引言 分布式数据处理是高效端到端分布式机器学习训练流水线的关键组成部分。如果您正在构建用于统计预测的基本神经网络,其中分布式训练可能意味着每个实验运行 10 分钟而不是 1 小时,那么这是正确的。如果您正在训练或微调大型语言模型 (LLM),其中分布式训练将为您节省几天时间,那么情况也是如此。在这篇文章中,我将向您展示如何使用 Ray Data 来分发机器学习流水线中的数据处理。分发数据处理不仅可以提高性能,而且当您使用无法容纳在单台机器内存中的数据训练模型时,它也是一个不错的选择。
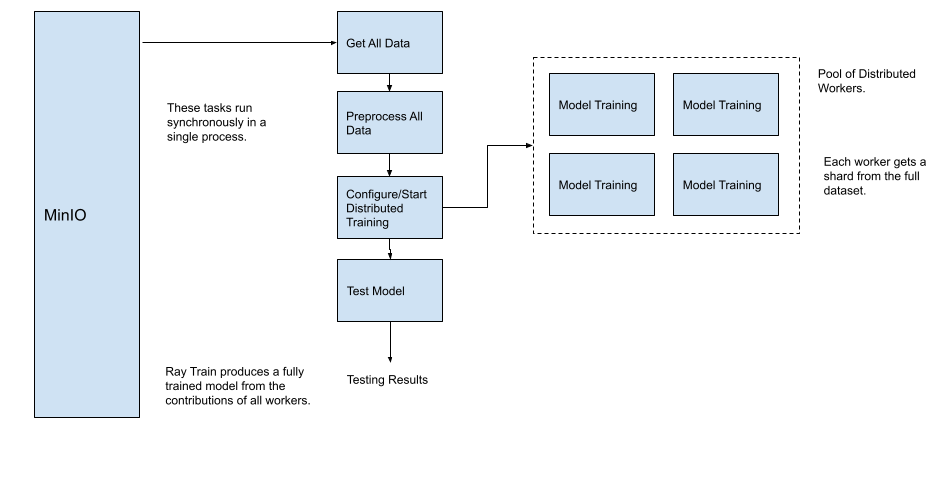
大多数工程师(像我一样)首先通过分发训练模型本身所需的计算来涉足分布式训练。这是一种非常好的入门方式——尤其是在您拥有现有的数据访问和处理代码并且想要按原样重用时。使用这种方法,仅具有分布式训练的机器学习流水线将如下面的图表所示。
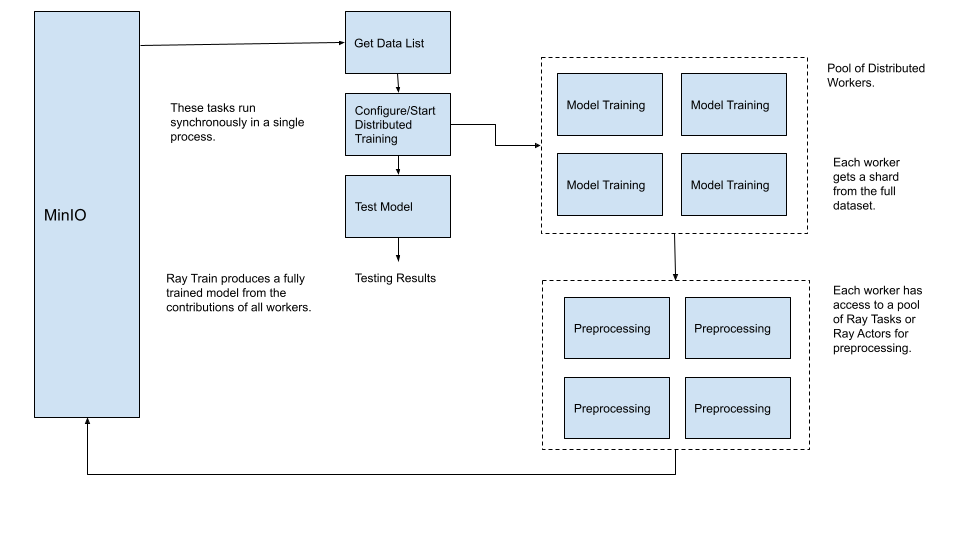
但是,如果您想要训练模型的数据无法放入内存中怎么办?即使所有数据都可以放入内存中,通过分发数据的加载和处理也可以提高效率。例如,在上图中,所有数据加载到内存中然后由单个执行线程进行预处理可能需要相当长的时间。更好的方法是找到一种方法让每个工作程序加载和预处理其数据份额(分片)。控制器节点只需要检索要共享并发送到工作程序节点的对象列表即可。此方法如下所示。
需要注意的是,在上图中,控制器节点仅检索指向对象存储的指针列表,而不是所有对象中的实际数据。当每个工作程序收到其对象指针列表时,它们将必须检索并预处理该对象。使用这样的设置,流水线中完成的繁重工作将转移到可扩展的资源上。MinIO 也是一种可扩展的资源,因为它是一个分布式对象存储,可以并行高速地处理对象请求。在上图中,我仅显示了四个工作程序进程,但可能会有数百个。在此流水线中使用低端存储解决方案将是一个错误。
让我们深入了解一下我们将在本文中构建的内容。
我们将构建什么 在这篇文章中,我将展示如何构建和测试上一节图表中所示的分布式数据处理。具体来说,我将展示如何从 MinIO 获取对象指针列表并为分布式处理设置数据。为此,我将使用 Ray Data 和 MinIO。Ray Data 是一个用于分布式机器学习工作负载的数据处理库。在我的下一篇文章中,我将展示如何使用本文中构建的内容,通过使用 Ray Train 和 MinIO 来完成我们完全分布式图表的实现。
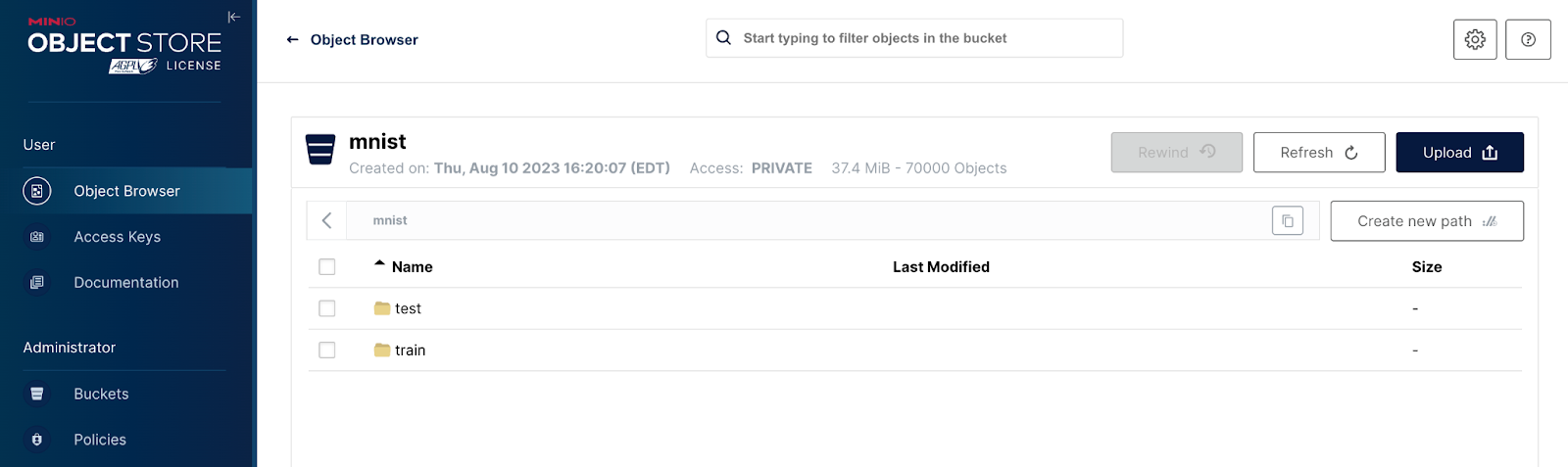
我将在本文中使用的数据集是修改后的国家标准与技术研究所 (MNIST) 数据集 代码下载
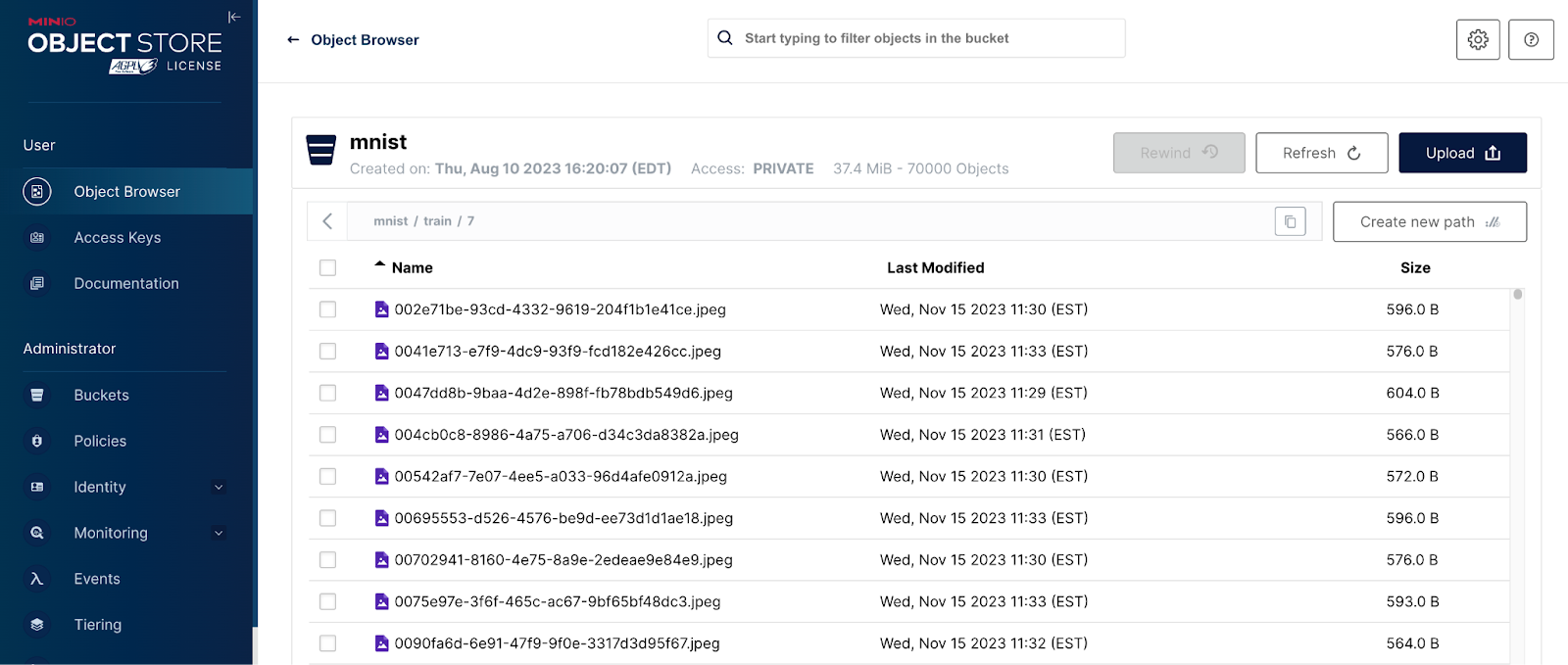
深入了解这些路径之一,我们可以看到对象本身。请参见下面的屏幕截图。对象路径包含其标签,我的脚本生成一个唯一的 GUID 来命名每个对象。由于上传脚本每次运行都会生成唯一的名称,因此您可以多次运行它——每次运行都会添加 60,000 个新的训练对象和 10,000 个新的测试对象。这是一种创建海量数据集以针对您的 AI 基础设施运行基准测试的完美方法。
现在我们了解了我们的数据及其存储方式,让我们首先创建一个从上面显示的 MinIO 存储桶检索对象列表的函数。
获取对象列表 从 MinIO 检索对象列表是通过简单地使用 MinIO SDK 完成的。由于我们的最终目标是训练模型,因此我们需要的不仅仅是一个简单的对象列表。我们需要按训练集和测试集分解的列表。此外,对于每个集合,我们需要特征和标签。使用 Python 的方法是使用以下变量:X_train、y_train、X_test、y_test。为此,我编写了下面描述的三个函数。这些函数的代码也在下面。在我的代码下载中,这些函数可以在 data_utilities.py 模块中找到。
get_train_test_data - 协调对其他函数调用的顶级函数。如果传递,它还会应用 smoke_test_size。get_object_list - 返回存储桶中所有对象的单个列表。split_train_test - 根据对象的路径创建 X_train、y_train、X_test、y_test 变量。
def get_object_list (bucket_name: str) -> List[str]: ''' Gets a list of objects from a bucket. ''' logger = create_logger() url = os.environ[ 'MINIO_URL' ] access_key = os.environ[ 'MINIO_ACCESS_KEY' ] secret_key = os.environ[ 'MINIO_SECRET_ACCESS_KEY' ] # Get data of an object. try : # Create client with access and secret key client = Minio(url, # host.docker.internal access_key, secret_key, secure= False ) object_list = [] objects = client.list_objects(bucket_name, recursive= True ) for obj in objects: object_list.append(obj.object_name) except S3Error as s3_err: logger.error( f'S3 Error occurred: {s3_err} .' ) raise s3_err except Exception as err: logger.error( f'Error occurred: {err} .' ) raise err return object_list
def split_train_test (objects: List[str]) -> Tuple[List[str], List[int], List[str], List[int]]: ''' 此函数将解析 get_object_list 函数返回的结果,并创建训练集 和测试集。 ''' X_train = [] y_train = [] X_test = [] y_test = [] for obj in objects: if obj[: 5 ] == 'train' : X_train.append(obj) label = int(obj[ 6 ]) y_train.append(label) if obj[: 4 ] == 'test' : X_test.append(obj) label = int(obj[ 5 ]) y_test.append(label) return X_train, y_train, X_test, y_test
下面的代码片段展示了如何调用 get_train_test_data 函数。请注意,我使用环境变量将 MinIO 凭据传递给我的辅助函数。
# 加载凭据和连接信息。 with open( 'credentials.json' ) as f: credentials = json.load(f) os.environ[ 'MINIO_URL' ] = credentials[ 'url' ] os.environ[ 'MINIO_ACCESS_KEY' ] = credentials[ 'accessKey' ] os.environ[ 'MINIO_SECRET_ACCESS_KEY' ] = credentials[ 'secretKey' ] X_train, y_train, X_test, y_test, load_time_sec = du.get_train_test_data() print( '训练集大小: ' , len(X_train)) print( '测试集大小:' , len(X_test)) print( '加载时间(秒):' , load_time_sec)
输出如下所示。
26090 2023-11-27 19:14:02,062 | INFO | get_train_test_data called. smoke_test_size: 0 训练 集 大小: 60000 测试 集 大小: 10000 加载时间(秒): 21.15908694267273
数据大小符合预期。原始数据集包含 60,000 个训练样本和 10,000 个测试样本。因此,在上传和列表检索之间没有丢失任何样本。我还喜欢跟踪任务花费的时间。在我的 Macbook Pro 上,使用在 Docker 中运行的 MinIO 本地实例,此任务花费了 21 秒。一旦构建了整个管道,此类统计信息将有助于定位瓶颈。
让我们检查训练集中单个样本,以准确了解我们拥有哪些数据。以下代码将查看训练集中第一个对象指针及其对应的标签。
print( '训练样本:' , X_train[ 0 ]) print( '样本标签:' , y_train[ 0 ])
输出
训练样本: train/0/000c2bff-4fa5-4e95-b90a-e39be79cf5e7.jpeg 标签 为 样本: 0
此样本指向数字零的图像。图像本身尚未加载到内存中,只有指向 MinIO 中图像的指针。我们将在分布式数据处理期间使用 X_train 中的指针检索图像。
设置分布式数据 到目前为止,我们所有的代码都使用普通的 Python 对象来存储数据。为了使我们的数据能够进行分布式数据处理,我们需要将这些数据加载到 Ray 数据集对象中。这可以通过以下代码片段完成。
train_dict_list = [{ 'X' : X_train[i], 'y' : y_train[i]} for i in range(len(X_train))] test_dict_list = [{ 'X' : X_test[i], 'y' : y_test[i]} for i in range(len(X_test))]
train_data = ray.data.from_items(train_dict_list, parallelism= 5 ) test_data = ray.data.from_items(test_dict_list, parallelism= 5 ) type(train_data)
这段代码的输出结果将是
ray.data.dataset.MaterializedDataset
这是一个Ray Data的内部类,您永远不会直接实例化它。此外,请注意from_items函数中的parallelism参数。此设置决定了Ray数据对象的所有转换将使用多少个并行进程。在上面的代码片段中,我将并行度设置为5。但是,您不应在生产应用程序中设置此参数。最好让Ray Data确定最佳值。Ray将根据设备上的CPU数量和数据大小确定最佳值。
让我们检查几行数据,看看它的形状。
rows = train_data.take( 3 ) rows
您将获得如下所示的输出
[{ 'X' : 'train/0/000c2bff-4fa5-4e95-b90a-e39be79cf5e7.jpeg' , 'y' : 0}, { 'X' : 'train/0/00143885-bede-4b19-8ef0-99135c8f2290.jpeg' , 'y' : 0}, { 'X' : 'train/0/00289886-490f-4966-ada8-2bfe1e165aa9.jpeg' , 'y' : 0}]
现在,我们拥有了所有能够进行并行(分布式)处理的Ray物化数据集。下一步是编写一个处理函数并将其映射到我们的物化数据集。
创建处理函数 我们需要做一些事情来准备我们的数据集进行训练。首先,我们必须使用对象指针从MinIO检索对象。其次,图像必须转换为驻留在Pytorch张量中的数字。最后,每个张量(每个图像一个张量)中的值必须被标准化,因为模型更喜欢小数字。下面的函数将为我们的MNIST数据集批量执行所有这些操作。
def preprocess_batch (batch: Dict[str, str], bucket_name: str) -> Dict[str, np.ndarray]: logger = create_logger() logger.info( f'preprocess_batch called. bucket_name: {bucket_name} ' ) url = os.environ[ 'MINIO_URL' ] access_key = os.environ[ 'MINIO_ACCESS_KEY' ] secret_key = os.environ[ 'MINIO_SECRET_ACCESS_KEY' ] # Get data of an object. try : # Create client with access and secret key client = Minio(url, # host.docker.internal access_key, secret_key, secure= False ) # Define a transform to normalize the data transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(( 0.5 ,), ( 0.5 ,)), ]) # Look through all the object names in the batch. for i in range(len(batch[ 'X' ])): response = client.get_object(bucket_name, batch[ 'X' ][i]) image = bytes_to_image(response.data) batch[ 'X' ][i] = transform(image) logger.info( f'Batch retrieval successful for bucket: {bucket_name} in MinIO object storage.' ) except S3Error as s3_err: logger.error( f'S3 Error occurred: {s3_err} .' ) raise s3_err except Exception as err: logger.error( f'Error occurred: {err} .' ) raise err finally : response.close() response.release_conn() return batch
关于上面代码的一些注释:它期望发送一批训练样本,并且每个批次打开一个到MinIO的连接。此外,Ray Data将此函数作为Ray任务
def create_logger (): logger = logging.getLogger( 'ray_logger' ) logger.setLevel(logging.INFO) formatter = logging.Formatter( '%(process)s %(asctime)s | %(levelname)s | %(message)s' ) stdout_handler = logging.StreamHandler(sys.stdout) stdout_handler.setLevel(logging.DEBUG) stdout_handler.setFormatter(formatter) file_handler = logging.FileHandler( 'ray_train_logs.log' ) file_handler.setLevel(logging.DEBUG) file_handler.setFormatter(formatter) logger.handlers = [] logger.addHandler(file_handler) logger.addHandler(stdout_handler) return logger
现在我们需要将我们的处理函数映射到我们的数据集。这只需一行代码即可完成。
train_data = train_data.map_batches(du.preprocess_batch, fn_kwargs={ 'bucket_name' : 'mnist' })
map_batches 函数仅仅将我们的函数与数据集关联起来。Ray Data 执行延迟转换,这意味着当我们通过批处理循环遍历数据集时,我们的函数才会被调用。接下来让我们做一个测试,检验我们已经组合好的所有内容。
在本节中,我展示了如何创建一个作为 Ray 任务运行的函数。创建执行相同操作的Ray Actor Ray 用户指南 代码示例
测试分布式数据处理 由于我们还没有准备好将数据集用于训练(我会在下一次文章中进行),我们将编写一些测试代码来调用我们的处理函数。这在下面使用训练数据的 iter_torch_batches 方法完成。
batch_count = 0 batch_size = 0 for batch in train_data.iter_torch_batches(batch_size= 400 , dtypes=torch.float32): if batch_size == 0 : batch_size = len(batch[ 'X' ]) images, labels = batch[ 'X' ], batch[ 'y' ] batch_count += 1 else : print(type(batch)) print(type(images)) print( 'Batch size: ' , batch_size) print( 'Batch count:' , batch_count) print(images[ 0 ]) print(labels[ 0 ])
运行此代码后,您将看到以下输出。
'dict' > 'torch.Tensor' > Batch size: 400 Batch count: 150 tensor([[[-1.0000, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000, -0.9843, -0.9922, -0.9765, -1.0000, -0.9686, -0.9922, -0.9608, -0.9451, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000], [-1.0000, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000, ... -1.0000, -1.0000, -1.0000, -0.9843, -0.9294, -0.9608, -1.0000, -0.9843, -0.9529, -0.9686, -0.9529, -0.9843, -1.0000, -0.9608, -0.9686, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000, -1.0000]]]) tensor(9.)
此外,以下是运行上述循环后我的日志文件开头的摘录。第一列是进程 ID,后跟时间戳。如您所见,五个进程并行启动并运行。
78560 2023-11-29 11:38:45,860 | INFO | 调用 get_images_by_batch。bucket_name: mnist 78558 2023-11-29 11:38:46,037 | INFO | 调用 get_images_by_batch。bucket_name: mnist 78567 2023-11-29 11:38:46,038 | INFO | 调用 get_images_by_batch。bucket_name: mnist 78565 2023-11-29 11:38:46,046 | INFO | 调用 get_images_by_batch。bucket_name: mnist 78561 2023-11-29 11:38:46,048 | INFO | 调用 get_images_by_batch。bucket_name: mnist
并行度的最佳值因系统和集群而异,所以尽情尝试吧。
总结和后续步骤 在这篇文章中,我们迈出了构建完全分布式端到端机器学习管道的第一步。具体来说,我们设置(并测试)了一个Ray Dataset,它可以以分布式方式加载和预处理数据。
下一步是通过实现 Ray Train 工作器来完成管道,这些工作器使用我们的 Ray Dataset 在 Ray 工作器内进行分布式数据处理和模型训练。我将在我的下一篇文章中进行此操作。所以,请继续关注 MinIO 博客。