动态ETL管道:使用Unstructured-IO将Web数据注入MinIO和Weaviate以供AI使用

在现代数据驱动的环境中,网络是无限的信息来源,为洞察和创新提供了巨大的潜力。然而,挑战在于提取、构建和分析这片浩瀚的数据海洋,使其具有可操作性。这就是Unstructured-IO的创新,结合MinIO强大的对象存储能力和Weaviate的AI和元数据功能,发挥作用的地方。它们共同创建了一个动态ETL管道,能够将非结构化网络数据转换为结构化、可分析的格式。
本文探讨了这些强大技术的集成如何彻底改变数据水化和分析,提供了一个全面的解决方案,不仅能够管理,还能从大量网络生成的内容中提取切实的价值。通过利用Unstructured-IO专为智能解析和构建大量非结构化数据而设计的动态处理工具,我们处于演变的前沿,展示了一种动态ETL的整体方法,它正在重塑数据管理和洞察力生成领域。
揭示Unstructured-IO的潜力
该过程始于Unstructured-IO,这是一个强大的工具,旨在筛选非结构化网络数据的混乱,提取有价值的信息并将其转换为结构化格式。这对依赖于网络生成内容的企业和研究人员至关重要,但他们在有效管理和分析方面面临着障碍。
接下来,MinIO开始发挥作用,提供对象存储解决方案,确保结构化数据安全有效地存储。其高性能和与现有工具的兼容性使其成为处理Unstructured-IO处理的数据量的理想基础。
最后,Weaviate使用AI和元数据功能丰富结构化数据,将纯文本转换为丰富的自定义对象。这种增强将数据转化为深度语境化的见解,提升决策和创新。
实际应用
假设你在网络上发现了有价值的内容。只需点击iOS快捷方式上的一个按钮,即可捕获、处理和存储此内容。这不仅仅是保存链接;它还关乎实时丰富你的数据生态系统,使每条信息都立即可访问和可分析。
这个动态ETL管道不仅仅是一个理论结构,而是一个已经在增强数据工作流的实用工具。它证明了现代解决方案如何应对网络生成数据的洪流,将其转变为任何组织的结构化、有价值的资产。
通过将Unstructured-IO与MinIO和Weaviate集成,我们不仅在管理数据;我们正在释放其全部潜能,使你更容易从网络的广阔空间中获得有意义的见解。这是数据管理和分析的未来,简化、安全和智能,随时准备将你的项目提升到新的水平。
使用Unstructured-IO彻底改变数据水化
在复制医疗保健领域D-ETL成功的同时,Unstructured-IO重新定义了网络生成内容的数据水化过程。通过将非结构化数据无缝转换为结构化、可分析的格式,它不仅增强了数据质量和数量,还为突破性见解和人工智能驱动的计划奠定了基础。这种转变对于企业和研究人员来说都是至关重要的,它为数字时代的数据高效管理和分析提供了可扩展的解决方案。
有关动态ETL方法及其在医疗保健数据管理中的应用的深入探讨,请参阅标题为“Dynamic-ETL: a hybrid approach for health data extraction, transformation and loading”的研究,可在PubMed Central获取。这项研究举例说明了用于克服协调电子健康记录(EHR)以用于临床研究网络的挑战的创新方法。
准备开发环境
我们的D-ETL管道设置的初始阶段至关重要,重点是为我们的开发环境配备必要的Python库。此步骤通过pip install执行,它安装以下三个包
- weaviate-client:促进与Weaviate的直接交互,使我们能够利用其复杂的AI驱动的搜索功能。
- unstructured:提供强大的工具,用于将非结构化数据转换为可供分析和存储的格式。
- minio:将我们的工作流程连接到MinIO,提供了一个无缝的界面来与我们的对象存储服务器交互,我们的数据将安全地存储在那里。
|
pip install weaviate-client unstructured minio |
通过将这些包集成到我们的环境中,我们确保我们的管道完全具备未来任务所需的条件。

此设置不仅为高效的数据提取、转换和加载过程奠定了基础,还为创新的数据管理解决方案打开了大门。凭借我们掌握的这些工具,我们准备踏上无缝数据处理之旅,从最初的网络内容提取到最终的存储和分析阶段。
展示MinIO、Weaviate和unstructured集成和用法的演示代码可供审查和探索此处。
初始化客户端
为ETL过程建立坚实的基础始于初始化我们的MinIO和Weaviate客户端。
|
从 minio 导入 Minio |
此过程涉及使用特定参数(例如访问凭据和连接 URI)配置每个客户端。
使用 Unstructured-IO 的自动分区进行数据提取和转换
此阶段涉及动态获取网络数据,并结合网络抓取请求和 Unstructured-IO 将内容划分为可管理的片段。
代码首先导入必要的库——requests 用于 HTTP 操作,re 用于正则表达式操作,有助于清理我们的 URL 以获得更具描述性的对象名称,io 用于处理字节流,以及 unstructured.partition.auto 用于智能地将复杂网络内容分解为结构化数据。
两个关键的辅助函数 sanitize_url_to_object_name 和 prepare_text_for_tokenization 用于清理 URL 和文本内容,确保输出采用适合分析的标准化格式。sanitize_url_to_object_name 函数修改 URL 以创建每个内容片段的唯一、对文件系统友好的名称,以便于组织存储。prepare_text_for_tokenization 进一步清理文本数据,去除不必要的空格,并为更深入的分析或 AI 处理做好准备。
|
导入 requests "https://unstructured.io/blog" |
这种结构化方法不仅简化了将网络数据导入到我们系统中的过程,也为后续阶段奠定了基础,在后续阶段,这些数据将存储在 MinIO 中并在 Weaviate 中建立索引。通过仔细选择 URL 作为数据源,该过程确保了可以获得丰富多样的数据集进行探索,随时准备在各种环境中推动洞察力和决策。
加载到 MinIO
此步骤旨在确保新结构化和清理后的数据以组织化的方式保存,以便于将来分析时轻松访问。
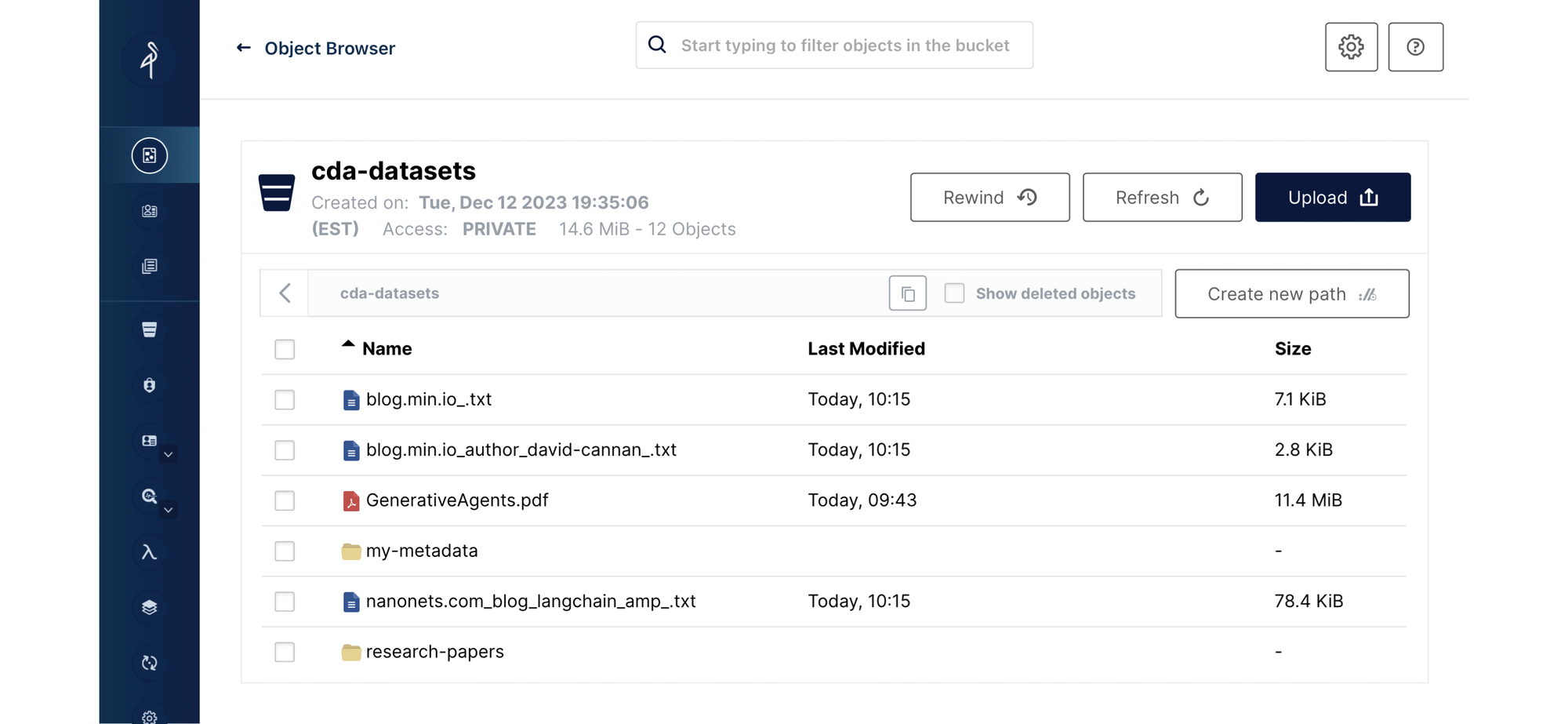
在数据经过转换后,下一步涉及将其安全地存储在 MinIO 中,以下代码块中描述了此过程。
|
存储桶名称 = "cda-datasets" |
该脚本自动检查是否存在 MinIO 存储桶,或者在必要时创建新的存储桶,这表明管道已准备好有效地处理数据。
|
对于 urls 中的每个 url: |
通过系统地处理并将每个数据片段上传到 MinIO,这种方法强调了可靠存储解决方案在维护数据完整性和可用性以供后续检索和分析工作的重要性。
使用 Weaviate 简化数据利用
数据转换完成后,下一步是将这些经过细化的信息导入 Weaviate。
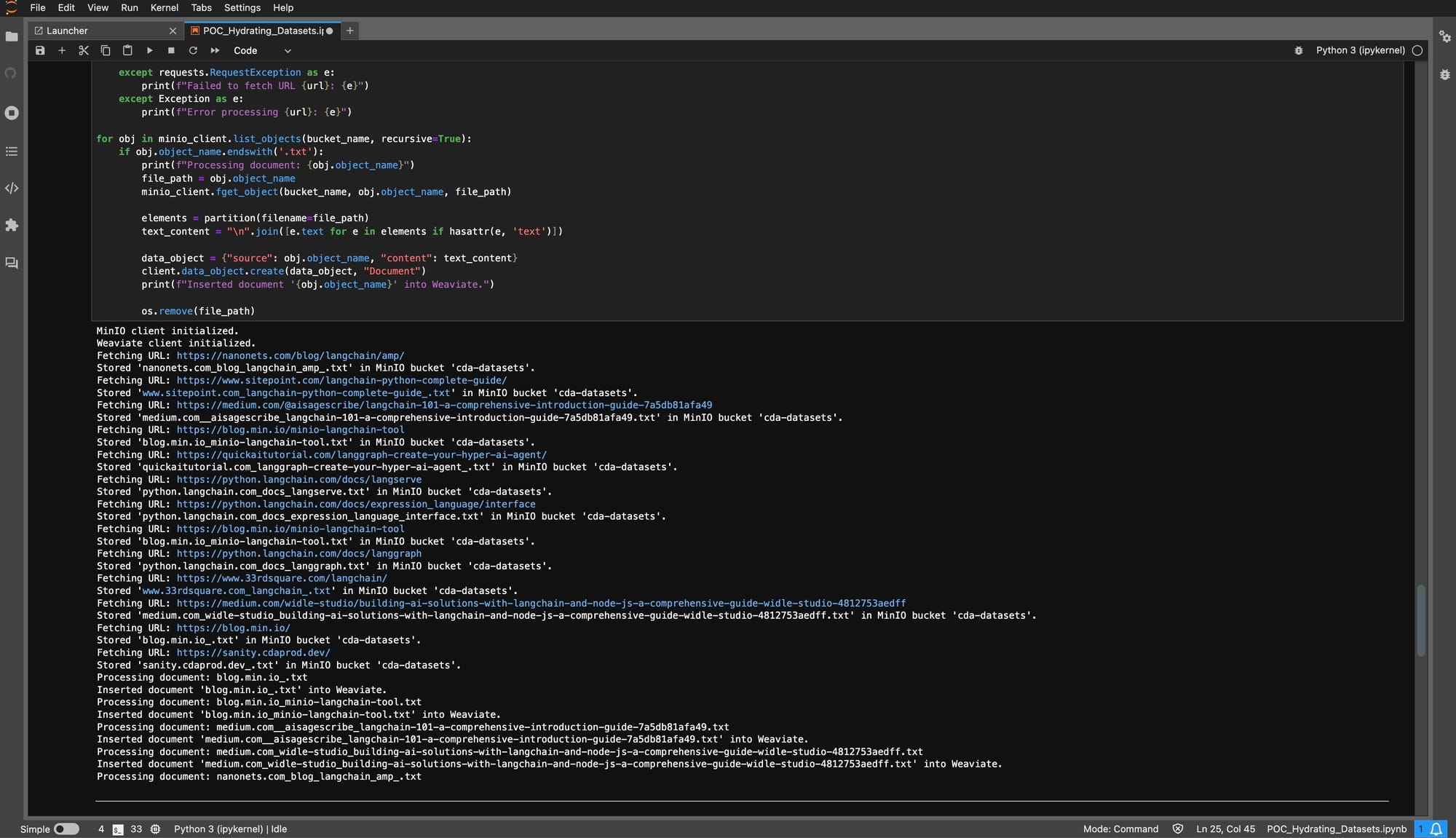
此阶段旨在利用Weaviate的先进搜索功能增强数据,并将其安全地存储在高效的存储系统中。Python代码片段概述了一种系统的方法,用于将转换后的数据(特别是文本文件)从MinIO导入到Weaviate中。
此过程不仅展示了存储平台和搜索平台之间的无缝集成,还突出了双重ETL管道在增强数据访问性和分析准备方面的实际应用。
|
for obj in minio_client.list_objects(bucket_name, recursive=True): |
管道这一部分强调将静态数据转换为Weaviate中动态的可搜索资产。通过将数据嵌入到Weaviate的上下文感知环境中,它释放了细致查询功能和数据驱动见解的潜力。此步骤概括了双重ETL方法的本质——利用MinIO的可扩展存储和Weaviate的智能搜索的组合优势,培育一个既健壮又能够响应分析查询的数据生态系统。
查询Weaviate—完成我们的数据处理过程
数据管道中的最后阶段利用Weaviate的语义搜索功能,查询转换后的数据以提取有意义的见解。
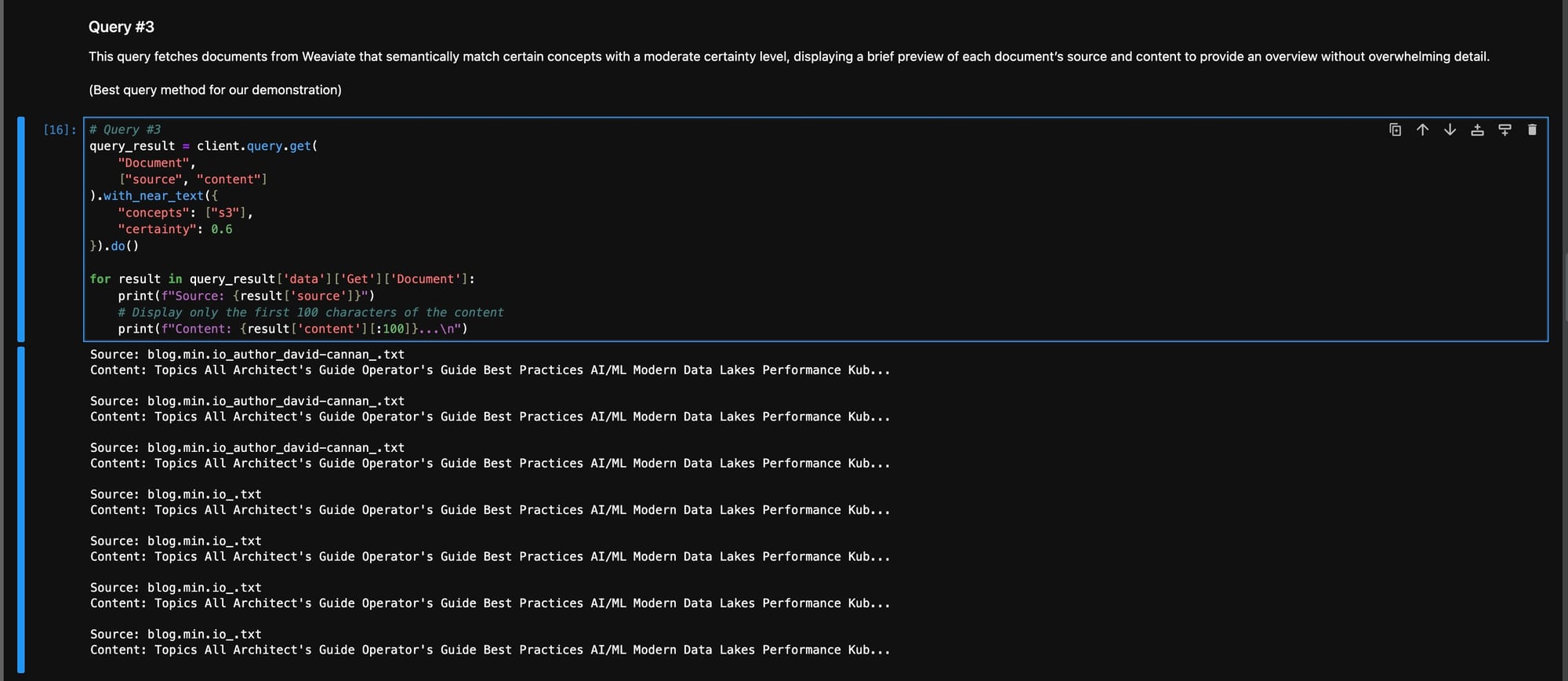
此过程将结构化数据转化为实用、可操作的智能。
|
query_result = client.query.get( |
这段 Python 代码演示了在 Weaviate 中进行目标搜索,检索语义上匹配给定概念且置信度达到设定水平的文档。
此功能体现了我们双重 ETL 管道的实际能力——将复杂数据转化为易于理解和使用的信息,为业务应用做好准备。
在我们结束对动态 ETL 管道的探索之际,该管道得到了 Unstructured-IO 的核心功能的增强,很明显,我们正处于数据管理革命的风口浪尖。探索将非结构化网络数据转化为结构化信息宝库的复杂过程,其转变可谓是翻天覆地。借助 Unstructured-IO 的自动分区、MinIO 的存储解决方案和 Weaviate 的 AI 功能,我们已经揭示了一条不仅简化数据管理,而且还能以前所未有的方式解锁更深入、更有价值的洞察力的途径。
使用 Unstructured-IO 连接器增强 ETL 流程
在我们概念验证的开发过程中,评估了几种方法以确保实现简化和高效,目标是最小化代码行数。Unstructured-IO Weaviate 连接器为增强数据处理工作流程提供了一条有希望的途径。
这些连接器尤其擅长管理批处理,确保数据符合预定义的模式,并简化错误处理机制。这使得它成为需要可扩展、高效且可靠的数据处理能力的项目的宝贵工具,尤其是在复杂或数据密集型环境中。它在这种场景中的潜在效用突显了考虑各种工具和方法以优化数据管道开发和运营效率的重要性。
将 Unstructured-IO 集成到我们的动态 ETL 管道中,不仅仅是一种技术方法;它是一种为数据分析和 AI 技术开辟道路的方法。通过将非结构化数据转换为有组织的可搜索存储库,我们不仅增强了当前的分析能力,而且还为新兴的 AI 方法奠定了基础,这些方法有望重新定义数据驱动决策中可能实现的目标。
创新与合作邀请
很明显,目前创新的潜力是无限的,其对从医疗保健到金融等行业的冲击尚未完全实现。我们邀请您——开发人员、数据工程师和远见卓识者加入我们的冒险之旅。无论是定制管道以满足特定需求,还是探索这些工具的新应用,您的贡献都是释放下一级数据驱动突破的关键。
归根结底,这不仅仅关乎数据或技术;它关乎我们建立的联系、我们发现的见解以及我们产生的影响。
如果您受到动态 ETL 的可能性的启发,对 Unstructured-IO 的功能感到好奇,或者只是想分享您的想法,我们随时为您服务。
请在 Slack 上联系我们并给我们留言。让我们继续这场对话,共同塑造数据管理的未来!