使用 MinIO 和 TensorFlow 进行超大规模机器学习
 发表于 集成
发表于 集成 
我们正处于一个由信息和人工智能定义的转型时代。每天都会生成和收集海量数据,以供这些贪婪的、最先进的 AI/ML 算法使用。数据越多,结果越好。
作为行业领先标准之一的框架是 谷歌的 TensorFlow。它用途广泛,用户可以快速入门并使用其 Keras 框架编写简单的模型。如果您寻求更高级的方法,TensorFlow 还允许您使用低级 API 构建自己的机器学习模型。无论您选择哪种策略,TensorFlow 都将确保您的算法针对您为算法选择的任何基础设施进行优化——无论是 CPU、GPU 还是 TPU。
随着数据集变得太大而无法放入内存或本地磁盘,AI/ML 管道现在需要从外部数据源加载数据。以 ImageNet 数据集为例,它包含 1400 万张图像,估计存储大小为 1.31TB。此数据集无法放入内存,也无法放入任何机器的本地存储驱动器中。如果您的管道在无状态环境(例如 Kubernetes,这正变得越来越普遍)中运行,则这些挑战会变得更加复杂。
解决此问题的兴起标准是在 AI/ML 管道的设计中使用高性能对象存储。MinIO 是该领域的领导者,并发布了许多证明其吞吐量能力的基准测试。在这篇文章中,我们将介绍如何将 MinIO 用于您的 TensorFlow 项目。
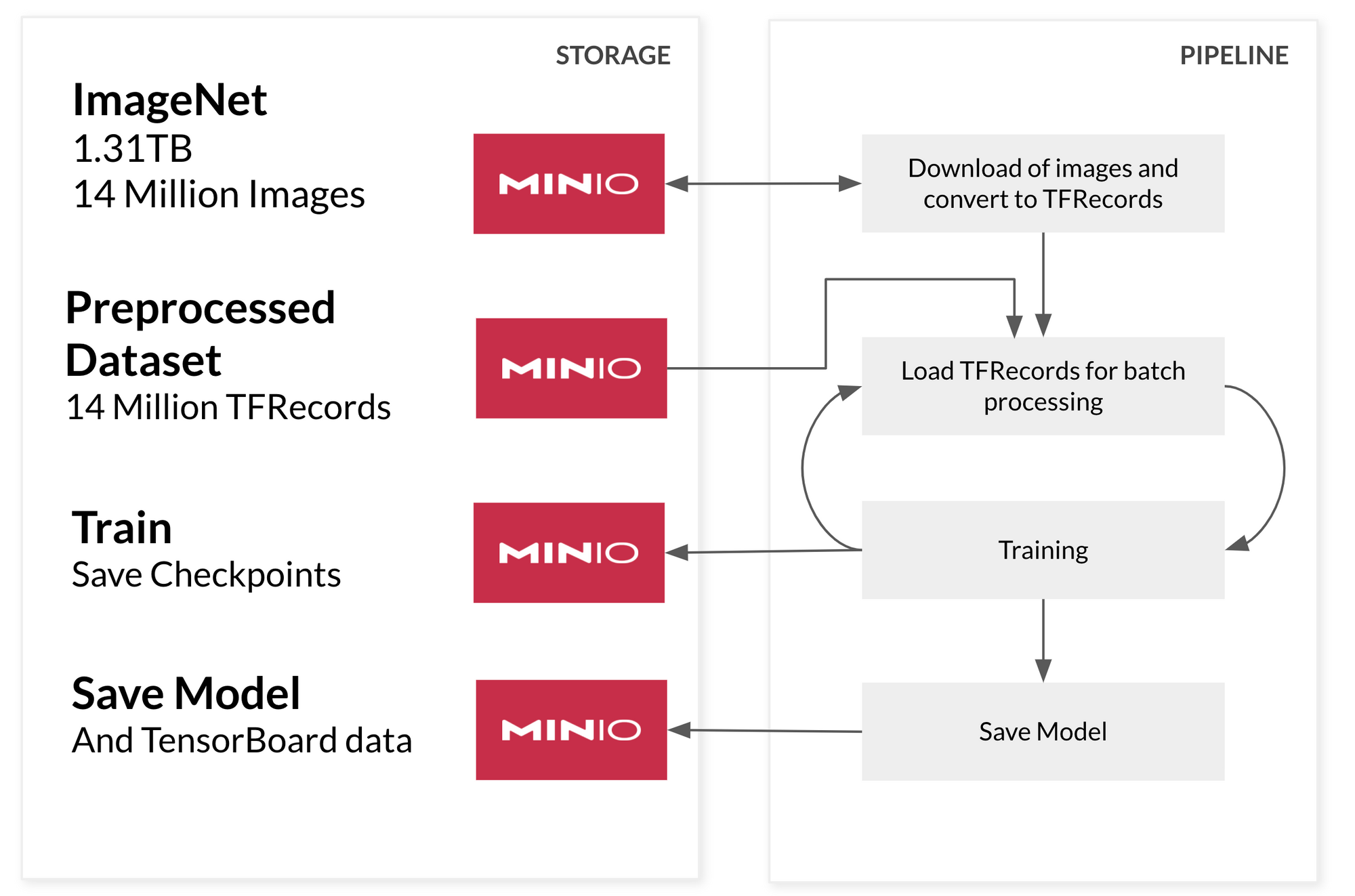
四阶段超大规模数据管道
为了构建一个超大规模的管道,我们将让管道的每个阶段都从 MinIO 读取数据。在本例中,我们将构建机器学习管道四个阶段。此架构将按需从 MinIO 加载所需数据。
首先,我们将预处理我们的数据集并将其编码为 TensorFlow 可以快速处理的格式。此格式是 tf.TFRecord,它是我们数据的二进制编码类型。我们采取此步骤是因为我们不想在训练期间浪费时间处理数据,因为我们计划在需要时直接从 MinIO 加载每一批训练数据。如果在将数据馈送到模型训练之前对其进行预处理,我们可以节省大量时间。理想情况下,我们创建预处理的数据块,将大量记录分组在一起——至少 100-200MB 大小。
为了加快数据加载和训练阶段的速度,我们将利用优秀的 tf.data API。此 API 旨在在模型的训练/验证期间有效地加载数据。它在模型正在处理当前批次数据时准备下一批数据。这种方法的优势在于,它确保了对昂贵的 GPU 或 TPU 的有效利用,这些 GPU 或 TPU 由于数据加载缓慢而不能闲置。MinIO 不会遇到此问题——它可以使用几个 NVMe 驱动器使 100Gbps 网络饱和,或者也可以 使用硬盘驱动器,确保管道能够以硬件允许的最快速度处理数据。
在训练期间,我们希望确保存储模型的训练检查点以及 TensorBoard 直方图。如果训练被打断并且我们想要恢复训练,或者如果我们获得更多数据并希望使用新数据和 TensorBoard 直方图继续训练我们的模型,则检查点很有用,让我们了解训练是如何进行的。TensorFlow 支持将这两者直接写入 MinIO。
一个小小的旁注。当模型完成后,我们也将将其保存到 MinIO——允许我们使用 TensorFlow Serving 提供服务——但这将是以后的文章内容。
构建管道
对于我们的超大规模管道,我们将使用一个可以轻松放入您本地计算机中的数据集,以便您可以一起学习。来自斯坦福大学的 大型电影评论数据集 非常棒,因为它有大量的样本(25,000 个用于训练,25,000 个用于测试),所以我们将构建一个 情感分析模型,它将告诉我们电影评论是 正面 还是 负面。请记住,每个步骤都可以应用于任何更大的数据集。此数据集的优势在于您可以在自己的计算机上尝试。让我们开始吧!
使用 MinIO 客户端 下载数据集并将其上传到 MinIO。
curl -O http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
mc mb myminio/datasets
mc cp aclImdb_v1.tar.gz myminio/datasets/让我们首先声明管道的一些配置,例如 批次大小、数据集的位置以及固定的 随机种子,以便我们可以一次又一次地运行此管道并获得相同的结果。
random_seed = 44
batch_size = 128
datasets_bucket = 'datasets'
preprocessed_data_folder = 'preprocessed-data'
tf_record_file_size = 500
# Set the random seed
tf.random.set_seed(random_seed)
# How to access MinIO
minio_address = 'localhost:9000'
minio_access_key = 'minioadmin'
minio_secret_key = 'minioadmin'我们将使用 minio-py 从 MinIO 下载我们的数据集。
minioClient = Minio(minio_address,
access_key=minio_access_key,
secret_key=minio_secret_key,
secure=False)
try:
minioClient.fget_object(
datasets_bucket,
'aclImdb_v1.tar.gz',
'/tmp/dataset.tar.gz')
except ResponseError as err:
print(err)现在让我们将数据集解压缩到一个临时文件夹 (/tmp/dataset) 中以预处理我们的数据。
extract_folder = f'/tmp/{datasets_bucket}/'
with tarfile.open("/tmp/dataset.tar.gz", "r:gz") as tar:
tar.extractall(path=extract_folder)预处理
由于数据集的结构,我们将从四个文件夹读取数据,最初是 test 和 train,每个文件夹都包含 25,000 个示例,然后,在每个文件夹中,我们都有 12,500 个每个标签 pos 用于正面评论和 neg 用于负面评论。从这四个文件夹中,我们将把所有样本存储到两个变量中,train 和 test。如果我们正在预处理一个无法放入本地机器的数据集,我们可以简单地一次加载一个对象的部分,并对其进行处理。
train = []
test = []
dirs_to_read = [
'aclImdb/train/pos',
'aclImdb/train/neg',
'aclImdb/test/pos',
'aclImdb/test/neg',
]
for dir_name in dirs_to_read:
parts = dir_name.split("/")
dataset = parts[1]
label = parts[2]
for filename in os.listdir(os.path.join(extract_folder,dir_name)):
with open(os.path.join(extract_folder,dir_name,filename),'r') as f:
content = f.read()
if dataset == "train":
train.append({
"text":content,
"label":label
})
elif dataset == "test":
test.append({
"text":content,
"label":label
})然后,我们将对数据集进行随机排序,这样我们就不会通过提供 12,500 个连续的正面示例,然后是 12,500 个连续的负面示例来引入训练偏差。我们的模型很难泛化这一点。通过对数据进行随机排序,模型将能够同时看到和学习正面和负面示例。
random.Random(random_seed).shuffle(train)
random.Random(random_seed).shuffle(test)由于我们正在处理文本,因此我们需要将文本转换为准确描述句子含义的向量表示。如果我们正在处理图像,我们会调整图像大小并将它们转换为向量表示,每个像素都是调整大小后的图像的值。
但是,对于文本,我们面临更大的挑战,因为单词并没有真正的数字表示。这就是 嵌入 有用之处。嵌入是某些文本的向量表示,在本例中,我们将整个评论表示为 512 维的单个向量。与其手动进行文本预处理(标记化、构建词汇表和训练嵌入层),我们将利用一个名为 USE(通用句子编码器) 的现有模型将句子编码为向量,以便我们可以继续我们的示例。这是深度学习的奇迹之一,能够在您的模型旁边重用不同的模型。这里我们使用 TensorFlow Hub,并将加载最新的 USE 模型。
import tensorflow_hub as hub
embed = hub.load("https://tfhub.dev/google/universal-sentence-encoder-large/5")由于创建 25,000 个句子的嵌入并将其保留在内存中会占用太多资源,因此我们将数据集切分为 500 个块。
要将我们的数据存储到 TFRecord 中,我们需要将特征编码为 tf.train.Feature。我们将数据的标签存储为 tf.int64 列表,并将电影评论存储为浮点数列表,因为在使用 USE 编码句子后,我们将得到 512 维的嵌入。
def _embedded_sentence_feature(value):
return tf.train.Feature(float_list=tf.train.FloatList(value=value))
def _label_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
def encode_label(label):
if label == "pos":
return tf.constant([1,0])
elif label == "neg":
return tf.constant([0,1])
# This will take the label and the embedded sentence and encode it as a tf.TFRecord
def serialize_example(label, sentence_tensor):
feature = {
'sentence': _embedded_sentence_feature(sentence_tensor[0]),
'label': _label_feature(label),
}
example_proto = tf.train.Example(features=tf.train.Features(feature=feature))
return example_proto
def process_examples(records,prefix=""):
starttime = timeit.default_timer()
total_training = len(records)
print(f"Total of {total_training} elements")
total_batches = math.floor(total_training / tf_record_file_size)
if total_training % tf_record_file_size != 0:
total_batches += 1
print(f"Total of {total_batches} files of {tf_record_file_size} records")
counter = 0
file_counter = 0
buffer = []
file_list = []
for i in range(len(records)):
counter += 1
sentence_embedding = embed([records[i]['text']])
label_encoded = encode_label(records[i]['label'])
record = serialize_example(label_encoded, sentence_embedding)
buffer.append(record)
if counter >= tf_record_file_size:
print(f"Records in buffer {len(buffer)}")
# save this buffer of examples as a file to MinIO
counter = 0
file_counter+=1
file_name = f"{prefix}_file{file_counter}.tfrecord"
with open(file_name,'w+') as f:
with tf.io.TFRecordWriter(f.name,options="GZIP") as writer:
for example in buffer:
writer.write(example.SerializeToString())
try:
minioClient.fput_object(datasets_bucket, f"{preprocessed_data_folder}/{file_name}", file_name)
except ResponseError as err:
print(err)
file_list.append(file_name)
os.remove(file_name)
buffer=[]
print(f"Done with chunk {file_counter}/{total_batches} - {timeit.default_timer() - starttime}")
if len(buffer) > 0:
file_counter+=1
file_name = f"file{file_counter}.tfrecord"
with open(file_name,'w+') as f:
with tf.io.TFRecordWriter(f.name) as writer:
for example in buffer:
writer.write(example.SerializeToString())
try:
minioClient.fput_object(datasets_bucket, f"{preprocessed_data_folder}/{file_name}", file_name)
except ResponseError as err:
print(err)
file_list.append(file_name)
os.remove(file_name)
buffer=[]
print("Total time preprocessing is :", timeit.default_timer() - starttime)
return file_list
process_examples(train,prefix="train")
process_examples(test,prefix="test")
print("Done Preprocessing data!")至此,我们完成了数据的预处理。我们有一组存储在我们的存储桶中的 .tfrecord 文件。现在,我们将将其馈送到模型,使其能够并发地使用和训练。
训练
我们将从 MinIO 获取文件列表(训练数据)。从技术上讲,预处理阶段和训练阶段可以完全解耦,因此列出我们在存储桶中拥有的文件块是个好主意。
# List all training tfrecord files
objects = minioClient.list_objects_v2(datasets_bucket, prefix=f"{preprocessed_data_folder}/train")
training_files_list = []
for obj in objects:
training_files_list.append(obj.object_name)
# List all testing tfrecord files
objects = minioClient.list_objects_v2(datasets_bucket, prefix=f"{preprocessed_data_folder}/test")
testing_files_list = []
for obj in objects:
testing_files_list.append(obj.object_name)为了让 TensorFlow 连接到 MinIO,我们将告诉它 MinIO 实例的位置和连接详细信息。
os.environ['AWS_ACCESS_KEY_ID'] = minio_access_key
os.environ['AWS_SECRET_ACCESS_KEY'] = minio_secret_key
os.environ['AWS_REGION'] = "us-east-1"
os.environ['S3_ENDPOINT'] = minio_address
os.environ['S3_USE_HTTPS'] = "0"
os.environ['S3_VERIFY_SSL'] = "0"
现在让我们创建一个tf.data.Dataset,它会在需要时从 MinIO 上的文件加载记录。为此,我们将获取我们拥有的文件列表,并以引用实际对象位置的方式对其进行格式化。我们也将对测试数据集执行此操作。
all_training_filenames = [f"s3://datasets/{f}" for f in training_files_list]
testing_filenames = [f"s3://datasets/{f}" for f in testing_files_list]以下步骤是可选的,但我建议您这样做。我将把我的训练数据集分成两个集合,90% 的数据用于训练,10% 的数据用于验证,模型不会在验证数据上学习,但它将有助于模型更好地训练。
total_train_data_files = math.floor(len(all_training_filenames)*0.9)
if total_train_data_files == len(all_training_filenames):
total_train_data_files -= 1
training_files = all_training_filenames[0:total_train_data_files]
validation_files = all_training_filenames[total_train_data_files:]现在让我们创建tf.data数据集
AUTO = tf.data.experimental.AUTOTUNE
ignore_order = tf.data.Options()
ignore_order.experimental_deterministic = False
dataset = tf.data.TFRecordDataset(training_files,num_parallel_reads=AUTO,compression_type="GZIP")
dataset = dataset.with_options(ignore_order)
validation = tf.data.TFRecordDataset(validation_files,num_parallel_reads=AUTO,compression_type="GZIP")
validation = validation.with_options(ignore_order)
testing_dataset = tf.data.TFRecordDataset(testing_filenames,num_parallel_reads=AUTO,compression_type="GZIP")
testing_dataset = testing_dataset.with_options(ignore_order)为了解码我们TFRecord编码的文件,我们将需要一个解码函数,该函数执行与我们的serialize_example函数完全相反的操作。由于来自TFRecord的数据分别具有(512,)和(2,)的形状,因此我们也将对其进行重塑,因为这是我们的模型期望接收的格式。
def decode_fn(record_bytes):
schema = {
"label": tf.io.FixedLenFeature([2], dtype=tf.int64),
"sentence": tf.io.FixedLenFeature([512], dtype=tf.float32),
}
tf_example = tf.io.parse_single_example(record_bytes,schema)
new_shape = tf.reshape(tf_example['sentence'],[1,512])
label = tf.reshape(tf_example['label'],[1,2])
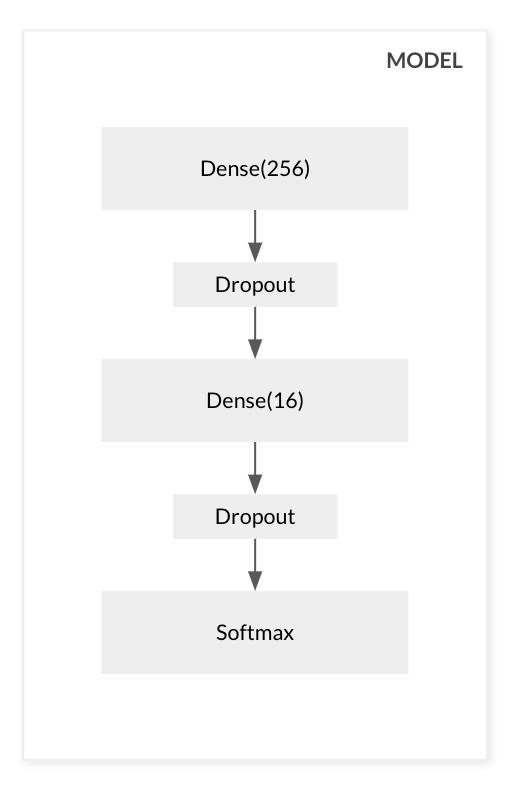
return new_shape,label让我们构建我们的模型,没什么特别的,我将使用几个密集层,并在最后使用softmax激活函数。我们试图预测输入是positive还是negative,因此我们将获得每个概率的可能性。
model = keras.Sequential()
model.add(
keras.layers.Dense(
units=256,
input_shape=(1,512 ),
activation='relu'
)
)
model.add(
keras.layers.Dropout(rate=0.5)
)
model.add(
keras.layers.Dense(
units=16,
activation='relu'
)
)
model.add(
keras.layers.Dropout(rate=0.5)
)
model.add(keras.layers.Dense(2, activation='softmax'))
model.compile(
loss='categorical_crossentropy',
optimizer=keras.optimizers.Adam(0.001),
metrics=['accuracy']
)
让我们通过让数据集重复几次并在每次迭代中批处理128个项目来为训练阶段准备我们的数据集。
mapped_ds = dataset.map(decode_fn)
mapped_ds = mapped_ds.repeat(5)
mapped_ds = mapped_ds.batch(128)
mapped_validation = validation.map(decode_fn)
mapped_validation = mapped_validation.repeat(5)
mapped_validation = mapped_validation.batch(128)
testing_mapped_ds = testing_dataset.map(decode_fn)
testing_mapped_ds = testing_mapped_ds.repeat(5)
testing_mapped_ds = testing_mapped_ds.batch(128)在训练过程中,我们希望存储模型的检查点,以防训练中断,并且我们希望从中断的地方继续。为此,我们将使用 Keras 回调tf.keras.callbacks.ModelCheckpoint让 TensorFlow 在每个 epoch 后将检查点保存到MinIO。
checkpoint_path = f"s3://{datasets_bucket}/checkpoints/cp.ckpt"
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path,
save_weights_only=True,
verbose=1)我们还想保存TensorBoard直方图,因此我们将添加一个回调来将它们存储在我们的存储桶中,位于logs/imdb/前缀下。我们使用model_note和当前时间来识别此运行,以便我们可以区分训练的不同实例。
model_note="256-input"
logdir = f"s3://{datasets_bucket}/logs/imdb/{model_note}-" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=logdir)最后,我们将训练模型
history = model.fit(
mapped_ds,
epochs=10,
callbacks=[cp_callback, tensorboard_callback],
validation_data=mapped_validation
)如果我们运行mc admin trace myminio,我们可以看到TensorFlow直接从 MinIO 读取数据,但仅读取它需要的那部分。

现在我们有了模型,我们想将其保存到 MinIO
model.save(f"s3://{datasets_bucket}/imdb_sentiment_analysis") 让我们测试我们的模型并查看它的性能
testing = model.evaluate(testing_mapped_ds)这返回了 85.63% 的准确率,虽然不是最先进的,但对于这样一个简单的例子来说也不错。
让我们运行TensorBoard来探索我们的模型,直接从 MinIO 加载数据。
AWS_ACCESS_KEY_ID=minioadmin AWS_SECRET_ACCESS_KEY=minioadmin AWS_REGION=us-east-1 S3_ENDPOINT=localhost:9000 S3_USE_HTTPS=0 S3_VERIFY_SSL=0 tensorboard --logdir s3://datasets/logs然后在浏览器中访问https://:6006
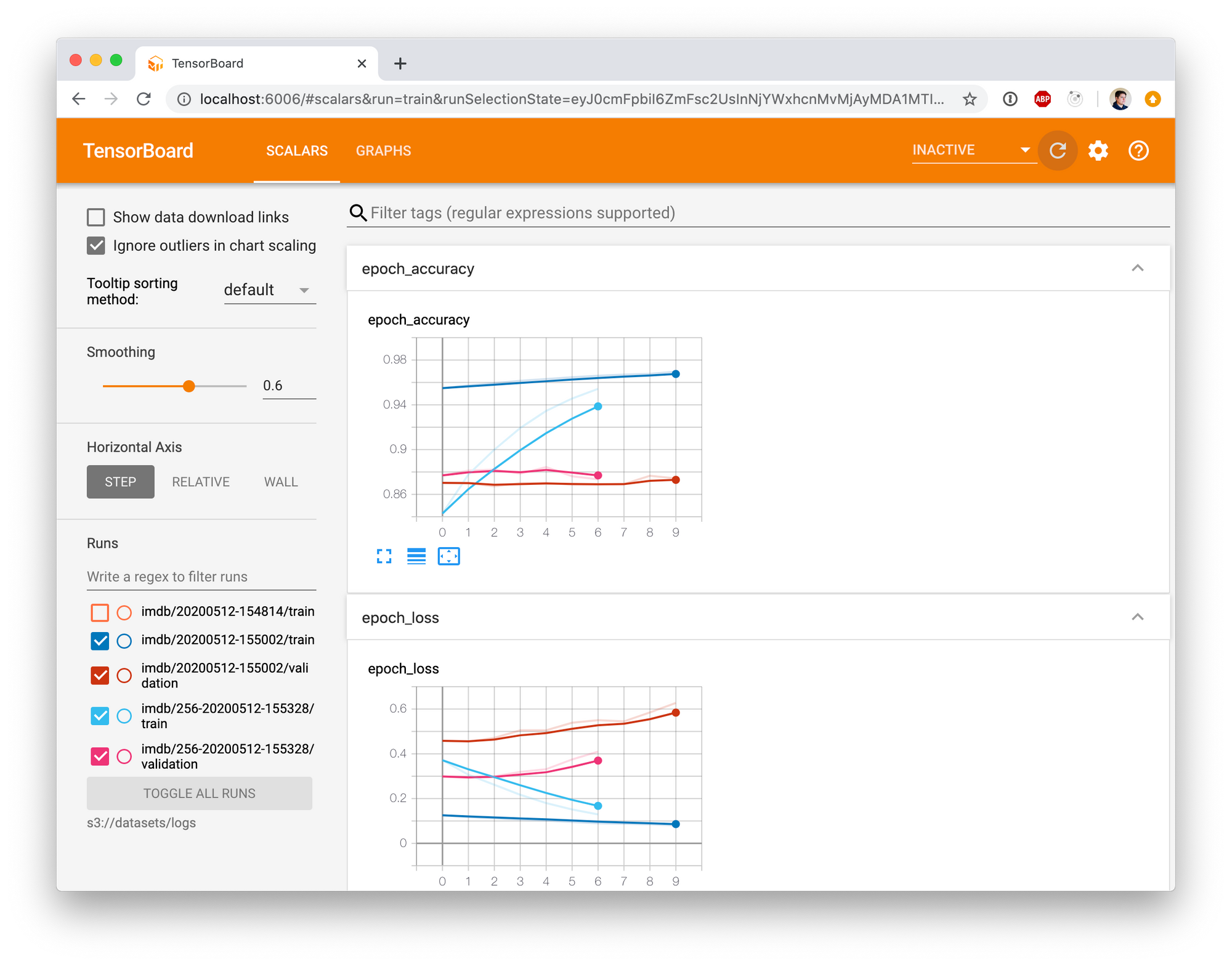
我们可以使用我们的模型并查看它是否有效
samples = [
"This movie sucks",
"This was extremely good, I loved it.",
"great acting",
"terrible acting",
"pure kahoot",
"This is not a good movie",
]
sample_embedded = embed(samples)
res = model.predict(sample_embedded)
for s in range(len(samples)):
if res[s][0] > res[s][1]:
print(f"{samples[s]} - positive")
else:
print(f"{samples[s]} - negative")这将返回以下输出
This movie sucks - negative
This was extremely good, I loved it. - positive
great acting - positive
terrible acting - negative
pure kahoot - positive
This is not a good movie - negative结论
如已证明,您可以构建完全依赖于 MinIO 的大规模 AI/ML 管道。这是 MinIO 的性能特性以及它能够无缝扩展到 PB 和 EB 级数据的功能的结果。通过分离存储和计算,您可以构建一个不依赖于本地资源的框架,从而允许您在 Kubernetes 内部的容器中运行它们。这增加了相当大的灵活性。
您可以看到 TensorFlow 如何能够根据需要加载数据,并且根本不需要任何自定义,它只是起作用了。此外,这种方法可以通过运行分布式 TensorFlow来快速扩展到训练阶段。这确保了在训练节点之间几乎没有数据需要在网络上进行混洗,因为 MinIO 成为该数据的唯一来源。
此帖子的代码可在 Github 上获取:https://github.com/dvaldivia/hyper-scale-tensorflow-with-minio