使用 MinIO 构建对话式 AI 聊天机器人


聊天机器人已成为人工智能最普遍的元素之一,它们也是人类(有意或无意地)与之交互的人工智能类型。 核心是自然语言处理 (NLP),这是人工智能领域中一个更广泛的研究领域,涉及机器理解语言的能力,包括文本和人类的口语。
NLP 的目标是让计算机能够进行完整对话,包括上下文、语气、情感和意图。
聊天机器人在过去几年中发展迅速,部分原因是疫情推动了远程工作和远程互动。与所有人工智能系统一样,学习是应用程序结构的一部分,聊天机器人可用的数据语料库已经产生了出色的性能—对有些人来说,这是一种令人不安的好。
聊天机器人的一个优势是它们被打包成应用程序,因此可以嵌入到网站和/或电话号码中,集成到商业应用程序和支付系统以及 CRM 系统中。
聊天机器人的另一个优势是,企业身份服务、支付服务和通知服务可以安全可靠地集成到消息系统中。这提高了客户需求的整体可支持性,以及重新建立与非活跃或断开连接的用户之间的连接以重新参与的能力。
不同类型的聊天机器人
有一个优秀学术文章由 Eleni Adamopoulou 和 Lefteris Moussiades 概述了不同类型的聊天机器人及其用途。我们在下面对其进行了概括,但鼓励读者阅读整篇文章,因为它涵盖了一些基础构建模块。
- 知识领域(开放):开放域聊天机器人可以谈论一般主题并做出适当的响应。
- 知识领域(封闭): 封闭域聊天机器人专注于特定知识领域,可能无法回答其他问题.
- 服务提供商:服务提供商考虑聊天机器人用户的感情距离以及发生的亲密互动量。
- 人际/人际关系:这些聊天机器人可以处于个人领域或沟通领域,通常被认为是友好的。
- 信息性: 这些聊天机器人是从事先存储的静态固定数据源构建的。
- 基于聊天的/对话式的:基于聊天的/对话式聊天机器人与用户对话,就像另一个真人一样,他们的目标是对给定的句子做出正确的响应。
- 基于任务的: 基于任务的聊天机器人执行特定任务,例如预订航班或帮助某人。这些聊天机器人在要求信息和理解用户输入方面很智能,它们使用规则和 NLP。
聊天机器人架构模型
同样,以 Eleni Adamopoulou 和 Lefteris Moussiades 的著作为来源,我们发现他们将架构分解如下。我们同意他们的分类,因此我们在下面重新创建了它。
- 基于规则的模型
- 固定预定义的规则集
- 识别输入文本的词法形式
- 人工手工编码的知识
- 基于检索的模型
- 查询随着时间推移收集的知识库
- 使用 API 分析可用资源
- 从索引中检索潜在的响应,并应用匹配以找到适当的答案
- 生成模型
- 更像人一样;根据之前的知识生成答案
- 应用机器学习算法和深度学习技术
- 取决于如何构建和训练机器学习模型
我们对使用生成模型来实现现代对话式人工智能聊天机器人感兴趣。让我们看一下聊天机器人的总体架构,并进一步扩展以使 NLP 能够改进知识库。
一般聊天机器人设计和架构
我们的方法将遵循使用构建模块的一般公认最佳实践。这与扩展 MinIO 的方式一致。对于我们的聊天机器人设计,我们希望创建模块化,以便 a) 准确的知识表示 b) 开发答案的策略 c) 当机器不理解时,预先确定的响应。
通常,这些架构基于基于检索的模型
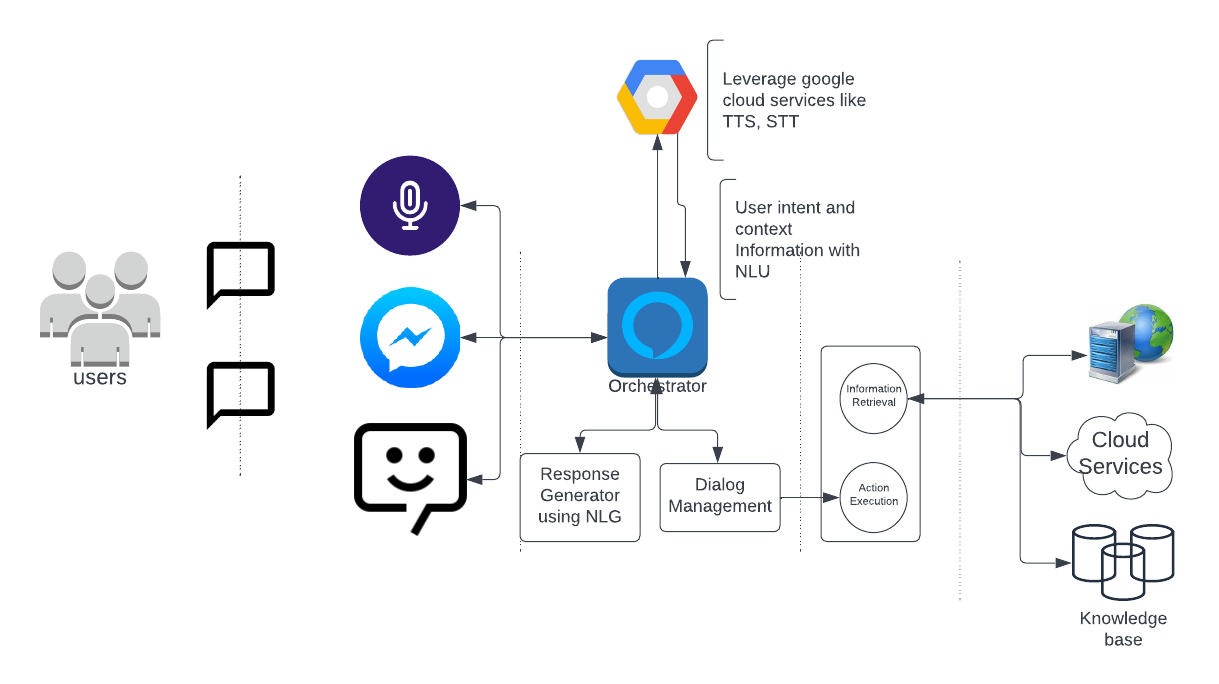
如果我们采用识别上图中组成部分的方法,除了用户界面之外,我们还需要构建用户消息分析,以进行语言理解并确定消息的上下文,并进行确认。我们还需要一个对话管理器,它可以在分析后的消息和后端系统之间进行接口,以执行用户发出的给定消息的操作。对话管理器还会与对用户有意义的响应生成进行接口。操作执行模块可以与知识库被整理和存储的数据源进行接口。
使用 MinIO 的对话式人工智能聊天机器人架构
随着人工智能/机器学习的出现,简单的基于检索的模型不足以支持企业的聊天机器人。为了构建对话式人工智能聊天机器人,需要将架构发展成生成模型。通过将 NLP、NLU 和 NLG 相结合,为您的业务应用程序添加类人对话功能已成为一种必要性。这些接口不断发展,并且正成为用户与企业沟通的首选方式之一。
随着最近的 Covid-19 大流行,对话式人工智能接口的采用已加速。企业被迫开发接口以通过新方式与用户互动,收集所需的用户资料,并集成后端服务以完成所需的任务。
在虚拟助手方面,公共云服务提供商一直处于对话式人工智能创新的前沿。文本到语音和语音到文本框架的创新以及与 NLP/NLU 框架的集成,使企业能够构建高效的聊天机器人和语音体验,提高用户满意度,降低运营成本,简化业务流程,同时加快上市时间。
然而,随着数据通常分布在公共云、私有云和本地位置,多云策略已成为一项优先事项。Kubernetes 和 Docker 化在软件交付方面为各处部署铺平了道路,无论位置如何。MinIO 通过采用这些进步将存储提升到了一个新的高度。启用复制的 MinIO 集群现在可以将知识库带到计算存在的地方。至于计算,我们可以使用 NLP 和 NLU 在知识库上应用人工智能原则,并不断改进要通过电话、虚拟助手和机器人来消费和传递给客户查询的内容。通过集成 Kubeflow 和 Kale 管道,后台的数据分析师和科学家可以在基于用户习惯捕获的数据上实现持续学习的人工智能模型,并优化响应和内容以有效地为前端组件提供服务。
这里描述的这种生成模型的一个例子利用 Google 文本到语音 (TTS) 和语音到文本 (STT) 框架来创建对话式人工智能聊天机器人。后端系统被 MinIO 取代,将数据直接摄取到 MinIO 中。随着 NLU 记录用户习惯,用户数据也与知识库一起在 MinIO 中变得可用,以便进行后台分析和机器学习模型实施。有关如何配置 Kubeflow 和 MinIO 的更多信息,请关注此博客。
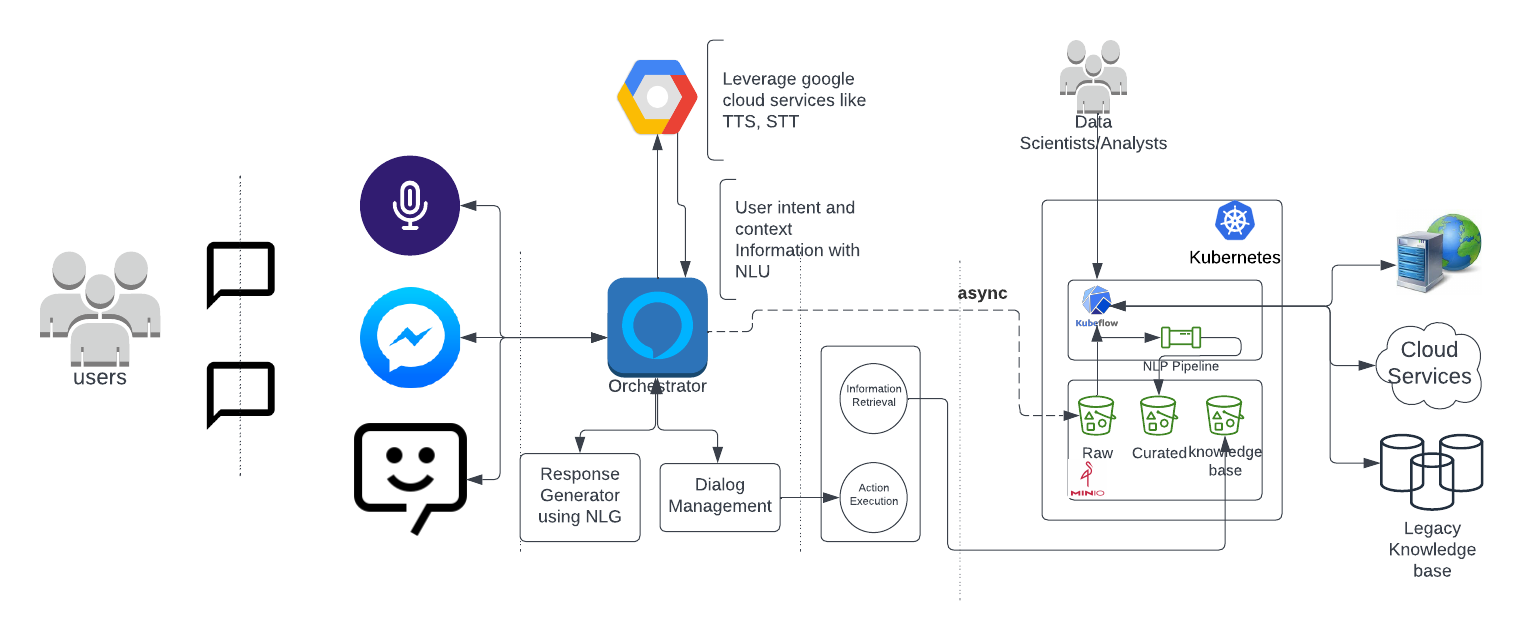
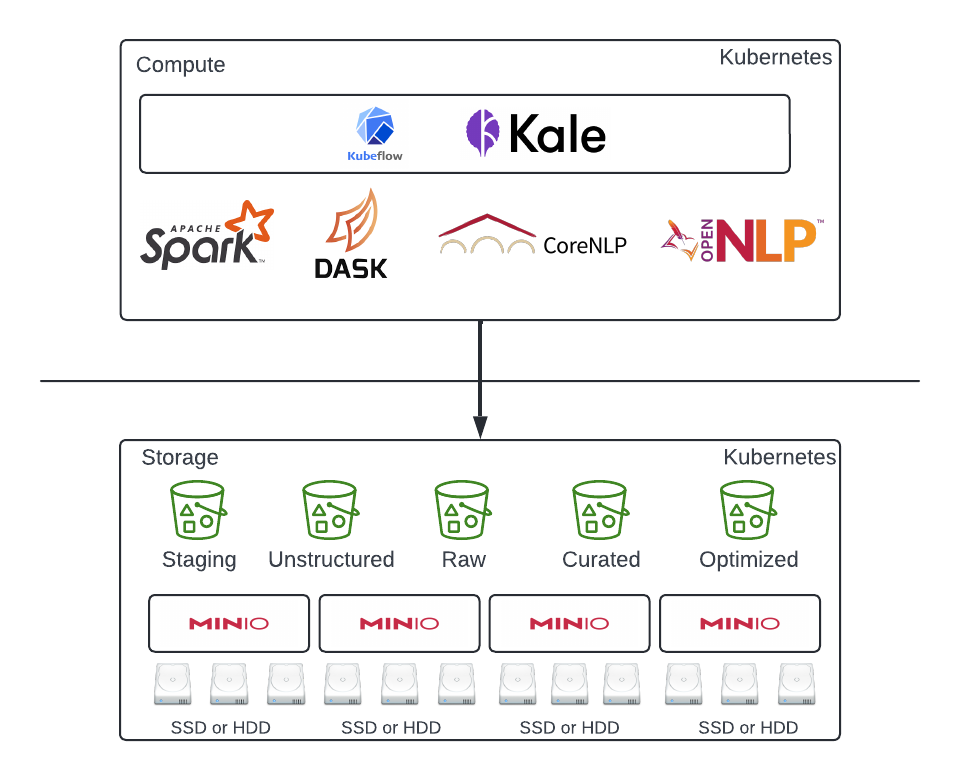
放大使用 MinIO 的架构,我们可以利用 Apache OpenNLP 等开源 NLP 项目Apache OpenNLP和斯坦福的 CoreNLP包在 MinIO 中通过用户活动捕获的数据集上执行 NLU 和 NLP。您可以利用第三方数据集来丰富和增强知识库,以根据业务需求不断学习和优化。然后,构建您的 NLP 管道,处理文本处理步骤,例如清理、规范化、标记化、停用词去除、命名实体识别和词干提取和词形还原。处理完成后并将数据存储在整理好的存储桶中,这意味着您拥有一个简化的词袋模型表示,忽略语法甚至词序,但保留多重性,我们可以使用来自现有和新知识库的可用数据不断训练模型。让 MinIO 处理底层存储并为您管理,如下所示
结论
艾伦·图灵说过:“我相信,在本世纪末,语言的使用和一般受过教育的意见将发生如此大的变化,以至于人们可以谈论机器思考,而不会期望遭到反驳。” 凭借今天的人工智能/机器学习,我们可以不断改进用户与对话式人工智能交互的预期结果,并且不会遭到反驳。
让开源软件帮助您简化企业对话式人工智能需求,让 MinIO 处理存储解决方案,以实现持续学习并优化知识库,从而改善聊天机器人体验。