使用 MinIO S3 存储桶备份 Weaviate

Weaviate 是一款开创性的开源向量数据库,旨在通过利用机器学习模型来增强语义搜索。与依赖关键字匹配的传统搜索引擎不同,Weaviate 采用语义相似性原理。这种创新方法将各种形式的数据(文本、图像等)转换为向量表示,即捕获数据上下文和含义本质的数值形式。通过分析这些向量之间的相似性,Weaviate 提供的搜索结果真正理解了用户的意图,在关键字搜索的局限性之上取得了显著的进步。
本指南旨在展示 **MinIO** 和 **Weaviate** 的无缝集成,利用 Kubernetes 原生对象存储和 AI 驱动的语义搜索功能的最佳优势。本指南利用 **Docker Compose** 进行容器编排,提供了一种构建健壮、可扩展且高效的数据管理系统的战略方法。该设置的目标是说明我们如何存储、访问和管理数据,对于希望利用现代存储解决方案和 AI 驱动的 数据检索功能的开发人员、DevOps 工程师和数据科学家来说,这是一次颠覆性的改变。
技术堆栈介绍
在本演示中,我们将重点关注 *使用 Docker 将 Weaviate 备份到 MinIO 存储桶*。这种设置确保了我们 AI 增强型搜索和分析项目中的数据完整性和可访问性。
- **MinIO 存储:** 我们使用 MinIO 作为我们的主要存储平台。MinIO 以其高性能和可扩展性而闻名,它擅长安全高效地处理大量数据。在本演示中,您将看到如何使用 MinIO 存储桶备份 Weaviate 数据,确保我们系统 的完整性和性能不受影响。
- **Weaviate 向量数据库:** 作为该集成的核心,Weaviate 的向量数据库通过其执行语义搜索的能力赋能 AI 应用程序。通过将非结构化数据转换为有意义的向量表示,它使应用程序能够以深刻细致的方式理解和与数据交互,为更智能和更具响应性的 AI 驱动功能铺平道路。
本演示旨在突出使用 Docker 无缝集成 MinIO 和 Weaviate,展示一种可靠的方法来备份 AI 增强型搜索和分析系统。
资源
- 所有文件都可通过 GitHub minio/blog-assets/minio-weaviate-backups 存储库文件夹获取。
- docker-compose.yaml
- schema.json
- data.json
- s3_backup_module.ipynb
必要的先决条件
- 您的机器上安装了 Docker 和 Docker Compose。
- 对 Docker 概念和 YAML 语法的基本了解。
- 用于使用 weaviate-client 库的 Python 环境。
- 用于运行诸如 curl 之类的命令的命令行访问权限。
与 Docker Compose 的集成和配置
此处提供的 docker-compose.yaml 文件旨在为 Weaviate 建立无缝设置,突出我们对简化和高效数据管理的承诺。此配置使能够创建一个健壮的环境,其中 MinIO 充当安全的存储服务,而 Weaviate 利用此存储服务来实现高级向量搜索功能。
下面提供的 docker-compose.yaml 概述了 Weaviate 的设置。
version: '3.8'
services:
weaviate:
container_name: weaviate_server
image: semitechnologies/weaviate:latest
ports:
- "8080:8080"
environment:
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
ENABLE_MODULES: 'backup-s3'
BACKUP_S3_BUCKET: 'weaviate-backups'
BACKUP_S3_ENDPOINT: 'play.min.io:443'
BACKUP_S3_ACCESS_KEY_ID: 'minioadmin'
BACKUP_S3_SECRET_ACCESS_KEY: 'minioadmin'
BACKUP_S3_USE_SSL: 'true'
CLUSTER_HOSTNAME: 'node1'
volumes:
- ./weaviate/data:/var/lib/weaviateDocker-Compose: 使用 backups-s3 模块启用和 play.min.io MinIO 服务器部署 Weaviate
配置 Weaviate 以进行 S3 备份
使用上述 docker-compose.yaml,Weaviate 经过精心配置以利用 MinIO 进行备份,从而确保数据完整性和可访问性。此设置涉及必要的环境变量,例如 ENABLE_MODULES 设置为 backup-s3,以及 S3 存储桶、端点、访问密钥和 SSL 使用的各种设置。此外,PERSISTENCE_DATA_PATH 设置为确保数据持久存储,以及 CLUSTER_NAME 用于节点标识。
值得注意的环境变量包括:
ENABLE_MODULES: 'backup-s3'BACKUP_S3_BUCKET: 'weaviate-backups'BACKUP_S3_ENDPOINT: 'play.min.io:443'BACKUP_S3_ACCESS_KEY_ID: 'minioadmin'BACKUP_S3_SECRET_ACCESS_KEY: 'minioadmin'BACKUP_S3_USE_SSL: 'true'PERSISTENCE_DATA_PATH: '/var/lib/weaviate'CLUSTER_NAME: 'node1'
此 docker-compose 中的 Weaviate 服务被设置为利用挂载卷进行数据持久化;这确保了您的数据在会话和操作之间持续存在。
注意:MinIO 存储桶需要事先存在,Weaviate 不会为您创建存储桶。
部署步骤
要使用 Docker Compose 将 MinIO 和 Weaviate 集成到您的项目中,请按照此详细步骤操作
保存或更新 Docker Compose 文件
- 全新设置:如果这是一个全新设置,请直接将提供的 docker-compose.yaml 文件保存到您项目的工作目录中。此文件对于正确配置服务至关重要。
- 现有设置:如果您正在更新现有的生产环境,请修改当前的 docker-compose.yaml 以反映上述设置。确保这些设置被准确地复制以连接到您的服务。
运行 Docker Compose 文件
一旦 docker-compose.yaml 文件就位,请在您的终端或命令提示符中使用以下命令启动部署
docker-compose up -d --build
此命令将在分离模式下启动 Weaviate 服务,并在您系统的后台运行它们。
了解持久目录
- 在构建和执行过程中,Docker Compose 将创建一个持久目录,如 docker-compose.yaml 文件中所指定。此目录(
./weaviate/data用于 Weaviate)用于持久存储数据,确保您的数据在容器重启和部署之间保持完整。
持久存储使能够创建一个更稳定的环境,其中数据在容器重启时不会丢失。
部署完 docker-compose 后,您可以在浏览器中访问 Weaviate 服务器的 URL,然后输入 /v1/meta 来检查您的部署配置是否正确。
https://:8080/v1/meta 上的 JSON 负载的第一行应如下所示
{"hostname":"http://[::]:8080","modules":{"backup-s3":{"bucketName":"weaviate-backups","endpoint":"play.min.io:443","useSSL":true}...[truncated]...}配置 MinIO:weaviate-backups 存储桶的访问策略
要将 Weaviate 与 MinIO 集成,您需要将 MinIO 中指定备份存储桶(即 weaviate-backups)的访问策略设置为公开。这种调整对于授予 Weaviate 备份-s3 模块必要的权限以成功与 MinIO 存储桶交互以进行备份操作至关重要。
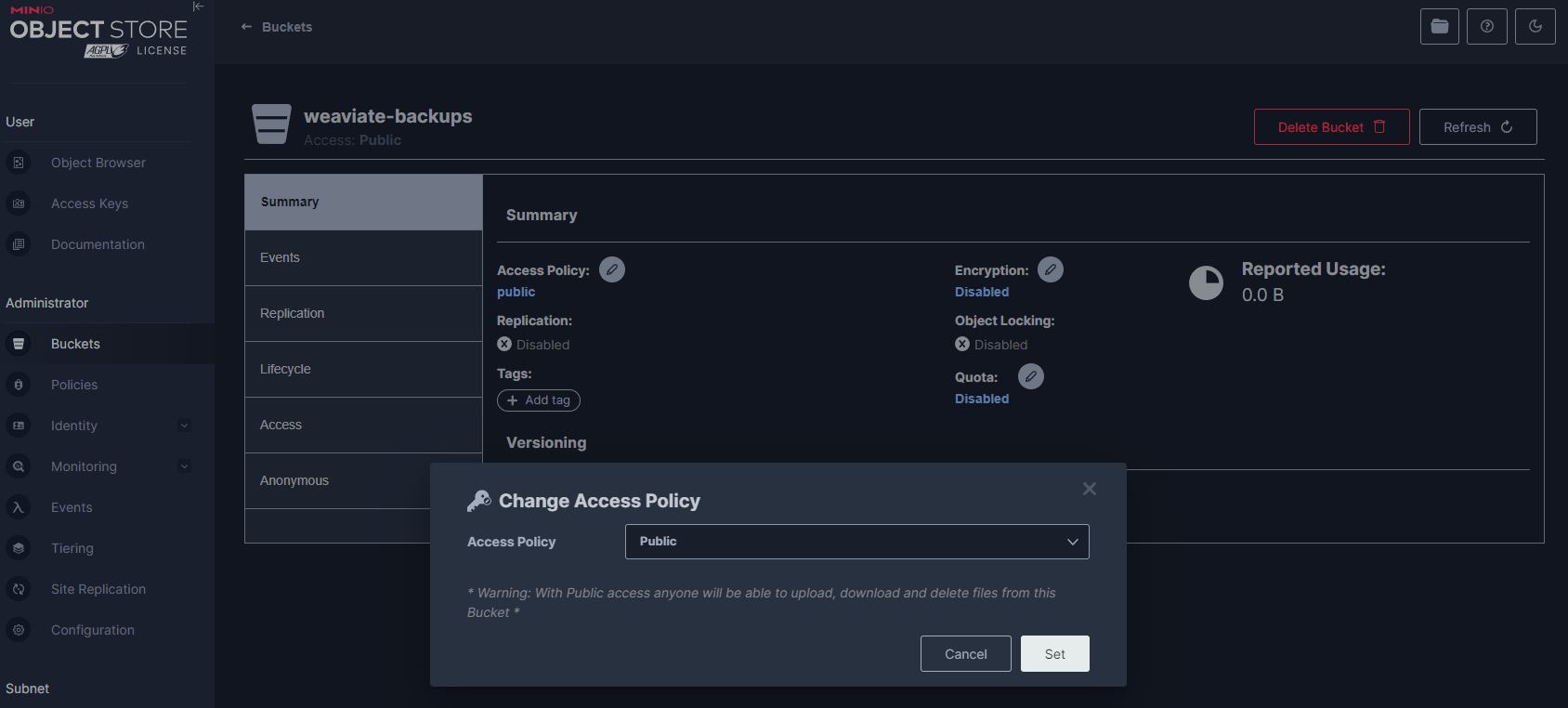
weaviate-backups 存储桶的访问策略注意:在生产环境中,您可能需要将其锁定,这超出了本教程的范围。
在进行此配置时,务必清楚地了解将存储桶设置为“公开”的安全含义。虽然此设置在开发环境中促进了备份过程,但应考虑在生产系统中使用其他方法来维护数据安全性和完整性。使用细粒度访问控制,例如 IAM 策略或“预签名”URL。
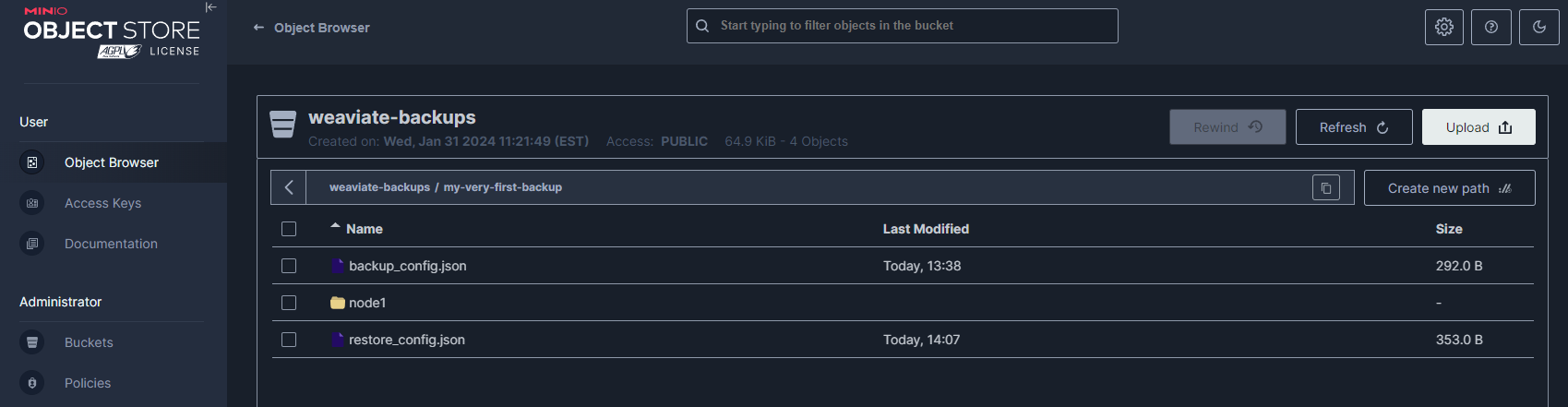
weaviate-backups 存储桶在本演示结束时,您将能够看到 Weaviate 在使用 backup-s3 模块时在整个过程中创建的存储桶对象。
使用 Python 概述流程
要在 Weaviate 中启用 S3 备份,请在您的 docker-compose.yaml 文件中设置必要的环境变量。这将指示 Weaviate 使用 MinIO 作为备份目标,包括备份模块设置和 MinIO 存储桶详细信息。
在深入技术操作之前,我想说明我在 JupyterLab 环境中演示以下步骤,为了便于将我们的管道封装在笔记本中,该笔记本可在此获取。
第一步是使用 pip 安装 weaviate-client 库来设置环境。此 Python 包对于以更 Pythonic 的方式与 Weaviate 的 RESTful API 交互至关重要,使能够无缝地与数据库进行交互以执行诸如模式创建、数据索引、备份和恢复等操作。在本演示中,我们将说明如何使用 Weaviate Python 客户端库。
在本演示中,我们使用 Weaviate V3 API,因此在运行 Python 脚本时,您可能会看到如下所示的消息
|
`DeprecationWarning: Dep016: 您正在使用已弃用的 Weaviate v3 客户端。 |
本消息为警告提示,可以忽略,更多信息可访问此文章了解 Weaviate 博客。
Python 步骤概述:
- 安装 weaviate-client 库
- 客户端初始化
- 创建模式
- 数据插入
- 启动备份
- 数据恢复
1. 安装 Weaviate-Client 库
!pip install weaviate-client2. 导入文章和作者模式类
本节介绍了“文章”和“作者”类的 数据结构和模式,为数据组织方式奠定了基础。它展示了如何在 Weaviate 中以编程方式定义和管理模式,突出了 Weaviate 灵活性和强大的功能,可以适应针对特定应用程序需求量身定制的各种数据模型。
import weaviate
client = weaviate.Client("https://:8080")
# Schema classes to be created
schema = {
"classes": [
{
"class": "Article",
"description": "A class to store articles",
"properties": [
{"name": "title", "dataType": ["string"], "description": "The title of the article"},
{"name": "content", "dataType": ["text"], "description": "The content of the article"},
{"name": "datePublished", "dataType": ["date"], "description": "The date the article was published"},
{"name": "url", "dataType": ["string"], "description": "The URL of the article"},
{"name": "customEmbeddings", "dataType": ["number[]"], "description": "Custom vector embeddings of the article"}
]
},
{
"class": "Author",
"description": "A class to store authors",
"properties": [
{"name": "name", "dataType": ["string"], "description": "The name of the author"},
{"name": "articles", "dataType": ["Article"], "description": "The articles written by the author"}
]
}
]
}
client.schema.delete_class('Article')
client.schema.delete_class('Author')
client.schema.create(schema)Python:创建模式类
3. 模式和数据的设置
在定义模式后,笔记本指导您初始化 Weaviate 客户端,在 Weaviate 实例中创建模式并索引数据。此过程使用初始数据集填充数据库,使您能够探索 Weaviate 的矢量搜索功能。它说明了开始使用 Weaviate 来存储和查询矢量化格式数据的实际步骤。
# JSON data to be Ingested
data = [
{
"class": "Article",
"properties": {
"title": "LangChain: OpenAI + S3 Loader",
"content": "This article discusses the integration of LangChain with OpenAI and S3 Loader...",
"url": "https://blog.min-io.cn/langchain-openai-s3-loader/",
"customEmbeddings": [0.4, 0.3, 0.2, 0.1]
}
},
{
"class": "Article",
"properties": {
"title": "MinIO Webhook Event Notifications",
"content": "Exploring the webhook event notification system in MinIO...",
"url": "https://blog.min-io.cn/minio-webhook-event-notifications/",
"customEmbeddings": [0.1, 0.2, 0.3, 0.4]
}
},
{
"class": "Article",
"properties": {
"title": "MinIO Postgres Event Notifications",
"content": "An in-depth look at Postgres event notifications in MinIO...",
"url": "https://blog.min-io.cn/minio-postgres-event-notifications/",
"customEmbeddings": [0.3, 0.4, 0.1, 0.2]
}
},
{
"class": "Article",
"properties": {
"title": "From Docker to Localhost",
"content": "A guide on transitioning from Docker to localhost environments...",
"url": "https://blog.min-io.cn/from-docker-to-localhost/",
"customEmbeddings": [0.4, 0.1, 0.2, 0.3]
}
}
]
for item in data:
client.data_object.create(
data_object=item["properties"],
class_name=item["class"]
)Python:按类索引数据
4. 创建备份
在索引数据后,重点转移到通过备份保留数据库状态。笔记本的这部分展示了如何触发对 MinIO 的备份操作。
result = client.backup.create(
backup_id="backup-id",
backend="s3",
include_classes=["Article", "Author"], # specify classes to include or omit this for all classes
wait_for_completion=True,
)
print(result)Python:创建备份
预期
{'backend': 's3', 'classes': ['Article', 'Author'], 'id': 'backup-id-2', 'path': 's3://weaviate-backups/backup-id-2', 'status': 'SUCCESS'}成功备份响应
5. 删除模式类以进行恢复
在继续进行恢复之前,有时需要清除现有模式。本节展示了用于清洁恢复过程的步骤。这确保了恢复的数据不会与数据库中现有的模式或数据发生冲突。
client.schema.delete_class("Article")
client.schema.delete_class("Author")6. 恢复备份
本节解释了如何恢复先前备份的数据,使数据库恢复到已知正常状态。
result = client.backup.restore(
backup_id="backup-id",
backend="s3",
wait_for_completion=True,
)
print(result)Python:恢复备份
预期
{'backend': 's3', 'classes': ['Article', 'Author'], 'id': 'backup-id', 'path': 's3://weaviate-backups/backup-id', 'status': 'SUCCESS'}成功备份-S3 响应
恢复期间的错误处理
笔记本的这部分提供了在备份恢复过程中实施错误处理的示例。它提供了对数据恢复操作期间意外问题的见解。
from weaviate.exceptions import BackupFailedError
try:
result = client.backup.restore(
backup_id="backup-id",
backend="s3",
wait_for_completion=True,
)
print("Backup restored successfully:", result)
except BackupFailedError as e:
print("Backup restore failed with error:", e)
# Here you can add logic to handle the failure, such as retrying the operation or logging the error.预期
Backup restored successfully: {'backend': 's3', 'classes': ['Author', 'Article'], 'id': 'backup-id', 'path': 's3://weaviate-backups/backup-id', 'status': 'SUCCESS'}成功备份恢复
验证恢复成功
最后,为了确认备份和恢复过程已成功完成,笔记本包含一个步骤来检索“文章”类的模式。此验证确保数据和模式已正确恢复。
client.schema.get("Article")将“文章”类作为 JSON 对象返回
预期
{'class': 'Article', 'description': 'A class to store articles'... [Truncated]...}笔记本的每个部分都提供了一个全面的指南,涵盖了 Weaviate 中数据管理的生命周期,从初始设置和数据填充到备份、恢复和验证,所有这些都在 Python 生态系统中使用 Weaviate-client 库完成。
使用 curl 概述流程
到目前为止,我们向您展示了如何使用 Pythonic 方式完成此操作。我们认为,展示通过 CURL 内部如何实现相同操作将很有帮助,而无需编写脚本。
为了与 Weaviate 实例交互以执行创建模式、索引数据、执行备份和恢复数据等任务,可以使用特定的 curl 命令。这些命令对 Weaviate 的 REST API 发出 HTTP 请求。例如,要创建模式,将使用模式详细信息向 Weaviate 的模式端点发送 POST 请求。同样,要索引数据,将使用数据有效负载向对象端点发送 POST 请求。
备份是通过向备份端点发送 POST 请求触发的,恢复是通过向恢复端点发送 POST 请求完成的。这些操作中的每一个都需要相应的 JSON 有效负载,通常在 curl 命令中使用 @ 符号作为文件引用提供。
为了实现 Weaviate,我们当然需要使用示例数据来进行操作,这些数据
我已经包含了以下内容
schema.json概述了我们要索引的数据的结构。data.json是我们实际数据发挥作用的地方,其结构与 schema.json 文件中的类一致。
schema.json 和 data.json 文件位于 MinIO 的 blog-assets 存储库中,您可以 在这里找到它们。
schema.json
{
"classes": [
{
"class": "Article",
"description": "A class to store articles",
"properties": [
{"name": "title", "dataType": ["string"], "description": "The title of the article"},
{"name": "content", "dataType": ["text"], "description": "The content of the article"},
{"name": "datePublished", "dataType": ["date"], "description": "The date the article was published"},
{"name": "url", "dataType": ["string"], "description": "The URL of the article"},
{"name": "customEmbeddings", "dataType": ["number[]"], "description": "Custom vector embeddings of the article"}
]
},
{
"class": "Author",
"description": "A class to store authors",
"properties": [
{"name": "name", "dataType": ["string"], "description": "The name of the author"},
{"name": "articles", "dataType": ["Article"], "description": "The articles written by the author"}
]
}
]
}文章和作者的示例模式类
schema.json 文件概述了要索引数据的结构,详细说明了类、属性及其数据类型,有效地为数据在 Weaviate 中的组织和交互方式奠定了基础。此模式充当人工智能的蓝图,用于理解和分类传入的数据,确保矢量搜索引擎能够以精确和相关的方式运行。
另一方面,data.json 文件使用实际数据实例填充此模式,反映了现实世界的应用程序和场景。此示例数据说明了 Weaviate 搜索功能的潜力,提供了一个实践体验,展示了如何解析查询以及如何根据人工智能对内容的理解动态生成结果。
data.json
[
{
"class": "Article",
"properties": {
"title": "LangChain: OpenAI + S3 Loader",
"content": "This article discusses the integration of LangChain with OpenAI and S3 Loader...",
"url": "https://blog.min-io.cn/langchain-openai-s3-loader/",
"customEmbeddings": [0.4, 0.3, 0.2, 0.1]
}
},
{
"class": "Article",
"properties": {
"title": "MinIO Webhook Event Notifications",
"content": "Exploring the webhook event notification system in MinIO...",
"url": "https://blog.min-io.cn/minio-webhook-event-notifications/",
"customEmbeddings": [0.1, 0.2, 0.3, 0.4]
}
},
{
"class": "Article",
"properties": {
"title": "MinIO Postgres Event Notifications",
"content": "An in-depth look at Postgres event notifications in MinIO...",
"url": "https://blog.min-io.cn/minio-postgres-event-notifications/",
"customEmbeddings": [0.3, 0.4, 0.1, 0.2]
}
},
{
"class": "Article",
"properties": {
"title": "From Docker to Localhost",
"content": "A guide on transitioning from Docker to localhost environments...",
"url": "https://blog.min-io.cn/from-docker-to-localhost/",
"customEmbeddings": [0.4, 0.1, 0.2, 0.3]
}
}
]包含文章的示例数据
使用 curl 设置
模式充当我们数据管理系统的结构支柱,定义了数据如何组织、索引和查询。
创建 Weaviate 模式
通过一个简单的 curl 命令,以及将我们的示例文件克隆到本地到我们的当前工作目录中;我们可以将我们的 schema.json 直接发布到 Weaviate,从而制定我们的数据将遵循的规则和关系。
curl -X POST -H "Content-Type: application/json" \
--data @schema.json https://:8080/v1/schemaCURL:创建
填充模式:索引数据
在模式到位后,下一步涉及使用实际数据填充它。使用另一个 curl 命令,我们将 data.json 索引到模式中。
curl -X POST -H "Content-Type: application/json" \
--data @data.json https://:8080/v1/objectsCURL:索引
确保数据持久性:使用 MinIO 备份
我们需要分配一个唯一的标识符或“backup-id”。此标识符不仅有助于精确跟踪和检索备份集,而且还确保每个数据集都经过版本控制。
curl -X POST 'https://:8080/v1/backups/s3' -H 'Content-Type:application/json' -d '{
"id": "backup-id",
"include": [
"Article",
"Author"
]
}' CURL:backup-s3
预期:
{'backend': 's3', 'classes': ['Article', 'Author'], 'id': 'backup-id', 'path': 's3://weaviate-backups/backup-id', 'status': 'SUCCESS'}成功备份-S3 响应
此输出格式化为 JSON 对象。它包括使用的后端(在本例中为 ‘s3’)、备份中包含的类列表('Article'、'Author')、分配给备份的唯一标识符 id('backup-id')、指示备份在 S3 存储桶中存储位置的路径(s3://weaviate-backups/backup-id)以及操作状态('SUCCESS')。
此结构化响应不仅确认了备份过程已成功完成,而且还提供了可用于将来参考、审核或恢复过程的重要信息。
数据恢复过程
Weaviate 生态系统中的数据恢复是通过结构化的 API 调用完成的,通过 POST 请求针对由 backup-id 标识的 /v1/backups/s3/backup-id/restore 端点。此 curl 调用不仅恢复了丢失或归档的数据,还允许您维护连续性。
curl -X POST 'https://:8080/v1/backups/s3/backup-id/restore' \
-H 'Content-Type:application/json' \
-d '{
"id": "backup-id",
"exclude": ["Author"]
}'CURL:恢复
预期
{
"backend": "s3",
"classes": ["Article"],
"id": "backup-id",
"path": "s3://weaviate-backups/backup-id",
"status": "SUCCESS"
}成功恢复响应
每个命令都应该根据您的特定设置和要求进行调整。您可能需要根据需要修改端点 URL、数据文件路径和其他参数。此外,请确保您的环境中存在必要的文件(schema.json、data.json)和配置。
有关 Weaviate 的其他说明
使用 GitOps 进行自动化
通过将所有内容编码到 Git 中,团队可以轻松跟踪更改、回滚到以前的状态并确保环境一致性。GitOps 工作流可以与持续集成/持续交付 (CI/CD) 工具和 Kubernetes 集成,进一步简化容器化应用程序的编排和基础设施管理。我们将在以后的博文中详细介绍如何使用 GitOps 进行自动化。
部分备份和恢复
Weaviate 允许备份或恢复特定类,这对于部分数据迁移或开发测试等情况非常有用。
多节点备份:对于多节点设置,特别是在 Kubernetes 环境中,请确保您的配置正确指定备份模块(如用于 MinIO 的 backup-s3)以及相关的环境变量。
故障排除
如果您在备份或恢复期间遇到问题,请检查您的环境变量配置,特别是与 S3 兼容存储(如 MinIO)的 SSL 设置相关的配置。禁用 SSL(BACKUP_S3_USE_SSL: false)可能会解决某些连接问题。
使用 MinIO 为 Weaviate 提供强大且可扩展的备份解决方案
在我们结束使用 Docker Compose 将 Weaviate 与 MinIO 集成的探索时,很明显,这种组合不仅仅是一个技术解决方案,而且是对数据管理的战略改进。这种集成与 MinIO 提供可扩展、安全和高性能数据存储解决方案的承诺完全一致,现在由 Weaviate 的人工智能驱动功能增强。Docker Compose 的使用进一步简化了这种集成,强调了我们专注于使复杂技术易于访问和管理。
一如既往,MinIO 团队致力于推动数据管理领域的技术创新。我们致力于提升和简化数据的存储、访问和分析方式,这是我们使命的核心所在。
通过将 Weaviate 的先进向量数据库功能与 MinIO 提供的强大存储解决方案相结合,用户能够释放数据的全部潜能。这包括利用语义搜索功能,不仅确保数据的可访问性,还在基础层面确保数据的安全性。
我们真正受到像您这样的敬业且充满激情的开发人员的非凡创新所启发。我们很高兴能够提供支持,成为您探索高级解决方案和在数据驱动项目中取得新高度的旅程的一部分。如果您有任何问题或只是想打个招呼,请随时联系我们,可以通过 Slack。