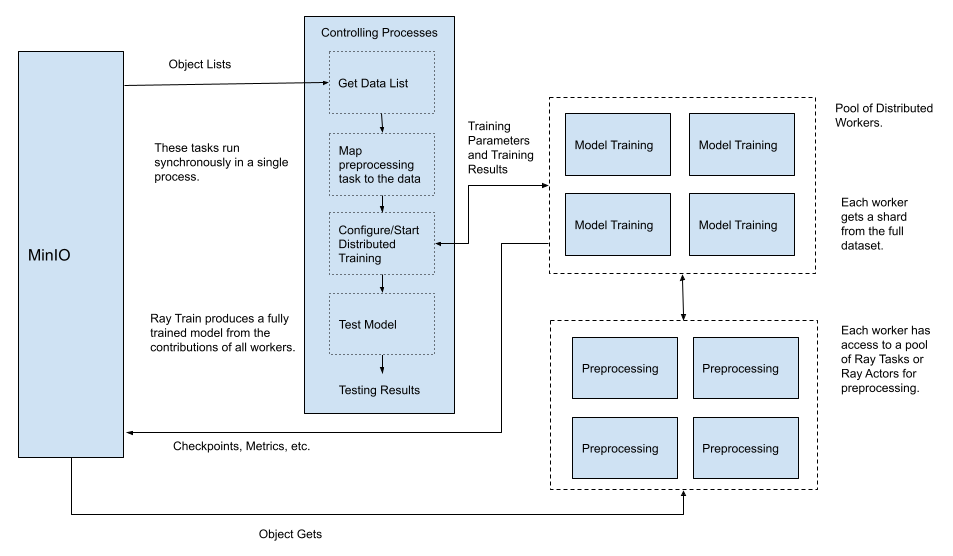
在单线程管道中,数据处理(或者在机器学习领域通常称为数据预处理)通常通过将整个数据集加载到内存中并在将数据传递给模型进行训练之前对其进行转换来完成。但是,一旦你想要利用分布式训练技术,这应该发生变化。数据预处理可以在训练循环中增量完成。在我关于 Ray Data 的上一篇文章中,我展示了如何使用可以映射到预处理任务或 Actor 的 Ray 数据集来分布式数据预处理。具体来说,我展示了如何创建 Ray 数据集并将其映射到处理任务。然后,我们通过迭代数据集并观察每个迭代执行的预处理任务来测试该数据集。此外,我还展示了如何使用 MinIO 作为数据集的来源,该数据集太大而无法完全加载到内存中。这需要查询 MinIO 以获取用于训练的对象列表,并将对象检索编码到我们的预处理任务中。如果你还没有阅读这篇文章,请现在快速阅读一下。
在这篇文章中,我将展示如何实现完全分布式 ML 训练管道所需的第二个修改。我将展示如何分布式模型训练并在训练循环中使用映射的数据集。在运行需要很长时间才能完成的训练函数时,最好在每个 epoch 之后对模型进行检查点。检查点也是你检索最终完全训练好的模型的方式。这篇文章将向你展示如何将模型检查点保存到 MinIO。
momentum=training_parameters['momentum']) metrics = {} batch_size_per_worker = training_parameters['batch_size_per_worker'] for epoch in range(training_parameters['epochs']): total_loss = 0 batch_count = 0 for batch in train_data_shard.iter_torch_batches(batch_size=batch_size_per_worker): # Get the images and labels from the batch. images, labels = batch['X'], batch['y'] labels = labels.type(torch.LongTensor) # casting to long images, labels = images.to(device), labels.to(device) # Flatten MNIST images into a 784 long vector. images = images.view(images.shape[0], -1) # Training pass optimizer.zero_grad() output = model(images) loss = loss_func(output, labels) # This is where the model learns by backpropagating loss.backward() # And optimizes its weights here optimizer.step() total_loss += loss.item() batch_count += 1 metrics = {'training_loss': total_loss/batch_count} checkpoint = None if train.get_context().get_world_rank() == 0: temp_dir = os.getcwd() torch.save(model.module.state_dict(), os.path.join(temp_dir, 'mnist_model.pt')) checkpoint = Checkpoint.from_directory(temp_dir) train.report(metrics, checkpoint=checkpoint)
此函数中第一次使用 ray 框架是通过使用 ray.train.torch.prepare_model() 函数来准备模型进行分布式训练。此函数创建了一个新的模型,该模型能够与在其他 Worker 中以相同方式创建的模型同步梯度和参数。
defdistributed_training(training_parameters, num_workers: int, use_gpu: bool): logger = du.create_logger() logger.info('Initializing Ray.') initialize_ray() train_data, test_data, load_time_sec = du.get_ray_dataset(training_parameters) # 缩放配置 scaling_config = ScalingConfig(num_workers=num_workers, use_gpu=use_gpu) # 初始化 Ray TorchTrainer start_time = time() trainer = TorchTrainer( train_loop_per_worker=train_func_per_worker, train_loop_config=training_parameters, datasets={'train': train_data}, scaling_config=scaling_config, run_config=get_minio_run_config() ) result = trainer.fit() training_time_sec = (time()-start_time) logger.info(result) logger.info(f'Load Time (in seconds) = {load_time_sec}') logger.info(f'Training Time (in seconds) = {training_time_sec}') model = tu.MNISTModel(training_parameters['input_size'],
training_parameters['hidden_sizes'],
training_parameters['output_size']) with result.checkpoint.as_directory() as checkpoint_dir: model.load_state_dict(torch.load(os.path.join(checkpoint_dir, "model.pt"))) tu.test_model(model, test_data) ray.shutdown()
缩放配置对象(从 ScaleConfig 类创建)告诉 Ray Train 我们想要多少个 worker 以及是否要使用 GPU。run_config 参数决定 Ray Train 将把指标和检查点发送到哪里。我将在后面的部分展示如何使用 run_config 将数据发送到 MinIO。
result = trainer.fit() model = tu.MNISTModel(training_parameters['input_size'],
training_parameters['hidden_sizes'],
training_parameters['output_size'])
with result.checkpoint.as_directory() as checkpoint_dir: model.load_state_dict(torch.load(os.path.join(checkpoint_dir, "model.pt"))) tu.test_model(model, test_data)
摘要
在这篇文章中,我完成了之前文章中开始的内容,展示了如何使用 Ray Data 分发在训练模型之前需要进行的任何预处理。我展示了如何分发模型的训练。我还展示了如何配置 Ray Train 将指标和检查点发送到 MinIO。最后,我展示了如何加载检查点,以便您可以测试和部署模型。