流数据是现代对象存储堆栈的核心组件。 无论数据来源是边缘设备还是数据中心运行的应用程序,流数据都正在快速超越传统的批处理框架。
流数据包括从日志文件(例如 Splunk SmartStore)到 Web 或移动应用程序、自动驾驶汽车、社交网络以及当然还有金融数据的所有内容。 数据通常是时间序列数据,因此需要使用相应的过滤、采样和窗口化技术进行处理。然而,回报是巨大的,并为企业的实时引擎提供支持。
企业如何处理流数据可能变得非常复杂,但本文将从基础开始,以最流行的流引擎之一 **Apache Kafka** 为例。
Apache Kafka 是一个开源的分布式事件流平台,允许用户存储、读取和处理流数据。它读取和写入事件流,允许在分布式、高度可扩展、弹性、容错和安全的环境中输入、输出和存储大量客户数据。
Kafka 支持各种各样的数据源,并通过处理信息流以“主题”的形式存储它们。它还将数据转储到许多类似 sink 的数据存储中,例如 MySQL 和 MinIO。
为了促进数据流从源到 sink 的移动,我们需要 Kafka Connect,这是一个用于在 Apache Kafka 和其他数据系统之间可靠地大规模流式传输数据的工具。
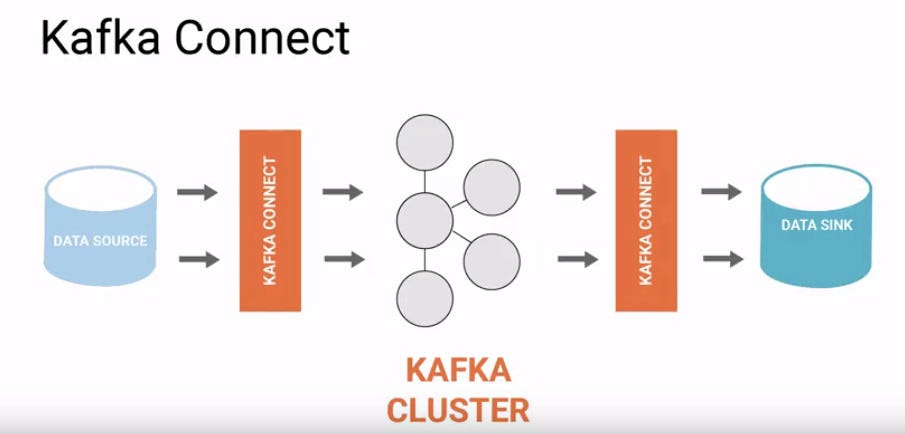
**Kafka** 和 **MinIO** 可以一起用于摄取/管理以及最终存储海量数据。
以下是如何将两者集成的分步教程
- **在 Ubuntu 20.04 上安装和运行 Apacha Kafka:**请按照链接中的步骤 4 进行操作,以将 kafka 作为 systemd 服务运行。https://www.digitalocean.com/community/tutorials/how-to-install-apache-kafka-on-ubuntu-20-04
2. **在 Ubuntu 20.04 上安装和运行 Minio:**
3. **安装 minio-client 并创建一个存储桶:**请按照链接操作,开始使用 minio 客户端 https://docs.min.io/docs/minio-client-quickstart-guide.html

4. **将 Kafka 与 Minio 集成:**使用 Confluent S3 插件将 **Kafka** 消息流式传输到 **MinIO** 存储桶。

在插件目录中创建两个配置文件 connector.properties 和 s3-sink.properties。这些文件是启动 kafka 连接器所必需的。
- 将以下内容复制粘贴到
connector.properties 中

- 将以下内容复制粘贴到
s3-sink.properties 中

5. **创建 Kafka 主题:**创建名为 minio_topic 的 **Kafka** 主题。这是我们在上面 s3-sink.properties 文件中设置的相同主题。

6. **配置 MinIO 凭据:**这对于连接到 MinIO 服务器是必需的。


8. **启动 Kafka 连接器**

9. **将数据发布到 Kafka 主题:**由于在 s3-sink.properties 中定义的刷新大小设置为 3,因此插件将在主题 minio_topic 中有三个消息后将数据刷新到 **MinIO**。

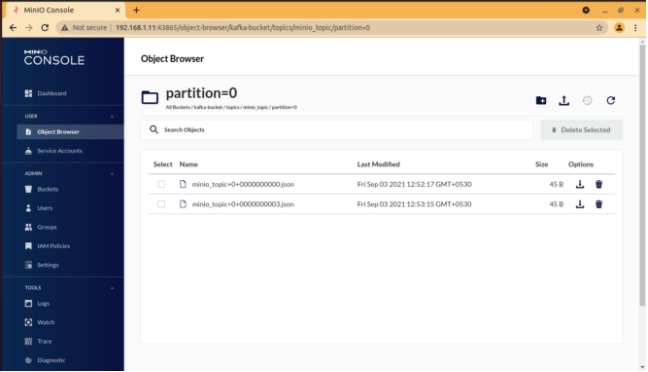
10. **验证 MinIO 服务器上的数据**

11. **登录到 MinIO 控制台重新验证。**