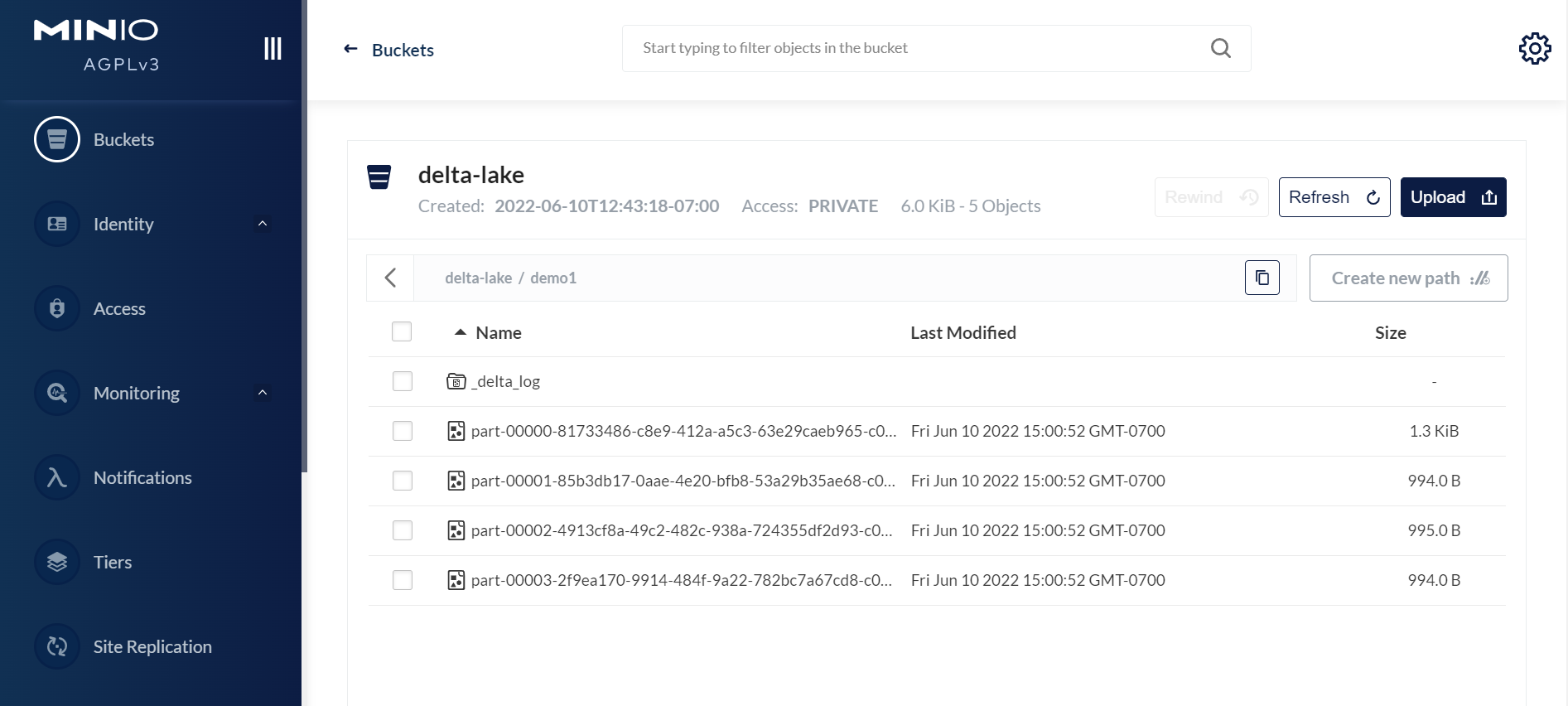
打开浏览器,使用您的访问密钥和密钥登录 MinIO,网址为 http://<您的 MinIO IP:9001>。您将看到存储桶中的 Delta Lake 表。
用于数据湖的高性能 ACID 事务的 MinIO 和 Delta Lake
MinIO 和 Delta Lake 的结合使企业能够拥有一个多云数据湖,作为集中的单一事实来源。查询和更新 Delta Lake 表的能力为企业提供了对业务和客户的丰富洞察。各种团队都可以访问 Delta Lake 表以进行自己的分析或机器学习计划,并确保其工作安全且数据及时。
要深入了解,请下载 MinIO,亲身体验,或在任何公共云上启动市场实例。有问题吗?在 Slack 或通过 hello@min.io 联系我们。