现代数据湖与 MinIO:第一部分

现代数据湖现在建立在云存储之上,帮助组织利用对象存储的规模和经济效益,同时简化整体数据存储和分析流程。
在本系列文章的第一部分,我们将探讨对象存储与其他存储方式的不同之处,以及为什么将 Minio 这样的对象存储用于数据湖是有意义的。
什么是对象存储?
对象存储通常指平台组织存储单元的方式,这些单元称为对象。每个对象通常包含三个部分
- 数据本身。数据可以是任何你想存储的东西,从家庭照片到用于建造火箭的 400,000 页手册。
- 可扩展的元数据。元数据由创建对象存储的人员定义,它包含有关数据是什么、应该如何使用、机密性或其他与数据使用方式相关的上下文信息。
- 全局唯一的标识符。标识符是分配给对象的地址,因此可以在分布式系统中找到它。这样,即使不知道对象的物理位置(可能存在于数据中心的不同部分或世界各地),也可以找到它。
块存储与对象存储
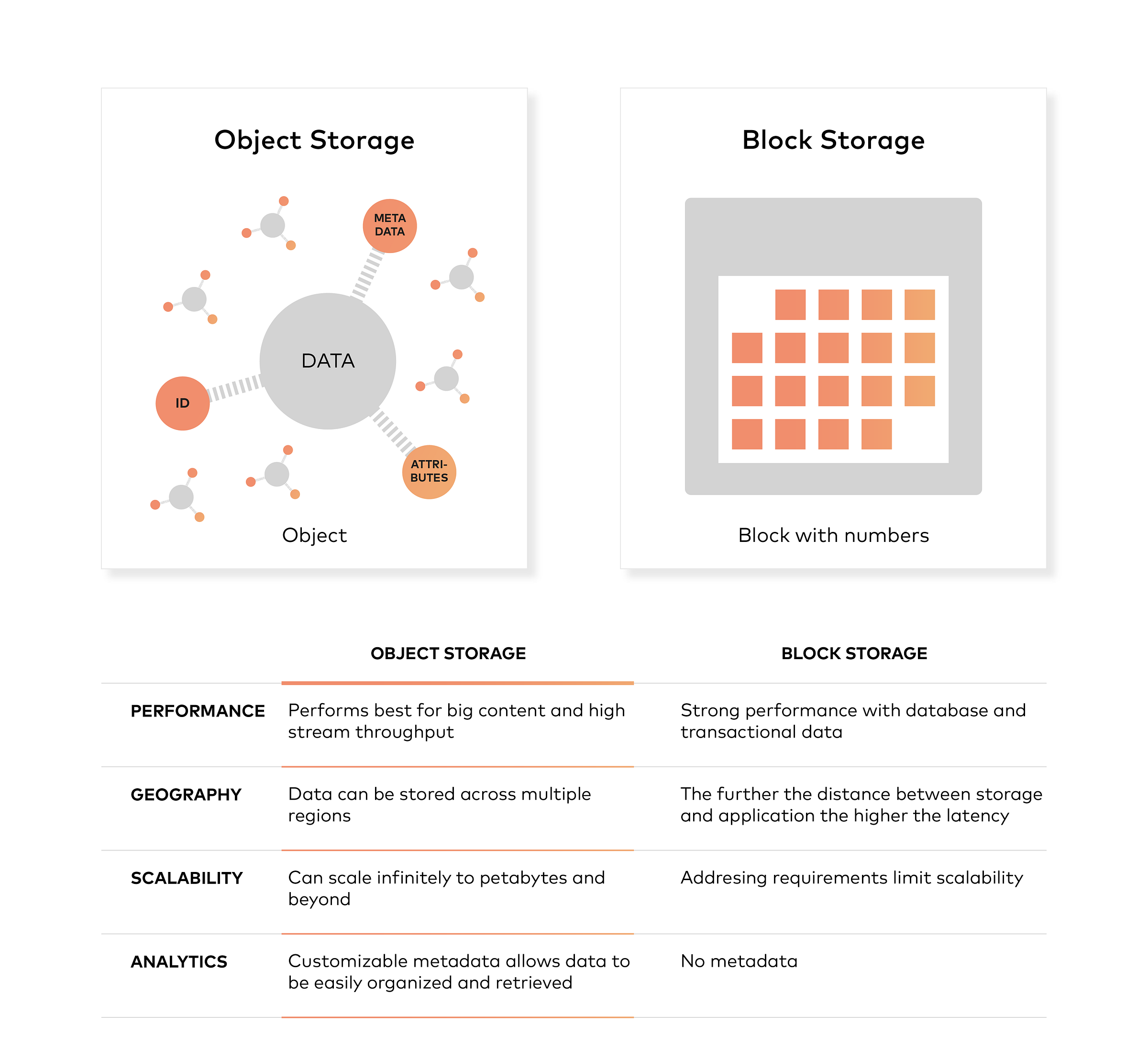
与块存储不同,对象存储不会将文件分割成原始数据块。相反,数据被存储为一个包含实际文件数据、元数据和唯一标识符的对象。请注意,元数据可以包含有关对象的任何文本信息。
现代企业数据中心越来越像私有云,以对象存储作为事实上的存储方式。对象存储提供更好的规模经济,确保数据以高可用性和高耐用性的方式在全球范围内可用。
为什么对象存储很重要?
Hadoop 曾经是数据湖的主流选择。但在当今技术快速发展的时代,已经出现了一种现代方法。现代数据湖基于对象存储,并使用 Apache Spark、Presto、Tensorflow 等工具进行高级分析和机器学习。
让我们回顾一下,了解事情是如何改变的。Hadoop 诞生于 2000 年代初,在过去五年左右的时间里获得了巨大的普及。事实上,由于许多公司致力于开源,所以五六年之前的大多数大数据项目都是基于 Hadoop 的。
简而言之,你可以将 Hadoop 看作具有两种主要功能
- 分布式文件系统 (HDFS) 用于持久化数据。
- 处理框架 (MapReduce) 允许你并行处理所有这些数据。
越来越多的组织开始想要处理他们所有的数据,而不仅仅是一部分数据。因此,Hadoop 因为其能够存储和处理新的数据源(包括系统日志、点击流以及传感器和机器生成的数据)而变得流行。
大约在 2008 年或 2009 年,这是一个改变游戏规则的时刻。在那个时候,Hadoop 非常适合其主要设计目标,即使用商品硬件构建本地集群来以低成本存储和处理这些新数据。
这是当时正确的选择,但今天不再是正确的选择。
Spark 出现
开源的好处是它一直在不断发展。开源的缺点是它也一直在不断发展。
我的意思是,你必须玩一场追赶的游戏,因为最最新、最大、最好的新项目不断涌现。所以让我们来看看现在正在发生的事情。
在过去几年中,出现了一个比 MapReduce 更新的框架:Apache Spark。从概念上讲,它与 MapReduce 类似。但关键的区别在于它针对内存而不是磁盘中的数据进行了优化。当然,这意味着在 Spark 上运行的算法将更快,通常快得多。
事实上,如果你今天开始一个新的“大数据”项目,并且没有与遗留 Hadoop 或 MapReduce 应用程序互操作的强制性需求,那么你应该使用 Spark。你仍然需要持久化数据,并且由于 Spark 已经与许多 Hadoop 发行版捆绑在一起,所以大多数本地集群都使用过 HDFS。这样做有效,但随着云的兴起,有一种更好的方法来持久化你的数据:对象存储。
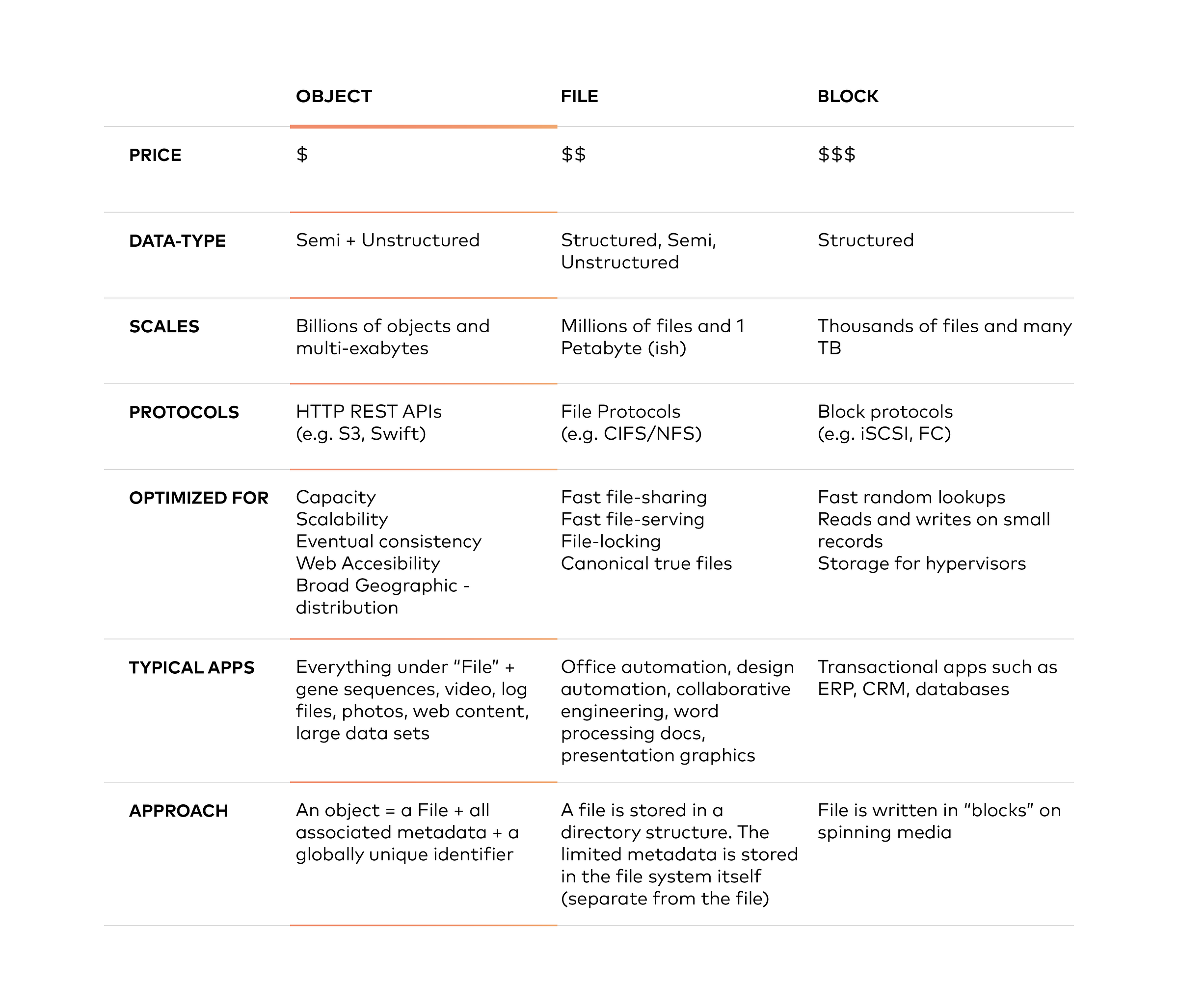
对象存储与文件存储和块存储的不同之处在于,它将数据保存在“对象”中,而不是块中,从而构成一个文件。元数据与该文件相关联,消除了文件存储中使用的层次结构的需要,对可以使用元数据的数量没有限制。所有内容都被放置在一个平坦的地址空间中,易于扩展。
对象存储提供多种优势
本质上,对象存储在大型内容和高流吞吐量方面表现出色。它允许数据存储在多个区域,无限扩展到 PB 级甚至更高,并提供可定制的元数据,以帮助检索文件。
许多公司,尤其是那些运行私有云环境的公司,将对象存储视为大型非结构化数据的长期存储库,这些数据需要出于合规性原因而保留。
但这不仅仅是为了合规性目的。公司使用对象存储来存储 Facebook 上的照片、Spotify 上的歌曲以及 Dropbox 中的文件。
最有可能让大多数人眼前一亮的因素是成本。对象存储的批量存储成本远低于 HDFS 所需的块存储。根据你在哪里购物,你会发现对象存储的成本大约是块存储的 1/3 到 1/5(请记住,HDFS 需要块存储)。这意味着在 HDFS 中存储相同数量的数据可能比将数据放入对象存储贵三到五倍。
所以,Spark 比 MapReduce 更快,而对象存储比 HDFS(具有块存储需求)更便宜。但让我们停止孤立地看待这两个组件,并将目光转向整体的新架构。
结合对象存储和 Spark 的好处
我们特别推荐的是,在云中基于对象存储和 Spark 构建数据湖。与基于 Hadoop 的数据湖相比,这种组合更快、更灵活且成本更低。让我们进一步解释一下。
在云中将对象存储与 Spark 相结合比传统的 Hadoop/MapReduce 配置更具弹性。如果你曾经尝试过向 Hadoop 集群添加和删除节点,你就会明白我的意思。这是可以做到的,但并不容易,而在云中,相同的任务就变得轻而易举了。
但弹性还有另一个方面。使用 Hadoop,如果你想添加更多存储空间,你需要通过添加更多节点(以及计算能力)来实现。如果你需要更多存储空间,你将获得更多计算能力,无论你是否需要它。
使用对象存储架构,情况有所不同。如果你需要更多计算能力,你可以启动一个新的 Spark 集群,而将你的存储保持不变。如果你刚获得了几 TB 的新数据,那么只需扩展你的对象存储即可。在云中,计算和存储不仅是弹性的,它们还独立地具有弹性。这是件好事,因为你对计算和存储的需求也是独立地具有弹性的。
使用对象存储和 Spark 可以获得什么?
业务敏捷性:所有这一切意味着你的性能可以得到提升。你可以根据自己的需求启动许多不同的计算集群。一个拥有大量 RAM、重型通用计算或用于机器学习的 GPU 的集群,你可以在需要时以及同时完成所有这些操作。
通过根据你的计算需求定制你的集群,你可以更快地获得结果。当你不使用集群时,你可以关闭它,这样你就不会为它付费。
使用对象存储作为数据湖中数据的持久存储库。在云中,你只需为存储的数据量付费,并且可以随时添加或删除数据。
这种新发现的资源分配和使用灵活性的实际效果是提高了企业的敏捷性。当出现新的需求时,您可以启动独立的集群来满足该需求。如果另一个部门想要使用您的数据,这也是可能的,因为所有这些集群都是独立的。
稳定性和可靠性:在较长的时间段内运行稳定可靠的 Hadoop 集群会带来比预期更多的复杂性。
如果您有本地解决方案,升级您的集群通常意味着将整个集群关闭并升级所有内容,然后再重新启动。但这样做意味着在升级过程中您无法访问该集群,如果遇到困难,这可能需要很长时间。当您再次启动它时,您可能会发现新的问题。
滚动升级(逐节点)是可能的,但仍然是一个非常困难的过程。因此,它并不被广泛推荐。不仅仅是升级和补丁,运行和调整 Hadoop 集群可能涉及调整多达 500 个不同的参数。
解决此类问题的一种方法是通过自动化。
但云为您提供了另一种选择。完全托管的 Spark 和对象存储服务可以为您完成所有这些工作。备份、复制、修补、升级、调整,所有这些都外包了。
在云中,稳定性和可靠性的责任从您的 IT 部门转移到了云供应商,无论是私有云还是公有云。
降低 TCO:将管理对象存储/Spark 配置的工作转移到云端还有另一个优势。您实际上是在将存储管理工作外包给供应商。这是一种让您的员工参与并致力于激动人心的项目,同时节省成本并有助于降低 TCO 的方法。
这种新架构的较低 TCO 不仅仅是减少人工成本,虽然这很重要。请记住,对象存储比 HDFS 所需的块存储更便宜。独立的弹性扩展确实意味着按需付费。
本质上
我们将这种基于对象存储和 Spark 的新型数据湖架构的优势归纳为三个
- 提高业务敏捷性
- 更高的稳定性和可靠性
- 降低总拥有成本
在本系列的下一篇文章也是最后一篇文章中,我们将了解一般的对象存储架构,然后了解如何将 Minio 对象存储与 Apache Spark 和 Presto 等工具集成,以简化整个组织的数据流。