使用 Amazon 的 S3 连接器在 PyTorch 和 MinIO 中使用地图样式数据集

在深入了解 Amazon 的 PyTorch S3 连接器之前,有必要介绍一下它旨在解决的问题。许多 AI 模型需要在无法放入内存的数据上进行训练。此外,许多为计算机视觉和生成式 AI 构建的真正有趣的模型使用的数据甚至无法放入单个服务器附带的磁盘驱动器中。
解决存储问题很容易。如果您的数据集无法放入单个服务器,则需要与 S3 兼容的对象存储。在云中,这很可能就是 Amazon 的 S3 对象存储。对于本地模型训练,您将需要 MinIO。S3 兼容性非常重要,因为 S3 已成为非结构化数据的实际接口,而使用 S3 接口的解决方案将在工程师选择数据访问库时提供更多选择。
解决内存问题更具挑战性。您无需在训练管道开始时一次加载整个数据集,而是需要找出一种策略,以便在每次需要批处理数据进行训练时读取数据。一种常见的方法是在训练管道开始时加载对象路径列表,然后,当您遍历此路径列表时,检索每个对象以获取实际的对象数据。以下两个可视化显示了前加载与批量加载的详细信息。

在训练管道开始时检索整个数据集的训练管道
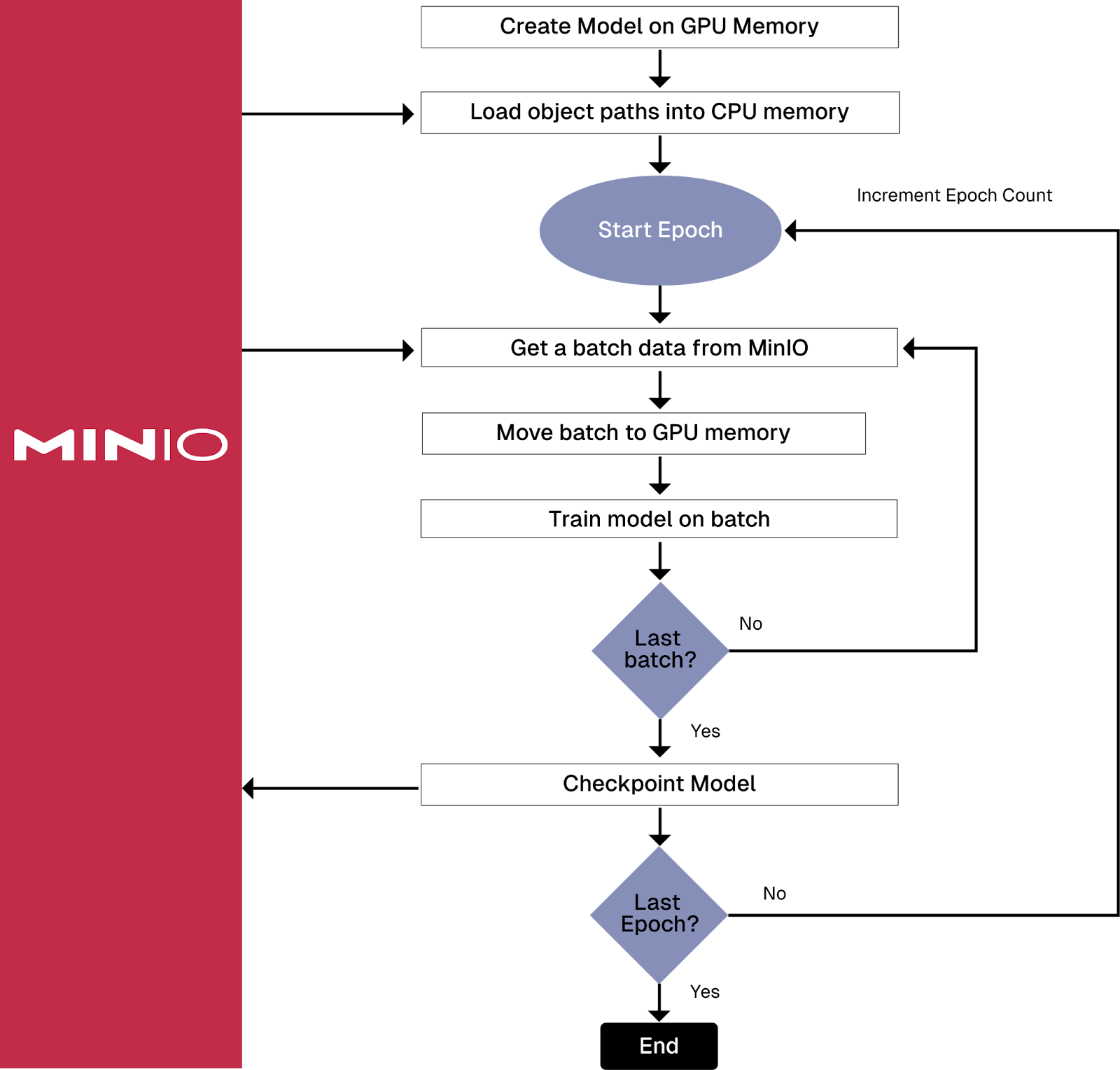
为每个批次从存储中检索数据的训练管道
如您所见,批量加载会给您的网络和存储解决方案带来更大的负担,这两者都需要快速运行。这是 Amazon 的 PyTorch S3 连接器解决的“大型数据集问题”的方法之一,它通过提高数据访问效率并减少需要编写的代码量来实现。
事实证明,之前也有人尝试解决大型数据集问题。让我们研究一下历史,并简要讨论一下在 Amazon 新连接器之前出现的库。许多这些库仍然可用,因此了解它们是什么非常重要,这样您就不会使用它们。
昨日的库
Amazon 于 2021 年 9 月宣布了 Amazon S3 PyTorch 插件。此插件从未作为真正的 Python 库进入 PyPI。相反,它可以通过 Amazon 的容器注册表获得,或者可以从其 GitHub 存储库安装。如果您今天导航到此帖子,您将看到一条建议使用 PyTorch S3 连接器的通知。
2023 年 7 月,PyTorch 宣布了 基于 CPP 的 S3 IO 数据管道。这个库看起来很有希望,因为它实现了 C++ 扩展(将其理解为它会非常快)并且具有列出和加载对象的类。列出 S3 存储桶中的对象有时可能会很慢,因此看起来 PyTorch 的开发人员走在了正确的道路上。原始公告仍然存在,没有警告,但是如果您导航到 S3 IO 数据管道文档 的 GitHub 页面,您将看到弃用警告并建议使用 PyTorch S3 连接器。 用户文档 中也有类似的警告。
既然我们知道不应该使用什么,那么让我们看看 PyTorch S3 连接器。
介绍 PyTorch S3 连接器
2023 年 11 月,Amazon 宣布了 PyTorch S3 连接器。Amazon PyTorch S3 连接器提供了 PyTorch 的 数据集原语(数据集和数据加载器)的实现,这些原语专为 S3 对象存储而构建。它支持 映射式数据集 以实现随机数据访问模式,以及 可迭代式数据集 以实现流式顺序数据访问模式。在这篇文章中,我将重点介绍映射式数据集。在以后的文章中,我将介绍可迭代式数据集。此外,此连接器的文档仅显示了从 Amazon S3 加载数据的示例 - 我将向您展示如何针对 MinIO 使用它。
PyTorch S3 连接器还包括一个检查点接口,可以直接将检查点保存和加载到 S3 存储桶中,而无需先保存到本地存储。这是一个非常好的功能——如果您尚未准备好采用正式的 MLOps 工具,并且只需要一种简单的方法来保存您的模型。我也将在以后的文章中介绍此功能。
仅仅为了好玩,让我们手动构建一个映射式数据集。如果您需要连接到与 S3 不兼容的数据源,则需要使用此技术。
手动构建映射式数据集
一个 映射式数据集 是通过实现一个类来创建的,该类覆盖了 PyTorch 的 Dataset 基类的 __getitem__() 和 __len__() 方法。一旦实例化,单个样本就会映射到索引或键。下面的代码显示了如何覆盖这些方法。它使用 MinIO SDK 手动检索存储的对象并对其应用转换。完整的代码下载可以在这里找到 这里。
请注意此类的两个方面。首先,在实例化时,它接收的是 S3 路径列表,而不是 S3 对象列表。以下函数用于此帖子的代码下载中,以获取存储桶中对象的列表。
其次,每次请求单个样本时,都会建立与数据源 MinIO 的连接以检索样本。换句话说,对于数据集中的每个对象,都会发出网络请求。以下代码片段展示了如何实例化此类并使用数据集对象创建 Dataloader。
最后,下面的代码片段是一个简化的训练循环,展示了如何使用这个数据加载器。突出显示的代码是批处理循环的开始。只要 for 循环产生并返回一批 ImageDatasetMap 对象,就会发生 IO 操作。此时,所有 **__getitem__()** 方法都将被调用。这会导致对 MinIO 的调用以检索对象数据。例如,如果您的批次大小设置为 200,则此循环的每次迭代都将导致 200 次网络调用以检索当前训练批次所需的 200 个样本。
上述代码使您的训练循环受限于IO操作。如果您的数据集太大,无法在训练流水线的开始阶段加载到内存中,并且每个样本都是一个独立的对象,那么这是在模型训练期间访问数据集的最佳选择。
将S3连接器连接到MinIO
将S3连接器连接到MinIO就像设置环境变量一样简单。之后,一切都会正常工作。诀窍是以正确的方式设置正确的环境变量。
此帖子的代码下载使用.env文件来设置环境变量,如下所示。此文件还显示了我用于使用MinIO Python SDK直接连接到MinIO的环境变量。请注意,AWS_ENDPOINT_URL需要协议,而MinIO变量不需要。此外,您可能会注意到AWS_REGION变量的一些奇怪行为。从技术上讲,访问MinIO时不需要它,但如果您为该变量选择错误的值,则S3连接器中的内部检查可能会失败。如果您遇到此类错误,请仔细阅读消息并指定其请求的值。
使用 S3 连接器创建 Map 样式数据集
要使用 S3 连接器创建 map 样式数据集,您无需像上一节中那样编写代码并创建类。**S3MapDataset.from_prefix()** 函数将为您完成所有操作。此函数假定您已设置连接到 S3 对象存储的环境变量,如上一节所述。它还要求您的对象可以通过 S3 前缀找到。下面显示了一个使用此函数的代码片段。
请注意,URI 是一个 S3 路径。mnist/train 路径下可以递归找到的每个对象都应该属于训练集的一部分。上面的函数还需要一个转换,将您的对象转换为张量并确定标签。这是通过下面显示的可调用类的实例完成的。
这就是使用 PyTorch 的 S3 连接器创建映射式数据集所需做的全部操作。
结论
PyTorch 的 S3 连接器易于使用,工程师在使用它时将编写更少的的数据访问代码。在这篇文章中,我展示了如何使用环境变量将其配置为连接到 MinIO。配置完成后,三行代码创建了一个数据集对象,并且数据集对象使用一个简单的可调用类进行了转换。
高速存储和高速数据访问与高速计算相辅相成。PyTorch 的 S3 连接器明确构建用于高效的 S3 访问,并且由为我们提供 S3 的公司编写。
最后,如果您的网络是训练管道中最薄弱的环节,请考虑创建包含多个样本的对象,您甚至可以对其进行 tar 或 zip 压缩。迭代式数据集专为这些场景而设计。我关于 PyTorch 的 S3 连接器的下一篇文章将介绍此技术。
如果您有任何疑问,请务必通过 Slack 与我们联系。