如果您正在使用大型语言模型 (LLM) 实现生成式 AI 解决方案,您应该考虑使用检索增强生成 (RAG) 的策略为您的 LLM 构建上下文感知提示。在 RAG 支持的 LLM 的预生产管道中,一个重要的过程是将文档文本进行分块,以便只有文档中最相关的部分与用户查询匹配并发送到 LLM 以进行内容生成。这就是 Open-Parse 可以提供帮助的地方。Open-Parse 超越了简单的文本分割,确保类似的文本不会被分割成两个独立的块。在本篇文章中,我将展示如何从 MinIO 存储桶中获取原始形式的文档,使用 Open-Parse 将其分块,然后将它们保存到另一个存储桶,该存储桶可用于为向量数据库提供数据。包含本篇文章中展示的所有代码的 Jupyter 笔记本可以从 这里 找到。
在介绍 Open-Parse 处理文档的功能之前,让我们先看看 RAG 推理管道。请特别注意文档块是如何被用来提高 LLM 在生成对用户查询的响应时的性能。
RAG 推理管道
下面的图表显示了 RAG 推理管道。它还显示了文档处理管道,将在后面的部分中讨论。
检索增强生成 (RAG) 是一种技术,它从用户请求(通常是问题)开始,使用向量数据库将请求与附加数据配对,然后将请求和数据传递给 LLM 以进行内容创建。使用 RAG,不需要训练,因为我们通过向 LLM 发送来自自定义文档语料库的相关文本块来对它进行教育。这在下图中显示。它使用问答任务来实现,如下所示:用户在应用程序的用户界面中提出问题。您的应用程序将获取该问题(具体来说是其中的词语),并使用向量数据库搜索与上下文相关的文本块。这些块和原始问题将被发送到 LLM。这个完整的包——问题加上块(上下文)被称为提示。LLM 将使用此信息来生成答案。这似乎是一件很愚蠢的事情——如果您已经知道答案(片段),为什么要费心使用 LLM 呢?请记住,这是实时发生的,目标是生成文本——您可以复制粘贴到您的研究中。您需要 LLM 来创建包含来自您的自定义语料库的信息的文本。使用 RAG,可以实现用户授权,因为文档(或文档片段)是在推理时从向量数据库中选择的。文档中的信息永远不会成为模型参数参数的一部分。RAG 的主要优势如下所示。
优势
- LLM 拥有来自您的自定义语料库的直接知识。
- 可解释性是可能的。
- 不需要微调。
- 幻觉被显著减少,并且可以通过检查向量数据库查询的结果来控制。
- 可以实现文档级授权。

文档处理管道
显然,RAG 的一个重要部分是文档处理,它发生在将您的文档通过嵌入模型并将其嵌入保存到向量数据库之前。如果您有复杂文档(以二进制格式,例如 PDF)则这并非易事。例如,文档通常包含表格、图形、注释、涂黑文本以及对其他文档的引用。此外,LLM 对您可以与原始查询一起发送的上下文的长度有限制。因此,发送整个文档不是一种选择。即使您可以发送整个文档,这可能也不会产生最佳结果。来自多个文档的片段集合可能是特定用户查询的最佳上下文。为了解决这个问题,许多解析库会根据所需的块长度来分割文档。一种蛮力方法是简单地使用块长度来分割文本。一个更好的方法是在句子或段落边界上分割,同时仍然保持块在限制范围内。虽然这更好,但它可能会将章节标题放在自己的块中,并破坏表格,将它们分割成多个块。
Open-Parse 是一个用于分割 PDF 文件的开源库,它超越了简单的文本分割。它旨在灵活且易于使用。它通过分析布局并根据简单的启发式算法(将相关文本保留在同一个块中)来创建块来对文档进行分块。下面是显示 Open-Parse 逻辑的流程图。注意:文本节点将转换为 Markdown,而表格节点将转换为 HTML。
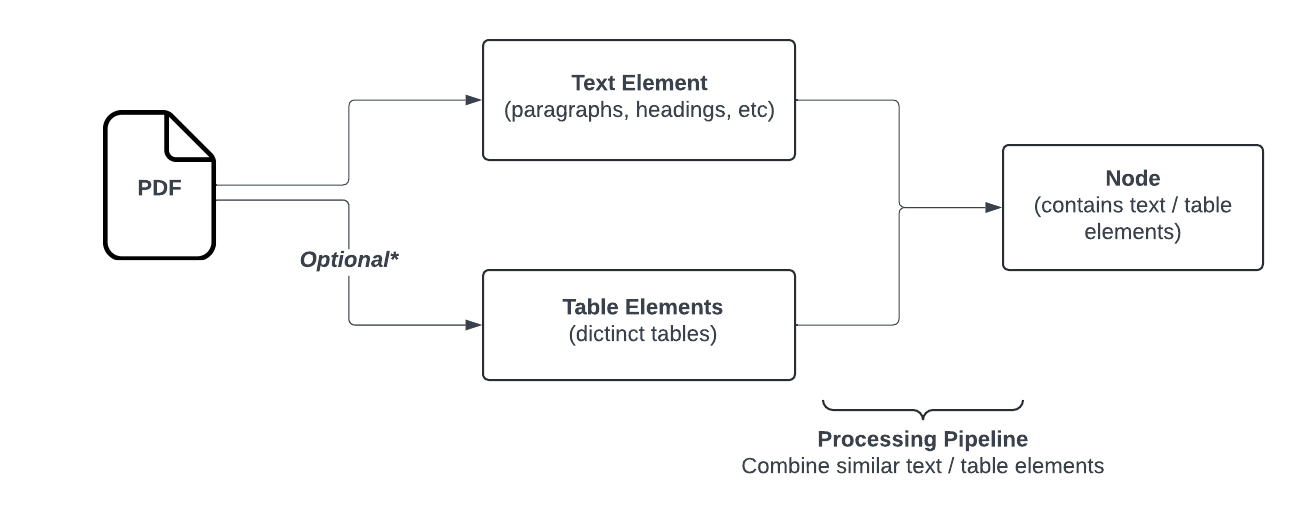
来源:https://filimoa.github.io/open-parse/processing/overview/
让我们看几个简单的例子,看看这到底意味着什么。
使用 Open-Parse 对文档进行分块
在生产环境中,您将需要将原始 PDF 和分块对象存储在能够实现性能和可扩展性的存储解决方案中。这就是 MinIO 的作用。本部分中的代码假设您已设置了两个存储桶,如下所示。
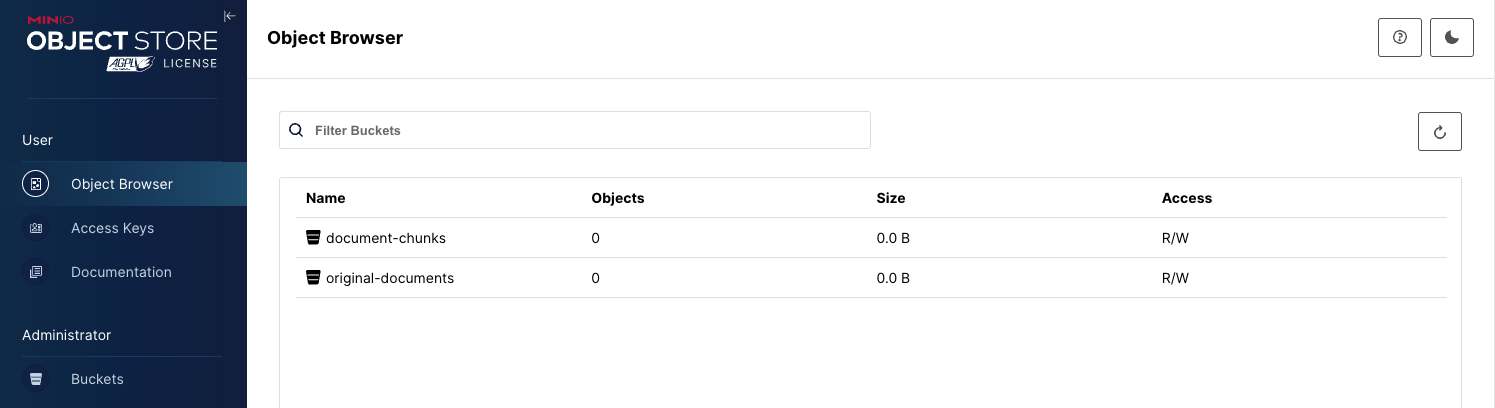
我已经将 Open-Parse 存储库中的 cookbooks 使用的一些示例文档上传到 original-corpus 存储桶。我还上传了我最喜欢的一篇白皮书。
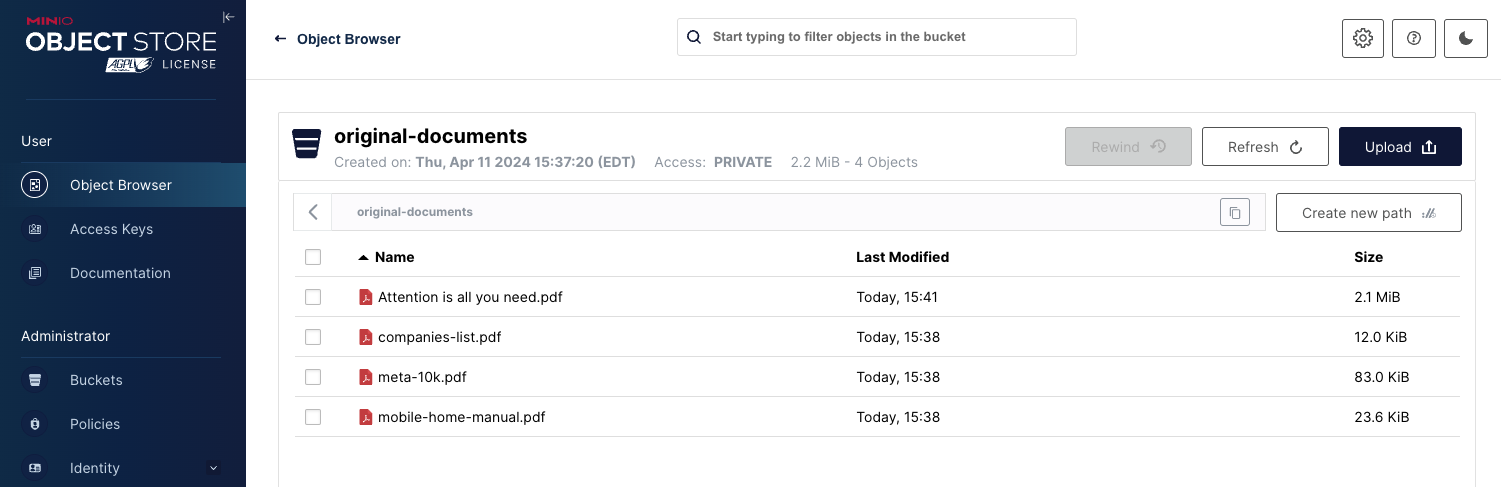
首先,我们需要一个实用程序函数将文件下载到临时目录,以便 open-parse 可以处理它。下面的函数将连接到 MinIO,并将 PDF 下载到系统的临时文件夹。
import os
from dotenv import load_dotenv
load_dotenv()
MINIO_URL = os.environ['MINIO_URL']
MINIO_ACCESS_KEY = os.environ['MINIO_ACCESS_KEY']
MINIO_SECRET_KEY = os.environ['MINIO_SECRET_KEY']
if os.environ['MINIO_SECURE']=='true': MINIO_SECURE = True
else: MINIO_SECURE = False |
import tempfile
from minio import Minio
from minio.error import S3Error
def get_pdf_from_minio(bucket_name: str, object_name: str) -> str:
'''
Retrieves an object from MinIO, saves it in a temp file and retiurns the
path to the temp file.
'''
try:
# Create client with access and secret key
client = Minio(MINIO_URL,
MINIO_ACCESS_KEY,
MINIO_SECRET_KEY,
secure=MINIO_SECURE)
# Generate a temp file.
temp_dir = tempfile.gettempdir()
temp_file = os.path.join(temp_dir, object_name)
# Save object to file.
client.fget_object(bucket_name, object_name, temp_file)
except S3Error as s3_err:
raise s3_err
except Exception as err:
raise err
return temp_file |
一旦我们使用下面的代码片段运行这个函数,我们将在当前系统的临时目录中获得一个文件。
original_corpus_bucket_name = 'original-documents'
chunked_corpus_bucket_name = 'document-chunks'
object_name = 'Attention is all you need.pdf'
temp_file = get_pdf_from_minio(original_corpus_bucket_name, object_name) |
接下来,让我们分割 PDF 文件。这只需要几行代码就可以完成。分割完文档后,节点就可以显示出来。如下所示。
import openparse
parser = openparse.DocumentParser()
parsed_basic_doc = parser.parse(temp_file)
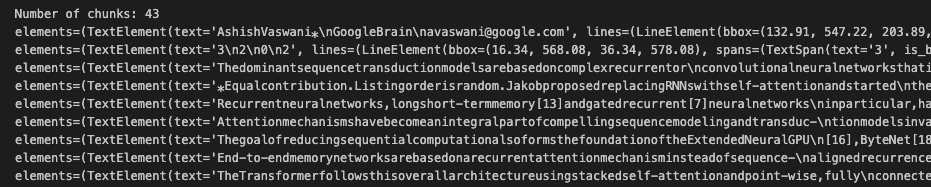
print('Number of chunks:', len(parsed_basic_doc.nodes))
for node in parsed_basic_doc.nodes:
print(node) |
每个节点包含一段文本以及有关该文本来自何处的附加信息。下面的截图显示了上面代码片段的输出,它包含了非常丰富的信息。
使用这种显示技术可以很好地理解用于表示文档的底层对象模型。但是,Open-Parse 的特别之处在于它的可视化工具,它可以在原始文档上绘制一个边界框,显示每个文本片段来自何处。这只需要两行代码就可以完成。
pdf = openparse.Pdf(temp_file)
pdf.display_with_bboxes(parsed_basic_doc.nodes[0:4]) |
在这段代码中,我要求 Open-Parse 绘制原始 PDF 以及围绕前四个文本片段的边界框。显示结果如下。请注意,即使文本采用网格格式,作者也被放置在一个单独的文本片段中。Open-Parse 还识别出了页面左侧的垂直文本。

如果我们使用类似的代码运行另一个原始文档,我们可以看到 Open-Parse 如何处理节标题和带项目符号的文本。

将文本片段保存到 MinIO
完成文档分割后,下一步是将每个文本片段保存到 MinIO。为此,我们将使用上面的截图中显示的 “document-chunks” 桶。下面的函数将文件保存到 MinIO 桶中。我们将使用此函数将每个文本片段保存为单独的对象。
def save_chunk_to_minio(bucket_name: str, object_name: str,
file_path: str, metadata: dict) -> None:
'''
将文档块保存到 MinIO。
'''
try:
# 使用访问密钥和密钥创建客户端
client = Minio(MINIO_URL, # host.docker.internal
MINIO_ACCESS_KEY,
MINIO_SECRET_KEY,
secure=MINIO_SECURE)
client.fput_object(bucket_name, object_name, file_path, metadata=metadata)
except S3Error as s3_err:
raise s3_err
except Exception as err:
raise err |
Open-Parse 提供了一个 `model_dump` 方法,用于将分块文档序列化为字典。以下代码片段调用了该方法,并打印了一些额外的信息,以帮助您了解这个字典是如何形成的。
import json
chunks = parsed_basic_doc.model_dump_json()
chunks = json.loads(chunks)
print(chunks.keys())
print(chunks['nodes'][0])
print(type(chunks['nodes'][0]))
chunks |
下面的代码显示了输出。
dict_keys(['nodes', 'filename', 'num_pages', 'coordinate_system', 'table_parsing_kwargs'])
{'variant': {'text'}, 'tokens': 140, 'bbox': [{'page': 0, 'page_height': 792.0, 'page_width': 612.0, 'x0': 116.68, 'y0': 436.19, 'x1': 497.21, 'y1': 558.54}], 'text': '...'}
<class 'dict'> |
{'nodes': [{'variant': {'text'},
'tokens': 140,
'bbox': [{'page': 0,
'page_height': 792.0,
'page_width': 612.0,
'x0': 116.68,
'y0': 436.19,
'x1': 497.21,
'y1': 558.54}],
'Text': ... |
该字典可以拆分,每个片段可以发送到MinIO。 下面的代码展示了如何实现。该代码还为每个对象添加了有关原始文档的元数据。 将原始文件名与每个片段一起保存有助于在Rag推理管道中实现可解释性。 可解释性允许使用Rag支持的LLM的应用程序显示用于构建提示上下文的所有文档的链接。 对于最终用户和致力于提高推理管道性能的工程师来说,这是一个强大的功能。
import json
temp_dir = tempfile.gettempdir()
temp_file = os.path.join(temp_dir, 'tmp.json')
print(temp_file)
metadata = {}
metadata['filename'] = chunks['filename']
metadata['num_pages'] = chunks['num_pages']
metadata['coordinate_system'] = chunks['coordinate_system']
metadata['table_parsing_kwargs'] = chunks['table_parsing_kwargs']
print(metadata)
chunk_num = 0
for node in chunks['nodes']:
with open(temp_file, 'w') as f:
f.write(json.dumps(node))
#pickle.dump(node, f) # Serialize the node.
chunk_name = os.path.splitext(object_name)[0]
save_chunk_to_minio(chunked_corpus_bucket_name, f'{chunk_num} - {chunk_name}.json',
temp_file, metadata)
chunk_num += 1 |
上述代码完成后,我们的文档片段存储桶将如下所示。
下一步
这篇文章介绍了 Open-Parse 的核心功能。但是,它还有一些高级功能,在构建生产级推理管道之前应该先探索这些功能。
- 解析表格 可能很棘手。如果默认功能在处理表格时遇到问题,请查看高级表格解析功能 这里。
- RAG 的主要优势之一是**可解释性**。它允许用户查看用于生成其答案的所有文档的链接。通过 Open-Parse,这可以通过每个文档块保留的元数据来实现。当收集语义相关的块时,可以使用所有文档确定,并可以显示指向这些文档的链接以及生成的文本。此功能的简短视频演示可以在此处查看。
- **语义分块**是一种高级技术,如果节点(块)在语义上相似,则将它们合并。了解更多信息此处。
- 如果您希望进一步处理提取的数据,您可以将**自定义处理函数**添加到 DocumentParser 类。了解更多信息此处。
如果您有任何问题,请务必在 Slack上与我们联系!
