MinIO 和 Apache Tika:文本提取模式

TL;DR
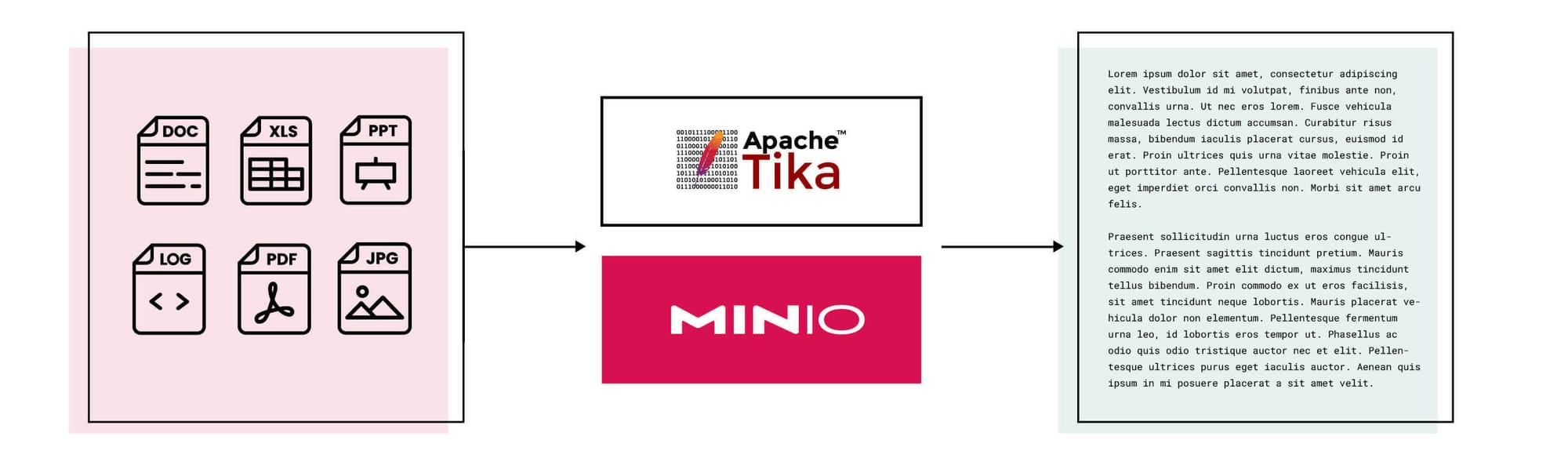
这篇文章将使用 MinIO Bucket Notifications 和 Apache Tika 进行文档文本提取,这是关键下游任务的核心,例如大型语言模型 (LLM) 训练和检索增强生成 (RAG)。
前提
假设我们想构建一个文本数据集,然后可以用它来微调一个 LLM。为此,我们首先需要收集各种文档(由于来源不同,这些文档可能具有不同的格式),并从中提取文本。数据集安全性和可审计性至关重要,因此这些非结构化文档需要存储在对象存储中以进行匹配。MinIO 是为这些情况以及更多情况而构建的对象存储。另一方面,Apache Tika 是一种工具包,“可以检测和提取来自超过 1000 种不同文件类型的元数据和文本(例如 PPT、XLS 和 PDF)。” 它们共同构成一个可以实现目标的系统。
在之前的一篇文章中,我们构建了一个带有 MinIO 的对象检测推理服务器,它开箱即用,并且大约有 30 行代码。我们将在文本提取任务中再次利用这种高度可移植且可重复的架构。以下是我们将构建的系统的粗略描述。
设置 Apache Tika
使 Apache Tika 运行起来的最简单方法是使用官方 Docker 镜像。查看 Docker Hub 获取所需的 Tika 镜像版本/标签。
在本例中,允许它使用和公开默认端口 9998。
docker pull apache/tika:<version>
docker run -d -p 127.0.0.1:9998:9998 apache/tika:<version>使用 docker ps 或 Docker Desktop 验证 Tika 容器是否正在运行以及是否已公开端口 9998。
构建文本提取服务器
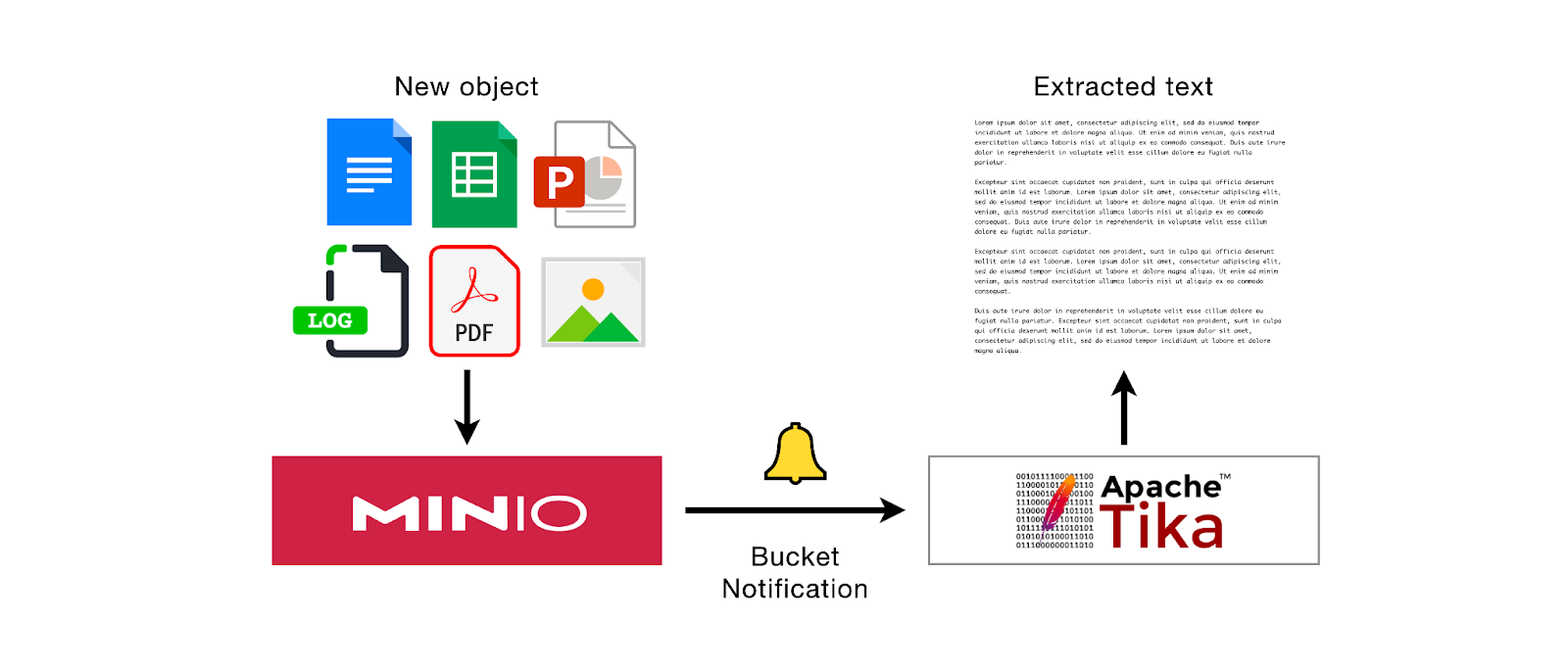
现在 Tika 正在运行,我们需要构建一个服务器,该服务器可以以编程方式针对新对象发出 Tika 提取请求。之后,我们需要在 MinIO 存储桶上配置 Webhook,以使该服务器能够收到关于新对象到达的通知(换句话说,存储桶的 PUT 事件)。让我们一步步进行。
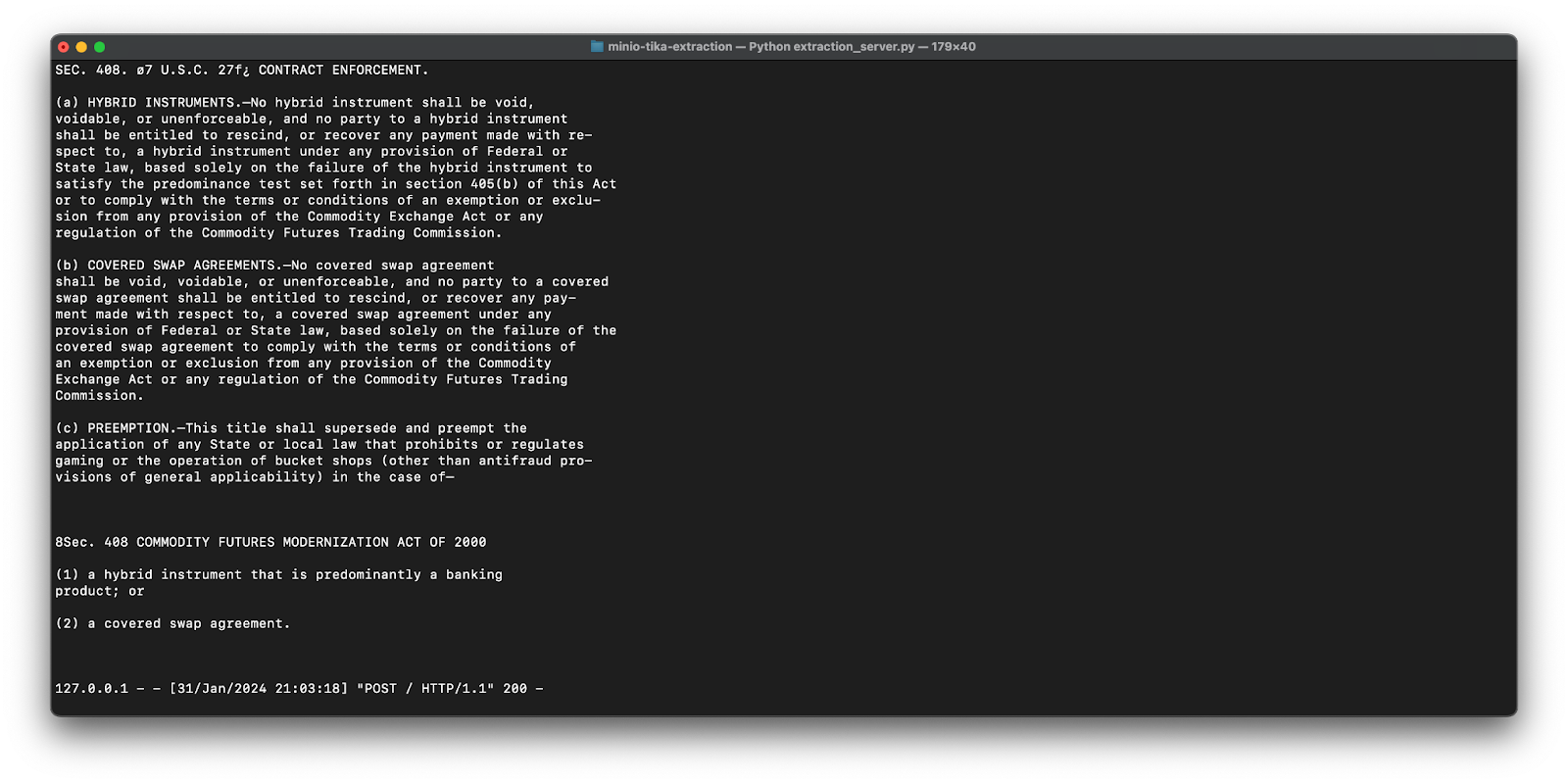
为了保持相对简单,并突出显示此方法的可移植性,文本提取服务器将使用流行的 Flask 框架用 Python 构建。以下是服务器的代码(也位于 MinIO 博客资源库中的 extraction_server.py 下),该代码使用 Tika(通过 Tika-Python)对添加到存储桶的新文档执行文本提取。
"""
This is a simple Flask text extraction server that functions as a webhook service endpoint
for PUT events in a MinIO bucket. Apache Tika is used to extract the text from the new objects.
"""
from flask import Flask, request, abort, make_response
import io
import logging
from tika import parser
from minio import Minio
# Make sure the following are populated with your MinIO details
# (Best practice is to use environment variables!)
MINIO_ENDPOINT = ''
MINIO_ACCESS_KEY = ''
MINIO_SECRET_KEY = ''
# This depends on how you are deploying Tika (and this server):
TIKA_SERVER_URL = 'https://:9998/tika'
client = Minio(
MINIO_ENDPOINT,
access_key=MINIO_ACCESS_KEY,
secret_key=MINIO_SECRET_KEY,
)
logger = logging.getLogger(__name__)
app = Flask(__name__)
@app.route('/', methods=['POST'])
async def text_extraction_webhook():
"""
This endpoint will be called when a new object is placed in the bucket
"""
if request.method == 'POST':
# Get the request event from the 'POST' call
event = request.json
bucket = event['Records'][0]['s3']['bucket']['name']
obj_name = event['Records'][0]['s3']['object']['key']
obj_response = client.get_object(bucket, obj_name)
obj_bytes = obj_response.read()
file_like = io.BytesIO(obj_bytes)
parsed_file = parser.from_buffer(file_like.read(), serverEndpoint=TIKA_SERVER_URL)
text = parsed_file["content"]
metadata = parsed_file["metadata"]
logger.info(text)
result = {
"text": text,
"metadata": metadata
}
resp = make_response(result, 200)
return resp
else:
abort(400)
if __name__ == '__main__':
app.run()
让我们启动提取服务器
记下 Flask 应用程序运行的主机名和端口。
设置存储桶通知
现在,剩下的就是配置 MinIO 服务器上存储桶的 Webhook,以便存储桶中的任何 PUT 事件(即添加的新对象)都会触发对提取端点的调用。使用 mc 工具,我们只需几个命令即可做到这一点。
首先,我们需要设置一些环境变量,以便向 MinIO 服务器发出信号,表明您正在启用 Webhook 以及要调用的相应端点。将 <YOURFUNCTIONNAME> 替换为您选择的函数名称。为简单起见,我使用了 ‘extraction.’ 另外,请确保端点环境变量设置为推理服务器的正确主机和端口。在本例中,Flask 应用程序正在运行的地址是 https://:5000。
export MINIO_NOTIFY_WEBHOOK_ENABLE_<YOURFUNCTIONNAME>=on
export MINIO_NOTIFY_WEBHOOK_ENDPOINT_<YOURFUNCTIONNAME>=https://:5000设置完这些环境变量后,启动 MinIO 服务器(如果它已经在运行,请重启它)。在接下来的步骤中,我们将需要您 MinIO 服务器部署的“别名”。要了解有关别名以及如何设置别名的更多信息,请查看 文档。我们还将使用 mc(MinIO 客户端命令行工具),因此请确保您已安装它。
接下来,让我们配置存储桶的事件通知以及我们要收到的通知类型。为了这个项目的目的,我创建了一个新的存储桶,也名为“extraction”。您可以通过MinIO 控制台或 mc 命令 来执行此操作。 由于我们想在将新对象添加到“extraction”存储桶时触发 Webhook,因此我们将重点关注 PUT 事件。将 ALIAS 替换为您 MinIO 服务器部署的别名,并将 BUCKET 替换为该服务器上的目标存储桶。和之前一样,请确保将 <YOURFUNCTIONNAME> 替换为您在之前步骤中使用的相同值。
mc event add ALIAS/BUCKET arn:minio:sqs::<YOURFUNCTIONNAME>:webhook --event put
最后,您可以通过运行此命令并检查是否输出了 s3:ObjectCreated:* 来验证是否已为存储桶通知配置了正确的事件类型
mc event ls ALIAS/BUCKET arn:minio:sqs::<YOURFUNCTIONNAME>:webhook
如果您想了解有关将存储桶事件发布到 Webhook 的更多信息,请查看文档 以及此 关于事件通知的深入分析。现在,我们已经准备好试用我们的文本提取服务器。
试用它
这是一个我想从中提取文本的文档。它是一个2000 年商品期货现代化法案的 PDF 文件,这是美国的一项有影响力的金融立法。

我使用 MinIO 控制台将此 PDF 文件放在我的“extraction”存储桶中。
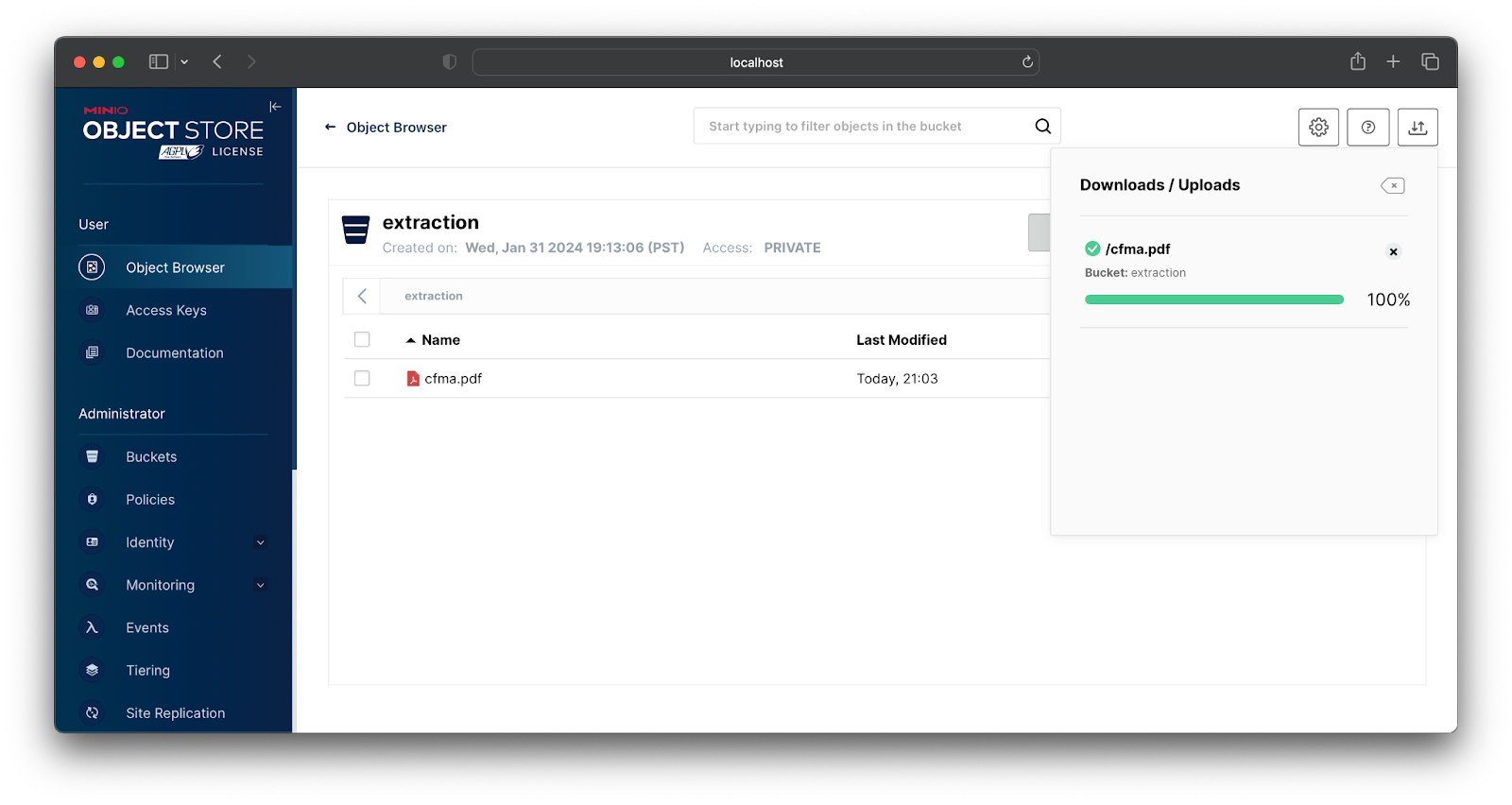
此 PUT 事件会触发存储桶通知,然后将其发布到提取服务器端点。因此,Tika 会提取文本并将其打印到控制台。
后续步骤
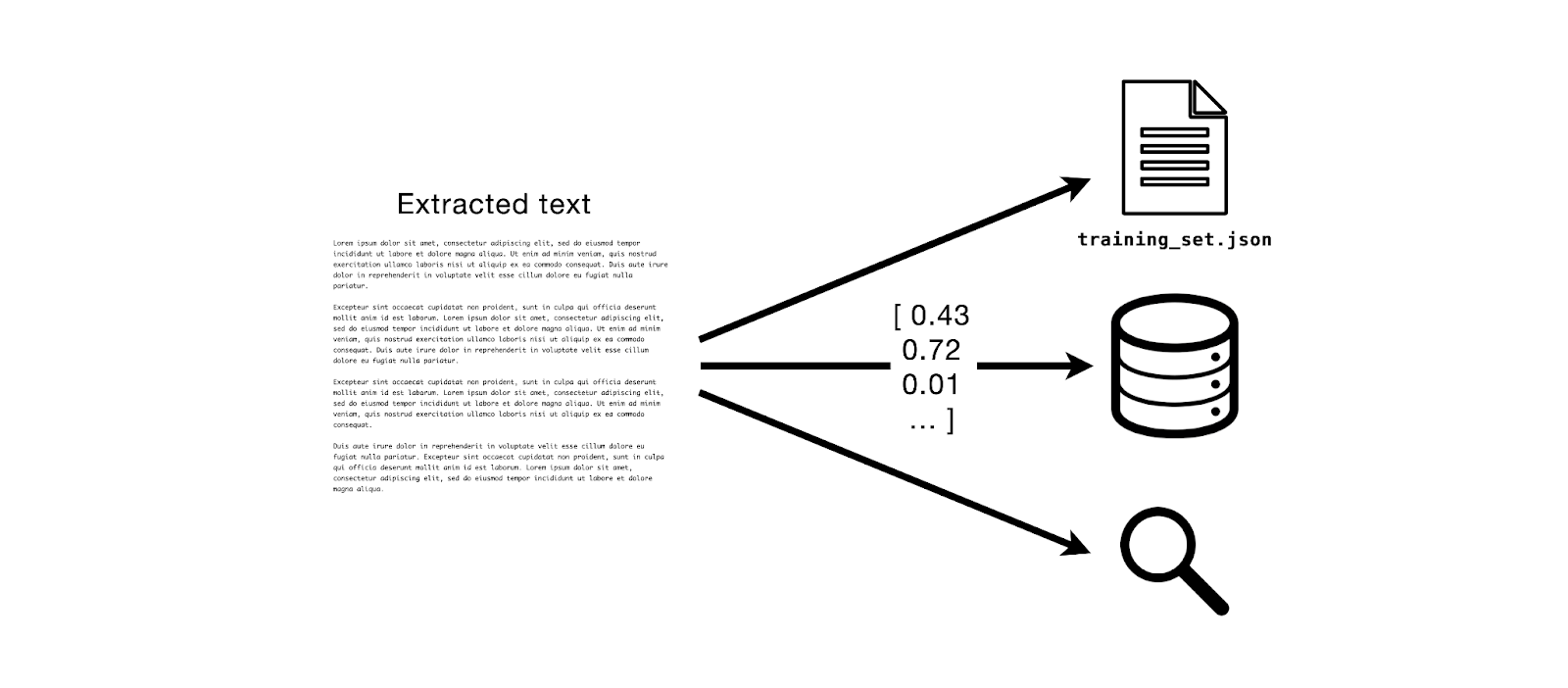
虽然我们现在只是打印出提取的文本,但正如“前提”中所暗示的那样,该文本可用于许多下游任务。例如:
- 为 LLM 微调创建数据集:假设您想在一个包含各种文件格式(即 PDF、DOCX、PPTX、Markdown 等)的企业文档集合上微调一个大型语言模型。要为该任务创建 LLM 友好的文本数据集,您可以将所有这些文档收集到一个 MinIO 存储桶中,该存储桶配置了类似的 Webhook,并将每个文档的提取文本传递到微调/训练集的数据帧中。此外,通过将数据集的源文件保存在 MinIO 上,管理、审计和跟踪数据集组成变得更加容易。
- 检索增强生成:RAG 是一种方法,LLM 应用程序可以使用它来利用精确的上下文并避免幻觉。该方法的核心方面是确保可以提取文档的文本,然后将其嵌入向量中,从而实现语义搜索。此外,将这些向量的实际源文档存储在对象存储(如 MinIO!)中通常是最佳做法。使用本文中概述的方法,您可以轻松实现这两者。如果您想了解有关 RAG 及其优势的更多信息,请查看此之前的一篇文章。
- LLM 应用程序: 通过一种可以立即提取新存储文档文本的编程方式,可能性是无限的,尤其是在您可以利用 LLM 的情况下。想想关键字检测(例如,提示:“提到了哪些股票代码?”)、内容评估(例如,提示:“根据评分标准,此论文提交应该得多少分?”)或几乎所有类型的基于文本的分析(例如,提示:“根据此日志输出,第一个错误何时发生?”)。
除了存储桶通知对这些任务的实用性之外,MinIO 还旨在为任何类型和数量的对象提供世界级的容错能力和性能,无论它们是 PowerPoint、图像还是代码片段。
如果您有任何疑问,请加入我们的Slack 频道 或给我们发送邮件至hello@min.io。我们随时为您提供帮助。