Intel 与 ARM CPU 性能对对象存储的影响
AWS 最近宣布其新款基于 ARM 架构的 Graviton2 服务器正式可用,这促使我们再次关注这些 ARM 服务器的性能表现。在这篇博文中,我们将描述一些你可能会感到惊讶的结果。
引言
MinIO 是一个采用 Apache 许可证的开源 S3 兼容对象存储服务器,其特别注重高性能。它能够使用普通硬盘读取和写入 数十 GB/秒 的数据,甚至使用 100 Gbit 网络结合 SSD 或 NVMe 驱动器达到 数百 GB/秒 的速度。
为了实现如此高的性能水平,MinIO 利用了 Golang(MinIO 的主要开发语言)紧密集成的汇编语言特性。
MinIO 的两个核心算法在计算方面要求很高,分别是擦除编码(用于数据持久性)和哈希(用于检测数据损坏)。这两个算法都利用 SIMD(单指令多数据)指令进行了大量优化,不仅针对英特尔平台(AVX2 和 AVX512),也针对 ARM(NEON)和 PowerPC(VSX)。
MinIO 依赖的第三个关键算法是(按对象)加密。由于 Golang 的标准库对各种加密技术提供了出色的支持,并包含了优化的代码,因此 MinIO 直接使用了这些实现。
由于其核心算法的高度优化特性,MinIO 成为比较不同 CPU 架构的绝佳目标。但是,为了消除任何系统影响,例如网络速度和/或存储介质吞吐量,我们选择进行单独的基准测试,如下所述。
基准测试方法
为了比较新的 Graviton2 CPU 与英特尔的性能,我们在两种不同类型的 EC2 实例上运行了测试。对于英特尔,我们选择了 c5.18xlarge 实例,而对于 ARM/Graviton2,我们使用了新的 m6g.16large 类型。
英特尔 Skylake 服务器是双插槽,每个 CPU 有 18 个核心。这导致每个 CPU 具有 36 个支持超线程的 vCPU,或者两个 CPU 总共 72 个 vCPU。ARM 服务器仅使用一个插槽,具有 64 个核心,不支持超线程。更多详细信息可以在下表中找到。
| Architecture | x86_64 | aarch64 |
| CPU(s) | 72 | 64 |
| Thread(s) per core | 2 | 1 |
| Core(s) per socket | 18 | 64 |
| Socket(s) | 2 | 1 |
| NUMA node(s) | 2 | 1 |
| L1d cache | 32K | 64K |
| L1i cache | 32K | 64K |
| L2 cache | 1024K | 1024K |
| L3 cache | 25344K | 32768K |
由于英特尔 CPU 比 ARM 芯片多 8 个(支持超线程的)vCPU,因此我们在测试中将线程最大数量限制为 64,以创造公平的竞争环境。
您可以在 GitHub 上的 MinIO-benchmarking 存储库中找到代码。
擦除编码
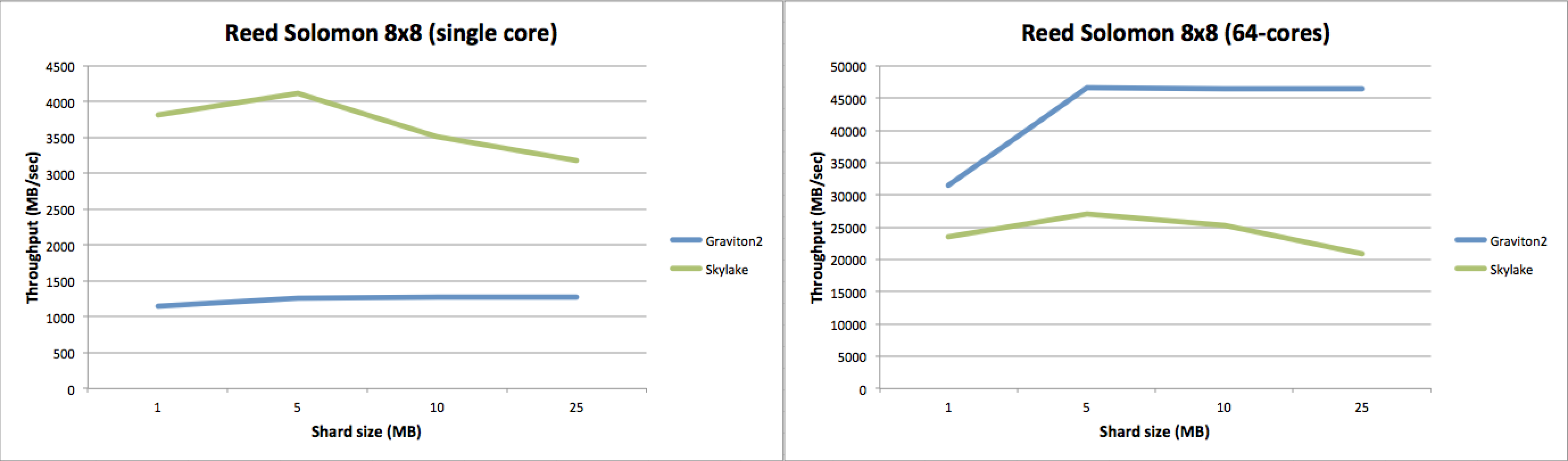
下面的组合图表左侧显示了运行 8 个数据和 8 个奇偶校验(Reed Solomon)擦除编码编码步骤的单核性能,作为数据分片大小(从 1 MB 到 25 MB)变化的函数。在这里,英特尔 Skylake 明显且大幅领先于 ARM Graviton2 CPU。随着数据分片大小的增加,英特尔的性能略有下降,而 ARM 的性能几乎保持不变。
如果我们查看右侧的多核性能图表(两个平台上的所有 64 个核心都 100% 忙于进行擦除编码),我们会看到基本上是相反的情况。ARM 的聚合性能非常平稳,并且比英特尔快约 2 倍,并且随着数据分片大小的增加,差距实际上还在扩大。
Highwayhash
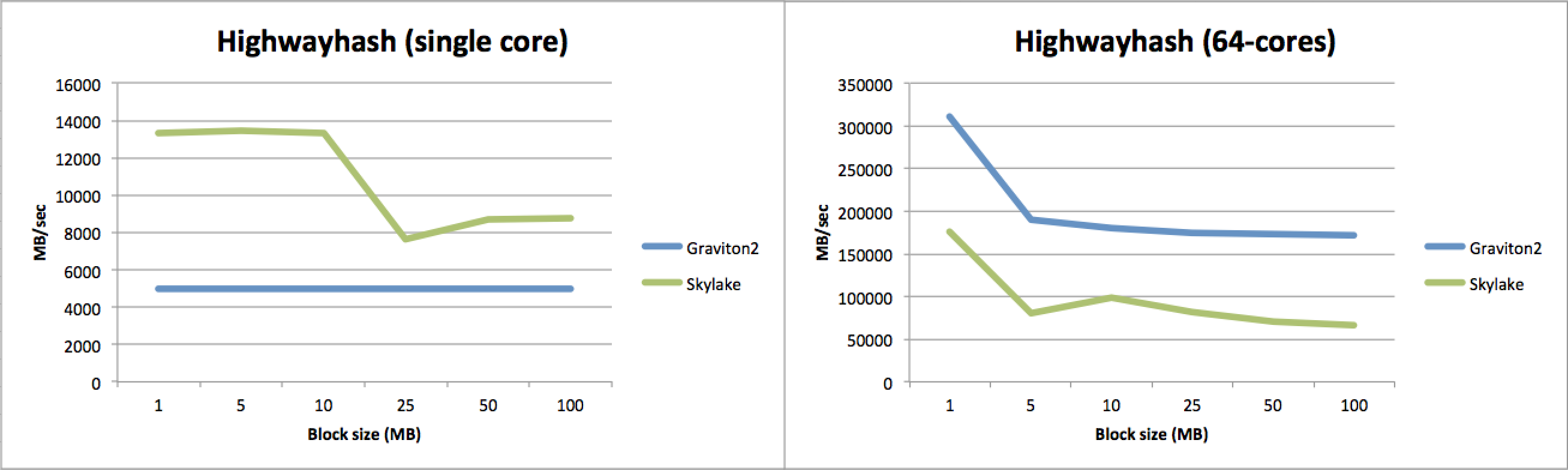
将注意力转向 MinIO 用于检测数据损坏的哈希算法,我们可以看到类似的模式。对于单核性能,英特尔占据明显优势,并且随着块大小的增加,优势有所减弱。
关于多核性能,情况再次反转,ARM 在几乎所有不同的块大小上都超过英特尔 2 倍以上。
加密
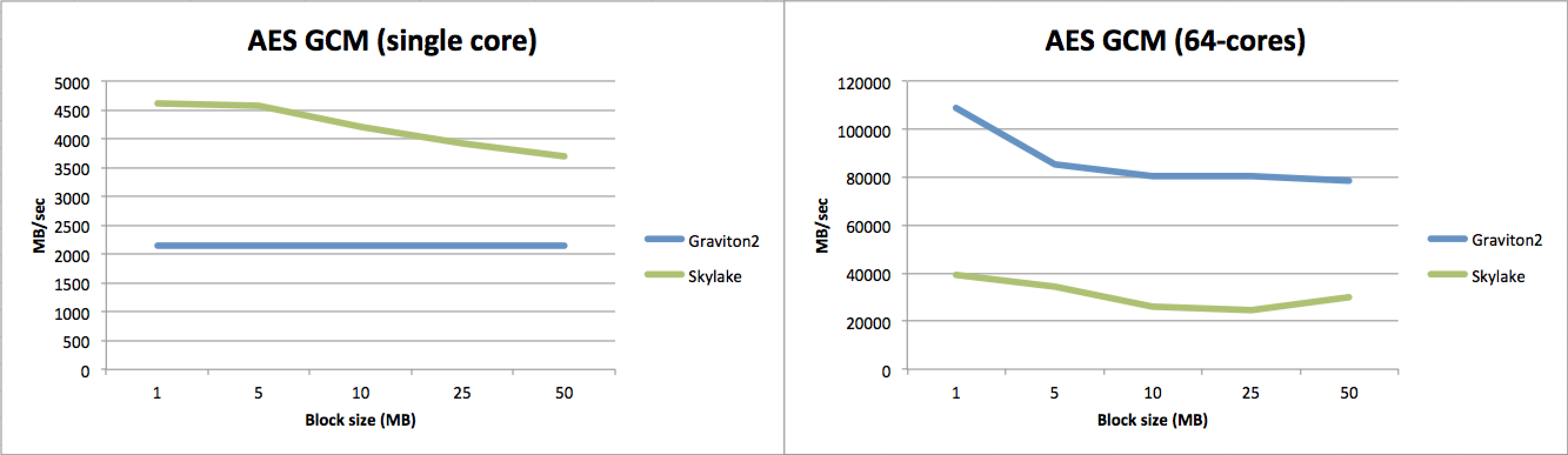
最后,对于加密,模式再次相同。在单核方面,英特尔明显优越,尽管随着块大小的增加,差距有所减小(而 ARM 的性能再次几乎完全一致)。
然后,在多核性能方面,ARM 再次击败英特尔两倍以上。
线性可扩展性
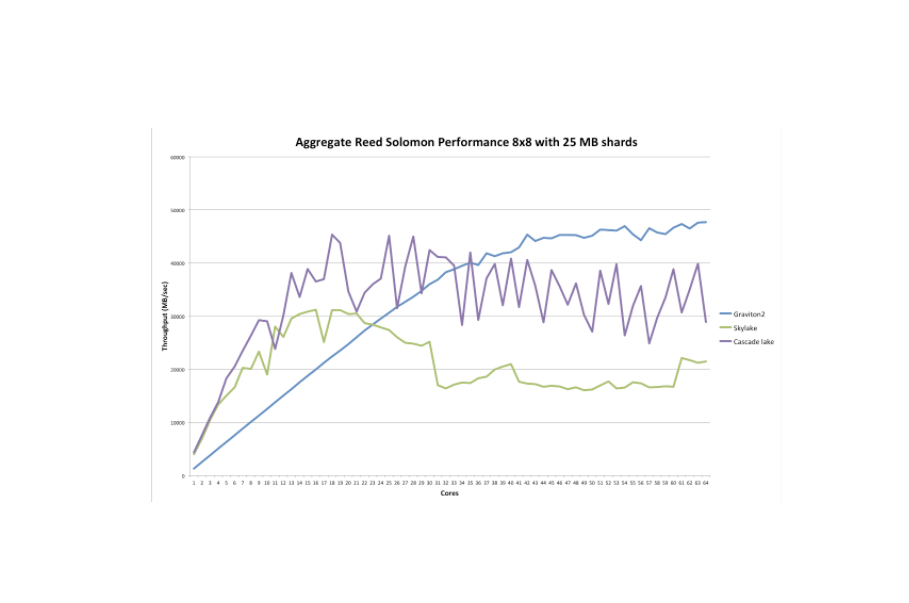
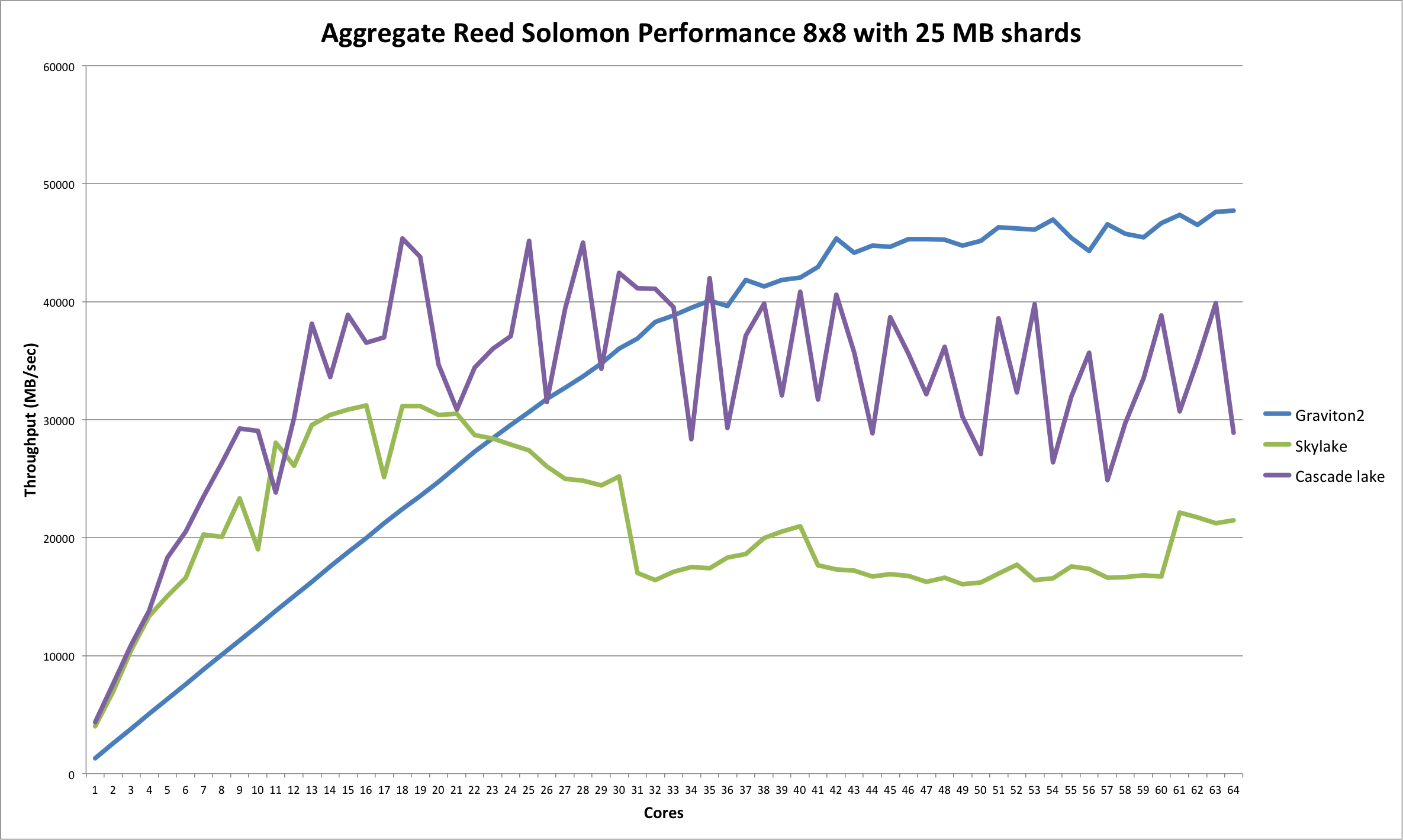
根据我们收集的数据,我们能够生成另一个有趣的比较图表。它显示了(聚合的)Reed Solomon 擦除编码性能(8 个数据和 8 个奇偶校验,25 MB 分片),作为 Skylake(和 Cascade Lake;稍后详细介绍)与 Graviton2 的核心数量的函数,范围从单个核心到 64 个核心。
这更详细地证实了我们上面观察到的结果。大约 20 个核心之前,英特尔 Skylake CPU 超越 Graviton2,但之后(聚合的)性能大致保持平稳(甚至略有下降)。
另一方面,Graviton2 具有完全的线性性能可扩展性,直到大约 30 多个核心后,性能提升才开始逐渐减弱。
由于 Skylake 不是英特尔 CPU 的最新一代,因此我们决定在 Cascade Lake 服务器上也运行此测试。为此,AWS 提供了 c5.24xlarge 实例类型,该类型具有双 Cascade Lake CPU,提供总共 96 个 vCPU 和每个 CPU 36608K 的 L3 缓存。为了便于比较,我们再次没有超过 64 个同时核心。
如您所见,在我们的测试中,Cascade Lake 明显快于 Skylake,尽管图表显示出更“锯齿状”的趋势。其峰值性能位于 20 到 30 个核心的范围内(也许并不奇怪,因为它有 24 个物理核心),并且与 Skylake 相比,核心数量较高时的下降幅度较小。
如果我们也将 Cascade Lake 与 Graviton2 进行比较,那么在核心数量较少的情况下,它快得多,但在核心数量较多时(如果你进行某种“移动平均”),它介于 Skylake 和 Graviton2 之间。因此,Cascade Lake 的性能明显优于 Skylake,但无法达到 Graviton2 的水平。
单插槽与双插槽
上面报告的(双)英特尔 CPU 的结果有些不尽如人意,这促使我们进行更多测试,以了解单插槽服务器上的性能表现。
事实证明,c5.9xlarge 和 c5.12xlarge 实例类型正是我们正在寻找的,因此我们在这些实例类型上重复了上述线性可扩展性测试。由于我们现在正在单个 CPU 上运行,因此对于 Skylake,核心数量限制为 36,而对于 Cascade Lake,核心数量限制为 48。为了便于比较,Graviton2 的图表重复显示到 64 个核心(当然也是单插槽)。
由于 AWS 上提供了 AMD EPYC CPU(形式为 c5a 实例类型),因此我们在该 CPU 上重复了单插槽测试(48 个物理核心;类型 7R32)。结果添加到下面的图表中,并且可以看出它与两个英特尔 CPU 相比具有更好的可扩展性。在高端,它似乎比 Graviton2 的性能略差。
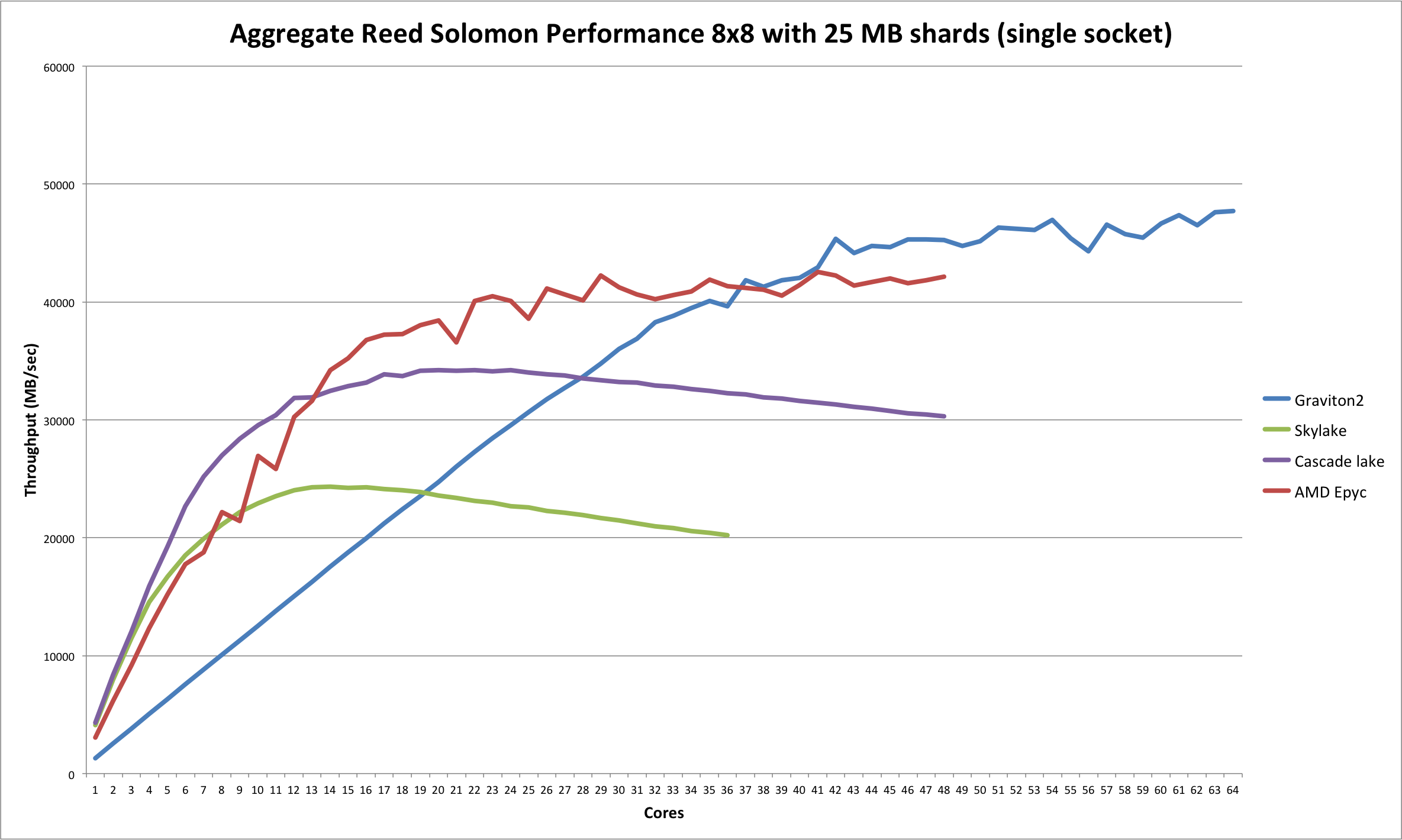
结果图表在形状上非常相似,但与之前显示的双插槽图表相比,更加“平滑”。再次,英特尔 CPU 在核心数量较少时提供出色的性能,并在物理核心数量附近达到峰值,然后在接近其最大核心数量时略有下降。
此图表详细说明的是,双插槽服务器的(很大程度上)没有额外的性能表明,双插槽服务器可能在内存访问方面存在严重“竞争”,这严重影响了性能。MinIO 代码库针对性能进行了高度优化,毫无疑问,这在很大程度上归因于这种现象。
成本和功耗
关于功耗,据估计,Graviton2(运行频率为 2.5 GHz)每个核心的功耗高达 1.8 W,总共约为 115W。据传闻,AMD EPYC 的功耗约为 280W,英特尔 CPU 的功耗约为 240W。下表总结了这四种 CPU 的信息。

基于此,我们可以计算一些有趣的比率。下表显示了每 vCPU 和(物理)核心的功耗和价格比率。显示每 vCPU 和每核心的比率的原因是,正如我们上面看到的,根据用例,“超线程”的有效性可能会有很大差异。因此,每 vCPU 或每核心的比率可能更适用于您的特定用例。
请注意,由于 Graviton2 不使用超线程,因此 vCPU 和核心之间显然没有区别。此外,基于 ARM 的实例类型提供了更多的 RAM,为 256 GiB,而其他两种类型为 144 或 192 GiB。

也许不出所料,鉴于 ARM 的背景,在功耗方面,与英特尔 CPU 和 AMD CPU 相比,Graviton2 的效率明显更高。在成本比较方面,Graviton2 和 AMD EPYC 在“每 vCPU”基础上的价格相同,而英特尔 CPU 的价格略贵。
结论
首先,我们要说明的是,从所有实际用途来看,英特尔和 ARM 平台都提供了充足的计算能力,足以饱和甚至最快的网络速度和 NVMe 驱动器。因此,从这个意义上说,两者都完全能够满足 MinIO 对象存储服务器对最高性能的要求。
话虽如此,但很明显的是,随着 AWS 推出 Graviton2 处理器,ARM 架构已经缩小了与英特尔的性能差距,甚至在多核性能方面超越了英特尔。
尤其是在高度多线程的环境中,Graviton2 CPU 看起来非常出色。随着云工作负载要求服务器应用程序处理(许多)多租户场景,这将是一个真正的优势。此外,随着 Firecracker(用于轻量级虚拟化和无服务器计算)等技术的日益普及,这些最新的 ARM 芯片是一个极好的补充。
最后,鉴于 ARM 来自移动计算领域的背景,Graviton2 的功耗很可能相对较低(尽管确切细节尚不清楚)。
需要注意的事项
亚马逊并不是唯一一家关注这个新的 ARM 平台的公司,以下是一些值得关注的其他发展方向: