为 MinIO 数据湖介绍 Spark-Select

早期的对象存储 API 开发重点在于高效存储和检索对象。亚马逊 S3 的成功及其对强大的 S3 API 的实现,迅速成为云端对象存储的事实标准。
MinIO 认识到这一点,在创建亚马逊以外最符合 S3 API 的实现方面投入了巨资。反过来,这使得 MinIO 成为私有云对象存储的标准,正如迄今为止超过 2 亿次的 Docker 拉取所证明的那样。
然而,与任何技术一样,对象存储 API 需要不断发展并适应不断变化的用户需求,在这种情况下,这些不断变化的需求正受到新兴的大数据、分析和机器学习工作流的驱动。S3 API 发展的一个动态领域是帮助用户充分利用其数据湖。
这种演变至关重要,因为 AI、ML/DL 和其他分析方法如今在企业数据战略中占据中心地位,而此类工作负载很少会关心对象本身,而是需要访问与特定作业相关的过滤数据。
这导致了 S3 Select API 的创建,该 API 本质上是将 SQL 查询功能直接嵌入到对象存储中。MinIO 最近推出了其对 Select API 的实现。用户可以在其对象上执行 Select 查询,并检索对象的相关子集,而不是必须下载整个对象。
在本文中,我们将讨论大数据生态系统中最受欢迎的数据分析平台之一——Spark。具体来说,我们将了解 MinIO 中的 Select 支持以及它如何补充 Spark 和类似框架。最后,我们将了解最近发布的 MinIO Spark-Select,并了解它如何通过利用 MinIO 中的 SQL 支持来提高查询性能。
MinIO S3 Select API 支持
在发布 Select API 之前,典型的数据流如下所示
- 应用程序使用
GetObject()下载整个对象 - 将对象加载到本地内存中。
- 在对象驻留在内存中的同时,启动查询过程。
使用 S3 Select API,应用程序现在可以下载对象的特定子集——仅满足给定 Select 查询的子集。这直接转化为效率和性能
- 降低带宽需求
- 优化计算资源和内存
- 由于内存占用空间更小,更多作业可以在相同计算资源下并行运行。
- 由于作业完成速度更快,因此可以更好地利用分析师和领域专家。
应用程序可以使用 AWS SDK 添加 S3 Select API。让我们看看使用 aws-sdk-python 使用 MinIO Select API 的示例。
首先,您需要有一个 MinIO 服务器实例已启动,并配置 mc 以与该实例通信。然后,下载一个示例 csv 文件并将其上传到 MinIO 服务器上的相关存储桶。
$ curl "https://esa.un.org/unpd/wpp/DVD/Files/1_Indicators%20(Standard)/CSV_FILES/WPP2017_TotalPopulationBySex.csv" > TotalPopulation.csv$ gzip TotalPopulation.csv$ mc mb myminio/mycsvbucket$ mc cp TotalPopulation.csv.gz myminio/mycsvbucket/sampledata/然后安装 aws-sdk-python 并使用以下代码片段直接在 MinIO 服务器上查询 csv 文件

此处参考 MinIO Select API 的详细文档:https://docs.minio.io/docs/minio-select-api-quickstart-guide.html
MinIO Spark-Select
现在,MinIO Select API 支持已普遍可用,任何应用程序都可以利用此 API 将查询作业卸载到 MinIO 服务器本身。
但是,像 Spark 这样的应用程序(已被数千家企业使用),如果与 Select API 集成,将对数据科学领域产生巨大影响——使 Spark 作业速度提高一个数量级。
从技术上讲,对于 Spark SQL 将可能的查询推送到 MinIO 并仅将对象的相应子集加载到内存中以进行进一步分析,这是非常合理的。这将使 Spark SQL 速度更快,使用更少的计算/内存资源,并允许更多 Spark 作业并发运行。
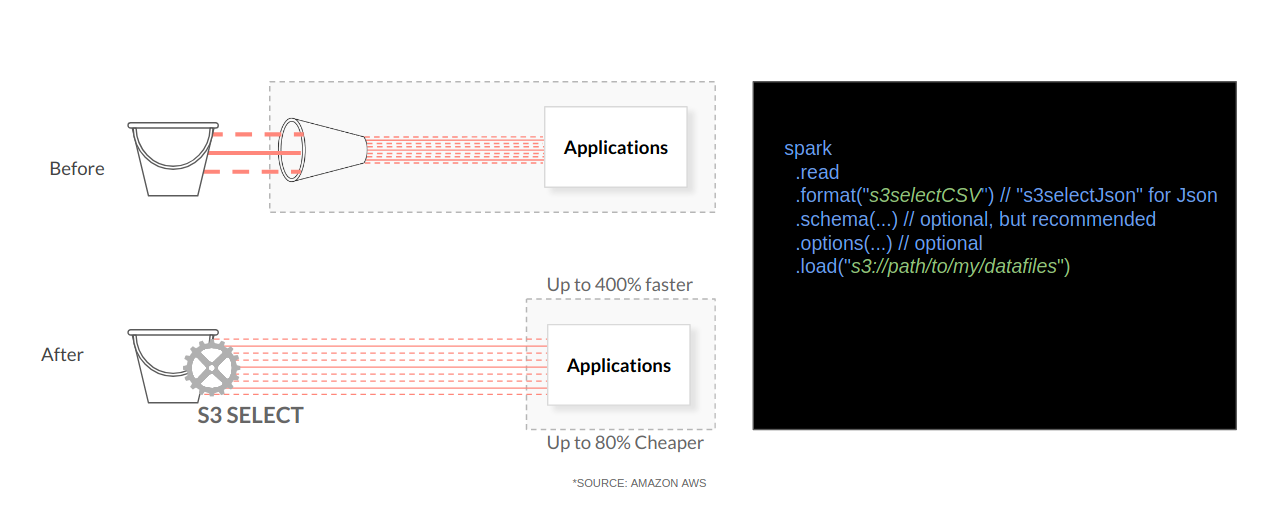
为了支持这一点,我们最近发布了 Spark-Select 项目,以将 Select API 与 Spark SQL 集成。Spark-Select 项目在 Apache License V2.0 下提供,位于
- GitHub (https://github.com/minio/spark-select)
- Spark 包 (https://spark-packages.org/package/minio/spark-select).
Spark-Select 项目作为 Spark 数据源工作,通过 DataFrame 接口实现。在非常高的层次上,Spark-Select 通过将传入的过滤器转换为 SQL Select 语句来工作。然后,它将这些查询发送到 MinIO。当 MinIO 根据 Select 查询返回数据子集时,Spark 将其作为 DataFrame 提供,该 DataFrame 可作为常规 DataFrame 用于进一步操作。与任何 DataFrame 一样,此数据现在可以被任何其他 Spark 库利用,例如 Spark MLlib、Spark Streaming 等。
Spark-Select 目前支持 JSON、CSV 和 Parquet 文件格式以进行查询下推。这意味着对象应该是这些类型之一,才能进行下推。
Spark-Select 可以通过 spark-shell、pyspark、spark-submit 等与 Spark 集成。您还可以将其添加为 Maven 依赖项、sbt-spark-package 或 jar 导入。
让我们看一个使用 spark-select 和 spark-shell 的示例。
- 启动 MinIO 服务器并配置 mc 以与该服务器交互。
- 创建一个存储桶并上传一个示例文件$ curl "https://raw.githubusercontent.com/minio/spark-select/master/examples/people.csv" > people.csv$ mc mb myminio/sjm-airlines
$ mc cp people.csv myminio/sjm-airlines - 从
spark-select存储库下载示例代码$ curl "https://raw.githubusercontent.com/minio/spark-select/master/examples/csv.scala" > csv.scala - 使用 Minio 配置 Spark。详细步骤在本文档中提供:https://github.com/minio/cookbook/blob/master/docs/apache-spark-with-minio.md
- 启动 Spark 时,使用
--packages标志添加spark-select包
> $SPARK_HOME- 成功调用
spark-shell后,执行csv.scala文件
scala> :load csv.scalaLoading examples/csv.scala...import org.apache.spark.sql._import org.apache.spark.sql.types._schema: org.apache.spark.sql.types.StructType = StructType(StructField(name,StringType,true), StructField(age,IntegerType,false))df: org.apache.spark.sql.DataFrame = [name: string, age: int]+-------+---+| name|age|+-------+---+|Michael| 31|| Andy| 30|| Justin| 19|+-------+---+scala>您可以看到,仅返回值为 age > 19 的字段。
我希望以上示例能说明 spark-select 如何帮助将查询下推到 MinIO 服务器并帮助加快数据分析管道。
欢迎您在 https://github.com/minio/spark-select 上查看该项目。
总结
对象存储的世界不仅在增长,而且还在同时发生变化。这些变化可以在生态系统中出现的越来越多的分析和机器学习接触点中看到。虽然本文从战略和战术角度重点介绍了 SQL Select,但未来几周将发布更多关于其他分析框架的文章。
关键要点是,对象存储正在迅速超越灾难恢复和归档的传统用例,进入更加动态的用例,这些用例强调分析和机器学习。SQL 作为数据的通用语言,对于这些用例的成功至关重要。
所有这些都强调了对象存储在公有云和私有云中企业中日益重要的地位。它还区分了传统对象存储和云原生对象存储解决方案。最终,这意味着亚马逊用于公有云,而 MinIO 用于私有云。