使用大型语言模型、Hugging Face 和 MinIO 进行特征提取

简介
在这篇文章中,我将介绍一种每个工程师都应该了解的技术,用于利用开源大型模型。具体来说,我将展示如何进行特征提取。
特征提取是两种使用模型已有的知识来完成与模型最初训练目标不同的任务的方法之一。另一种方法被称为微调——总体而言,特征提取和微调被称为迁移学习。
特征提取已经存在一段时间,它早于使用Transformer架构的模型——比如最近成为头条新闻的大型语言模型。举个具体的例子,假设你已经构建了一个复杂的深度神经网络,用来预测图像中是否包含动物——并且该模型的性能非常好。这个模型可以用来检测在你的花园里吃番茄的动物,而无需对整个模型进行再训练。基本思想是,你创建一个训练集,用来识别偷窃动物(臭鼬和老鼠)和尊重动物。然后,你以与使用原始任务(动物检测)相同的方式将这些图像发送到模型中。但是,你不需要使用模型的输出,而是使用每个图像的最后一层隐藏层的输出,并使用该隐藏层和新的标签作为新模型的输入,来识别偷窃动物和尊重动物。一旦你拥有了一个性能良好的模型,你只需要将它连接到监控系统,就能在你的花园处于危险时发出警报。这种技术对于使用Transformer架构构建的模型特别有用,因为它们很大,训练成本高。下图展示了Transformer的这个过程。
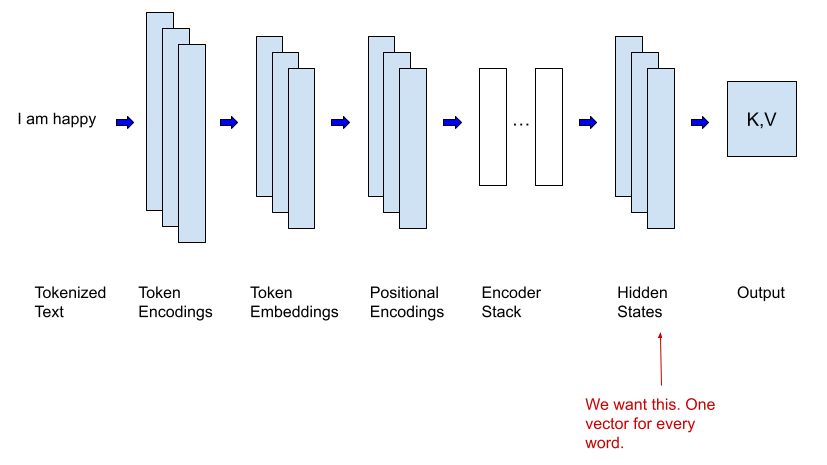
这篇文章中的代码示例将做类似的事情。我将从 Hugging Face Hub 下载一个预先训练好的大型语言模型 (LLM),该模型经过训练用于生成式 AI(作为聊天机器人或总结),并将其用于检测情绪。你可以把它看成是对英语有很多通用知识。我将发送一个包含文本样本的训练集,然后我会使用模型的最后一层隐藏层以及包含文本主要情绪的原始标签(悲伤、喜悦、爱、愤怒、恐惧、惊讶)来训练另一个模型。
让我们快速浏览一下我们将使用的工具,以便使用特征提取来实现迁移学习。
我们将使用的工具
为了完成我们的任务,我们需要以下工具
Hugging Face Hub - Hugging Face 是机器学习的 Github。你可以在 Hub 中找到开源模型。Hugging Face Hub 还包含数千个数据集,你可以用它们来进行实验。我们将使用 distilbert-base-uncased 大型语言模型。对于我们的数据,我们将使用 emotions 数据集,这是一个包含 Twitter (X) 推文集合,这些推文根据它们所表达的情绪进行了分类。以下是在 Hub 中显示有关 distilbert-base-uncased 模型和 emotions 数据集的详细信息的截图。
Hugging Face Transformer 和 Dataset 库 - Hugging Face Transformer 和 Dataset 库分别提供了对 Hugging Face Hub 中的模型和数据集进行编程访问的途径。Transformer 库是用于处理来自 Hugging Face Hub 的模型的高级 API。你使用这个 API 所做的所有事情,都可以使用纯 Python 和你选择的框架(PyTorch、TensorFlow 等)来完成。但是,使用 Hugging Face 库,你将编写更少的代码。此外,这些库对于常见任务有很多有用的函数。例如,Transformer 库有一个属性可以检索在推理完成后模型的最后一个隐藏状态。这个库还提供了分词器,并跟踪为给定模型使用了哪个分词器。
要安装这两个库,请运行以下命令。
用于对象存储的 MinIO - 为了使我们的代码示例更逼真,我们的数据将来自 MinIO 存储桶。Hugging Face Dataset 库可以直接从 Hugging Face Hub 下载数据,但是,在处理企业数据时,使用这个库来访问 Hugging Face Hub 并不现实。一个更好的解决方案是获取存储在 MinIO 存储桶和对象中的数据,并将其放入 Dataset 库的内部结构中。我将在本文中提供一些可重用的实用程序来完成此操作。
我假设你已经在 Docker 容器中运行了 MinIO。如果你想了解如何做到这一点,请查看本文的 MinIO 部分:https://blog.min-io.cn/setting-up-a-development-machine-with-kubeflow-pipelines-2-0-and-minio/。你还需要一个访问令牌才能使用 MinIO SDK。这篇文章还展示了如何获取访问令牌。
要安装 MinIO Python SDK,请运行以下命令。
现在,我们已经对目标和我们将使用的工具有了概念上的理解——让我们开始设置数据集。
Hugging Face 数据集和 MinIO
将数据放入 Hugging Face Dataset 库提供的对象中最简单的方法是,使用 `load_dataset()` 函数和数据集名称直接从 Hub 下载数据。以下代码将下载 emotions 数据集。(本文的完整笔记本可以在 https://github.com/minio/blog-assets/tree/main/feature_extraction?ref=blog.min.io 找到。)
此单元格的输出显示了用于保存使用此函数加载的数据的底层对象的类型。
虽然这是将数据放入数据集的最简单方法,但它要求你将数据上传到 Hugging Face Hub。这可能并不总是可行——尤其是在你的数据包含专有信息或敏感信息的情况下。因此,为了模拟企业场景,我将拆分这个数据集,并为训练集、验证集和测试集创建一个 jsonl 文件。一旦我有了这些文件,我将把它们上传到 MinIO。最后,我将通过连接到 MinIO、下载文件并使用 `load_dataset()` 函数重新加载它们来重新创建数据集。
首先,让我们为将数据传入和传出 MinIO 创建一些辅助函数。这些函数如下所示——它们很简单。`get_object()` 函数将从 MinIO 中检索一个对象,并将其保存为一个文件。`put_file()` 函数将文件上传到 MinIO 中指定的存储桶。如果存储桶不存在,它将被创建。
要创建这些文件并将其上传到 MinIO,请运行以下代码片段。你将为每个集合获得一个文件。支持的其他文件类型有 CSV、Arrow 和 Parquet。
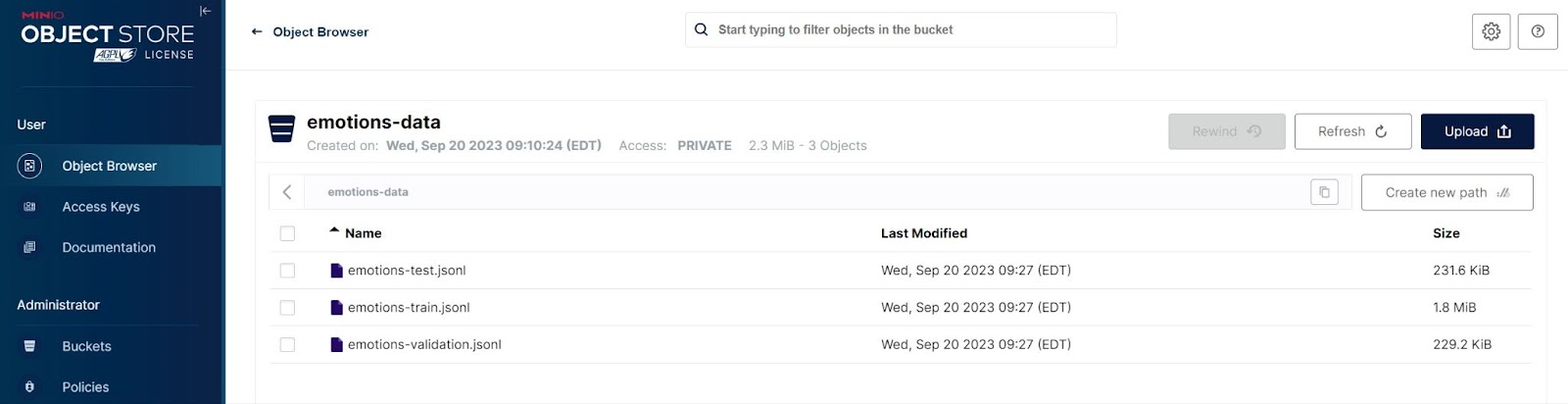
这段代码执行完毕后,你的 MinIO 存储桶中应该会有三个文件。下面是 MinIO 控制台中的截图。
最后,我们可以使用下面的代码从 MinIO 重新加载我们的数据。
现在,我们已经加载了一个包含训练集、验证集和测试集的 emotions DatasetDict 对象。我们可以使用 `column_names` 属性查看列。
输出是
注意:加载到 Dataset 库对象的中的数据可以像加载到 Pandas DataFrame 中的数据一样进行预处理。因此,本节中介绍的技术可以用于将预处理后的数据保存到 MinIO 中,前提是该数据已经处于你训练所需的格式。
现在我们已经准备好从 Hub 加载我们的模型和分词器。
加载模型和分词器
在加载模型和分词器之前,让我们编写一些代码来检测是否存在 GPU。下面的代码将创建一个设备对象,如果存在 GPU,则该对象指向你的 GPU,否则,它指向你的 CPU。
在 Mac 上运行这段代码会产生以下输出。
在拥有 GPU 的机器上,您将获得以下输出。(确保您使用支持 cuda 的 torch 版本。)
现在我们可以创建模型和分词器。Hugging Face Transformers 库使这变得很容易。请注意,模型被移动到我们的设备上。
对数据进行分词
此时,我们拥有数据、模型和分词器。下一步是对文本进行分词。让我们将分词器封装起来,以便可以从映射函数中调用它。
现在分词只需要一行代码。
Hugging Face 的 map() 函数类似于 Python 的 map 函数 - 它对可迭代对象中的每个项目执行指定函数。在本例中,emotions 数据集本质上是一个包含以下键的字典:“train”、“validation” 和“test”。因此,tokenize 函数被调用三次:tokenize(emotions[“train”])、tokenize(emotions[“validation”]) 和 tokenize(emotions[“test”])。
调用 tokenize 函数后,它将为我们的数据添加两列新列。
以及输出
特征提取
在推断过程中深入研究模型以检索最后一个隐藏状态可能听起来很难。实际上,如果我们直接使用 Pytorch 等 ML 框架,这会有点棘手。幸运的是,Hugging Face 使这与从模型本身读取属性一样简单。我们将设置我们的代码,类似于我们设置分词代码的方式。让我们从创建一个将从映射函数中调用的函数开始。
请注意,数据被移动到我们的设备。如果您有 GPU,那么您现在将数据和模型都放在了 GPU 上。这不是一个执行训练的函数。相反,此函数使用模型进行推理,然后读取最后一个隐藏状态,将其移动到 CPU,然后返回。
我们现在可以使用 DatasetDict 的 map 函数。请注意,我们只使用由 tokenizer 创建的字段和原始标签。
再次查看我们的列,我们看到了额外的字段。
迁移学习
我们现在将使用我们在上一节中提取的特征(最后一个隐藏状态)进行迁移学习。为了我们的目的,我们将使用 scikit-learn 中的 LogisticRegression 来训练一个新的、更简单的模型,该模型使用提取的特征。第一步是将我们的数据转换成 Numpy 数组。
我们可以看到,隐藏状态包含了大量信息。每条推文都有一个长度为 768 的向量。
下一步是创建逻辑回归模型并训练它。之后,我们可以使用验证集对模型进行评分。
返回的分数是 0.6335,这意味着模型 63% 的时间预测正确。然而,对像我们这样的分类模型进行评分并不能说明全部情况。让我们进一步分析结果。
分析结果
分析分类任务结果的最佳方法是使用混淆矩阵。下面的代码将创建一个混淆矩阵。下面还显示了我们结果中的混淆矩阵。
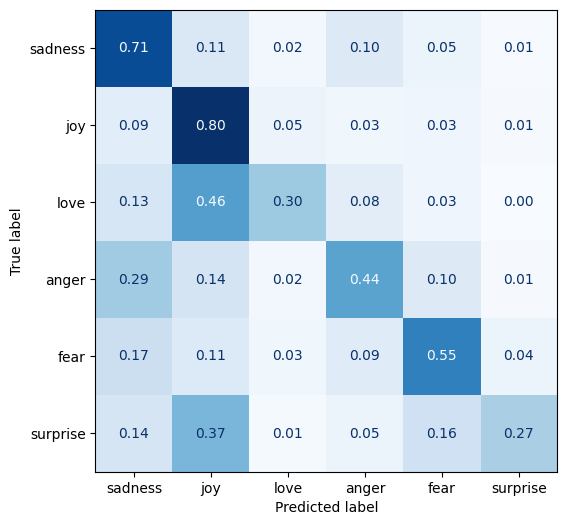
从我们的混淆矩阵中可以看出,结果比分数让我们相信的要好。惊喜经常被预测为快乐。爱也被预测为快乐。最后,愤怒经常与悲伤混淆。这些错误实际上是近乎失误。我们还可以看到,愤怒和爱很少互相混淆。
摘要
在这篇文章中,我们在处理来自 Hugging Face Hub 的模型和数据时,取得了两个重要的结果。
首先,我们创建了可重用的代码,可以用于将数据从 MinIO 获取到 Hugging Face DatasetDict 对象中。这很重要,因为企业数据不能像开源数据集那样从 Hugging Face Hub 上传和下载。组织将希望在 MinIO 中安全地管理重要数据,并拥有将其加载到 Hugging Face 工具中的方法,以便可以轻松地处理数据并将其传递给模型。
我们的第二个成就是下载了一个大型语言模型,将我们的数据通过它运行,并执行特征提取。使用特征提取,您可以利用已在现有模型中训练的知识。无需额外的训练。这代表了希望在其自身数据上为自身任务使用基于 Transformer 的模型的组织的重大成本节约,这些模型训练成本高昂。
此外,应该注意,特征提取不是利用预训练模型的唯一方法。另一种迁移学习技术是微调。微调模型涉及使用少量自定义数据对模型执行额外训练。最后,检索增强生成 (RAG) 对于 NLP 任务(如文档创建、问答和摘要)很有用。RAG 利用自定义语料库中的文本来帮助大型语言模型找到更具体的結果。
如果您有任何问题,请通过 hello@min.io 与我们联系,或加入我们的 通用 Slack 频道 进行讨论。