在 MinIO 云存储上使用 Apache Presto 进行交互式 SQL 查询
数据分析和查询技术可以深入了解用户想要什么、用户行为以及更多其他信息。随着越来越多的数据进入企业云,分析技术正在不断发展,以帮助企业理解这些数据。
数据分析领域本身并不新鲜;现在已经存在各种工具和技术很长时间了。然而,随着数据规模达到历史新高,这些工具的效率、响应速度和易用性比以往任何时候都更加重要。
随着企业转向基于对象存储的私有云,这些私有云可以直接与应用程序集成,因此分析技术也应该与对象存储进行集成。这样做不仅可以提高效率,而且易于维护。
在这篇文章中,我们将讨论Presto——一个快速、交互式、开源的分布式SQL查询引擎,用于对各种规模的数据源(从GB到PB)运行分析查询。Presto于2012年在Facebook开发,并在2013年以Apache 2.0许可证开源。 Starburst是一家由该项目主要贡献者组成的公司,为Presto提供企业支持。他们的工程师最近发表了一篇博客文章,介绍了如何使用Presto查询对象存储数据湖。
Presto可以通过它的连接器连接到各种数据源。我们将重点关注Hive连接器,它允许Presto与Minio服务器进行通信。使用Presto从私有云中的Minio服务器查询数据,您可以获得安全高效的数据存储和处理管道。
用例
当Presto在Minio服务器上运行查询时,多个查询用户会从Minio中使用相同的数据,而生成数据的应用程序会写入Minio。这导致计算层和存储层有效分离,从而提供灵活的扩展选项。
此类部署可以用于各种用例。例如
- 在进行深度查询之前,使用通用的即席交互式查询来理解模式。
- 分析A/B测试结果,以了解用户从测试数据中的行为。
- 从用户数据训练深度学习模型。
为什么选择Minio
Minio是一个高度可扩展且高效的对象存储服务器。它可以部署在各种平台上,并可以直接连接到任何支持S3的应用程序。凭借SSE-C、联合、擦除编码等功能,Minio提供企业级对象存储解决方案。
这使得Minio成为私有云存储需求的理想选择。
为什么选择Presto
Presto允许查询数据所在位置,包括Hive、Cassandra、关系数据库,甚至专有数据存储。以下是几个优点:
- 将计算与存储分离,并独立扩展。
- 单个Presto查询可以组合来自多个数据源的数据,从而允许跨整个组织进行分析。
- 凭借其交互性,Presto的目标是需要亚秒级到分钟级响应时间的用例。
- Presto由Facebook开发,用于针对包括其300PB数据仓库在内的多个内部数据存储进行交互式查询。每天有超过1000名Facebook员工使用Presto运行超过30,000个查询,这些查询每天总共扫描超过1PB的数据。
- 其他主要Presto用户包括Netflix(使用Presto分析存储在AWS S3中的超过10PB的数据)、Airbnb和Dropbox。
与Hive的比较
- 速度:由于其优化的查询引擎,Presto速度更快,最适合交互式分析。相比之下,Hive速度较慢。
- 灵活:Presto的即插即用式数据源模型使跨不同数据源的轻松连接和查询成为可能。Hive也可以连接到Hadoop存储后端,但一次只能连接一个。
- ANSI SQL:Presto遵循ANSI SQL,这是公认的SQL语言,因此它有助于轻松地进行查询迁移,而无需太多开销。另一方面,Hive具有类似SQL的语法,但并不严格遵循ANSI标准。
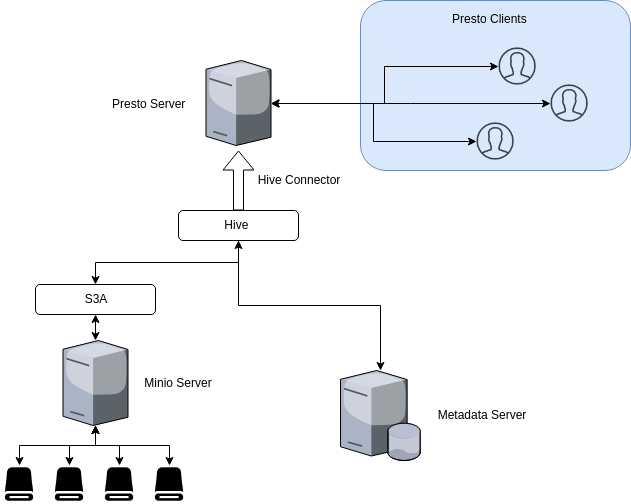
要将Presto连接到Minio服务器,我们将使用Presto Hive连接器。为什么使用Hive连接器?Presto使用Hive元数据服务器获取元数据,使用Hadoop s3a 文件系统从S3对象存储获取实际数据;这两种操作都是通过Hive连接器完成的。
Presto仅通过Hive连接器使用元数据和数据。它不使用HiveQL或Hive执行环境的任何部分。
要将Minio与Presto一起部署,我们需要先设置Hive。只有这样,Presto Hive连接器才能使用Hive元数据服务器。
- 启动Minio服务器——按照此处所述部署Minio服务器。然后在您的Minio服务器上创建一个名为
presto-minio的桶。我们将在后面使用此桶。 - 设置Hadoop——Hadoop是Hive的基础平台。按照以下步骤设置Hadoop:
- 从
2.8版本系列的此处下载最新的Hadoop版本。将内容解压缩到一个目录中,我们将称之为Hadoop安装目录。 - 将环境变量
$HADOOP_HOME设置为Hadoop安装目录。此外,使用以下命令更新PATH:export PATH=$PATH:$HADOOP_HOME/bin
export SPARK_DIST_CLASSPATH=$(hadoop classpath) - 打开文件
$HADOOP_HOME/etc/hadoop/hdfs-site.xml,并在<configuration>标签内添加以下内容:<property>
<name>fs.s3a.endpoint</name>
<description>要连接到的AWS S3端点。</description>
<value>http://127.0.0.1:9000</value>
</property><property>
<name>fs.s3a.access.key</name>
<description>AWS访问密钥ID。</description>
<value>minio</value>
</property><property>
<name>fs.s3a.secret.key</name>
<description>AWS密钥。</description>
<value>minio123</value>
</property><property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
<description>启用S3路径样式访问。</description>
</property><property>
<name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.s3a.S3AFileSystem</value>
<description>S3A文件系统的实现</description>
</property>
请记住使用上面Minio服务器端点和访问/密钥的实际值。
3. 设置Hive —通过从此处下载相关tarball安装Hive的稳定版本。
- 将内容解压缩到一个目录中,我们将称之为hive安装目录。
- 将环境变量
$HIVE_HOME设置为hive安装目录。 - 使用以下命令将
$HIVE_HOME/bin添加到您的PATH中:
export PATH=$HIVE_HOME/bin:$PATH- 将用于Hadoop 和aws-java-sdk 的
jar文件添加到Hive库中:mv ~/Downloads/hadoop-aws-2.8.2.jar $HIVE_HOME/lib
mv ~/Downloads/aws-java-sdk-1.11.234.jar $HIVE_HOME/lib - 在创建Hive表之前,使用以下HDFS命令创建
/tmp和/user/hive/warehouse(也称为hive.metastore.warehouse.dir),并使用chmod g+w设置权限。$HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$HADOOP_HOME/bin/hadoop fs -mkdir /user/hive/warehouse
$HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse - 下一步是为Hive设置模式:$HIVE_HOME/bin/schematool -dbType derby -initSchema
在此处,我们使用derby 作为测试/演示目的的元数据数据库。
- 使用以下命令启动Hive服务器:$HIVE_HOME/bin/hiveserver2
默认情况下,它监听端口10000。
- 最后,使用以下命令启动Hive元数据服务器:$HIVE_HOME/bin/hiveserver2 --service metastore
默认情况下,元数据服务器监听端口9083。我们将使用它作为Presto的元数据服务器。
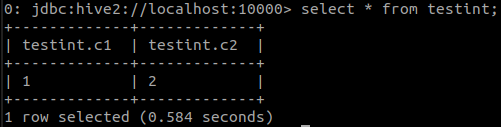
如果您是出于测试目的,并且没有实际数据可以用来测试Hive,可以使用Hive2客户端beeline 创建一个表,填充一些数据,然后使用select 语句显示内容。
4. 设置Presto——Presto安装步骤在文档页面中进行了说明。按照这些步骤创建相关配置文件。现在,我们将进入配置Presto Hive连接器以与我们刚启动的Hive元数据服务器进行通信的步骤。
- 使用以下内容创建
etc/catalog/hive.properties,将hive-hadoop2连接器作为hive目录挂载:connector.name=hive-hadoop2
hive.metastore.uri=thrift://127.0.0.1:9083
hive.metastore-timeout=1m
hive.s3.aws-access-key=minio
hive.s3.aws-secret-key=minio123
hive.s3.endpoint=http://127.0.0.1:9000
hive.s3.path-style-access=true
hive.s3.ssl.enabled=false
请注意指向在上一步骤中创建的Hive元数据服务器的元数据URI。
- 使用
bin/launcher run启动Presto服务器。您应该在控制台中看到类似以下的消息:
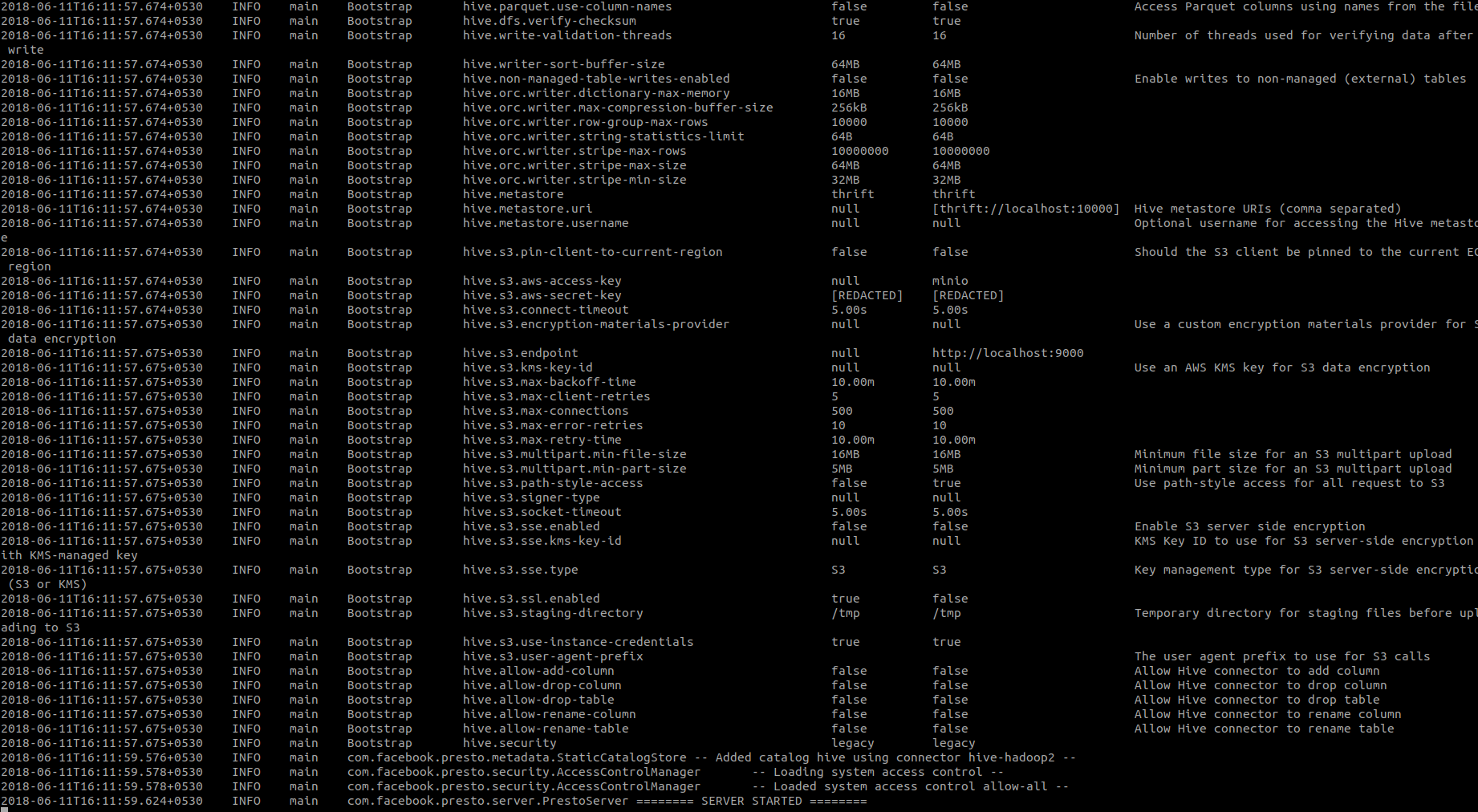
这意味着Presto现在正在运行。您还可以通过浏览器访问https://:8080/ui/ 的Presto UI。
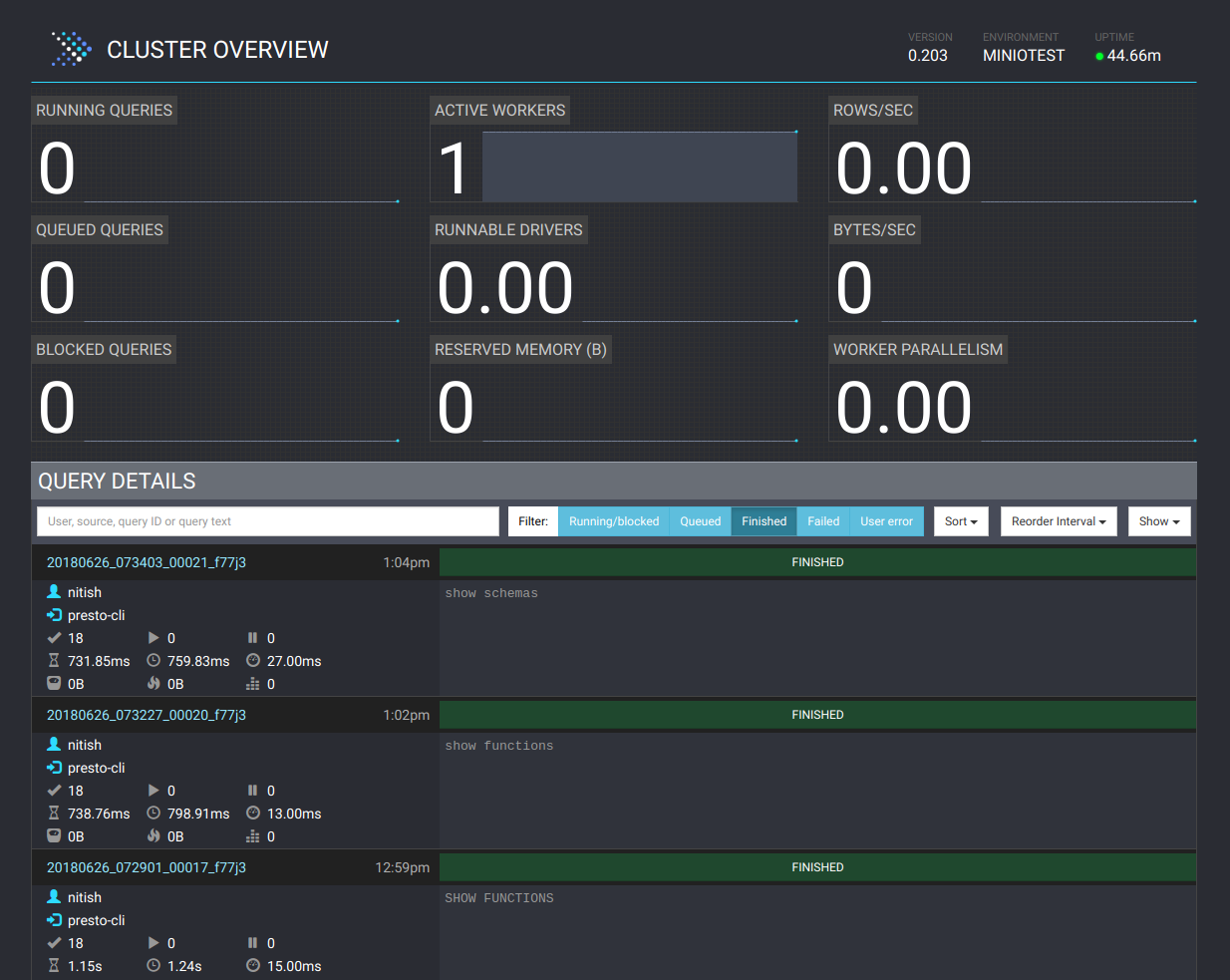
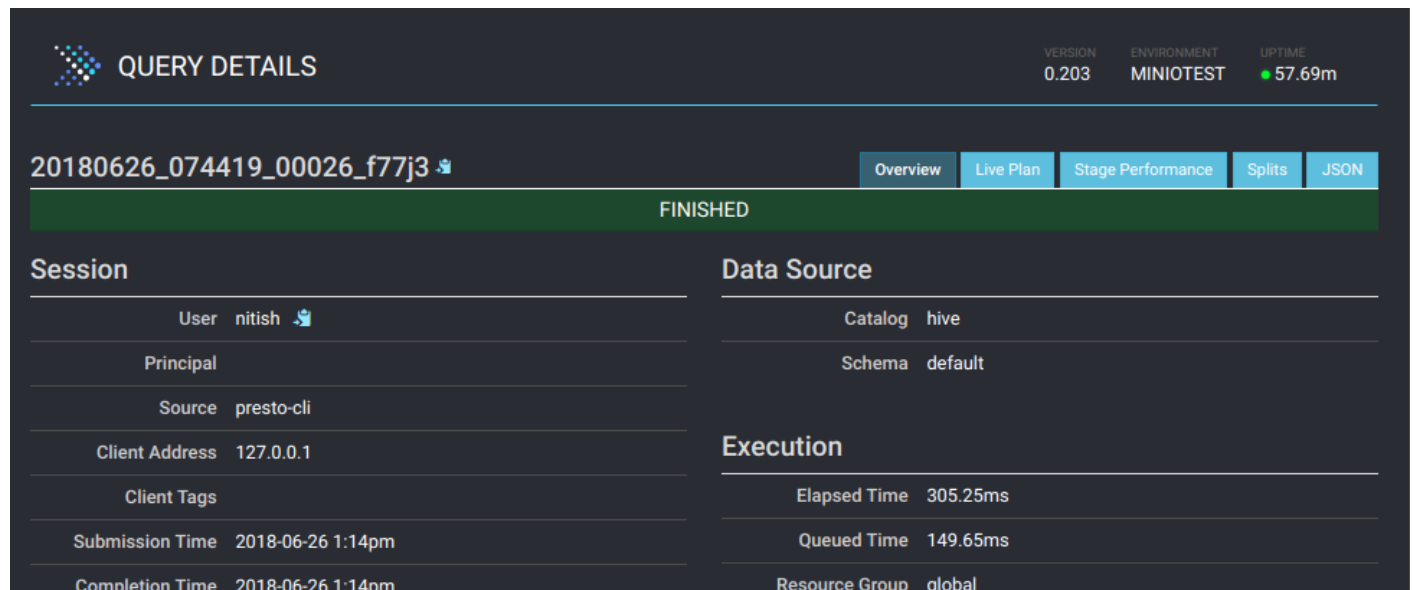
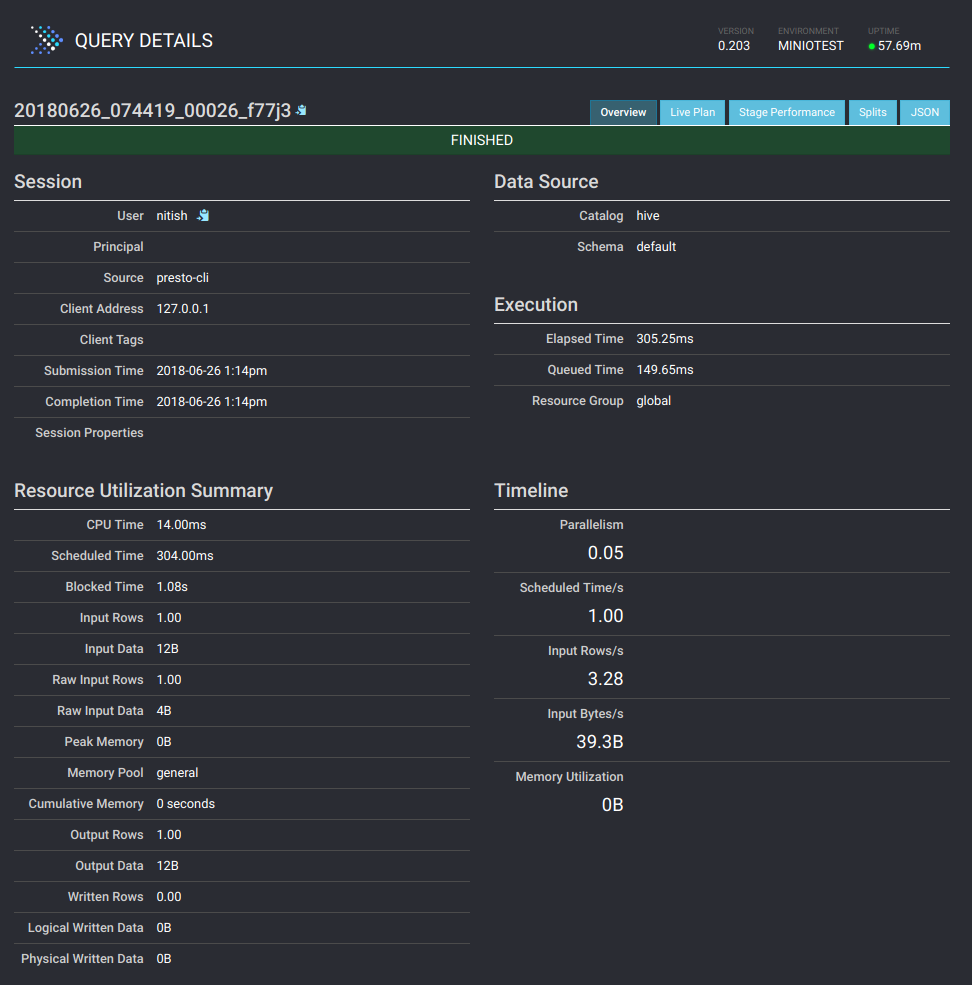
Presto UI提供了正在执行的每个查询的详细内容。单击查询以查看资源利用率、时间线、阶段和工作进程完成的任务等详细信息。以下是详细信息页面的样子:
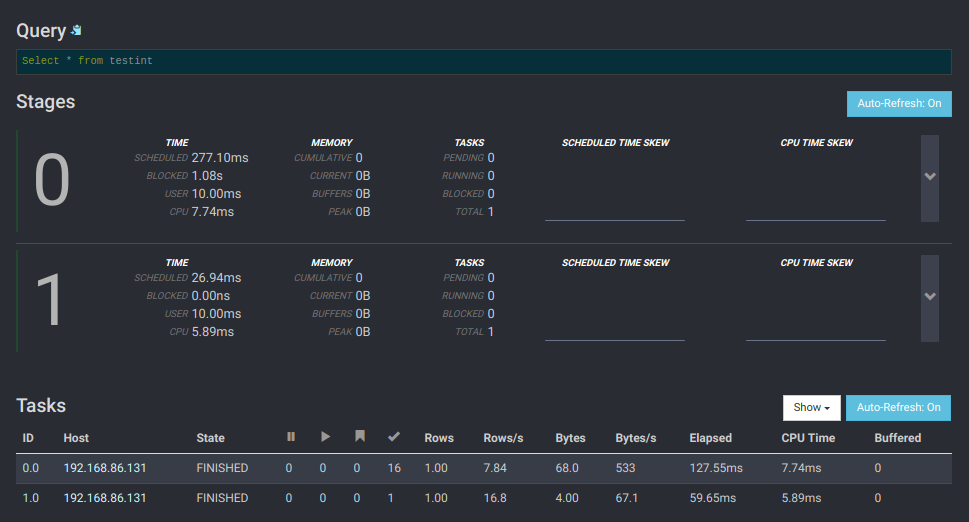
现在,您可以使用Presto CLI 对存储在Minio服务器上的数据发出查询。您还可以使用Presto客户端 之一。
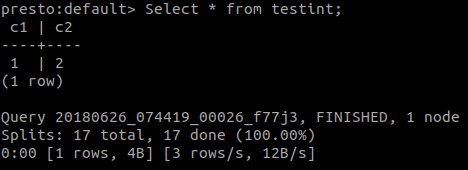
要确认在 Hive 中创建的表是否可通过 Presto 客户端访问,请启动 cli 工具并对该表执行 select 语句。您应该看到相同的内容。
在这篇文章中,我们了解了为什么以及 Presto 如何成为从 Minio 等平台查询大型数据集的首选工具。然后,我们学习了在私有基础设施上设置和部署 Presto 的步骤。