企业级生成式 AI

引言
生成式AI代表了企业可以用来解锁其边界内被困数据的最新技术。理解生成式AI可能性的最简单方法是想象一个定制的大型语言模型——类似于为ChatGPT提供动力的模型——在您的防火墙内运行。现在,这个自定义的LLM与OpenAI在公共互联网上托管的模型不同。相反,它获得了关于您业务的“高级教育”。这是通过向其提供外部世界无法访问的大量文档来实现的。但是,这个新工具不是一个传统的搜索引擎,它不会提供一系列链接,让您花费数小时来审查和进一步筛选。相反,它是一个能够生成您需要的内容的解决方案。随着时间的推移,您会发现自己既向它发出指令,也向它提出问题。下面是一些示例,让您了解其可能性。
- “查找我们最近在欧洲股市中的发现。”
- “为我关于生成式AI的演讲创建一个摘要。”
- “查找我们本季度发布的所有内容。”
以上示例是研究场景,但构建良好的大型语言模型(LLM)也可用于客户支持(聊天机器人)、摘要、研究、翻译和文档创建,仅举几例。
这些简单的示例突出了生成式AI的强大功能——它是一种更有效地完成工作的工具,而不是生成阅读清单。
这样的工具无法凭空产生,如果安全和数据质量等问题没有得到考虑,事情可能会变得非常糟糕。此外,为生成式AI提供动力的模型无法在传统的数据中心内运行。它们需要一个现代化的环境,配备现代化的工具来管理非结构化数据(数据湖)、为您的LLM创建AI/ML管道(MLOPs工具)以及允许LLM获得有关您的自定义语料库所需教育的新工具。(我指的是用于实现检索增强生成(RAG)的向量数据库——我将在本文后面进一步解释)。
在这篇文章中,我想从概念层面上介绍企业成功实施生成式AI时应考虑的事项。
让我们从关于数据的对话开始。
数据源(原始数据)
一个重要的区别是,生成式AI所需的数据与传统AI使用的数据不同。数据将是非结构化的——具体来说,您需要的数据将是锁定在SharePoint、Confluence和网络文件共享等工具中的文档。一个好的生成式AI解决方案还可以处理非文本内容,例如音频和视频文件。您将需要一个数据管道来收集所有这些数据并将其集中在一个地方。
这可能是生成式AI计划中最具挑战性的任务。我们都知道Confluence站点和Sharepoint站点在组织内部出现的速度有多快。无法保证其中的文档完整、真实和准确。其他问题包括安全、个人身份信息以及如果文档来自外部来源的许可条款。
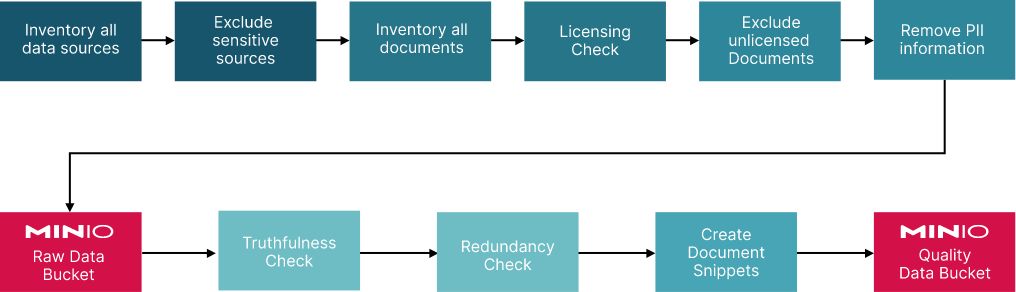
一旦您确定了包含真正信息的文档,您就需要一个放置它们的地方。不幸的是,它们不能保留在原始位置。SharePoint、Confluence和网络文件共享是未设计用于快速为训练和推理提供服务的工具。这就是MinIO发挥作用的地方。您需要将文档存储在具有您习惯的所有功能的存储解决方案中:按需扩展、大规模性能、可靠、容错以及云原生接口。最重要的是,您需要构建一个数据管道,该管道聚合来自多个来源的原始数据,然后将其转换为LLM可消费的格式。下图显示了组织中可能存在的各种来源以及应该进行的高级检查。

让我们通过深入了解将原始数据转换为高质量数据所需的安全性检查和质量检查来更仔细地研究数据管道。
数据预处理(高质量数据)
组织应首先对所有文档来源进行清单。对于每个文档来源,应对找到的所有文档进行编目。应根据许可和安全对文档进行审查。某些文档可能需要从您的解决方案中排除。此过程的重要部分是识别需要在包含在生成式AI解决方案中之前进行修改的受限数据。
在审查文档的安全性和许可后,接下来是质量检查。例如,真实性、多样性(如果它们是关于人的)和冗余性。如果没有高质量的数据,就无法创建准确的模型。这对于传统的AI(监督学习、无监督学习和强化学习)是正确的——对于生成式AI尤其如此。质量较低的文档、冗余的文档以及包含不准确数据的文档将稀释LLM的响应,甚至会导致幻觉。
更详细的管道的可视化如下所示
关于存储解决方案重要性的一些想法:您的高质量文档需要位于一个存储解决方案中,该解决方案可以快速为训练、微调和推理提供数据服务。工程师可以运行的实验越多,模型最终的性能就越好。您还希望跟踪实验、保存处理后的数据以及对模型进行版本控制。这可以通过手动将此信息直接保存到MinIO或使用您选择的MLOP工具来完成。许多MLOP工具在后台使用对象存储。例如,来自DataBricks的MLFlow和来自Google的KubeFlow都使用MinIO。此外,上图中所示的MinIO实例应来自现代数据湖的实现。现代数据湖是能够支持AI的系统架构的中心。
让我们继续讨论LLM如何使用包含高质量文档的对象存储。
LLM如何使用高质量数据
在本节中,我们将介绍两种使用开源LLM和高质量文档生成特定领域内容的方法。这两种技术是微调和检索增强生成(RAG)。
微调开源模型
当我们微调模型时,我们使用自定义信息对其进行更多训练。这可能是获得特定领域LLM的一种好方法。虽然此选项确实需要计算才能针对自定义语料库执行微调,但它不像从头开始训练模型那样密集,并且可以在适度的时间范围内完成。
如果您的领域包含日常使用中找不到的术语,则微调将提高LLM响应的质量。例如,将使用医学研究、环境研究以及与自然科学相关的任何内容的文档的项目将受益于微调。微调采用文档中发现的高度特定的术语,并将它们烘焙到模型的参数参数中。
缺点
- 微调将需要计算资源。
- 无法解释。
- 随着语料库的发展,您将需要定期使用新数据重新微调。
- 幻觉是一个问题。
优点
- LLM通过微调了解了来自自定义语料库的知识。
- 与RAG相比,更快的价值实现时间。
虽然微调是教LLM了解您业务语言的一种好方法,但它会稀释数据,因为大多数LLM包含数十亿个参数,而您的数据将分布在所有这些参数中。
让我们看看一种在推理时结合自定义数据和参数数据的方法。
检索增强生成(RAG)
检索增强生成(RAG)是一种从提出的问题开始的技术——将其与其他数据结合起来,然后将问题和数据传递给LLM和向量数据库以创建内容。使用RAG,不需要训练,因为我们通过向其发送来自高质量文档语料库的相关文本片段来教育LLM。
它的工作原理如下,使用问答任务:用户在应用程序的用户界面中提出问题。您的应用程序将获取问题——具体来说是其中的文字——并使用向量数据库搜索您高质量文档的语料库中上下文相关的文本片段。这些片段以及原始问题将发送到大型语言模型 (LLM)。整个包——问题加上片段(上下文)被称为提示。LLM 将使用此信息生成您的答案。这可能看起来像一件愚蠢的事情——如果您已经知道答案(片段),为什么要费心使用 LLM 呢?好吧——请记住——这是实时发生的,目标是生成文本——您可以复制粘贴到您的研究中的内容。您需要 LLM 来创建包含自定义语料库信息的文本。
这比微调更复杂。您可能听说过向量数据库——它们是寻找问题的最佳上下文时的关键组件。设置向量数据库可能很棘手。如果您需要一个简单的临时解决方案,您可以使用像 Elastic Search 这样的文本搜索工具。但是,向量数据库更好,因为它们可以学习单词的语义含义并提取使用不同单词但具有相同或相似含义的上下文。
缺点
- 需要向量数据库。
- 与微调相比,价值实现时间更长。(由于向量数据库和在向 LLM 发送请求之前所需的预处理。)
优点
- LLM 直接拥有来自您自定义语料库的知识。
- 可解释性是可能的。
- 不需要微调。
- 幻觉显著减少,可以通过检查向量数据库查询的结果来控制。
摘要
任何愿意进行适当规划的企业都可以实现生成式 AI 的成功。
像所有 AI 一样,生成式 AI 从数据开始。大型语言模型(为生成式 AI 提供支持)所需的数据是定义您防火墙内独特知识的自定义语料库。不要将自己限制在基于文本的文档上。可以利用培训视频、录制会议以及音频和视频格式的录制事件。构建数据管道并不容易,必须注意维护安全性和许可,同时确保质量。
开源模型消除了设计模型的复杂性,并且由于大多数模型都是预训练的,因此它们还消除了初始训练的高成本。组织应尝试微调,以查看它是否可以提高生成内容的质量。
最后,检索增强生成 (RAG) 是一种强大的技术,可用于将组织自定义文档语料库中的知识与 LLM 的参数知识相结合。与微调不同,来自您语料库的信息不会被训练到模型的参数参数中。相反,相关片段在推理时被定位并作为上下文传递给模型。
后续步骤
生成式 AI 是一项新技术,新技术需要基础设施更新。对于认真对待生成式 AI 的组织来说,下一步是创建包含 AI/ML 管道、数据管道、现代数据湖 和向量数据库(如果要使用 RAG)的系统架构。在这篇文章中,我从高层次介绍了这些技术。
敬请关注此博客,以获取有关生成式 AI 系统架构的更详细说明。如果您有任何疑问,请发送邮件至 hello@min.io 或加入Slack 社区。