Kubernetes 存储模式
Kubernetes 从根本上改变了传统的应用程序开发和部署模式。应用程序开发团队现在可以在几天内跨不同环境在他们的 Kubernetes 集群中开发、测试和部署他们的应用程序。以前的科技通常需要数周甚至数月的时间。
这种加速得益于 Kubernetes 带来的抽象化,即它处理物理或虚拟机底层细节,同时允许用户声明 CPU、内存、容器实例数量等其他参数。在庞大、热情的社区和不断增长的采用率的支持下,Kubernetes 成为领先的容器编排平台,并且领先优势相当大。
随着采用率的增长,人们对 Kubernetes 中的存储模式的困惑也在增加。
每个人都在争夺 Kubernetes 存储蛋糕的一块,关于存储选项有很多噪音,淹没了信号。
Kubernetes 是现代应用程序开发、部署和管理模式。现代模式将存储和计算解耦。为了完全理解 Kubernetes 上下文中的解耦,我们需要理解有状态和无状态应用程序以及存储的概念。这就是 S3 的 RESTful API 方法比替代解决方案提供的 POSIX/CSI 方法具有明显优势的地方。
这篇文章讨论了 Kubernetes 存储模式,并解决了无状态与有状态的争论,目标是了解为什么存在差异以及为什么它很重要。在文章的后面,我们将根据容器和 Kubernetes 的最佳实践介绍应用程序及其存储模式。
无状态容器
容器本质上是轻量级和短暂的,它们可以轻松地停止、删除或部署到另一个节点,所有这些操作都在几秒钟内完成。在一个大型的容器编排系统中,这种情况一直发生,即使消费者都没有注意到这种转变。但是,只有在容器没有对底层节点的任何数据依赖关系时,这种移动才有可能。这样的容器是*无状态*的。
有状态容器
如果容器将数据存储在本地挂载的驱动器(或块设备)上,则底层存储将必须与容器本身一起移动到新节点 - 在发生故障的情况下。这很重要,否则在容器中运行的应用程序无法正常运行,因为它需要引用它在本地挂载上存储的数据。这样的容器是*有状态*的。
从技术上讲,有状态容器也可以移动到不同的节点。通常,这是通过将分布式文件系统或网络块存储附加到运行容器的所有节点来实现的。这样,容器就可以访问持久卷挂载,并且数据将存储到附加的存储中,该存储在网络上可用。为了统一,在本文的剩余部分中,我将把这种方法称为*有状态容器方法*。
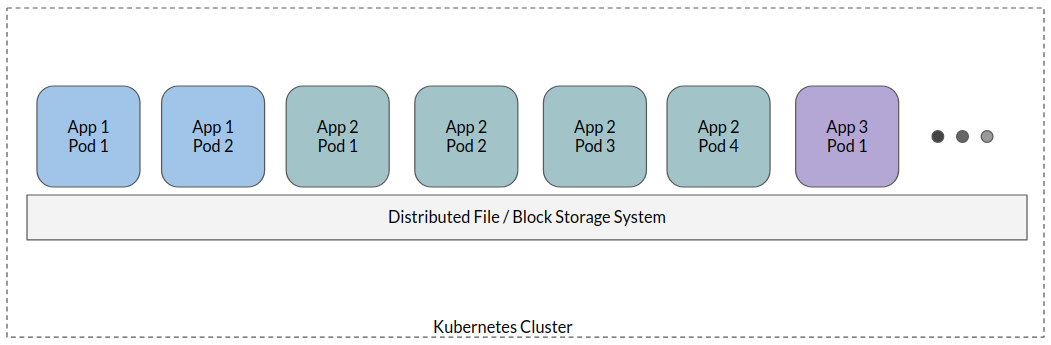
在典型的有状态容器方法中,应用程序 Pod 被挂载到一个分布式文件系统 - 类似于所有应用程序数据所在的共享存储。虽然可能存在一些变体,但这是一种高级方法。
现在,让我们了解为什么*有状态容器方法在云原生世界中是一种反模式*。
云原生应用程序设计
传统上,应用程序使用数据库存储结构化数据,使用本地驱动器或分布式文件系统来转储所有非结构化数据,甚至半结构化数据。随着非结构化数据的增长,开发人员意识到 POSIX 太过繁琐,存在很大的开销,最终阻碍了应用程序的扩展性。
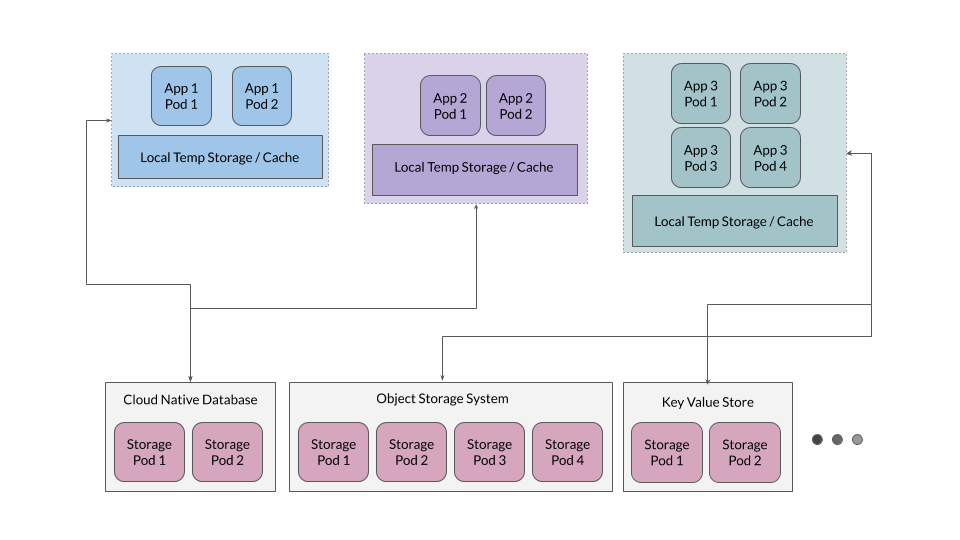
这在很大程度上促成了新的存储标准,即云原生存储,由 RESTful API 驱动,使应用程序免受处理本地存储的任何负担,并使其有效地成为无状态(因为状态位于远程存储系统中)。现代应用程序从一开始就考虑到了这一点。通常,任何处理某种数据的现代应用程序(日志、元数据、Blob 等)都会通过将状态发送到相关的存储系统来符合云原生设计。
有状态容器方法将所有内容都带回了起点!
使用 POSIX 接口存储数据,应用程序以有状态的方式运行,并失去了云原生设计的最重要的原则,即能够根据入站负载扩展和缩减应用程序工作者,并在当前节点出现故障后立即移动到新节点等。
随着我们变得更具体,我们发现我们再次处于*POSIX 与 REST API 的存储之争*中,但由于 Kubernetes 环境的分布式性质,POSIX 问题被进一步放大。具体来说,
- POSIX 太过繁琐:POSIX 语义要求每个操作都具有相关的元数据和文件描述符,这些描述符维护操作的状态。这会导致大量开销,而这些开销并没有增加任何实际价值。像 S3 API 这样的对象存储 API 摆脱了这些要求,允许应用程序发出并忘记调用。来自存储系统的响应表明操作是否成功。如果发生故障,应用程序可以重试。
- 网络限制: 在分布式系统中,多个应用程序尝试写入单个挂载是隐含的。因此,应用程序不仅要争夺带宽(将数据发送到挂载),存储系统本身也要在同一个网络上争夺带宽来将数据发送到实际驱动器。由于 POSIX 的繁琐性,网络调用的数量增加了几倍。另一方面,S3 API 允许在客户端到服务器和内部服务器调用之间明确隔离网络调用。
- 安全性:POSIX 安全模型是为人类用户而设计的,管理员为每个用户或组配置特定的访问级别。这使得它难以适应云原生世界。现代应用程序依赖于基于 API 的安全模型,该模型具有定义的访问策略、服务帐户、临时凭据等等。
- 可管理性: 有状态容器会增加管理开销。同步并行数据访问、确保数据一致性等需要仔细考虑数据访问模式。这意味着要安装、管理和配置更多软件,当然也需要额外的开发工作。
容器存储接口
虽然 CSI 在扩展 Kubernetes 卷层以支持第三方存储供应商方面做得很好,但它也不知不觉地导致了生态系统相信有状态容器方法是 Kubernetes 中推荐的存储方法。
CSI 是作为一种标准开发的,用于将任意块和文件存储系统暴露给 Kubernetes 上的传统应用程序。正如我们在本文中所看到的,有状态容器方法(及其当前形式的 CSI)有意义的唯一情况是应用程序本身是传统系统,无法添加对对象存储 API 的支持。
重要的是要理解,使用 CSI 的当前形式,即与现代应用程序的卷挂载,最终会导致我们一直在使用 POSIX 风格存储系统遇到的类似问题。
更好的方法
重要的是要理解,大多数应用程序本质上不是有状态的,也不是无状态的。它们的运行方式由整体架构和特定的设计选择决定。当然,也有一些存储应用程序需要是有状态的(例如 MinIO)。我们将在后面讨论有状态应用程序。
一般来说,应用程序数据可以分为几种类型
- 日志数据
- 时间戳数据
- 事务数据
- 元数据
- 容器镜像
- Blob 数据
所有这些数据类型在现代存储平台中都得到了很好的支持,并且有几个云原生平台可用于满足每种特定数据格式的需求。例如,事务数据和元数据可以存储在现代的云原生数据库中,例如 CockroachDB、YugaByte 等。容器镜像或 Blob 数据可以存储在基于 MinIO 的 Docker 镜像仓库中。时间戳数据可以存储在时间序列数据库中,例如 InfluxDB 等等。我们不会详细介绍每种数据类型和相关应用程序,但重要的是要避免基于本地挂载的持久化。

此外,在许多情况下,拥有一个可用于应用程序的临时缓存层作为暂存空间是有效的,但应用程序不应依赖该层作为事实来源。
有状态应用程序存储
虽然通常最好保持应用程序无状态,但存储应用程序(例如数据库、对象存储、键值存储)需要是有状态的。让我们了解这些应用程序如何在 Kubernetes 上部署。我将以 MinIO 为例,但类似的原则适用于所有主要的云原生存储系统。
云原生存储应用程序旨在利用容器带来的灵活性,这意味着这些应用程序不会对部署环境做出任何假设。例如,MinIO 使用内部擦除编码机制来确保系统中有足够的冗余,允许最多一半的驱动器发生故障。MinIO 还使用自己的哈希算法和服务器端加密来管理数据完整性和安全性。
对于此类云原生应用程序,本地持久卷 (PV) 最适合作为后端存储。本地 PV 提供原始存储容量,而运行在这些 PV 之上的应用程序使用自己的智能来扩展和管理不断增长的数据需求。
与基于 CSI 的 PV 相比,这是一种更简单、更可扩展的方法,因为 CSI 基于 PV 会带来自己的管理和冗余层,这些层通常会与有状态应用程序的设计相冲突。
向解耦的稳步前进
在这篇文章中,我们讨论了应用程序如何变得无状态,或者换句话说,将存储与计算解耦。现在,让我们看看这种趋势的一些现实世界的例子。
Spark,这个著名的数据分析平台,传统上以有状态的方式运行在面向 HDFS 的部署中,但随着它向云原生世界迁移,Spark 越来越多地在 Kubernetes 上使用 `s3a` 连接器以无状态方式运行。Spark 使用连接器将状态发送到其他系统,而 Spark 容器本身则完全无状态运行。大数据分析领域的其他主要企业参与者,如 Vertica、Teradata、Greenplum 正在向计算和存储解耦的模式发展。
同样,从 Presto、Tensorflow 到 R、Jupyter Notebook 的所有其他主要分析平台都遵循这种模式。将状态卸载到远程云存储系统可以使您的应用程序更易于扩展和管理。此外,它还有助于保持应用程序的可移植性,使其可以适应不同的环境。
不要只听我们说……
理解这些概念的最佳方法是自己尝试一下。如果您还没有运行 MinIO,请在此处下载 MinIO。 作为 100% 开源解决方案,您将获得我们最新和最强大的功能,没有任何保留。如果您想先进行一些研究,请查看我们的文档或加入我们的 Slack 频道,看看人们都在关注什么。