在过去的几个月里,我写了一些关于不同技术的文章(Ray Data Ray Train MLflow Ray Train 文章 这里
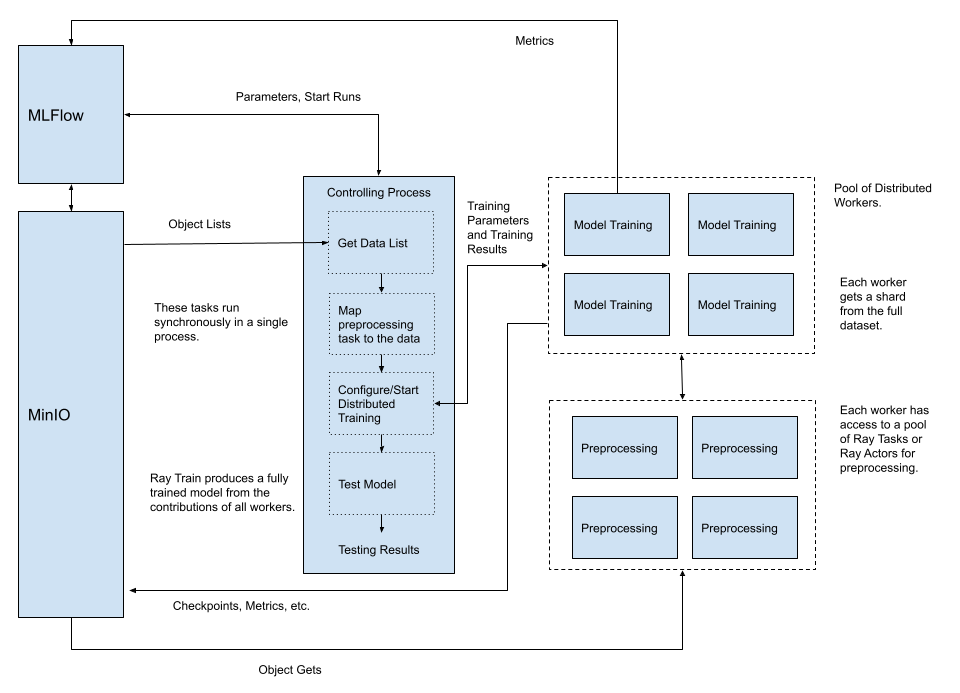
下面的图表可视化了分布式训练、分布式预处理和 MLflow 如何协同工作。这是我在 Ray Train 文章中介绍的图表,添加了 MLFlow。它代表了为所有 AI 计划构建基础的良好起点:MinIO 用于高速对象存储,Ray 用于分布式训练和数据处理,以及 MLFlow 用于 MLOPs。
为分布式训练设置 MLFlow 以下代码是分布式训练的设置,并添加了 MLFlow 设置代码。我已经突出显示了 MLFlow 所需的附加代码。在函数顶部,配置了 MLFlow 并启动了一个运行。我会在下一部分解释对训练配置参数的添加。运行完成后,您需要让 MLFlow 知道 - 这是在函数底部完成的。如果您不熟悉 MLFlow 跟踪,请查看我关于 使用 MinIO 进行 MLFlow 跟踪 使用 MLflow 和 MinIO 设置开发机器
def distributed_training (training_parameters, num_workers: int, use_gpu: bool): logger = du.create_logger() # Setup mlflow to point to our server. experiment_name = 'MLFlow - Ray test' run_name = 'Testing Epoch metrics' mlflow_base_url = 'https://:5001/' mlflow.set_tracking_uri(mlflow_base_url) active_experiment = mlflow.set_experiment(experiment_name) active_run = mlflow.start_run(run_name=run_name) training_parameters[ 'mlflow_base_url' ] = mlflow_base_url training_parameters[ 'run_id' ] = active_run.info.run_id # Log parameters mlflow.log_params(training_parameters) logger.info( 'Initializing Ray.' ) initialize_ray() train_data, test_data, load_time_sec = du.get_ray_dataset(training_parameters) # Scaling configuration scaling_config = ScalingConfig(num_workers=num_workers, use_gpu=use_gpu) # Initialize a Ray TorchTrainer start_time = time() trainer = TorchTrainer( train_loop_per_worker=train_func_per_worker, train_loop_config=training_parameters, datasets={ 'train' : train_data}, scaling_config=scaling_config, run_config=get_minio_run_config() ) result = trainer.fit() training_time_sec = (time()-start_time) logger.info(result) logger.info( f'Load Time (in seconds) = {load_time_sec} ' ) logger.info( f'Training Time (in seconds) = {training_time_sec} ' ) model = tu.MNISTModel(training_parameters[ 'input_size' ],
training_parameters[ 'hidden_sizes' ],
training_parameters[ 'output_size' ]) with result.checkpoint.as_directory() as checkpoint_dir: model.load_state_dict(torch.load(os.path.join(checkpoint_dir, "model.pt" ))) tu.test_model(model, test_data) # 关闭 Ray ray.shutdown() # 结束运行 mlflow.end_run()
跟踪分布式实验的问题 将 MLFlow Python 库与分布式训练一起使用的问题是,它的所有函数都使用一个在内部维护的运行 ID - 运行 ID 本身不是函数(如 log_metric() 或 log_metrics())的参数。因此,当 Ray Train 工作节点启动时,它们将不会拥有控制进程启动运行时创建的运行 ID,因为它们处于不同的进程中。这个问题很容易解决。我们可以简单地将运行 ID 作为训练配置的一部分传递到工作节点进程。但是,这并不能解决 MLFlow 库的问题。幸运的是,MLFlow 具有一个 REST API,它接受运行 ID 作为所有调用的参数。它还需要 MLflow 的基本 URL。以下是一个函数,它包装了 MLFlow REST API 用于记录指标。查看 MLFlow REST API 示例
def log_metric (base_url: str, run_id: str, metric: Dict[str, float]) -> int: '''为给定运行记录指标字典。''' base_url = f' {base_url} /api/2.0/mlflow' url = base_url + '/runs/log-metric' payload = { "run_id" : run_id, "key" : metric[ "key" ], "value" : metric[ "value" ], "timestamp" : mlflow.utils.time.get_current_time_millis(), "step" : metric[ "step" ], } r = requests.post(url, json=payload) return r.status_code
可以使用以下代码片段将 MLflow 的基本 URL 和运行 ID 添加到训练配置变量中。(训练配置变量是一个 Python 字典;它是唯一可以传递给工作函数的参数。)
training_parameters[ 'mlflow_url' ] = mlflow_url training_parameters[ 'run_id' ] = active_run.info.run_id
现在我们有了一种将 MLflow 信息发送到分布式工作器的方法,并且有一个可以对 MLflow 的跟踪服务器进行 RESTful 调用的函数。下一步是在分布式工作器的训练循环中使用上面的函数。
将实验跟踪添加到 Ray Train 工作器 在远程工作器进程中运行的函数中添加跟踪需要最少的代码。下面显示了添加了突出显示的代码行的完整函数。
def train_func_per_worker (training_parameters): # 训练模型并记录训练指标。 model = tu.MNISTModel(training_parameters[ 'input_size' ],
training_parameters[ 'hidden_sizes' ], training_parameters[ 'output_size' ]) model = ray.train.torch.prepare_model(model) # 获取训练工作进程的数据集分片。 train_data_shard = train.get_dataset_shard( 'train' ) loss_func = nn.NLLLoss() optimizer = optim.SGD(model.parameters(), lr=training_parameters[ 'lr' ],
momentum=training_parameters[ 'momentum' ]) metrics = {} batch_size_per_worker = training_parameters[ 'batch_size_per_worker' ] for epoch in range(training_parameters[ 'epochs' ]): total_loss = 0 batch_count = 0 for batch in train_data_shard.iter_torch_batches(batch_size=batch_size_per_worker): # Get the images and labels from the batch. images, labels = batch[ 'X' ], batch[ 'y' ] labels = labels.type(torch.LongTensor) # casting to long images, labels = images.to(device), labels.to(device) # Flatten MNIST images into a 784 long vector. images = images.view(images.shape[ 0 ], -1 ) # Training pass optimizer.zero_grad() output = model(images) loss = loss_func(output, labels) # This is where the model learns by backpropagating loss.backward() # And optimizes its weights here optimizer.step() total_loss += loss.item() batch_count += 1 metrics = { 'training_loss' : total_loss/batch_count} checkpoint = None if train.get_context().get_world_rank() == 0 : temp_dir = os.path.join(os.getcwd(), 'checkpoint' ) torch.save(model.module.state_dict(), os.path.join(temp_dir, 'mnist_model.pt' )) checkpoint = Checkpoint.from_directory(temp_dir) mlflow_metric = {} mlflow_metric[ 'key' ] = 'training_loss' mlflow_metric[ 'value' ] = loss.item() mlflow_metric[ 'step' ] = epoch+ 1 log_metric(training_parameters[ 'mlflow_base_url' ], training_parameters[ 'run_id' ],
mlflow_metric) train.report(metrics, checkpoint=checkpoint)
这段代码有一些需要注意的地方。首先,我只从一个工作进程记录指标。虽然所有工作进程都有自己正在训练的模型副本,但它们在工作进程之间是同步的。因此,没有必要从每个工作进程记录指标。如果你这样做,你将在 MLFlow 中获得冗余信息。其次,这段代码仍然使用 Ray Train 报告指标和检查点。如果你愿意,可以将所有报告和检查点转移到 MLFlow。
总结 在这篇文章中,我展示了如何将 MLflow 跟踪添加到使用分布式训练和分布式预处理的机器学习管道中。如果你想了解更多关于 MinIO、Ray Data、Ray Train 和 MLflow 的功能,请查看以下相关文章。
使用 Ray Train 和 MinIO 进行分布式训练
使用 Ray Data 和 MinIO 进行分布式数据处理
使用 MLFlow 和 MinIO 设置开发机器
MLflow 跟踪和 MinIO
MLflow 模型注册表和 MinIO
将这些技术整合到你的 ML 管道中是构建完整 AI 基础设施的第一步。你将拥有:
MinIO - 高性能数据湖 Ray Data - 分布式预处理 Ray Train - 分布式训练 MLflow - MLOPs 下一步,考虑将一个现代数据湖
如果你想进一步讨论,请随时在我们的通用 Slack 频道 hello@min.io