MinIO 中擦除编码对 CPU 利用率的影响

擦除编码是 MinIO 核心功能之一。它是为分布式设置提供高可用性的基石之一。简而言之,写入 MinIO 的对象会被分成多个数据分片 (M)。为了补充这些数据分片,我们会创建一定数量的奇偶校验分片 (K)。然后,这些分片会分布在多个磁盘上。只要有 M 个分片可用,就可以重建对象数据。这意味着我们可以丢失 K 个分片而不会丢失数据。更多详细信息,请参阅 擦除编码 101。
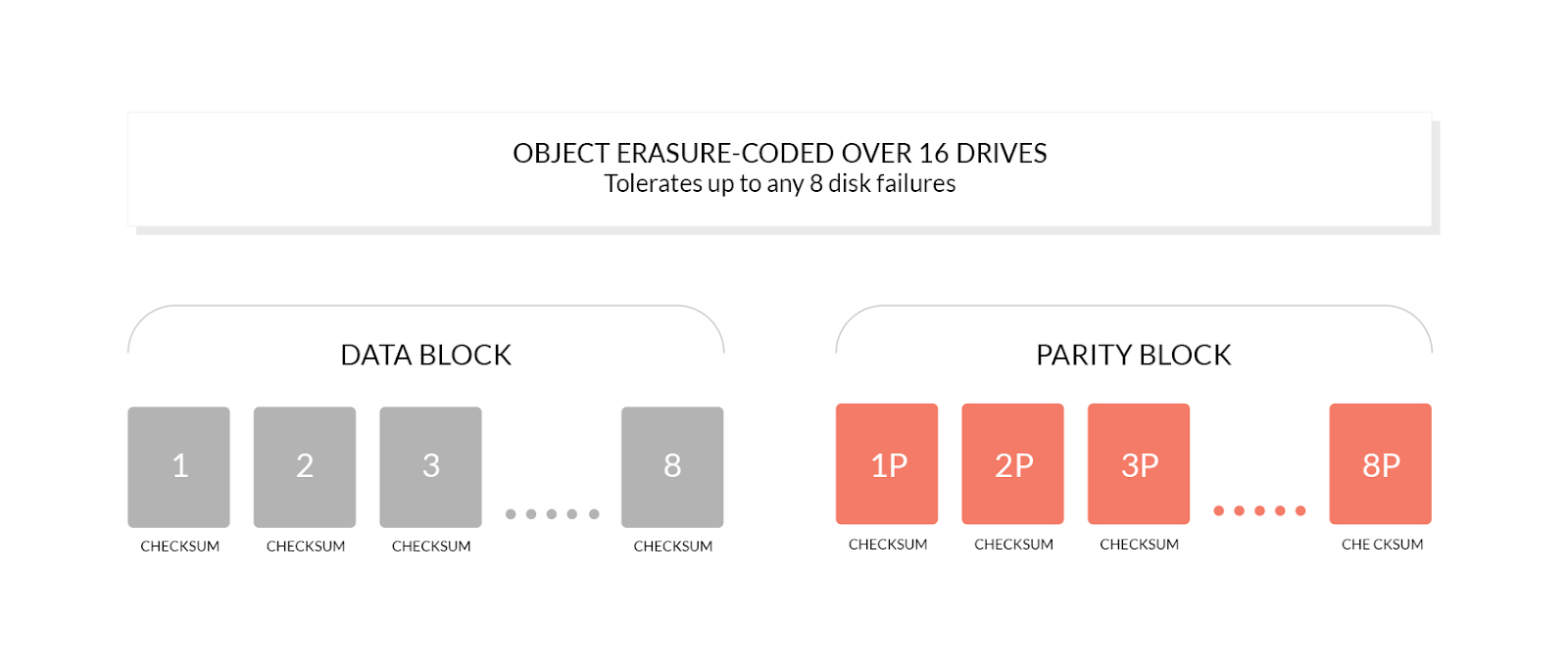
传统上,擦除编码被认为是一项 CPU 密集型任务。因此,存在专门用于创建擦除码的硬件。但是,MinIO 不使用此类硬件,那么这是否应该成为性能方面需要关注的问题呢?
2006 年,英特尔发布了补充流式 SIMD 扩展 3,通常称为 SSSE3。几年后,人们发现 SSSE3 中的特定指令可以用来将擦除编码的速度提高近一个数量级。从那时起,英特尔发布了 伽罗华域新指令 (GFNI),进一步将这些计算加速了大约 2 倍。
这些创新,加上可以利用这些扩展的软件,使得擦除编码在没有专用硬件的情况下成为可能。这对我们来说很重要,因为我们的主要目标之一是在通用硬件上使 MinIO 性能良好。也就是说,让我们来探讨一下实际性能。
测试设置
为了测试各种平台的性能,我们创建了一个 小型应用程序 和一个配套的 脚本,该脚本在一个对 MinIO 来说现实的场景中对性能进行了基准测试。
- 块大小:1MiB
- 块数:1024
- M/K:12/4、8/8、4/4
- 线程:1->128
所有 MinIO 对象都以最大 1MiB 的块写入,该块大小除以我们要写入数据分片的驱动器数量。因此,我们在测试中保持此数字不变。
基准测试对 1024 个块进行操作。这意味着输入数据为 1GiB。这样做是为了消除 CPU 缓存的影响。我们这样做是为了测试最坏情况下的性能,而不仅仅是数据位于 L1/L2/L3 缓存时的性能。
选择 CPU 以全面了解各种平台的性能。
- 英特尔® 至强® 白金 8461V(Sapphire Rapids,48 核,96 线程)
- 2 x 英特尔® 至强® 金 6338(Ice Lake,2 x 32 核,128 线程)
- AMD EPYC 7R13(Milan,48 核,96 线程)
- Amazon Graviton 3(ARM,64 核,64 线程)
请参阅文章末尾,了解测量数据的链接。
基准测试
我们测量了三种不同的擦除码配置下的编码和解码速度。
编码 12+4
首先,我们查看对象跨 16 个磁盘分片时的编码速度。使用默认设置,MinIO 会将数据分成 12 个分片并创建 4 个奇偶校验分片。我们将查看使用不同数量的核心进行计算的速度。这是将对象上传到 MinIO 时执行的操作。为了使其易于与 NIC 速度进行比较,我们以每秒千兆位显示速度。
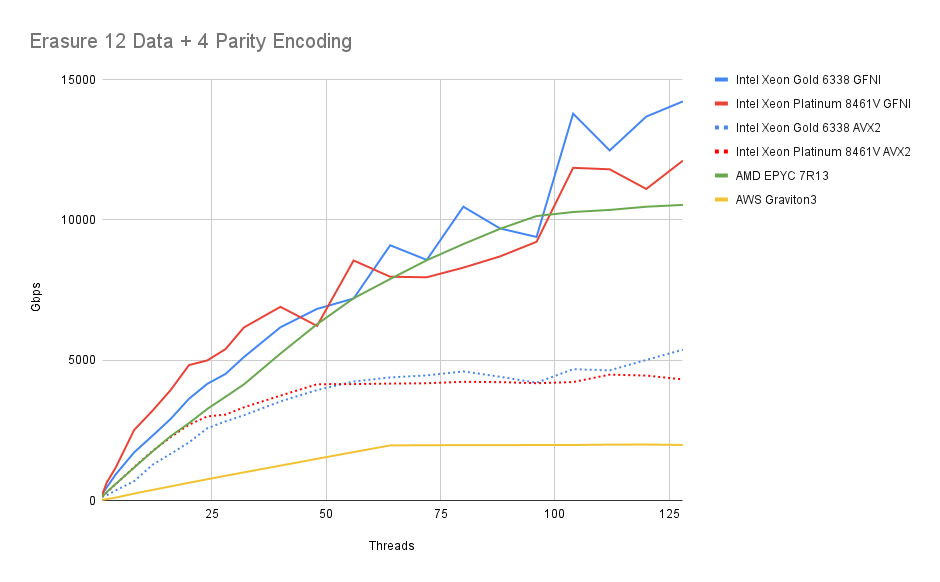
在此图表中,我们可以看到我们很快就超过了顶级 400Gibps NIC 的速度——事实上,所有 x86-64 平台都可以使用少于 4 个线程来做到这一点,而 Graviton 3 需要大约 16 个核心。
较旧的双插槽英特尔 CPU 几乎可以跟上新一代单插槽英特尔 CPU 的速度。AMD 紧随英特尔,尽管此 CPU 代没有提供 GFNI 支持。出于好奇,我们还在没有 GFNI 的情况下测试了英特尔 CPU,仅使用 AVX2。
我们看到 Graviton 3 在达到其核心数量时达到峰值,正如我们预期的那样。
解码 12+4
接下来,我们查看重建对象时的性能。即使在本地分片包含奇偶校验以减少远程调用的情况下,MinIO 也会重建对象,即使这并非严格必要。
设置与上面类似。对于每个操作,从剩余数据中重建 1 到 K(此处为 4)个分片。
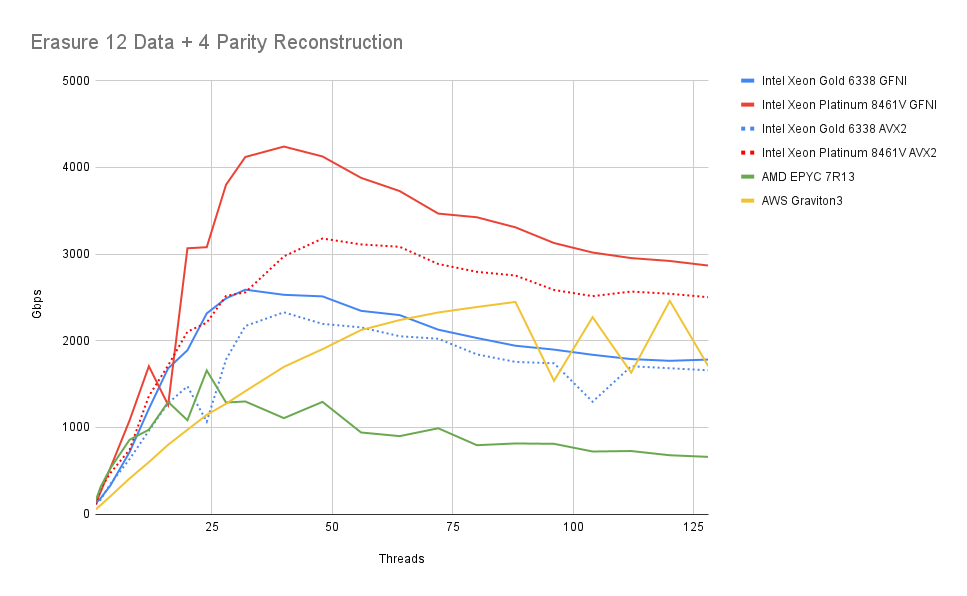
首先,我们观察到我们很快就超过了我们可以遇到的最大 NIC 速度。实际上,这意味着擦除编码的 CPU 利用率在任何设置中都不会消耗超过几个核心。
我们还可以看到,随着使用核心数量的增加,性能略有下降。这可能是内存带宽竞争的结果。如上所述,由于其他系统瓶颈,任何服务器都不太可能达到此利用率范围。
8 个数据 + 8 个奇偶校验
我们调查的另一个设置是 16 个驱动器设置,其中每个对象被分成 8 个数据分片并创建 8 个奇偶校验分片。
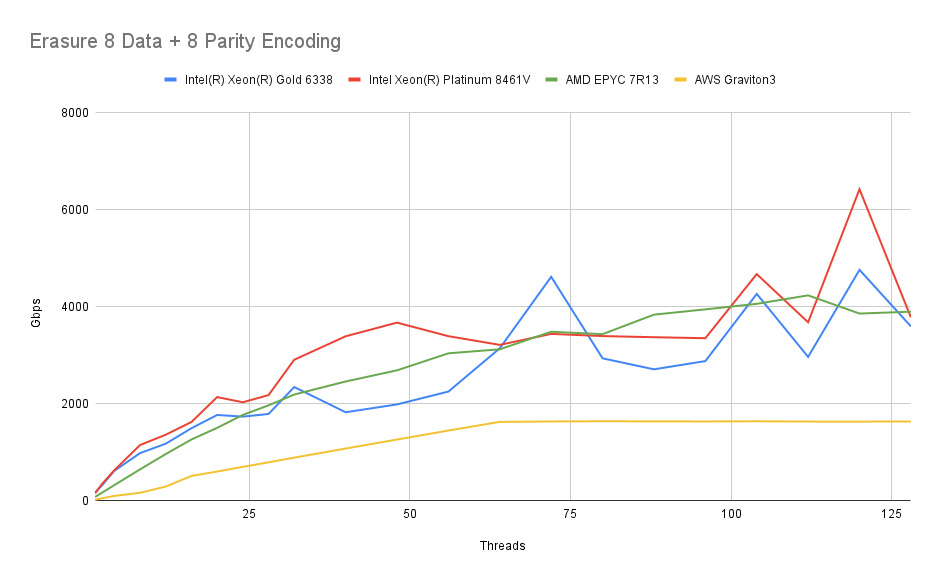
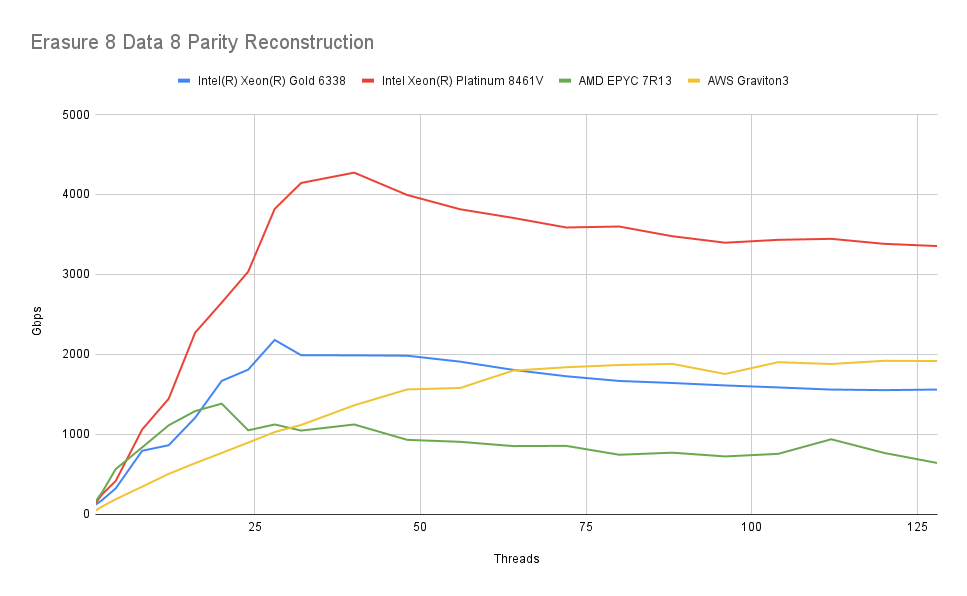
我们观察到类似的模式,速度下降幅度略高。可能这是由于每次操作写入的数据量更大造成的。但速度下降幅度并不令人担忧,达到 400 GbE NIC 的速度应该不成问题。
4 个数据 + 4 个奇偶校验
最后,我们对对象被分成 4 个数据分片和 4 个擦除分片的设置进行基准测试

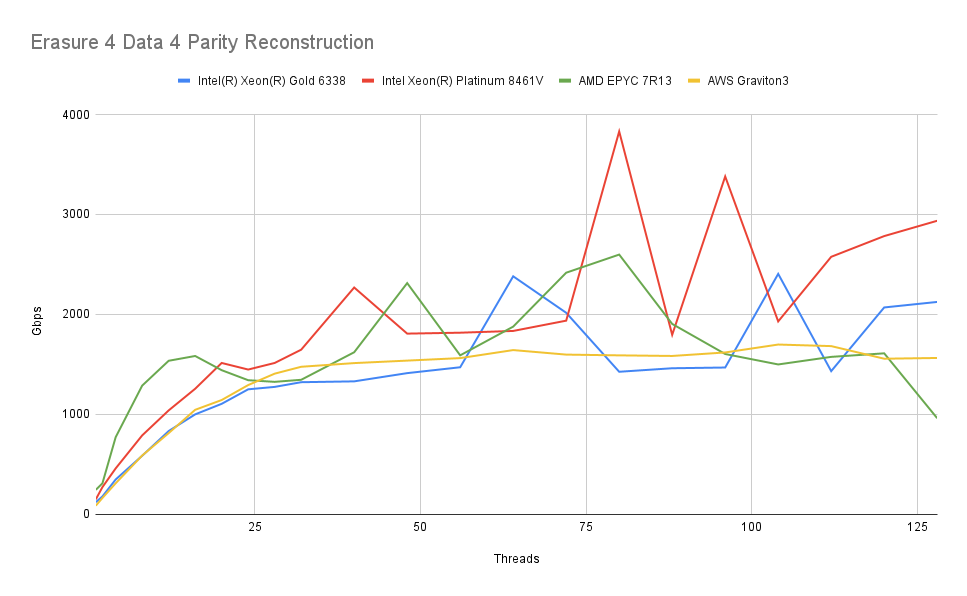
情况仍然类似。同样,读写操作都不会对这些现代 CPU 中的任何一个造成明显的负载。
您可以在 此处 找到完整的测试结果。
分析和结论
通过此测试,我们希望确认在通用硬件上进行擦除编码可以与专用硬件一样快——而无需付出成本或锁定。我们很高兴地确认,即使在顶级 NIC 速度下运行,我们也只会占用所有最流行平台上用于擦除编码的少量 CPU 资源。
这意味着 CPU 可以将资源用于处理 IO 和请求的其他部分,并且我们可以合理地预期,任何外部流处理器处理至少需要等量的资源。
我们很高兴看到英特尔在其最新平台上提高了吞吐量。我们期待测试最新的 AMD 平台,并预计其 AVX512 和 GFNI 支持将进一步提高性能。即使 Graviton 3 的表现稍逊一筹,我们也不认为它会成为一个重要的瓶颈。
有关在任何环境中安装、运行和使用 MinIO 的更多详细信息,请参阅我们的 文档。要详细了解 MinIO 或参与我们的社区,请访问 min.io 或加入我们的 公共 Slack 频道。