在 我之前关于 MLRun 的帖子 中,我们使用 docker-compose 文件创建了 MLRun UI、MLRun API 服务、Nuclio、MinIO 和 Jupyter 服务的容器,搭建了开发环境。 容器启动后,我们运行了一个简单的烟雾测试来确保一切正常。 我们创建了一个简单的无服务器函数,该函数记录其输入并连接到 MinIO 获取存储桶列表。
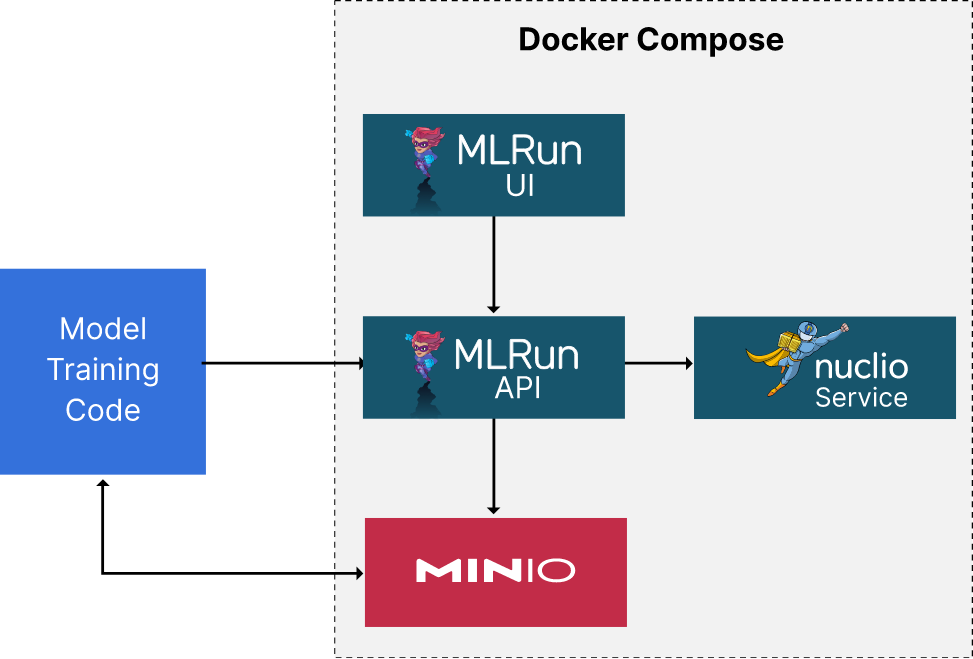
以下是我们将构建的内容和 docker-compose 文件内容的示意图。 我扩展了 MLRun 文档中提供的 docker-compose 文件,使其包含 API 服务和 MinIO。 本文将接着上一篇博文继续介绍。 我们将创建一个另一个无服务器函数来训练模型。 记住,MLRun 的目标是消除对样板代码的需求,因此我们也应该看到训练模型本身所需的代码减少。 如果你想一想训练模型时编写的代码——尤其是在 PyTorch 中——无论用于训练模型的数据和模型本身是什么,它基本上都是一样的。 换句话说,它是样板代码。 从理论上讲,它可以用一些额外的配置来代替。 此外,部署代码本身应该很简单。 在上一篇博文中,我们已经看到了一些示例。 但是,部署驱动模型训练的函数稍微复杂一些——因此我们需要更多 MLRun 功能来实现这一点。 本文随附的代码(下一节中描述)包含允许使用无法放入内存的数据集训练模型的实用程序。 我在这里不会详细介绍这些技术——那是另一篇博文的内容。
关于代码下载
本文中展示的所有代码(以及更多)都在 这里。 为了简洁起见,代码下载中的许多实用程序函数没有在本文的代码清单中显示。 但是,许多是用于将 PyTorch 与 MinIO 集成的通用实用程序。 在本节中,我将列出我希望您在使用 MinIO 存储数据集的所有 ML 项目中都能找到有用的重要实用程序。
MinIO 实用程序 (data_utilities.py)
- get_bucket_list - 返回 MinIO 中的存储桶列表。
- get_image_from_minio - 从 MinIO 返回图像。 使用 PIL 将对象转换回其原始格式。
- get_object_from_minio - 从 MinIO 返回对象——按原样。
- get_object_list - 从存储桶获取对象列表。
- image_to_byte_stream - 将 PIL 图像转换为字节流,以便可以将其发送到 MinIO。
- load_mnist_to_minio - 此函数将 MNIST 数据集加载到 MinIO 存储桶中。 每个图像都被发送为一个单独的对象。 此方法对于在集群中进行性能测试很有用,因为它会创建许多小图像。
- put_image_to_minio - 将图像字节流作为对象放到 MinIO 中。
PyTorch 实用程序 (torch_utilities.py)
- create_minio_data_loaders - 创建一个 PyTorch 数据加载器,其中包含 MinIO 存储桶中 MNIST 对象的列表。 有助于模拟无法放入内存的数据集的模型训练测试。
- create_memory_loaders - 创建一个 PyTorch 数据加载器,其中 MNIST 图像加载到内存中。
- MNISTModel - 本文使用的模型。
- ConvNet - 这是读者可以尝试的另一个模型——它为 MNIST 数据集创建卷积神经网络 (CNN)。
将现有代码迁移到 MLRun
让我们看看如何将现有代码迁移到 MLRun 中作为无服务器函数运行。 如果你有很多模型的训练代码,但没有时间更改代码以利用 MLRun 的所有功能,那么这可能是一种方法。 这是迭代迁移到 MLRun 的一种可行方法——让所有 ML 代码由 MLRun 管理——然后添加代码以利用其他功能。
考虑下面的代码,它在 MNIST 数据集上训练模型。(为了简洁起见,省略了导入和日志记录代码。 代码下载 包含所有导入和日志记录。)它是一个脚本,你可以从任何终端应用程序运行。 “train_model” 函数检索数据,创建模型,然后将控制权转交给 “epoch_loop” 函数进行训练。
def train_model(loader_type: str='memory', bucket_name: str=None, training_parameters: Dict=None):
# 加载数据并记录加载指标。
if loader_type == 'memory':
train_loader, test_loader, _ = tu.create_memory_data_loaders(training_parameters['batch_size'])
elif loader_type == 'minio-by-batch':
train_loader, test_loader, _ = tu.create_minio_data_loaders(bucket_name,
training_parameters['batch_size'])
else:
raise Exception('未知的加载器类型。必须是 "memory" 或 "minio-by-batch"')
# 创建模型。
model = tu.MNISTModel(training_parameters['input_size'], training_parameters['hidden_sizes'],
training_parameters['output_size'])
# Train the model.
start_time = time()
epoch_loop(model, train_loader, training_parameters)
training_time_sec = (time()-start_time)
# Test the model and log the accuracy as a metric.
testing_metrics = tu.test_model_local(model, test_loader, training_parameters['device'])
def epoch_loop(model: nn.Module, loader: DataLoader, training_parameters: Dict[str, Any]) -> Dict[str, Any]:
# Create the loss and optimizer functions.
loss_func = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=training_parameters['lr'],
momentum=training_parameters['momentum'])
# Epoch loop
for epoch in range(training_parameters['epochs']):
total_loss = 0
for images, labels in loader:
# Move tensors to the specified device.
images = images.to(training_parameters['device'])
labels = labels.to(training_parameters['device'])
# Flatten MNIST images into a 784 long vector.
images = images.view(images.shape[0], -1)
# Training pass
optimizer.zero_grad()
output = model(images)
loss = loss_func(output, labels)
# Backward pass
loss.backward()
# And optimizes its weights here
optimizer.step()
total_loss += loss.item()
print("Epoch {} - Training loss: {}".format(epoch+1, total_loss/len(loader)))
if __name__ == "__main__":
# training configuration
training_parameters = {
'batch_size': 32,
'device': torch.device('cuda:0' if torch.cuda.is_available() else 'cpu'),
'dropout_input': 0.2,
'dropout_hidden': 0.5,
'epochs': 2,
'input_size': 784,
'hidden_sizes': [1024, 1024, 1024, 1024],
'lr': 0.025,
'momentum': 0.5,
'output_size': 10,
'smoke_test_size': -1
}
train_model(loader_type='memory', bucket_name='mnist', training_parameters=training_parameters) |
如果我们想在 MLRun 中将此函数作为无服务器函数运行,我们只需要用 “mlrun.handler()” 装饰器装饰 “train_model()” 函数,如下所示。
@mlrun.handler()
def train_model(loader_type: str='memory', bucket_name: str=None, training_parameters: Dict=None) - > None:
..... |
接下来,我们需要设置 MLRun 环境,创建一个项目,将训练函数注册到 MLRun,并运行函数。我们将从运行在我们 docker-compose 部署中的 Jupyter Notebook 中驱动此操作。下面显示了为此操作所需的单元格。(您可以在 代码下载 中的 mnist_training_setup.ipynb 笔记本中找到此代码。)在此简单演示中使用的超参数是硬编码的;但是,如果您正在构建一个用于生产的模型,则应该使用超参数搜索来找到最佳值。
# 设置环境:
mlrun.set_environment(env_file='mlrun.env') |
# 创建项目:
project_name='mnist-training'
project_dir = os.path.abspath('./')
project = mlrun.get_or_create_project(project_name, project_dir, user_project=False) |
# 创建训练函数。
trainer = project.set_function(
"mnist_training_with_mlrun.py", name="trainer", kind="job",
image="mlrun/mlrun",
requirements=["minio", "torch", "torchvision"],
handler="train_model_with_mlrun"
) |
# 超参数
training_parameters = {
'batch_size': 32,
'device': 'cpu',
'dropout_input': 0.2,
'dropout_hidden': 0.5,
'epochs': 2,
'input_size': 784,
'hidden_sizes': [1024, 1024, 1024, 1024],
'lr': 0.025,
'momentum': 0.5,
'output_size': 10,
'smoke_test_size': -1
} |
# 运行函数。
trainer_run = project.run_function(
"trainer",
inputs={"bucket_name": "mnist", "loader_type": "memory"},
params={"training_parameters": training_parameters},
local=True
) |
这就是在 MLRun 中运行现有代码所需做的全部操作。但是,如果你仔细查看 epoch_loop() 函数,你会发现它是一个模板代码。几乎每个 PyTorch 项目都有一个类似的函数,无论模型是什么,或者用于训练模型的数据是什么。让我们来看看如何使用 MLRun 来删除这个函数。
优化训练代码
我们可以使用 MLRun 的 mlrun_torch.train() 函数来移除上面显示的调用 epoch_loop 函数。该函数的导入以及修改后的 train_model() 函数如下所示。一个“accuracy()”函数也传递给 mlrun_torch.train()。
import mlrun.frameworks.pytorch as mlrun_torch |
@mlrun.handler()
def train_model_with_mlrun(context: mlrun.MLClientCtx, loader_type: str='memory', bucket_name: str=None, training_parameters: Dict=None):
logger = du.create_logger()
logger.info(loader_type)
logger.info(bucket_name)
logger.info(training_parameters)
# Load the data and log loading metrics.
if loader_type == 'memory':
train_loader, test_loader, _ = tu.create_memory_data_loaders(training_parameters['batch_size'])
elif loader_type == 'minio-by-batch':
train_loader, test_loader, _ = tu.create_minio_data_loaders(bucket_name, training_parameters['batch_size'])
else:
raise Exception('Unknown loader type. Must be "memory" or "minio-by-batch"')
# Train the model and log training metrics.
logger.info('Creating the model.')
model = tu.MNISTModel(training_parameters['input_size'], training_parameters['hidden_sizes'], training_parameters['output_size'])
loss_func = nn.NLLLoss()
optimizer = optim.SGD(model.parameters(), lr=training_parameters['lr'], momentum=training_parameters['momentum'])
# Train the model.
logger.info('Training the model.')
mlrun_torch.train(
model=model,
training_set=train_loader,
loss_function=loss_func,
optimizer=optimizer,
validation_set=test_loader,
metric_functions=[accuracy],
epochs=training_parameters['epochs'],
custom_objects_map={"torch_utilities.py": "MNISTModel"},
custom_objects_directory=os.getcwd(),
context=context,
)
def accuracy(y_pred, y_true):
ps = torch.exp(y_pred)
pred_label = ps.argmax(1)
return (sum(pred_label == y_true) / y_true.size()[0]).item() |
在迁移你的代码以使用该函数时,有几点需要记住。
- 首先,如果你在“epoch_loop()”函数中声明了你的损失函数和你的优化器,那么你需要将这些声明移动,因为它们必须传递给“mlrun_torch.train()”。
- 其次,如果你在你的 epoch 循环中执行任何转换,你将需要将它们移动到你的数据处理逻辑中,或者,更确切地说,是一个数据管道。如果你是执行图像增强和特征工程,那么这一点尤其重要。
- 最后,为了让你的模型针对它在训练期间没有见过的数据集进行测试,你只需要提供一个 accuracy() 函数,如上所示。
虽然该函数减少了你必须编写的代码,但它最大的好处是指标跟踪和工件管理。让我们快速浏览一下 MLRun UI,看看从我们的第一个完全管理的运行中保存了什么,我们训练了一个模型。
查看运行
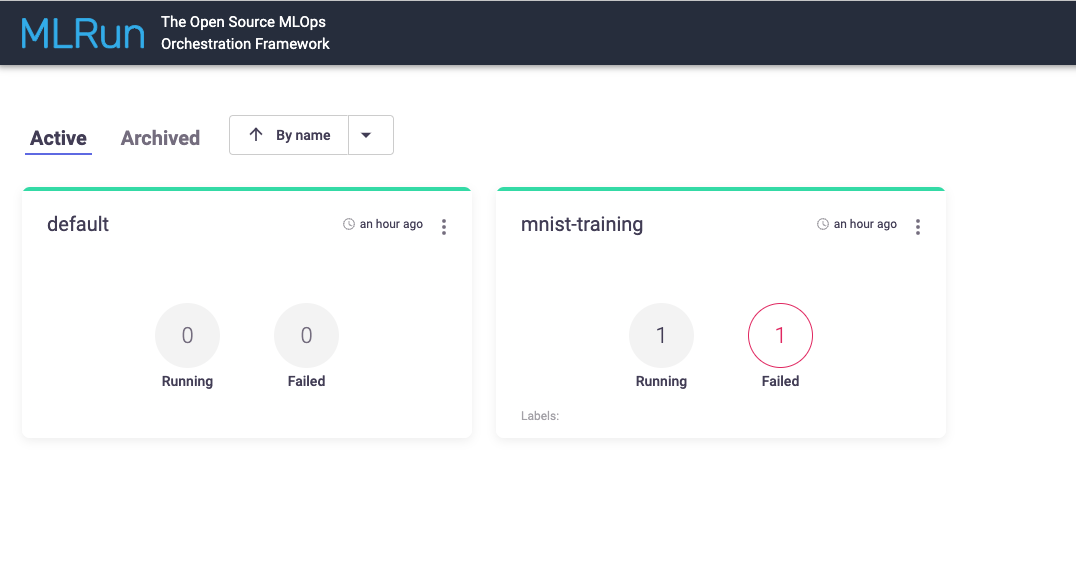
MLRun UI 的主页显示所有项目的列表。对于每个项目,你可以看到失败和正在运行的任务数量。
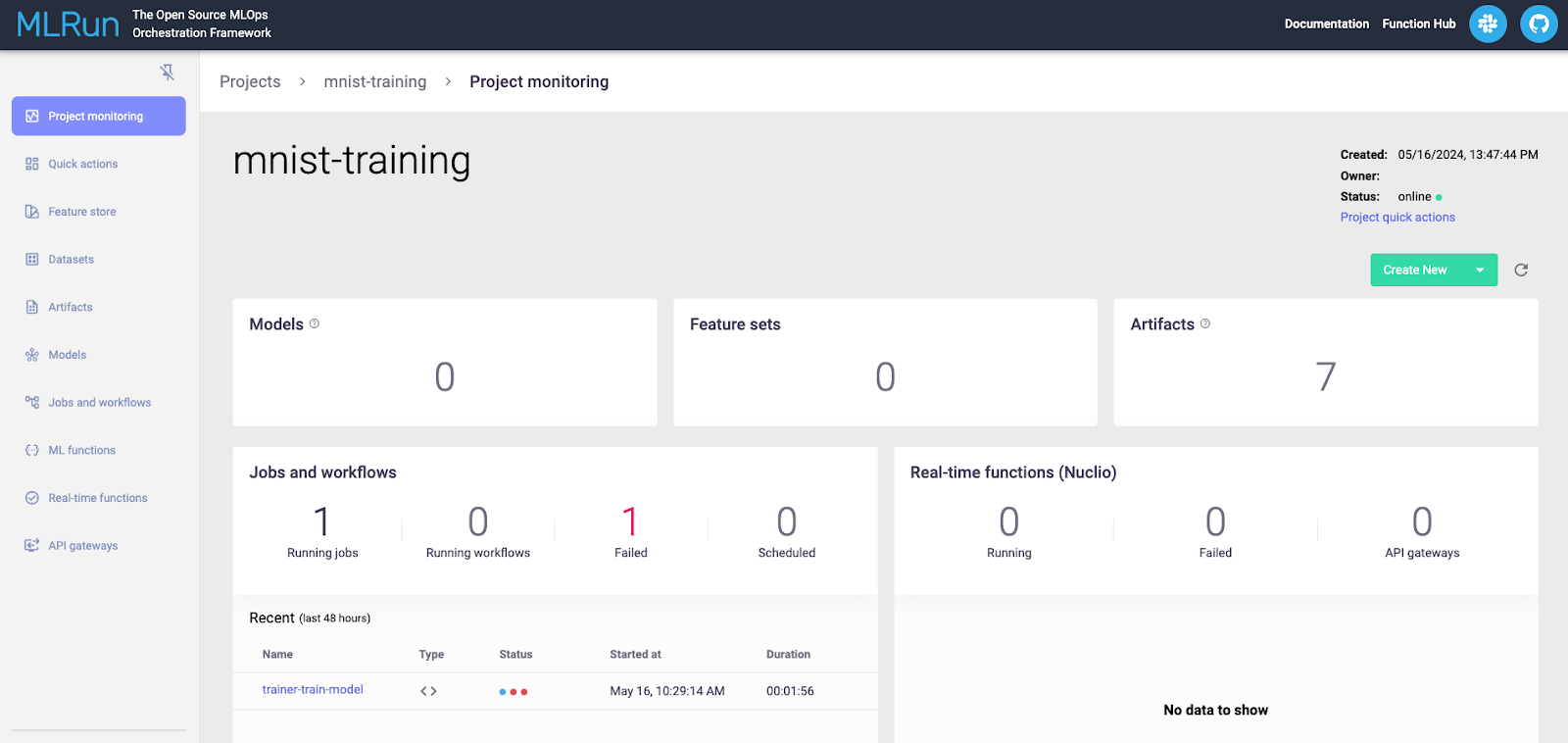
深入你的项目,你将看到更多关于你的项目的细节。
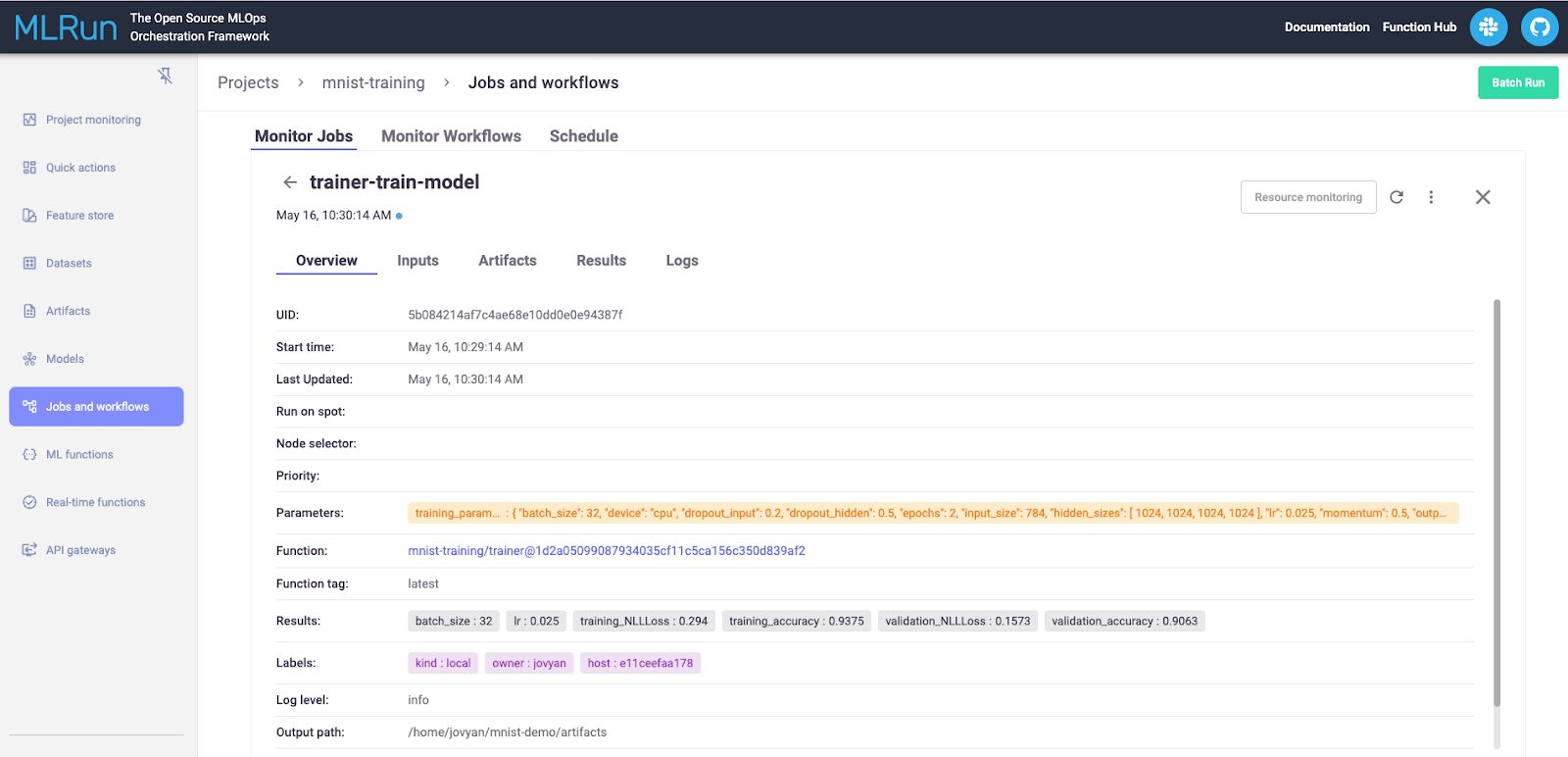
点击一个特定的任务,将把你带到最新的运行。在那里,你可以查看参数、输入、工件、结果和代码记录的任何输出。
总结和下一步
在这篇文章中,我从我上一次关于设置 MLRun 的帖子开始。我展示了如何使用 MLRun 来托管现有的模型代码,并且只需要进行最小的更改。但是,利用 MLRun 的跟踪功能的最佳方法是让 MLRun 管理你的模型的训练。
虽然将现有的代码迁移到 MLRun 是可能的,但这项技术并没有完全利用 MLRun 的自动化跟踪功能。更好的方法是使用 MLRun 的“mlrun_torch.train()”函数。这使得 MLRun 可以完全管理训练 - 工件、输入参数和指标将被记录下来。
如果你已经使用 MLRun 到此,请考虑接下来使用分布式训练和大型语言模型。
如果你有任何问题,请务必在Slack上与我们联系!MLOps Live Slack 工作空间的“mlrun”频道也是一个很棒的地方,如果你遇到问题,可以在这里获得帮助。
