这篇文章是与来自cnvrg.io 的 Harinder Mashiana 合作撰写的。
大型语言模型 (LLM) 彻底改变了科技界,为文本分析、语言翻译和聊天机器人交互提供了强大的功能。这场革命将对企业产生重大影响,根据 OpenAI 的说法,大约 80% 的美国劳动力至少有 10% 的工作任务会受到 GPT 引入的影响。虽然 LLM 的前景和价值显而易见,但它们也存在一些局限性,需要考虑并加以解决以提高其性能和效率。在这篇博文中,我们将探讨 LLM 的一些缺点,以及如何通过利用运行在 cnvrg.io 上的 RAG(检索增强生成)和 MinIO 来克服这些缺点。此处提供的演示将展示如何针对特定用例微调 LLM。
在深入探讨挑战之前,让我们简要概述一下我们在本解决方案中用来构建更有效的 LLM 的工具。
cnvrg.io 是一个完整的机器学习操作系统,它拥有 AI 开发人员在任何基础设施上构建和部署 AI 所需的一切。cnvrg.io 由数据科学家为 AI 开发人员构建,旨在简化机器学习流程并利用 MLOps,使他们能够减少在技术复杂性上的时间投入,并专注于利用 AI 创造价值。cnvrg.io 提供无与伦比的灵活性,可以在本地或任何云环境中运行。cnvrg.io 允许开发人员利用 MinIO 构建具有 RAG 的 LLM 管道。
要了解更多信息,请访问https://cnvrg.io/ | 什么是 MinIO?MinIO 是一款高性能、与 S3 兼容的对象存储。它是为大规模 AI/ML、数据湖和数据库工作负载而构建的。它可以在本地和任何云(公共或私有)以及从数据中心到边缘运行。MinIO 是软件定义的,并在 GNU AGPL v3 下开源。企业使用 MinIO 来满足 ML/AI、分析、备份和归档工作负载的需求,所有这些都来自单个平台。MinIO 非常易于安装和管理,提供了一套丰富的企业功能,针对安全性、弹性、数据保护、可扩展性和身份管理。在本演示中,MinIO 用于存储客户的文档。
|
利用大型语言模型的挑战
大型语言模型作为独立解决方案存在一些可以缓解的缺点。举几个例子:
- 响应过时 - LLM 受限于其训练数据,如果未经常更新和重新训练,可能会产生过时的响应。
- 缺乏行业特定知识 - 通用 LLM 不具备提供上下文特定响应所需的特定领域知识。
- 频繁更新知识的培训成本高昂 - LLM 的大规模特性导致频繁更新知识的培训需求成本高昂且资源密集。
- 幻觉 - 即使经过微调,LLM 也会“产生幻觉”或生成与提供的数据不符的事实错误的响应。
检索增强生成 (RAG) 是一种强大的工具,可以改善大型语言模型的优势和效率。
RAG 如何工作?
假设你向 ChatGPT 提问关于今天发生的事情。它将无法回答这个问题,因为它是在 2021 年之前的数据上进行训练的。RAG 可以帮助你克服这个问题。检索增强生成 (RAG) 是一种将自然语言处理中的两种关键方法相结合的技术:基于检索的模型和基于生成的模型。例如,假设 RAG 可以访问一个包含最新新闻文章的数据库。现在,当你的客户提出问题时,RAG 将根据问题访问前 5 个最相关的文档,并将它们发送给你的 LLM,以便更准确地回答问题。
使用 RAG,你可以使用更小的语言模型,因为每次请求都会发送最新的和上下文相关的的信息。RAG 解决上面列出的每个组织在实施 LLM 时都会面临的挑战。
- 最新的响应以及改进的精确度和召回率 - RAG 管道通过将检索机制集成到 LLM 中来增强精确度和召回率,从而降低不准确或不相关响应的可能性。这有助于减少不准确性并捕获更广泛的信息范围,从而提高召回率。
- 上下文理解和行业特定知识 - RAG 管道通过集成能够访问外部知识库或网络的系统来增强 LLM 的上下文理解和行业特定知识,从而使模型能够检索超出其训练数据的相关信息。
- 高效的计算和减少延迟 - RAG 管道通过使用更小、更高效的模型来降低 LLM 的高计算成本和延迟,同时以显着降低的计算开销提供更高质量的响应。
- 缓解偏见和改善公平性以解决幻觉问题 - 检索机制能够检索更多样化的信息,提供多种视角。此外,这些系统提供的对信息源的明确控制允许使用精选的多样化文档集,从而减少偏见来源的影响。
如何在 cnvrg.io 上使用 RAG 来增强 LLM 与 MinIO
为了展示 RAG 和 MinIO 的功能,我们在 cnvrg.io 上构建了一个端到端解决方案。此解决方案利用 RAG 作为 cnvrg.io 上的端点,允许用户使用 API 请求提问,cnvrg.io 作为编排平台,MinIO 作为存储解决方案。
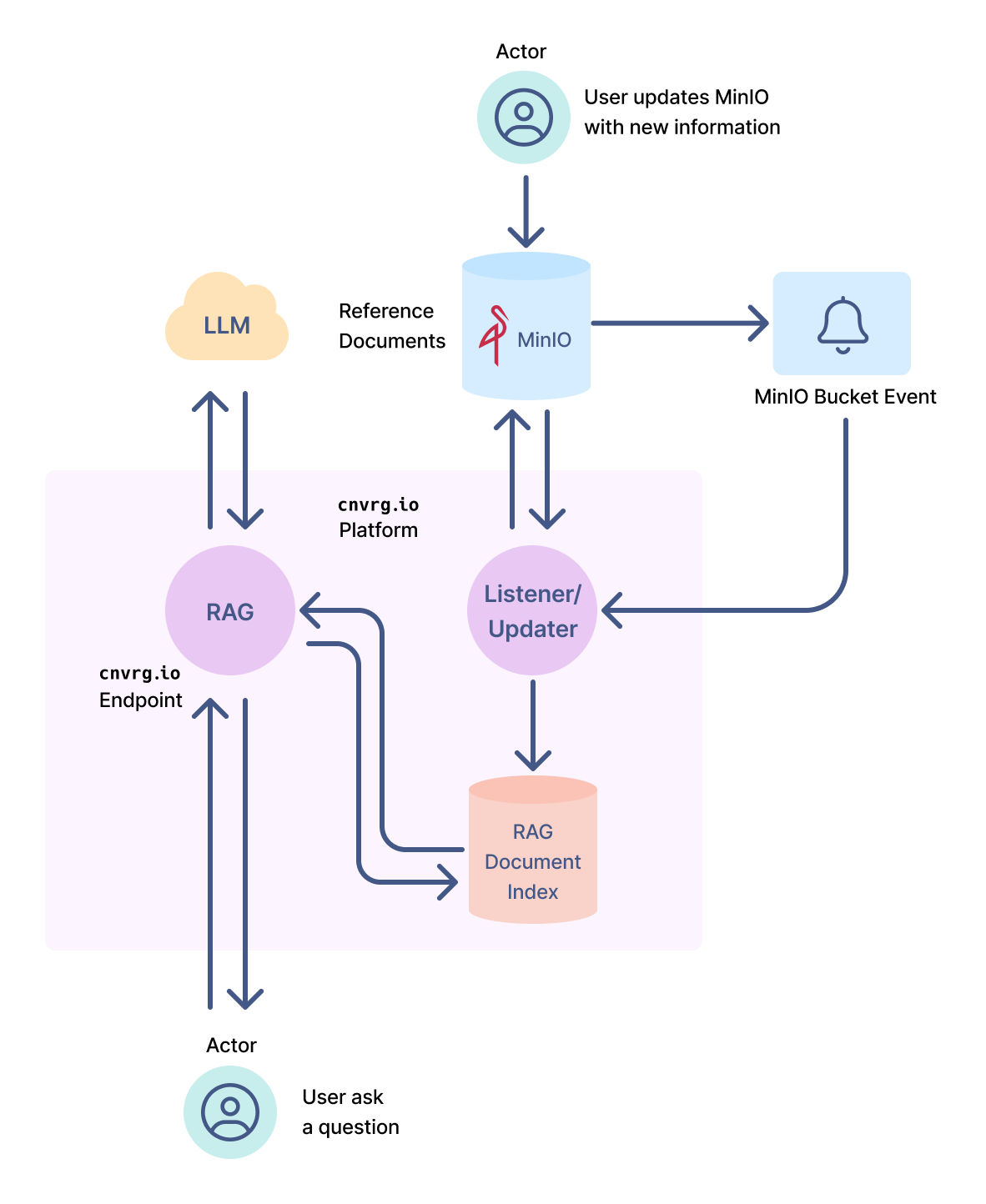
图 1
构建优化的 LLM 管道
使用 cnvrg.io,你可以构建自己的检索管道,并辅助任何生成模型的内容生成。使用 cnvrg.io、MinIO 和 RAG,你可以优化你的 LLM,并为你的解决方案带来以下优势:
- 降低模型大小,从而降低成本
- 为你的解决方案定制上下文响应
在图 1 中所示的解决方案中,RAG 部署为 cnvrg.io 上的端点,用户可以通过 API 提交问题。生成响应的事件序列总结如下:

图 2
使用 MinIO,用户可以轻松更新 RAG 使用的文档。将新文档上传到指定的 MinIO 存储桶,将触发一个事件,该事件会被 Listener/Updater 捕获,Listener/Updater 将从你的存储桶下载新文档并更新 RAG 文档索引。下次向 RAG 端点提交问题时,它将可以访问新文档并将它们提供给 LLM 以生成改进的响应。

图 3
让我们看看从用户角度来看这可能是什么样子。在本例中,我们正在利用fastRAG,这是一个用于构建针对英特尔 CPU 优化的性能优异的 RAG 管道的开源库。
假设有一种新的疾病正在传播,并且你已经用关于这种名为 X 的新疾病的信息更新了你的数据库。
问题:我喉咙痛,还腹泻。可能是什么原因?
无 RAG 的回答:喉咙痛和腹泻可能由多种原因引起,包括病毒、细菌甚至食物过敏。最好去看医生进行正确的诊断和治疗。
使用 RAG 的回答:你的症状可能是多种因素造成的,包括病毒、细菌或食物过敏,但听起来你可能也患有 X 病的症状,这是一种新传播的疾病。建议你进行 X 病的检测,并在检测结果呈阴性之前与他人隔离。此外,在你从感冒、喉咙痛和腹泻中恢复期间,务必休息并照顾好自己,并多喝水。请也去看医生以获得正确的诊断和治疗。
如你所见,没有 RAG 的 LLM 没有新数据,产生的答案中不包含有关新疾病的信息。而使用 RAG 的 LLM 可以访问新的和相关的数据,并产生了一个包含有关最新疾病信息的答案。
使用 MinIO 进行文档存储
当客户上传文档以微调 LLM 时,这些文档将安全地存储在 MinIO 中。此外,RAG 解决方案利用了MinIO 的存储桶事件。当文档到达 MinIO 时,会触发一个事件,导致调用 Webhook。(图 1 中的 Listener/Updater。)Listener/Updater 处理新文档并更新客户的文档索引数据库。此解决方案的未来版本可能会利用 MinIO 的对象 Lambda 功能。MinIO 的对象 Lambda 使应用程序开发人员能够在将数据返回到应用程序之前处理从 MinIO 检索到的数据。如果你需要删除敏感信息或想要记录检索活动,这将非常有用。
英特尔推理优化
RAG 算法和模型可以直接使用 CPU 部署,而无需使用昂贵的 GPU 进行检索管道。像 GPT-3 这样的大型语言模型在运行时计算成本很高,尤其是在处理长而复杂查询或文档时。检索模型可以充当初始过滤器,缩小搜索范围并减少需要由生成模型处理的查询数量。通过检索相关文档或段落,我们可以显着降低为每个输入生成响应的计算成本。此外,根据所使用的语言模型,完全可以使用 CPU 部署 LLM,就像我们在上面共享的示例中所做的那样。
总结
检索增强管道代表了 NLP 领域的一项重大进步,它利用了大型语言模型和高效检索机制的优势。这些管道提供了诸如增强精确度和召回率、扩展知识、缓解偏见、计算效率和改进泛化等优势。通过将大型语言模型的功能与信息检索技术相结合,检索增强管道为更准确、更具上下文丰富性和更高效的 NLP 系统铺平了道路。随着该领域的研发生产的不断发展,我们可以预期检索增强管道将在塑造自然语言处理的未来中发挥至关重要的作用。

