使用 Hugging Face 和 MinIO 微调大型语言模型

引言
在之前的文章中,我介绍了特征提取,这是一种利用预训练的大语言模型 (LLM) 来解决自定义问题而无需重新训练模型的技术。特征提取是使用模型已有的知识来完成与模型最初训练目的不同的任务的两种方法之一。另一种技术称为微调 - 总体而言,特征提取和微调被称为迁移学习。
在这篇文章中,我将介绍微调。与特征提取一样,它也是一种之前已在深度神经网络中使用过的技术。但是,与特征提取不同,此技术需要训练。让我们来看一个具体的场景,了解微调是如何工作的。假设您有一个 LLM,它是在数千个网站、数千本书和许多文本数据集(如维基百科数据集)上训练的。此模型将拥有大量的通用知识。一个比喻是,此模型类似于一位了解很多不同主题的聪明同事或朋友。不幸的是,此模型(以及您的朋友)无法回答需要对特定主题有详细了解的问题。如果您问模型:“如果您喉咙痛且耳朵痛该怎么办?- 那么您将无法得到好的答案。为了纠正这一点,我们可以使用微调。它的工作原理如下。从您最初经过大量训练的模型开始,然后使用特定于某个领域的數據对其进行更多训练。在我们的例子中,这可能是一个自定义语料库,其中包含讨论疾病、症状和治疗方法的文档。对于使用 Transformer 架构构建的模型,此技术尤其有价值,因为它们规模庞大且训练成本高昂。下图展示了 Transformer 的此过程。
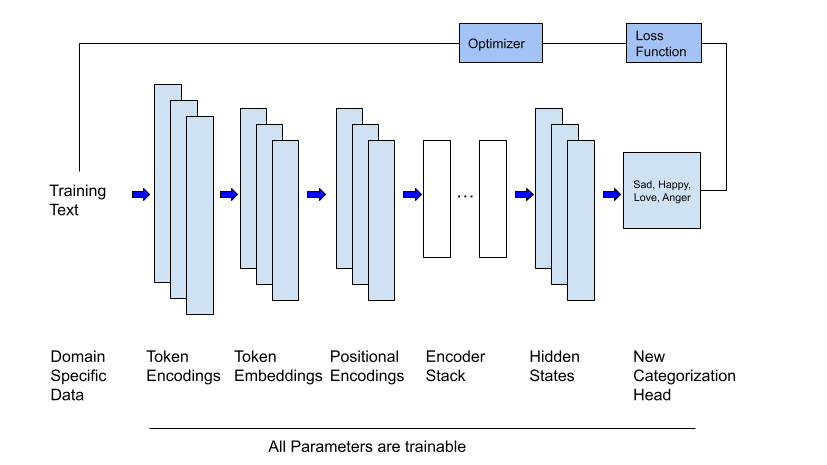
本文中的代码示例将微调我在上一篇文章中使用的相同模型,并尝试解决相同的问题。具体来说,我将从 Hugging Face Hub 下载一个针对生成式 AI(充当聊天机器人或进行摘要)训练的预训练 LLM,并将其用于检测情绪。这将需要稍微修改输出,因为我需要对文本进行分类,并且不需要模型生成文本。(正如我们将看到的,Hugging Face 库使这变得很容易。)然后,我将使用包含带有文本主要情绪标签(悲伤、快乐、爱、愤怒、恐惧、惊讶)的文本样本的训练集重新训练此模型。完成后,我们将拥有一个针对情绪检测进行微调的 LLM。特别有趣的是,我们将能够将结果与特征提取的结果进行比较。
在编写代码之前,让我们快速浏览一下微调大型语言模型所需的工具。
工具
在我的上一篇文章中,我详细介绍了下面列出的工具以及如何安装它们。因此,如果您不熟悉其中任何一个,请转到该文章并快速阅读本节。此外,我在上一篇文章中创建的可重复使用的函数(用于将 MinIO 中的数据获取到 Hugging Face 的 DatasetDict 对象中)将在本文中使用,无需过多解释。(不用担心 - 这些函数很直观,因此无需解释。)
为了完成我们的任务,我们将需要以下工具
Hugging Face Hub
如果您不熟悉Hugging Face,请查看他们的 Hub。浏览不同的模型、数据集和空间。
Hugging Face Transformer 和 Dataset 库
要安装这两个库,请运行以下命令。
用于对象存储的 MinIO
要安装 MinIO Python SDK,请运行以下命令。
现在我们已经对目标和将要使用的工具有了概念上的理解 - 让我们开始设置数据集。
Hugging Face 数据集和 MinIO
Hugging Face Dataset 库具有内置配置,可以直接与 Hugging Face Hub 通信并按名称下载数据集。例如,考虑以下代码,它将直接从 Hugging Face Hub 下载我们将在本文中使用的数据集。
此单元格的输出显示了用于保存数据的底层对象的类型。
让我们快速查看一下列,以便了解特征。
输出为
emotions 数据集有一个特征 - text - 它是推文中提取的文本。label 列是目标 - 它是一个整数,是以下数组的索引。
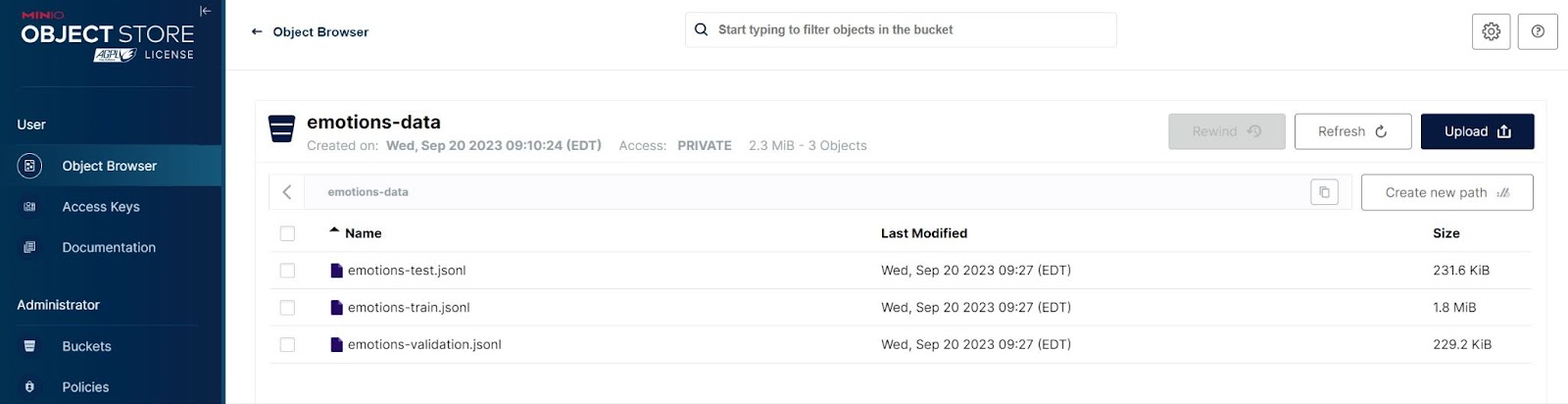
虽然上面使用的 `load_dataset` 函数是将数据加载到数据集的最简单方法,但它要求您将数据上传到 Hugging Face Hub。这可能并非总是可行 - 特别是如果您的数据包含专有或敏感信息。在我的上一篇文章中,我模拟了一个企业场景,将此数据集拆分并为训练集、验证集和测试集创建了一个 JSONL 文件。创建这些文件后,我将它们上传到 MinIO。然后,我通过连接到 MinIO、下载文件并使用 `load_dataset()` 函数重新加载它们来重新创建 DatasetDict 对象。为此,我创建了两个辅助函数 `put_file` 和 `get_object`,分别用于将文件上传和下载到 MinIO。为了简洁起见,我不会在本篇文章中介绍这些辅助函数,但我会将它们包含在代码下载中。下面的代码片段展示了如何使用它们。第一个代码片段拆分 DatasetDict 对象并将每个集合作为单独的对象上传。第二个代码片段下载这些对象并重新创建 DatasetDict 对象。
将数据上传到 MinIO 后,您的 MinIO 存储桶中将包含三个对象。下图显示了 MinIO 控制台的屏幕截图。
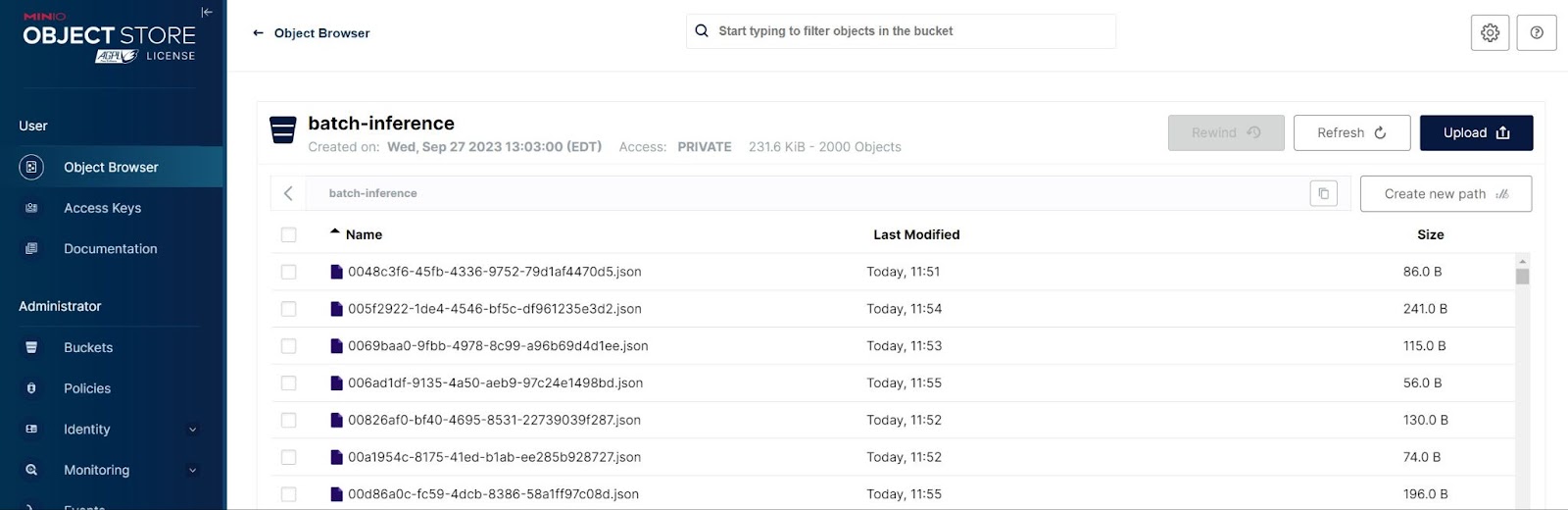
在这篇文章中,我想模拟另一个现实场景。当模型投入生产并用于推理时,数据不会以 CSV、JSON 或 Parquet 文件的形式整齐地打包提供。相反,它将作为一堆小对象交付,其中每个对象代表一个需要预测的样本。因此,让我们拆分测试集并为每条推文创建一个 MinIO 对象。我们将使用这些对象进行批量推理。换句话说,一旦我们拥有一个微调后的模型,我们将获取所有这些单独的对象并获得它们的预测结果。
首先,我们需要创建一个辅助函数,该函数将 JSON 格式的字符串保存为单个对象。以下函数将为我们执行此操作。请特别注意文本是如何编码的,然后在发送到 MinIO 的 `put_object` 方法之前,是如何加载到 Python 的 `io.BytesIO` 类中的。
现在我们可以拆分测试集并将每条推文作为对象发送到 MinIO。下面的代码片段将使用我们的辅助函数填充批处理推理存储桶。
我们得到的输出是
完成后,“batch-inference”存储桶中将有 2000 个对象,如上面上传代码的输出所示。
下图是本文中介绍的实验的完整数据流的可视化。

现在,我们准备从 Hub 加载模型和分词器。
加载模型和分词器
如果您的机器有 GPU,您将希望使用它。以下代码将创建一个设备对象,如果您的机器有 GPU,则该对象指向您的 GPU,否则指向您的 CPU。
现在我们可以创建我们的模型和分词器了。Hugging Face Transformers 库使这变得很容易。请注意,模型被移动到我们的设备上。
这段代码与我们在上一篇文章中进行特征提取时编写的代码非常相似。我们正在加载相同的模型 - “distilbert-base-uncased”,并且我们正在获取为此模型创建的分词器。但是,有一个重要的区别 - 请注意,我们正在使用 `AutoModelForSequenceClassification` 类来获取预训练的模型。此类将分类头添加到现有模型中,因此我们无需自己添加。我们还传递了标签的数量,在本例中为 6 - 我们要检测的每种情绪一个。
在训练模型之前,我们必须不要忘记对推文进行分词。这在下面完成。这与特征提取中使用的技术相同。
现在我们已经准备好微调模型了。
模型微调
在我们使用训练集和验证集重新训练模型之前,我们需要创建一个计算指标的函数,以便了解模型的性能。我们将借用sklearn(也称为scikit-learn)中的几个函数。
接下来,我们需要设置训练参数。这可以通过Transformers库中的`TrainingArguments`类来完成。
现在,我们可以从 Transformer 库的 Trainer 类实例化一个训练器对象,并对模型进行微调。请记住,此模型已经使用大量文本语料库进行了训练,并且对英语语言拥有丰富的知识。我们只是进行一些额外的训练,以便让模型获得一些关于情感的额外知识。
train 方法需要一些时间才能运行,尤其是在使用较旧的机器时。还会生成大量输出,但我们感兴趣的输出是最后一轮 epoch 的结果,它显示了模型在用于验证集时的准确性。
92.4% 的准确率相当不错。对于这个数据集,微调的效果比特征提取更好。在特征提取过程中,我们实现了 63.4% 的准确率——使用特征提取创建的模型对彼此相似的感情(例如愤怒和悲伤)感到困惑。
让我们将此模型应用于放入批量推理 MinIO 存储桶中的数据。
从 MinIO 存储桶进行预测
如前所述,在现实世界中,数据不会以 CSV、JSON 和 Parquet 文件的形式很好地打包。您很可能要处理大量的小对象,其中每个对象代表一个样本——或者在本例中,代表一个调整。我们之前通过在 MinIO 中创建批量推理存储桶来模拟这种情况。下面显示了一个屏幕截图。
以下函数将读取每个对象并创建一个单独的 JSONL 文件。
拥有 JSONL 文件后,我们可以使用它通过 `load_dataset` 函数创建 `DatasetDict` 对象,如下所示。
要使用微调后的模型进行预测,我们使用 `predict` 方法。
结果
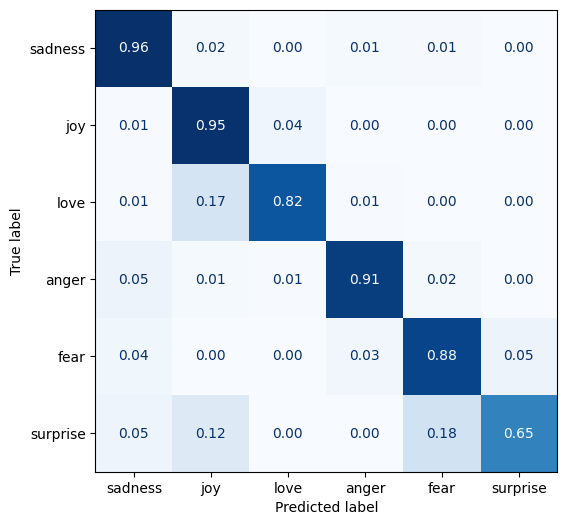
几乎与验证集一样好,准确率为 91.2%。以下是混淆矩阵。(我在上一篇文章中展示了创建此矩阵的代码。)
摘要
使用 Hugging Face 和 MinIO,您可以使用不适合云端的数据微调开源模型。在这篇文章中,我们演示了实现此目的所需的技术。
首先,我们创建了可重用的代码,可用于将数据从 MinIO 获取到 Hugging Face DatasetDict 对象中。这很重要,因为企业数据不能像开源数据集一样从 Hugging Face Hub 上传和下载。组织希望在 MinIO 中安全地管理重要数据,并能够将其加载到 Hugging Face 工具中,以便可以轻松地处理和传递给模型。此外,我们模拟了一种批量推理场景,其中数据没有打包成漂亮的 CSV、Parquet 或 JSON 文件。相反,每个样本都是一个单独的对象。这需要获取 MinIO 存储桶中所有对象的列表,下载每个对象(或样本),并分批将数据传递给我们的模型。
我们的第二个成果是下载了一个大型语言模型,通过添加一个分类头部对其进行了一些修改,然后使用自定义数据对其进行微调。这使我们能够利用已经训练到模型中的知识,同时赋予它额外的信息(在本例中,是关于情绪的信息),以便它可以给出关于特定问题(一段文本表达了哪种情绪)的答案。对于希望使用基于 Transformer 的模型的组织来说,这代表着巨大的成本节省,因为从头开始训练这些模型成本很高,并且可能不具备关于特定领域的详细知识。
此外,需要注意的是,微调不是利用预训练模型的唯一方法。另一种迁移学习技术是特征提取。我在之前的文章中介绍了特征提取。最后,检索增强生成(RAG)对于 NLP 任务(如文档创建、问答和摘要)很有用。RAG 在推理过程中利用自定义语料库中的文本,以帮助大型语言模型找到更具体的答案。RAG 与特征提取一样,不需要额外的训练。
如果您有任何意见或建议,请通过发送邮件至 hello@min.io 或加入我们的 通用 Slack 频道 进行讨论。