MLflow 追踪和 MinIO
引言
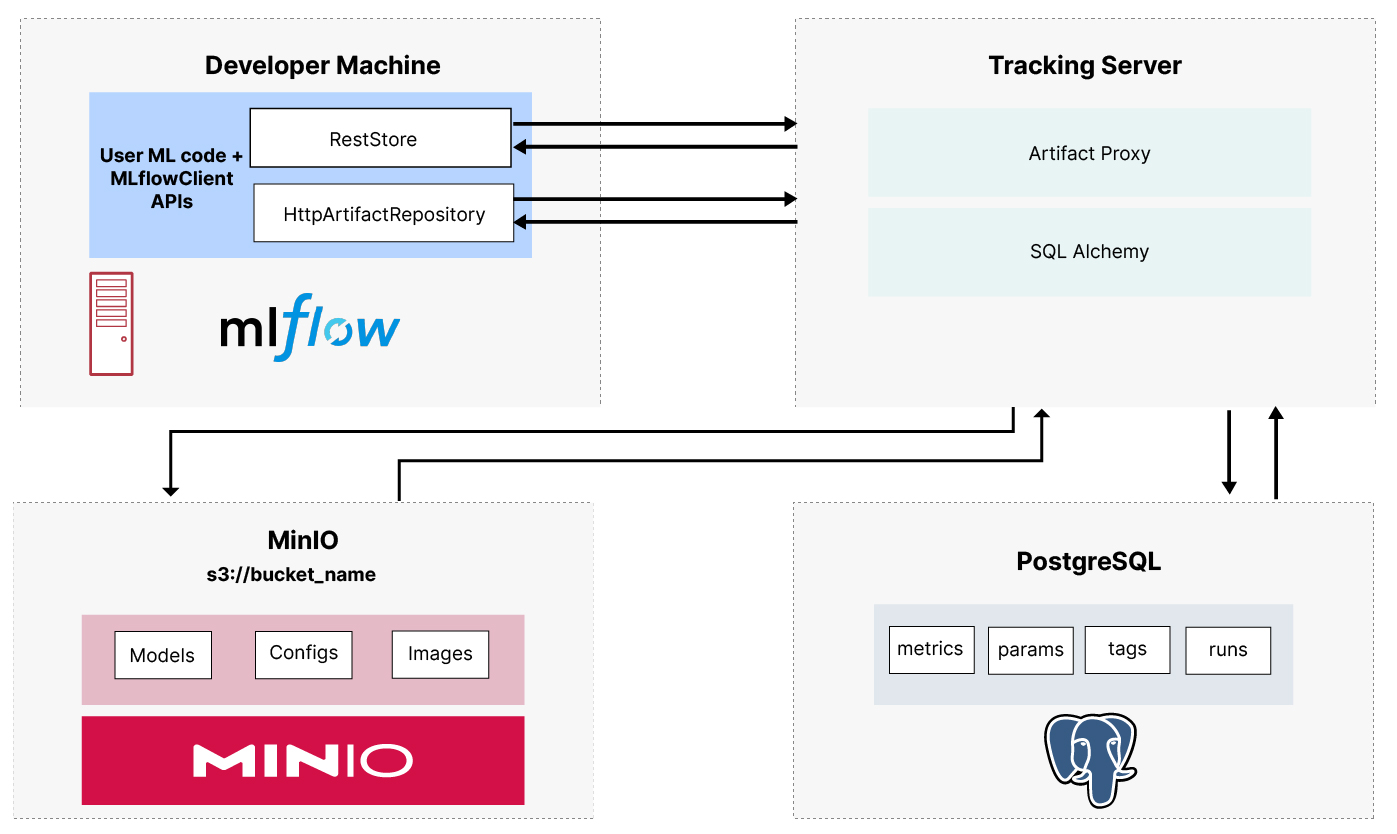
跟踪机器学习实验是一项挑战。假设您在 MinIO 存储桶中有一组用于训练和测试模型的原始文件。始终有多种方法可以预处理数据、设计特征和设计模型。鉴于所有这些选项,您将希望运行许多实验。反复迭代下面所示管道的前 5 个步骤是机器学习的重要组成部分。如果没有适当的跟踪,您将无法确定使用哪种数据整理技术和模型设计获得了特定结果。此外,无论您在哪里运行实验,都应跟踪结果。这可能是笔记本电脑上运行的笔记本,也可能是用于分布式训练的集群。

本文介绍了 MLflow Tracking - MLflow 的一个组件,旨在用于记录和查询机器学习实验。本文的代码下载可以在这里找到 这里。
MLflow 快速入门
MLflow 是一个开源平台,旨在管理完整的机器学习生命周期。作为管理完整生命周期的工具,MLflow 包含以下四个组件。
- MLflow Tracking - 工程师将最多使用此功能。它允许记录和查询实验。它还跟踪每个实验的代码、数据、配置和结果。
- MLflow Projects - 通过将代码打包成与平台无关的格式,允许重现实验。
- MLflow Models - 将机器学习模型部署到可以提供服务的环境中。
- MLflow Model Registry - 允许在中央存储库中存储、注释、发现和管理模型。
本文将研究 MLflow Tracking。我假设您已经在开发机器上安装了 MLflow 作为使用 PostgreSQL 和 MinIO 的远程服务器。如果您没有安装 MLflow,请查看我在 使用 MLflow 和 MinIO 设置开发机器 上的文章。在我的设置文章中,我展示了如何使用 Docker Compose 运行以下所示的服务。
MLflow Tracking API
在编写任何代码之前,了解一下哪些功能是可能的将很有帮助。以下是最常用的跟踪 API 及其最常用的参数列表。对于每个 API,我都提供了简短的描述。此外,我还根据它们是用于设置、记录参数、指标还是工件对它们进行了分类。完整的 API 列表可以在 MLflow API 文档 中找到。
设置
设置 API 连接到您的 MLflow 服务器,还用于启动运行并将它们与实验关联。MLflow 与其他 MLOps 工具一样,将运行定义为代码的一次遍历。我喜欢将运行视为一次遍历上面显示的管道的前 5 个步骤,这些步骤从原始数据开始,到经过测试的模型结束。实验是一组具有共同目标的运行。假设您想找出最佳学习率或哪个损失函数更好。这些是两个实验的示例,这些实验将有多个运行。为您的实验和运行提供有意义的名称,以帮助您理解实验的目标以及每个运行发生了哪些变化。用于设置实验的 API 在被调用时需要一个名称。当您使用 mlflow.start_run() 启动运行时,您不需要向其传递名称。此 API 将为您生成一个名称。生成的名称非常有创意且有趣 - 因此,如果您想笑一笑,请让 MLflow 为您的运行命名。
以下是我们将在本文中使用的四个设置 API。
连接到 MLflow 服务器的一个实例。如果您不调用此 API,则所有内容都将保存到本地文件系统中名为 `mlruns` 的目录下。
将实验设置为活动实验。在此 API 调用后启动的所有运行都将记录到指定的实验中。如果实验不存在,则将创建它。我们在本文中的用法将需要此参数以简化操作。
启动一个新的运行。如果没有传递 run_name,则会为您创建一个有创意的有趣名称。
结束当前运行。
参数
参数是您可以更改的任何内容,这些内容会影响模型的准确性。学习率、时期数和隐藏状态的大小都是参数的示例。我喜欢将所有参数都放在一个字典中,并使用 `mlflow.log_params()` api 通过一次调用记录所有内容。以下是用于记录参数的两个 API。
记录单个参数。
记录一批参数。参数必须打包到字典中。
指标
指标是任何类型的结果。最常见的指标是训练时期时损失函数的结果以及模型针对测试集的准确性。有两个 API 用于记录指标。
记录单个指标。注意可选的 `step` 参数。此参数旨在在时期循环内使用,以允许在时期中跟踪单个指标。最常见的示例是损失指标。
记录指标字典。
工件
工件是您希望作为运行的一部分保存的任何大型文件。这可能是您的原始输入文件、有关输入文件的元数据或训练后的模型本身。有两个 API 用于指标。
将单个文件记录为工件。
将给定目录中的所有文件作为工件记录。
此函数特定于模型。由于我们使用的是 Pytorch,因此我们的函数将是 mlflow.pytorch.log_model()。请勿使用 log_artifact 记录模型。使用 log_model 记录模型后,便可以将其注册到模型注册表中。
关于这些 API 的最后一点需要注意的是,MLflow 确实具有自动记录功能。这是与各种框架直接集成产生的结果。支持情况因您使用的框架而异,并非所有框架都受支持。我不会在本帖中使用自动记录。我更喜欢明确记录我记录的所有内容,而且事实是,它并不难使用。上面的 API 易于使用,如果您正在为现有代码库添加工具,您会发现自己会替换可能散布在代码中用于将信息发送到终端窗口的 print 语句。
现在,我们已准备好使用这些 API 为我们的代码添加工具。让我们介绍一下我们的数据,并创建一个训练集和一个测试集。
MNIST 数据集
修改后的美国国家标准与技术研究所 (MNIST) 数据集 是手写数字的集合。它是机器学习社区中最知名的数据集之一,通常用作构建神经网络的入门教程。每个图像都是一个 28 x 28 像素的手写数字图像,数字介于 0 到 9 之间。下面是数据集中每个数字的一些示例。此数据集的创建者已经指定了要用于训练和测试的图像。有 60,000 张图像用于训练,10,000 张图像用于测试。

由于每个图像的大小相同且数字居中,因此很容易获得超过 90% 的准确率。因此,为了好玩,我们将看看我们能将模型的准确率提高到多接近完美 - 100%。
Pytorch 有一些内置实用程序可以轻松加载此数据集。下面的函数将为训练集和测试集创建一个 DataLoader。
请注意,我并没有在这个函数中进行任何日志记录,而是返回了一些指标,这些指标将在调用此代码的控制函数中进行记录。具体来说,我返回了训练集的大小、测试集的大小以及加载这些图像所花费的时间。
此代码还会将原始 MNIST 数据加载到当前工作目录下的名为 `mnistdata` 的文件夹中。稍后,我将把整个文件夹作为工件记录下来。
接下来,让我们创建我们的模型。
模型
模型的代码如下所示。当我们实例化此类以创建我们的模型时,输入大小必须为 784,因为这是每个图像中的像素数。输出大小必须为 10,因为这是一个分类问题,模型必须为每个图像计算 10 个概率。(该图像为 0 的概率,该图像为 1 的概率,……)概率最高的是预测结果。隐藏层的大小是可以进行实验的参数。
这是一个简单的三层神经网络,使用ReLU激活函数。一些可以对模型本身进行的实验包括增加层数、更改隐藏层的尺寸以及更改激活函数。
我们有数据,也有模型。接下来,我们需要一个训练函数。
模型训练
下面是训练函数,它将带我们完成各个epoch。
请特别注意每个epoch之后是如何记录损失的。`mlflow.log_metric()` 函数有一个可选参数用于指定epoch。这使我们能够创建一个名为training_loss的单个指标,其中包含一个值数组。当我们在MLflow UI中查看此指标时,将能够看到此指标在所有epoch上的良好图形。在探索MLflows UI时,我将展示此图形。
让我们将所有内容整合在一起并记录一些指标。
整合所有内容
下面的代码将把所有内容整合在一起。在这里,我们大量使用了上面列出的API。它们都用于下面的控制代码中。
首先进行设置 - 我们连接到服务器,创建一个实验并启动一个运行。在此之后,创建并记录参数。记录加载、训练和测试的指标。(`test_model` 函数可以在github代码库中下载。为了简洁起见,这里省略了它。)最后,我记录了模型和原始数据(这会发送到MinIO)。
我们做得怎么样?使用本文中提供的代码,我能够在测试集上获得98.2%的准确率。然而,比结果更有趣的是在所有实验中收集到的指标。现在让我们通过MLflow UI查看它们。
探索MLflow UI
我使用此模型运行了几个运行。我感兴趣的是确定最佳学习率。我还想知道最佳的epoch数。在完成几次运行后,我的MLflow主页看起来像下面的屏幕截图。
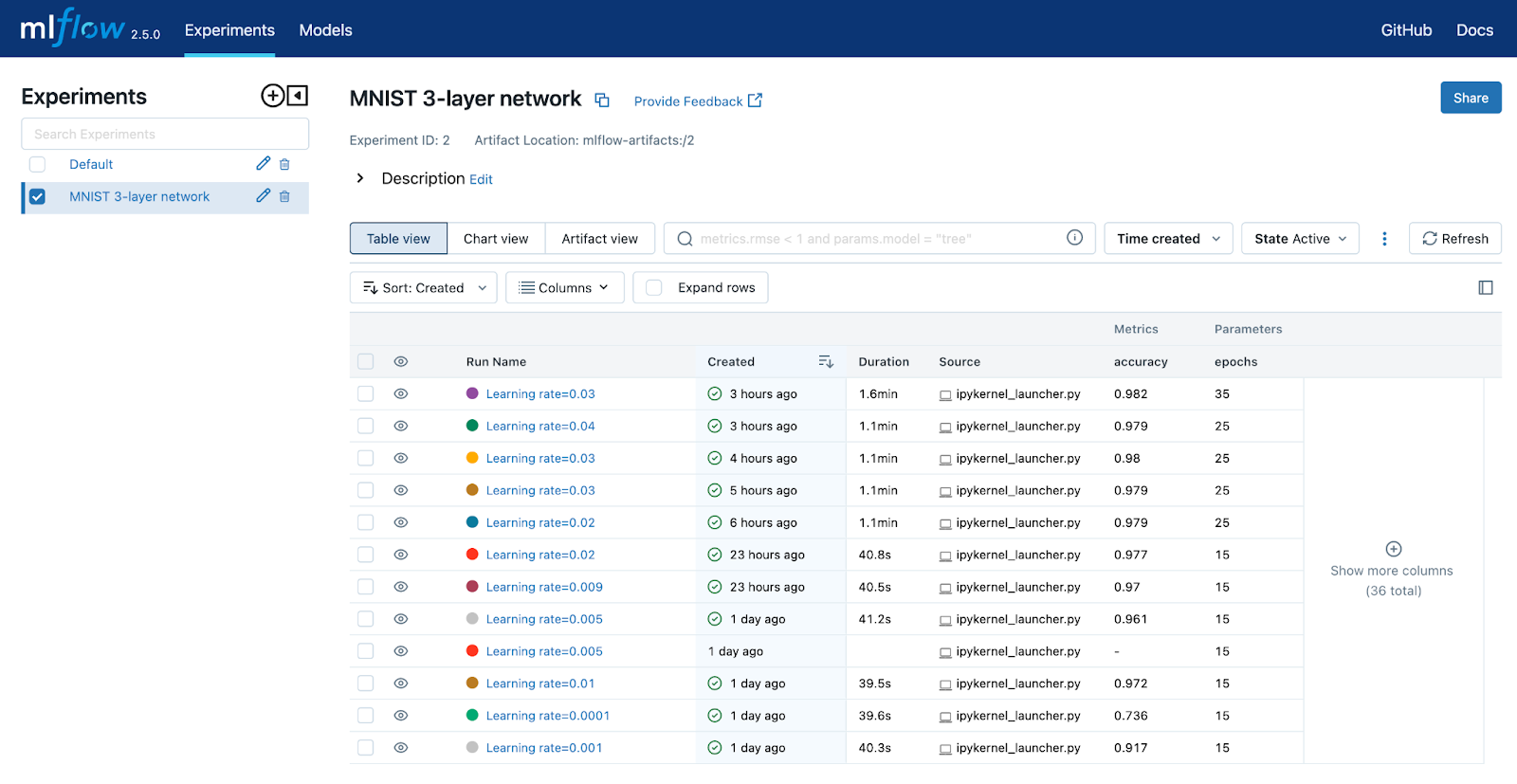
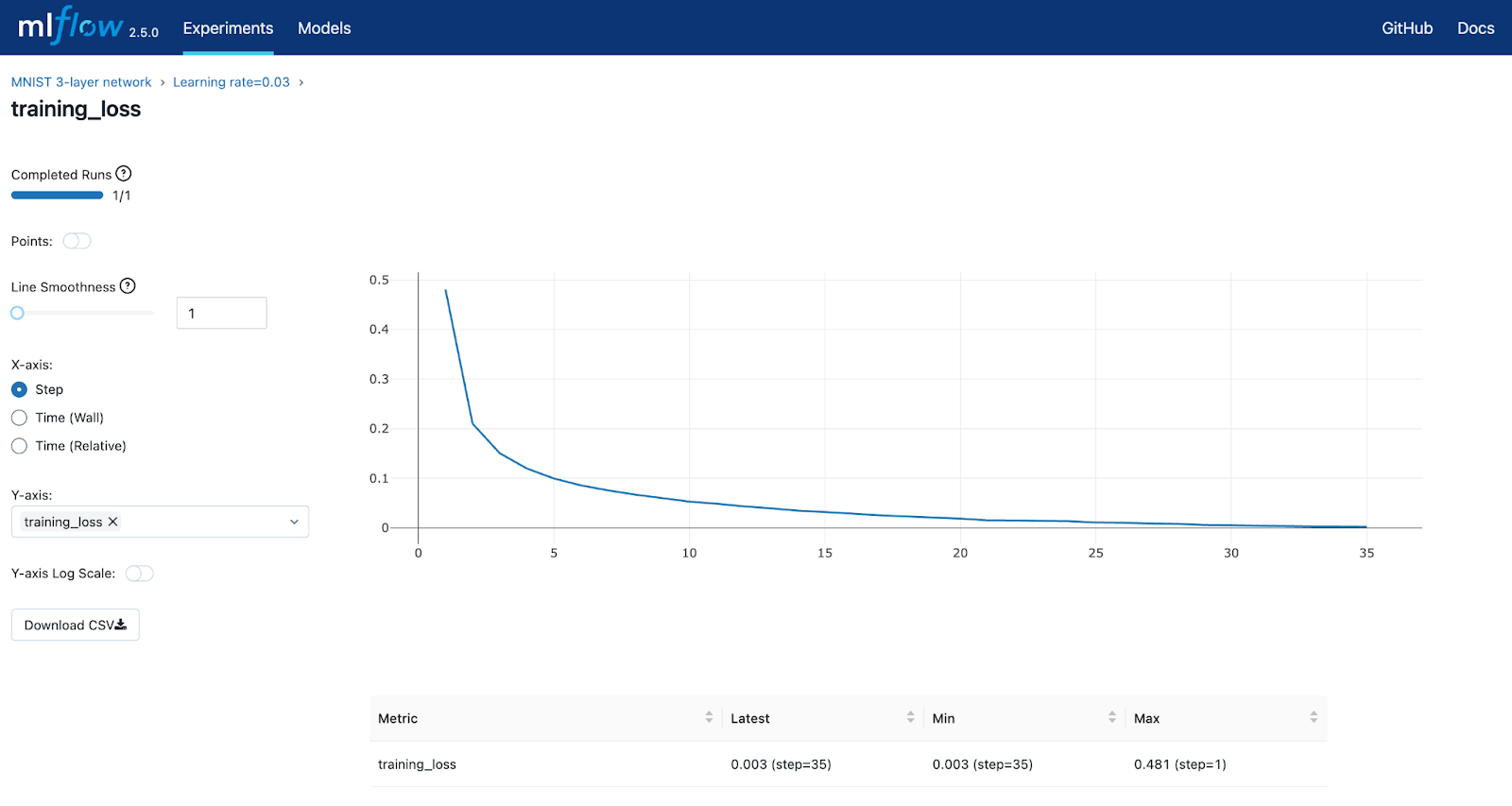
默认视图是表格视图。您可以选择要显示的列。从这里,如果要查看特定运行的参数和指标,可以深入到该运行中。选择一个运行并点击`training_loss`指标,将生成下面的图形。如您所见,损失函数看起来在大约35左右开始趋于平缓。额外的epoch不会产生更好的结果。
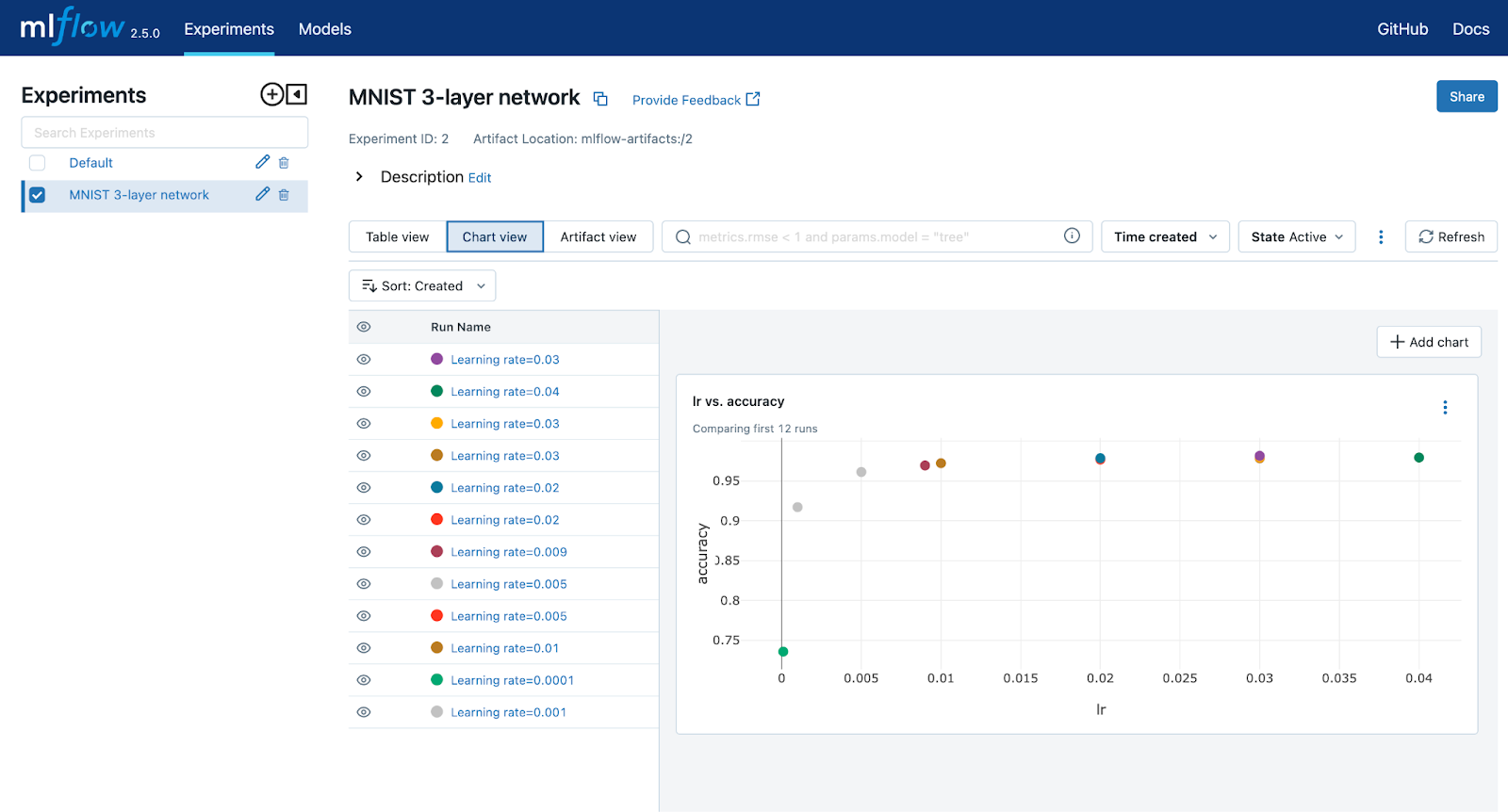
返回主页并点击“图表视图”按钮,将带您到一个可以创建图表的页面。我创建了一个图表,显示了学习率与准确率之间的关系。您可以创建任意数量的图表。这些图表将显示您在实验中选择的任何参数和指标在所有运行中的关系。
最后,我们进入工件视图。如果需要,可以为每个运行保存工件。模型应该在每次运行时都保存。最终,您将拥有一个性能良好的模型,并且希望在MLflows模型注册表中注册它。为此,需要将其记录下来。如果正在应用特征工程和数据整理技术,请考虑为每次运行记录数据集。最终,您的数据集将达到在运行之间不再变化的程度,在这种情况下,您不再需要记录数据集。MLflow提供了一种从记录的工件中获取URI的方法。这使您可以使用先前运行中的数据集。
选择“工件视图”后,必须选择要调查的运行。选择运行后,您将看到下面的页面。此视图显示了数据集(mnistdata)和模型(mnistmodel)。模型与数据的处理方式不同。模型可以放置在MLflows模型注册表中 - 我将在以后的文章中介绍这一点。
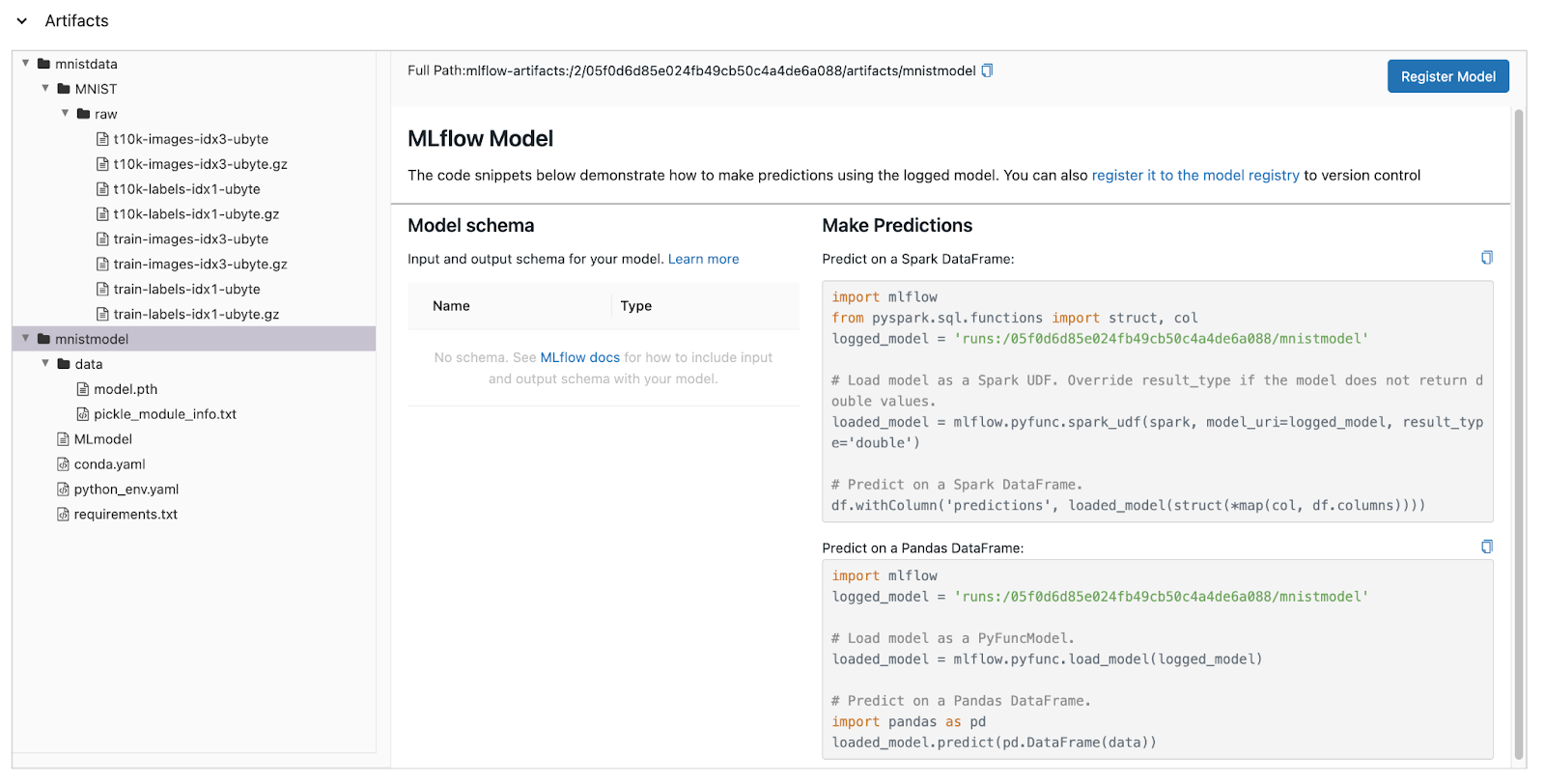
“完整路径”属性是关于在MinIO中查找此工件位置的线索。请记住,当我们安装MLflow时,我们在MinIO中设置了一个由MLflow使用的单个bucket。此bucket名为`mlflow`。让我们通过MinIO UI查看此bucket的内容。如下所示。
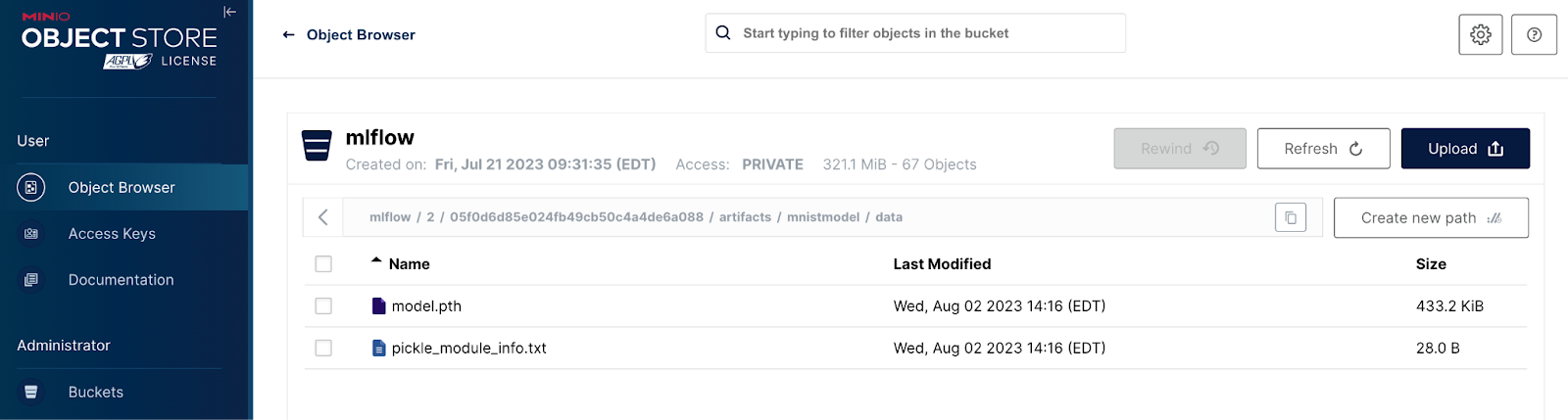
在这里,我们看到了模型在MinIO中的存储位置。路径中的`mnistmodel`部分是在调用log_model时指定的`artifact_path`。值得注意的是,三层神经网络产生的模型大小接近0.5 MB。这就是为什么机器学习工作流程中需要MinIO对象存储的原因。在生产环境中,需要可靠地存储模型并有效地提供服务。在32个NVMe驱动器和100GbE网络的32个节点上,MinIO的GET/PUT速度超过325 GiB/秒和165 GiB/秒。此外,随着模型越来越大,加载时间会更长 - 使用MinIO将改善加载时间。
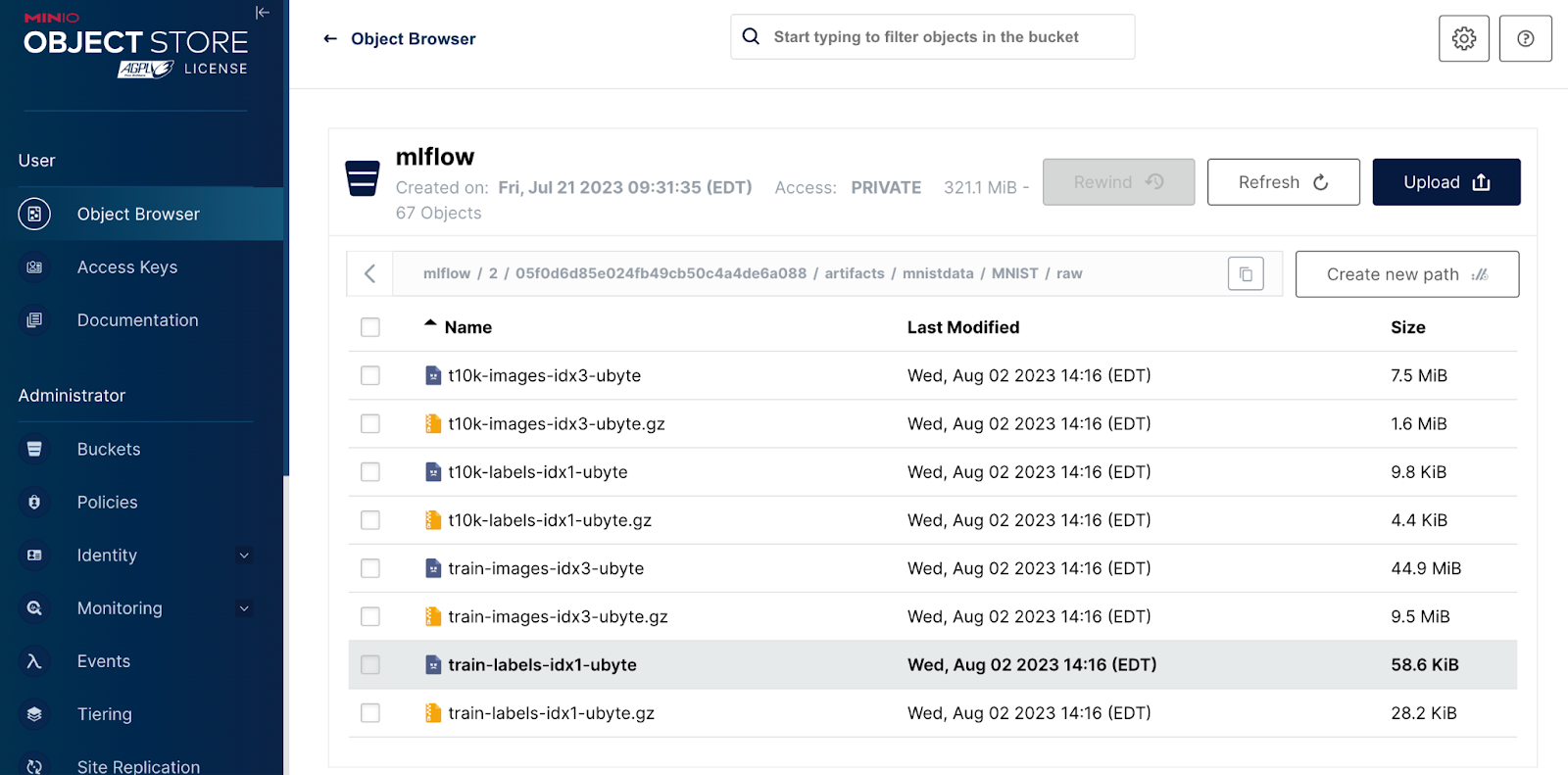
最后,请注意`mnistdata`路径。这是我们使用`mlflow.log_artifacts()`和`mnistdata`的`artifact_path`记录的原始数据。此处看到的压缩对象是Pytorch为我们下载的文件。
总结
MLflow跟踪是一个易于使用的工具,用于跟踪(或记录)参数、指标和工件。在这篇文章中,我们使用了MNIST数据集来演示参数跟踪、指标跟踪和工件跟踪。我们还探索了MLflow UI的报告功能,在其中看到了许多可用于改进模型性能的有用报告。最后,我们查看了底层并展示了MLflow如何使用MinIO存储工件。