使用 Fluentd、MinIO 和 Apache Spark 进行物联网数据存储和分析
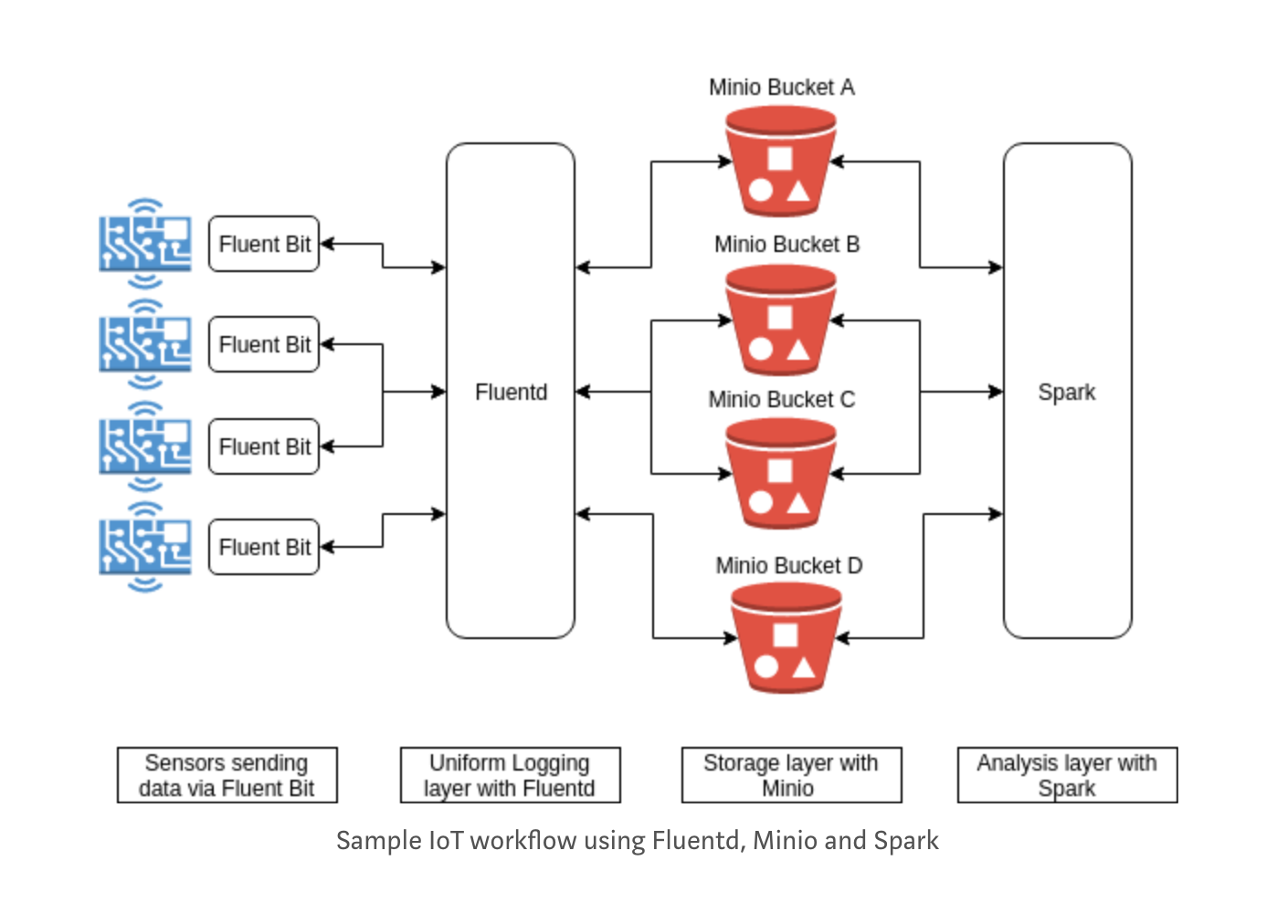
物联网战略成功的关键要求之一是能够存储和分析设备和传感器数据。随着物联网每天将数千台设备接入网络,所有这些设备产生的数据量正在达到惊人的水平。
以可扩展且经济高效的方式存储物联网数据,同时能够轻松地对其进行分析是一个重大挑战。
在这篇文章中,我们将看到一套企业级开源产品,这些产品将有助于建立一个强大、经济高效的物联网数据存储和分析管道。我们将用于设置的产品有
- Fluent Bit:适用于 Linux、OSX 和 BSD 系列操作系统的 数据转发器。
- Fluentd:统一的数据收集和消费层。
- MinIO:可扩展的、云原生存储后端。
- Spark:用于大规模数据处理的通用分析引擎。
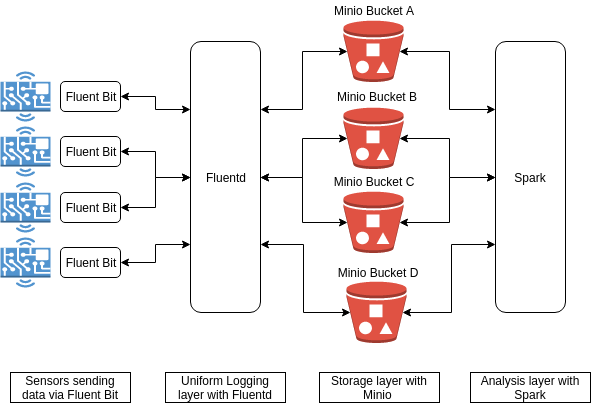
现在让我们逐步了解一下这种设置是如何运作的。
Fluent Bit:最后一公里数据收集
物联网数据源多种多样。在一个典型的设置中,可能存在多种类型的传感器、操作系统、数据库等,每个都以其自身的格式发送数据。
Fluent Bit 通过其可插拔设计简化了从所有这些端点收集数据。Fluent Bit 中的每个输入和输出路由都是一个插件,允许您从各种来源获取数据并将其发送到各种目标。
为了了解 Fluent Bit 的工作原理,让我们看看如何设置 Fluent Bit 来获取 CPU 使用率数据并将其发送到 Fluentd 实例。
首先,使用此处提供的文档安装 Fluent Bit。为了获取数据,我们将使用cpu输入插件,并将数据发送到 Fluentd,我们将使用forward输出插件。这两个插件默认可用,因此只需运行$ fluent-bit -i cpu -t fluent_bit -o forward://127.0.0.1:24224
这会将cpu数据发送到侦听127.0.0.1:24224上的 Fluentd 实例。
Fluentd:统一的数据收集层
鉴于典型的物联网部署每天生成的日志量之大,人类几乎不可能对其进行分析。现代应用程序日志更适合由机器而不是人类来消费。
Fluentd 充当统一的日志记录层,它可以从各种端点获取数据,并允许您将其路由到长期存储或处理引擎。在这篇文章中,我们将采用日志数据存储路径。
MinIO:物联网数据的存储
在完成数据收集和统一之后,让我们看看如何将物联网日志数据存储起来以供长期分析和使用。
选择此类大型数据流的存储时的关键要求包括存储的可扩展性、成本效益,以及由于涉及大量数据传输,带宽使用成本是多少。
凭借内置的擦除码和比特腐烂保护、存储硬件无关性、易于部署和多租户可扩展性,MinIO 满足了上述所有要求,同时具有成本效益和高性能。
在我们继续之前,让我们看看如何在 Fluentd 中获取 Fluent Bit 转发的数据并将其转发到 MinIO 服务器实例。我们将使用in_forward插件获取数据,并使用fluent-plugin-s3将其发送到 MinIO。
首先,使用此处提到的其中一种方法安装 Fluentd。然后编辑 Fluentd 配置文件以添加forward插件配置(对于源代码安装,Fluentd 配置文件默认位于./fluent/fluent.conf)。添加以下部分<source>
type forward
bind 0.0.0.0
port 24224
</source>
这将设置 Fluentd 以侦听端口24224上的forward协议连接。如果您已如上一步所述设置了 Fluent Bit,则应该在 Fluentd 控制台上看到cpu数据。
接下来,设置 Fluentd 将日志数据发送到 MinIO 存储桶。按照这些步骤部署 MinIO 服务器,并使用mc mb命令创建一个存储桶。
然后通过$ fluent-gem install fluent-plugin-s3安装fluent-plugin-s3 gem。
将以下部分添加到 Fluentd 配置文件以配置out_s3插件以将数据发送到 MinIO 服务器。<match>
@type s3
aws_key_id minio
aws_sec_key minio123
s3_bucket test
s3_endpoint http://127.0.0.1:9000
path logs/
force_path_style true
buffer_path /var/log/td-agent/s3
time_slice_format %Y%m%d%H%M
time_slice_wait 10m
utc
buffer_chunk_limit 256m
</match>
请注意,您需要将aws_key_id、aws_sec_key、s3_bucket和s3_endpoint字段替换为您在 MinIO 部署中的实际值。
Spark:物联网数据处理
为了使来自连接设备的数据有用,对其进行处理和分析非常重要。Spark非常适合这里。它擅长以高速处理海量数据,使其成为物联网数据分析的自然选择。
由于 MinIO API 严格兼容 S3,因此它可以与其他兼容 S3 的工具开箱即用,从而可以轻松设置 Apache Spark 以分析来自 MinIO 的数据。
在上面的示例中,我们已经将物联网数据从端点(通过 Fluent bit)发送到统一的日志记录层(Fluentd),然后将其持久存储在 MinIO 数据存储中。下一步是设置 Spark 以分析存储的数据。您可以按照这些步骤配置 Spark 以使用 MinIO 服务器作为数据源。
Spark 是一个通用处理引擎,它开辟了广泛的数据处理功能——无论您需要对物联网数据进行预测分析以查找某些硬件的预期故障,还是分析非结构化数据以构建模型来理解某些模式。
我们了解了如何使用 Fluentd、MinIO 和 Spark 创建一个典型的物联网数据收集、流式传输、存储和处理管道。这种设置不仅具有很好的可扩展性,而且通用性强,可以适应各种类型的物联网工作流。
在此期间,请帮助我们了解您的用例以及我们如何更好地为您提供帮助!填写我们的 MinIO 最佳部署表单(不到一分钟),并有机会在 MinIO 网站上展示您的 MinIO 私有云设计,并向 MinIO 社区展示。