打破 HDFS 速度障碍 - 对象存储的首次突破
很少有人会反驳Hadoop HDFS正在衰落的说法。事实上,Hadoop生态系统中的HDFS不仅在衰落,它正在自由落体。在其诞生之初,它作为一个高吞吐量、容错的分布式文件系统发挥了重要的作用。其秘诀在于数据局部性。
通过将计算和数据共置在相同的节点上,HDFS克服了访问数据的网络速度慢的局限性。然而,其影响在目前已经众所周知。通过将数据和计算共置,每增加一个存储节点,就必须增加一个计算节点。鉴于数据增长速度远远超过了对计算增长的需求,因此导致了巨大的失衡。计算节点处于闲置状态。多家分析公司报告称,对于较大的实例,客户的CPU利用率仅为个位数。
HDFS的局限性和复制方案进一步加剧了这种情况。Hadoop供应商将每个数据节点的容量限制为最大100 TB,并且只支持4 TB或8 TB容量的驱动器。例如,为了存储10 PB的数据,需要30 PB的物理存储空间(3倍复制)。这将需要至少300个存储节点和300个计算节点。
不用说,这是非常低效的。
解决这个问题的方法是将存储和计算解耦,以便它们可以独立扩展。对象存储利用更密集的存储服务器,例如Cisco UCS S3260存储服务器或Seagate Exos AP 4U100。这些盒子可以容纳每台服务器超过1 PB的可使用容量,以及100 GbE网卡。另一方面,计算节点针对MEM和GPU密集型工作负载进行了优化。这种架构非常适合云原生基础设施,其中软件堆栈和数据管道通过Kubernetes弹性地管理。
虽然云原生基础设施更具可扩展性且更易于管理,但这只是故事的一部分——就像成本只是故事的一部分一样。另一部分是性能。
HDFS能够生存下来的原因之一是,竞争架构无法在规模上提供其性能。
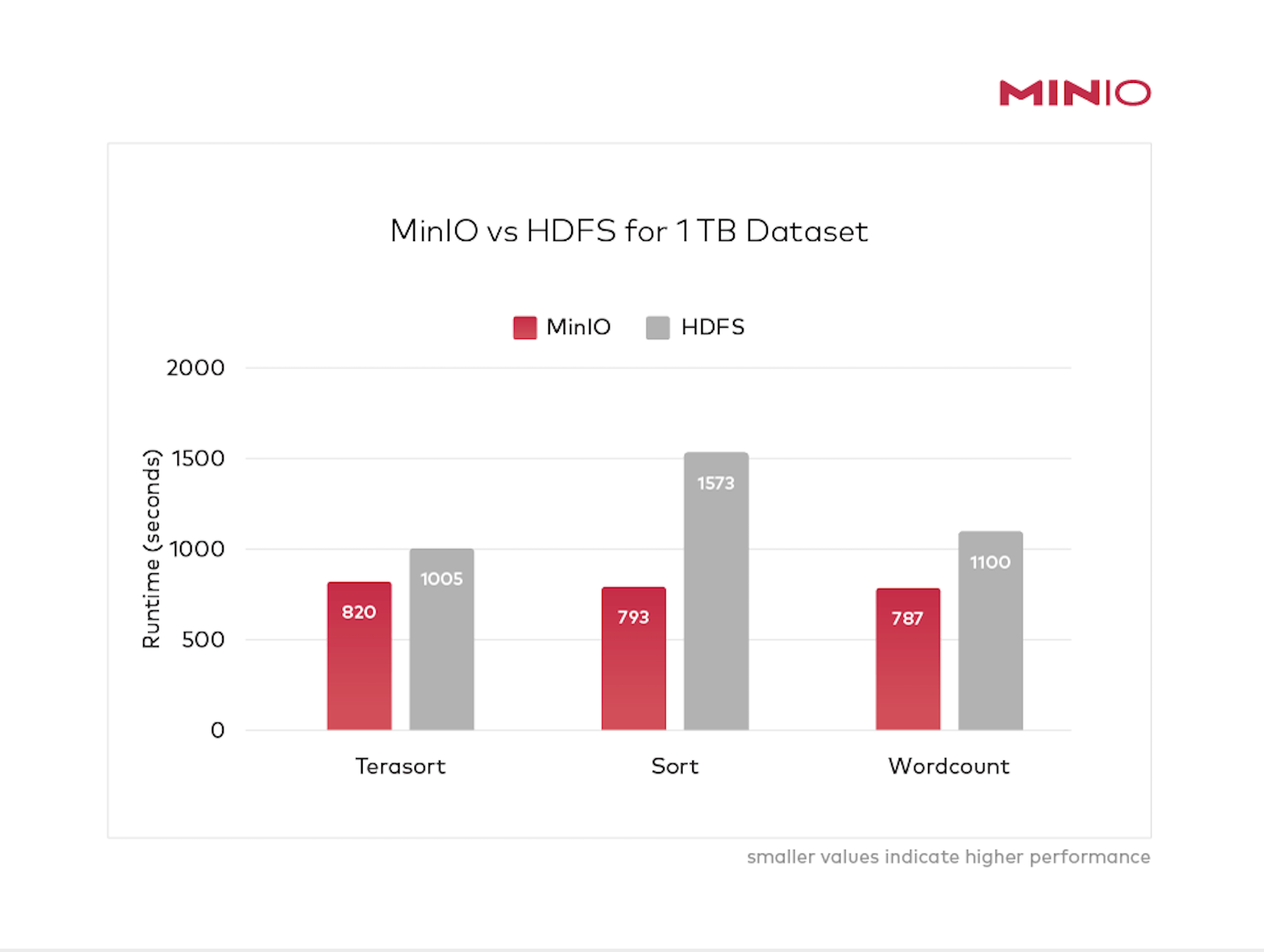
现在情况不再如此。现代云原生对象存储打破了人们对性能方面的可能性的认知。本文通过比较Hadoop HDFS和MinIO使用最成熟的Hadoop基准测试的性能来证明这一点:Terasort、Sort和Wordcount。结果表明,对象存储在性能方面与HDFS相当,并为解耦的Hadoop架构提供了强有力的论据。

使这种比较有趣和有意义的是,MinIO和HDFS都在其原生环境(分别为解耦和耦合)中运行。
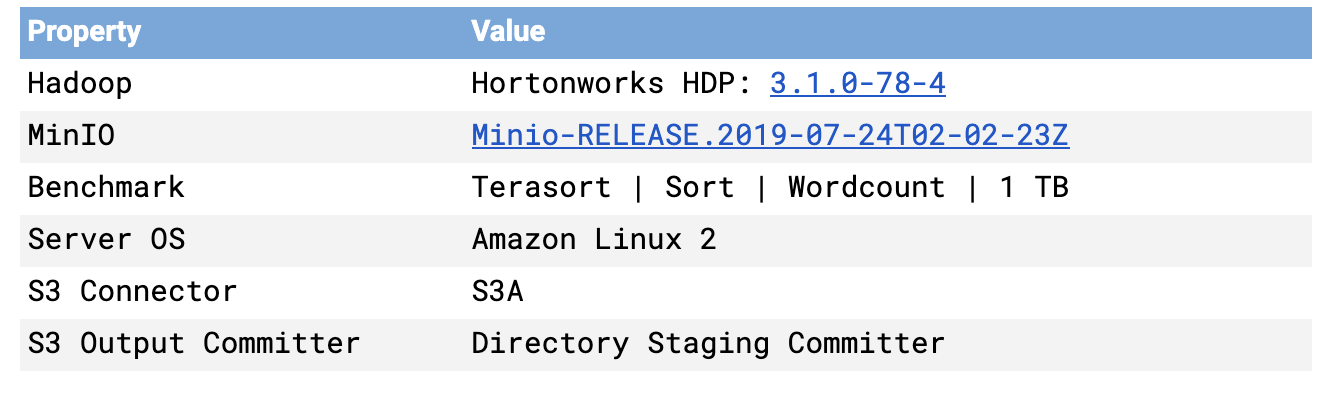
MinIO基准测试是在AWS裸机存储优化实例(h1.16xlarge)上进行的,该实例使用本地硬盘驱动器和25 GbE网络。计算作业在计算优化实例(c5d.18xlarge)上运行,通过25GbE网络连接到存储。


MinIO的解耦存储和计算架构
HDFS基准测试是在AWS裸机实例(h1.16xlarge)上进行的,该实例使用本地硬盘驱动器和25 GbE网络。HDFS上的MapReduce具有数据局部性的优势,并且内存容量是MinIO的两倍(2.4 TB)。


Hadoop HDFS的共置存储和计算架构
每个软件的版本如下
HDFS实例需要大量的调整——有关其详细内容,请参阅完整的基准测试文件。
详细讨论了S3A提交器的使用,以及对Netflix的目录暂存提交器和分区暂存提交器的评估,因为它们不需要重命名操作。还评估了Magic提交器。
发现目录暂存提交器是三者中最快的,它被用于基准测试。
基准测试分为两个阶段:数据生成和基准测试。
在数据生成阶段,为相应的基准测试生成数据。即使此步骤不是性能关键的,但仍对其进行评估以评估MinIO和HDFS之间的差异。

请注意,为Sort基准测试生成的数据可用于Wordcount,反之亦然。
在Terasort的情况下,HDFS生成步骤的执行速度比MinIO快2.1倍。在Sort和Wordcount的情况下,HDFS生成步骤的执行速度比MinIO快1.9倍。
在生成阶段,S3暂存提交器处于劣势,因为提交器将数据暂存在RAM或磁盘中,然后上传到MinIO。在HDFS和S3A Magic提交器的情况下,不存在暂存惩罚。
尽管在生成阶段处于劣势,但其他基准测试结果强烈地偏向于MinIO的解耦方法。


这些结果在多个方面意义重大。
首先,这远远超出了人们通常认为的对象存储的性能能力。这个行业的特点是廉价且深度存档和备份存储,其品牌名称如Glacier。比Hadoop更快的性能闻所未闻。
其次,这彻底改变了大规模高级分析的经济性。Hadoop的TCO挑战众所周知,但有了MinIO,价格/性能曲线完全不同。成本部分是Hadoop的一小部分,人员成本是Hadoop的一小部分,复杂性是Hadoop的一小部分,而性能则是其几倍。对于大多数企业来说,在性能方面接近就足以让他们迁移到解耦的架构——而这更多,远远更多。
第三,现代对象存储是,嗯,现代的。它具有现代API(Amazon S3),它是在一个拥有容器和编排以及最佳微服务的世界中设计的。这个由微服务、Kubernetes和容器组成的世界是一个充满活力、不断发展壮大的生态系统——与不断缩小的Hadoop生态系统相去甚远。这意味着对于那些乘坐云原生列车的人来说,未来和创新就在眼前。
应该指出的是,这也为对象存储领域的传统设备供应商划了一条线。云原生不在他们的DNA中。他们卡在了低速档。
那么是什么让MinIO如此快呢?有五个主要因素
- 我们只提供对象。我们从头开始构建平台,以解决这一问题,并比任何人都做得更好。我们没有将对象附加到文件或块架构上。多层会导致复杂性。复杂性会导致延迟。
- 我们不使用元数据数据库。对象和元数据在单个原子操作中一起写入。其他方法有多个步骤,而多个步骤会导致延迟。
- 我们采用SIMD(单指令多数据)加速。通过使用汇编语言(SIMD扩展)编写MinIO的核心部分,我们可以在普通硬件上实现超高速。
- 我们结合使用Go和汇编语言,通过针对任务进行优化,以提供类似C语言的性能。
- 我们坚持不懈地追求简单性。结果是,诸如内联擦除码、位腐烂保护、加密、压缩、严格一致性和同步I/O之类的功能从性能角度来看微不足道。
最终的结果是企业使用对象存储的方式发生了转变。他们不再仅仅将其视为旧数据的目的地,而是将其视为高级分析、Spark、Presto、Tensorflow等应用程序的热层。
与往常一样,我们鼓励讨论。请发送邮件至hello@min.io或在Twitter上关注@minio,加入讨论。