基于 MinIO 的现代数据湖:第 2 部分
在本系列的第一部分,我们了解了为什么像 Minio 这样的对象存储系统是构建现代数据湖的完美方法,这些数据湖敏捷、经济高效且具有极强的可扩展性。
在这篇文章中,我们将深入了解对象存储,特别是 Minio,然后了解如何将 Minio 与 Apache Spark 和 Presto 等工具连接起来以进行分析工作负载。
对象存储系统的架构
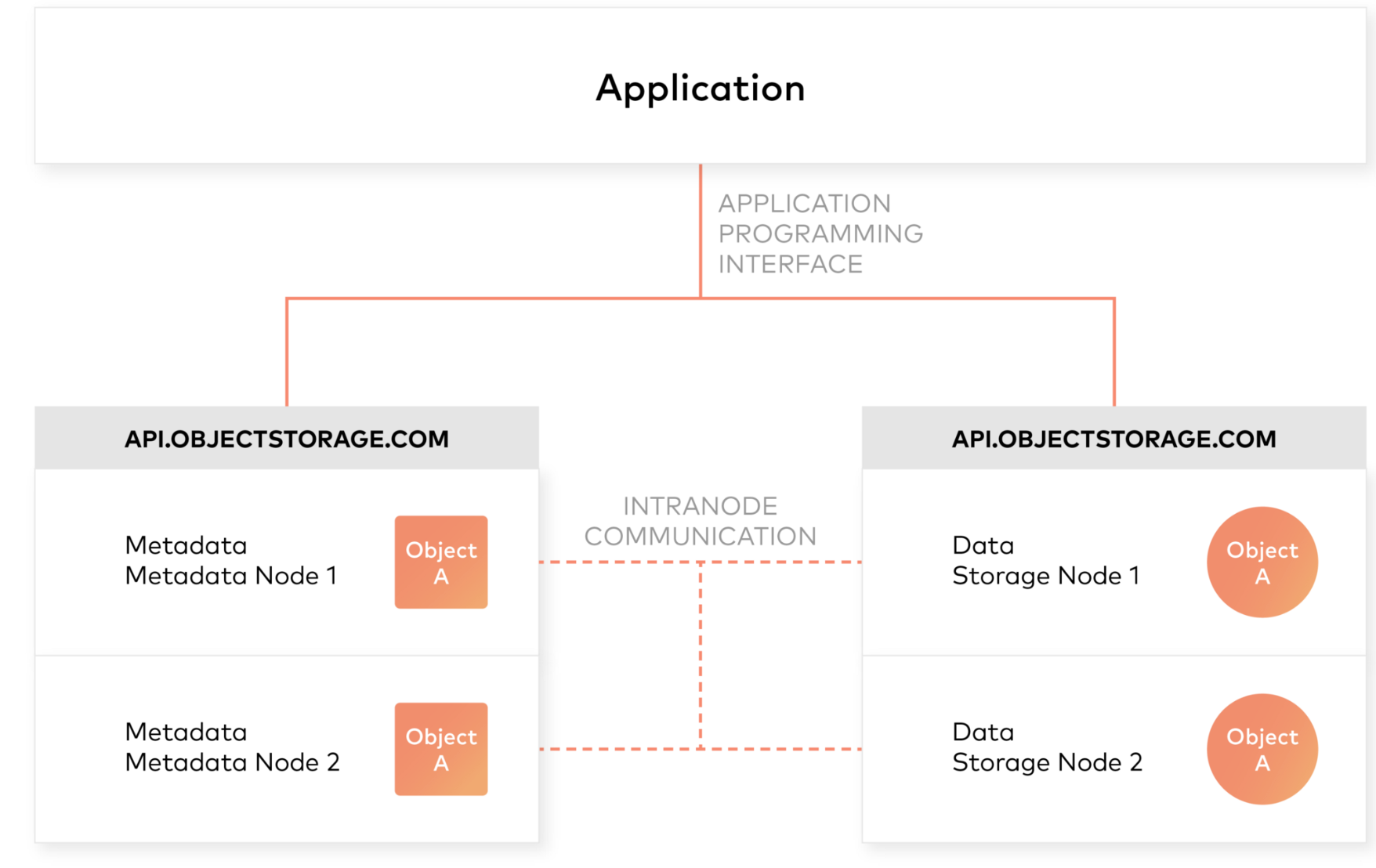
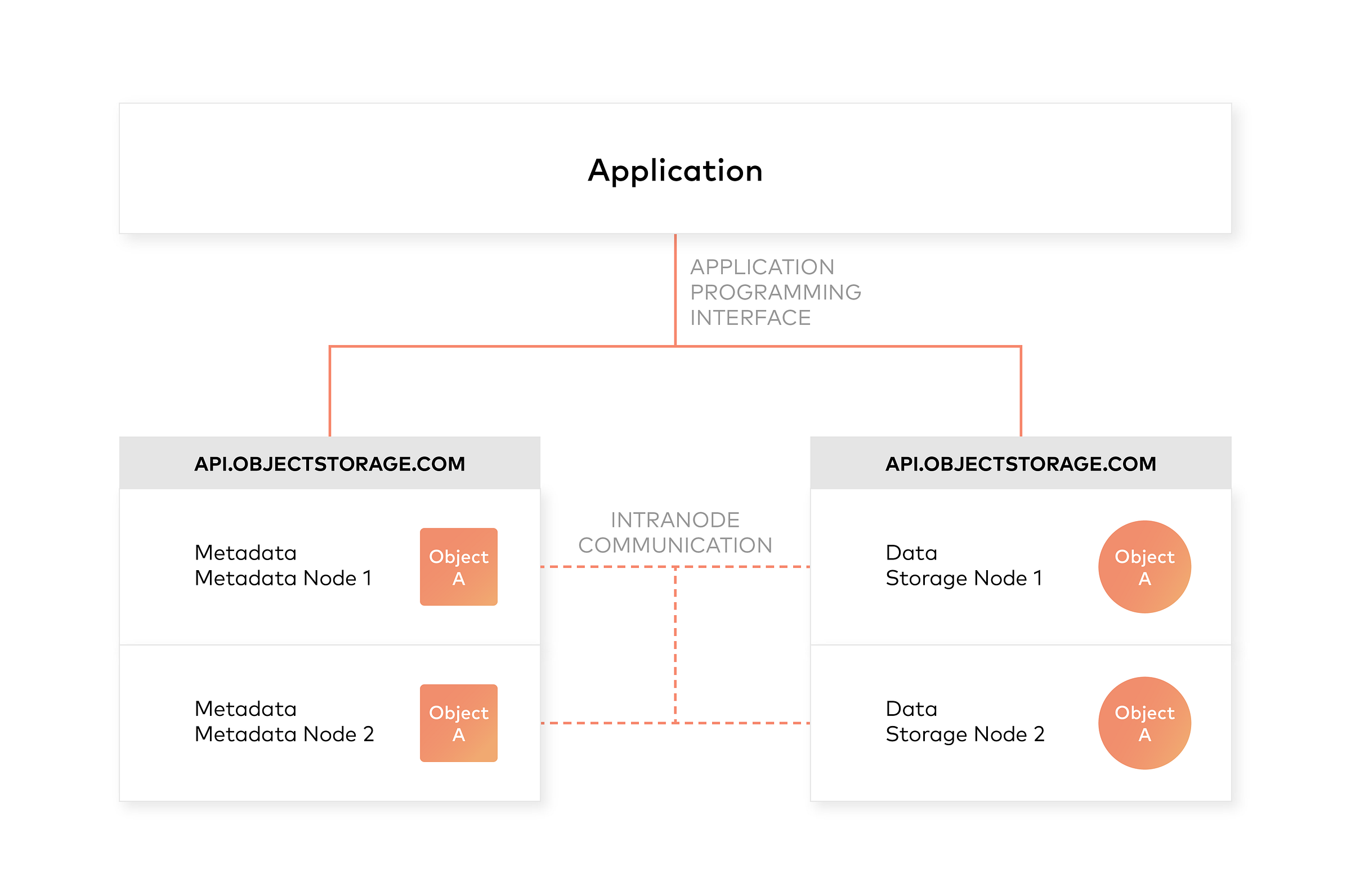
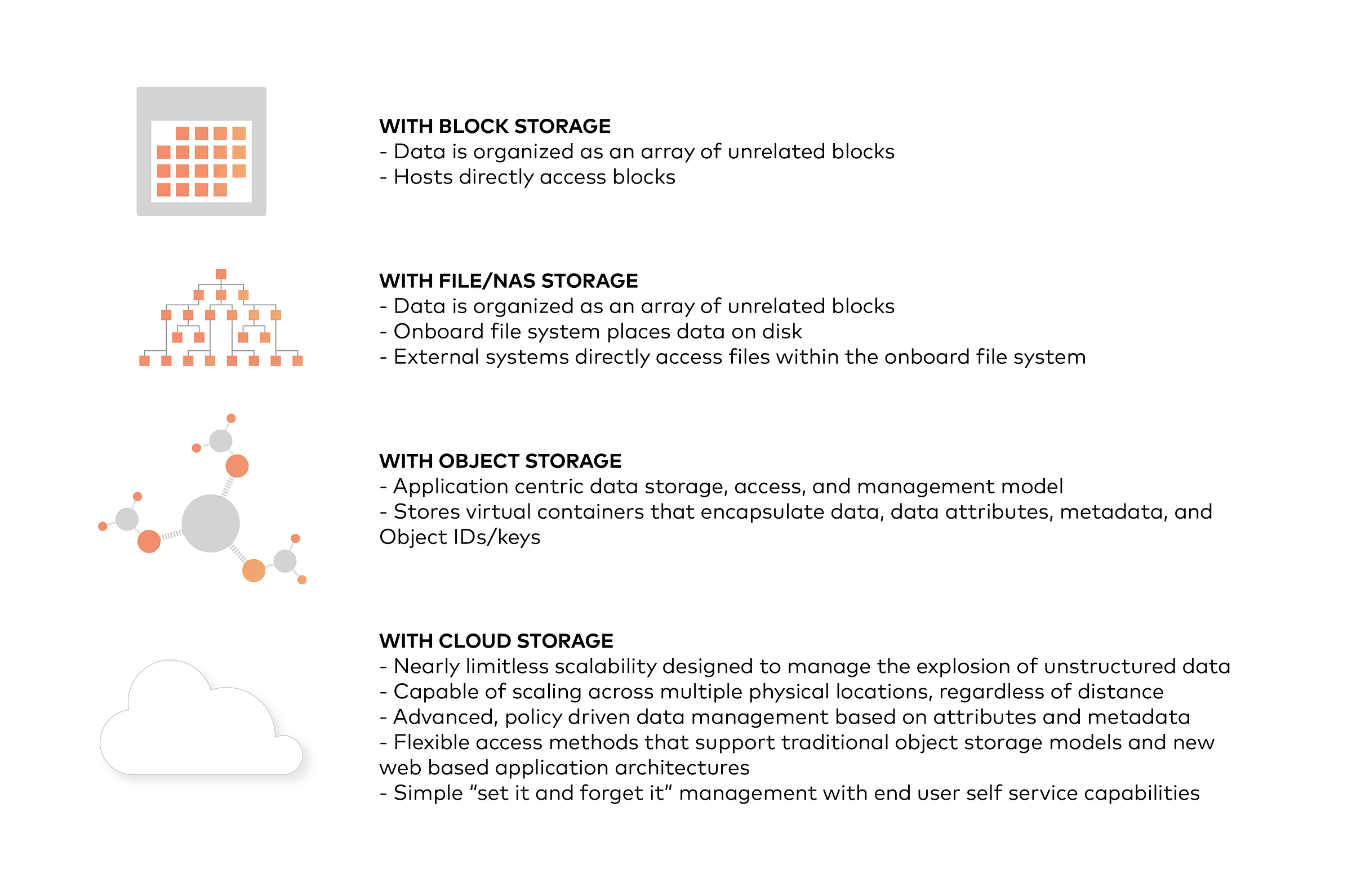
对象存储的设计原则之一是从管理员和应用程序中抽象出一些底层存储层。因此,数据以对象而不是文件或块的形式公开和管理。对象包含其他描述性属性,可用于更好的索引或管理。管理员不必执行底层存储功能,例如构建和管理逻辑卷以利用磁盘容量或设置RAID级别以处理磁盘故障。
对象存储还允许通过不仅仅是文件名和文件路径来寻址和识别单个对象。对象存储在存储桶内或整个系统中添加一个唯一的标识符,以支持更大的命名空间并消除名称冲突。
在对象中包含丰富的自定义元数据
对象存储明确地将文件元数据与数据分离以支持其他功能。与文件系统中的固定元数据(文件名、创建日期、类型等)相反,对象存储提供了完整的函数、自定义、对象级元数据,以便
- 捕获特定于应用程序或特定于用户的信息以用于更好的索引目的
- 支持数据管理策略(例如,将对象从一个存储层移动到另一个存储层的策略)
- 跨多个单个节点和集群集中管理存储
- 优化元数据存储(例如,封装的、数据库或键值存储)和缓存/索引(当权威元数据与对象内部的元数据封装在一起时)独立于数据存储(例如,非结构化二进制存储)
将 Minio 对象存储与 Hadoop 3 集成
使用Minio 文档在您首选的平台上部署 Minio。然后,按照步骤了解如何将 Minio 与 Hadoop 集成。
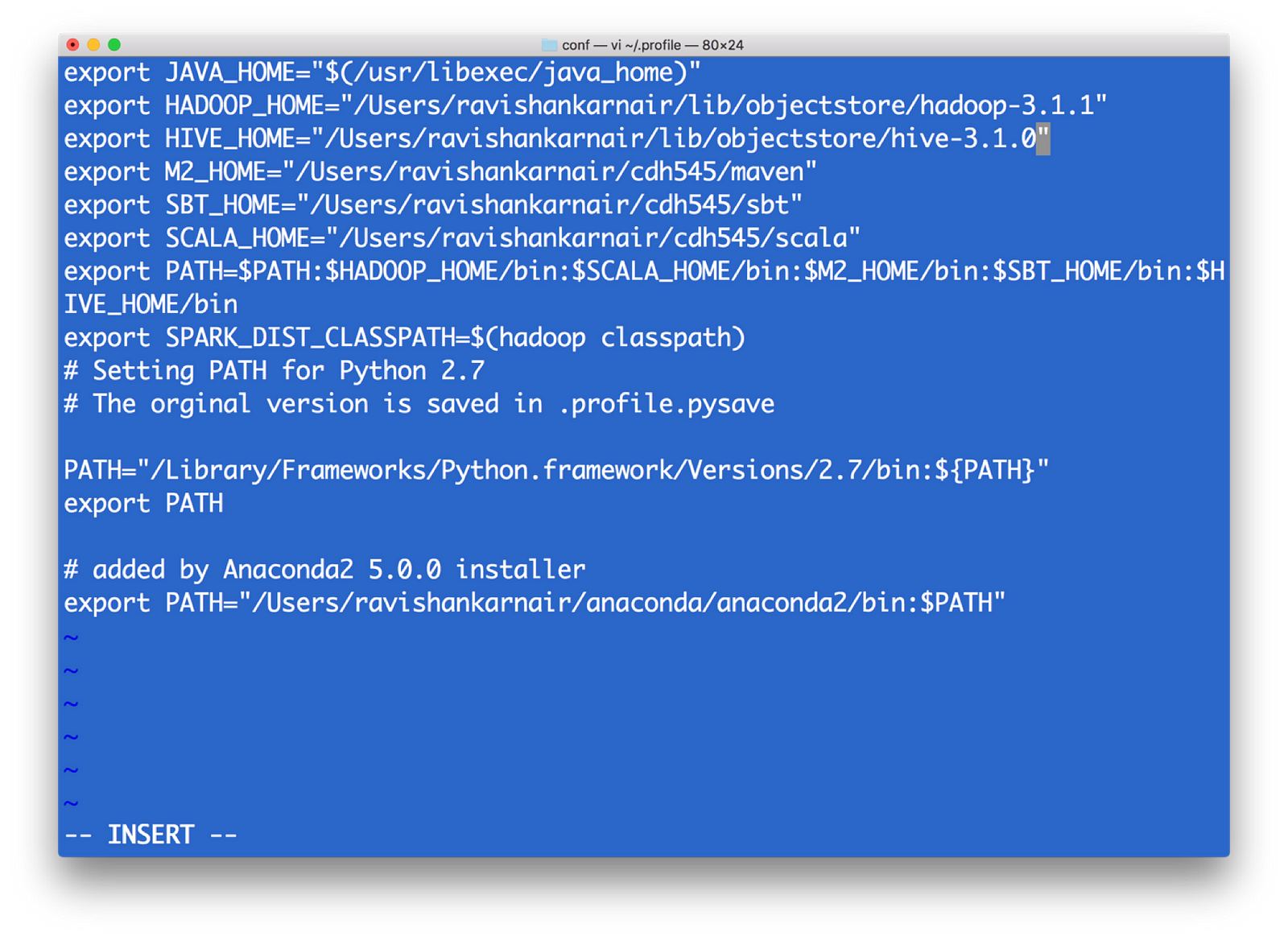
- 首先,安装 Hadoop 3.1.0。下载 tar 并解压缩到一个文件夹中。创建 .bashrc 或 .profile(在 Windows 中,路径和环境变量)如下
2) 所有与文件系统相关的 Hadoop 配置都保存在目录 etc/hadoop 中(这是相对于安装根目录的——我将调用安装根目录为 $HADOOP_HOME)。我们需要在 core-site.xml 中进行更改以指向新的文件系统。请注意,当我们写入 hdfs:// 以访问 Hadoop 文件系统时,默认情况下它会连接到 core-site.xml 中配置的底层默认 FS,该 FS 以 128MB 的块进行管理(Hadoop 版本 1 为 64 MB),本质上表明 hdfs 是块存储。现在我们有了对象存储,访问协议不能是 hdfs://。相反,我们需要使用另一个协议,最常用的协议是 s3a 。S3 代表简单存储服务,由亚马逊创建,并广泛用作对象存储的访问协议。因此,在 core-site.xml 中,我们需要写入有关当命令以 s3a 开头时底层代码应该执行的操作的信息。有关详细信息,请参阅以下文件并将其更新到 Hadoop 安装的 core-site.xml 中。<property>
<name>fs.s3a.endpoint</name>
<description>要连接到的 AWS S3 端点。</description><value>https://:9000</value>
<! — 注意:以上值是从 minio 启动窗口获取的 — -></property>
<property>
<name>fs.s3a.access.key</name>
<description>AWS 访问密钥 ID。</description>
<value>UC8VCVUZMY185KVDBV32</value>
<! — 注意:以上值是从 minio 启动窗口获取的 — -></property>
<property>
<name>fs.s3a.secret.key</name>
<description>AWS 密钥。</description>
<value>/ISE3ew43qUL5vX7XGQ/Br86ptYEiH/7HWShhATw</value>
<! — 注意:以上值是从 minio 启动窗口获取的 — ->
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
<description>启用 S3 路径样式访问。</description>
</property>
3) 为了启用 s3a,我们需要将一些 jar 文件复制到 $HADOOP_HOME/share/lib/common/lib 目录。请注意,您还需要将您的 Hadoop 版本与您下载的 jar 文件匹配。我使用了 Hadoop 版本 3.1.1,因此我使用了 hadoop-aws-3.1.1.jar。以下是所需的 jar 文件:hadoop-aws-3.1.1.jar //应与您的 Hadoop 版本匹配
aws-java-sdk-1.11.406.jar
aws-java-sdk-1.7.4.jar
aws-java-sdk-core-1.11.234.jar
aws-java-sdk-dynamodb-1.11.234.jar
aws-java-sdk-kms-1.11.234.jar
aws-java-sdk-s3–1.11.406.jar
httpclient-4.5.3.jar
joda-time-2.9.9.jar
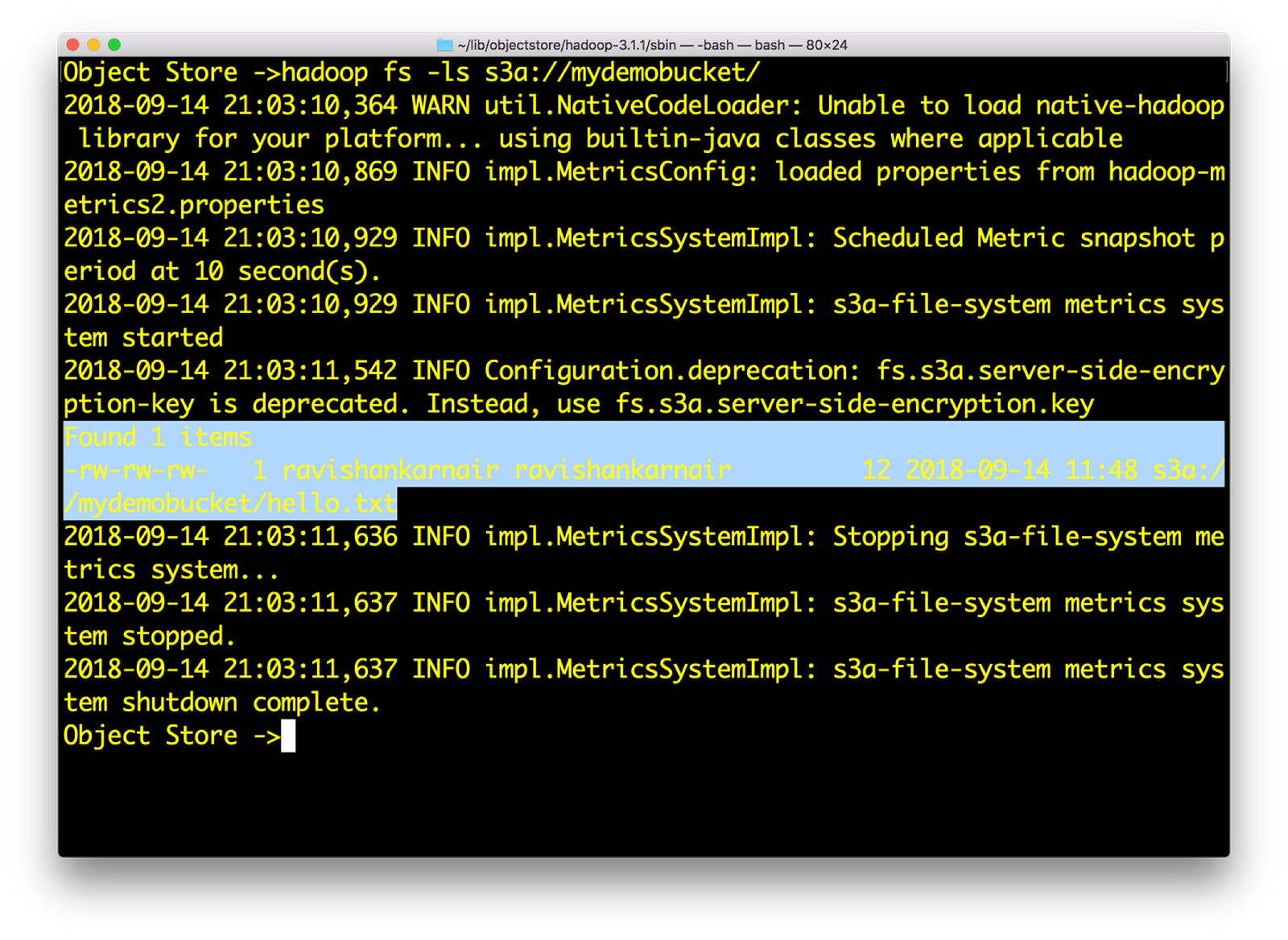
6) 现在在本地创建一个包含随机文本的示例文件 res.txt。然后输入
hadoop fs –put res.txt s3a://mydemobucket/res.txt
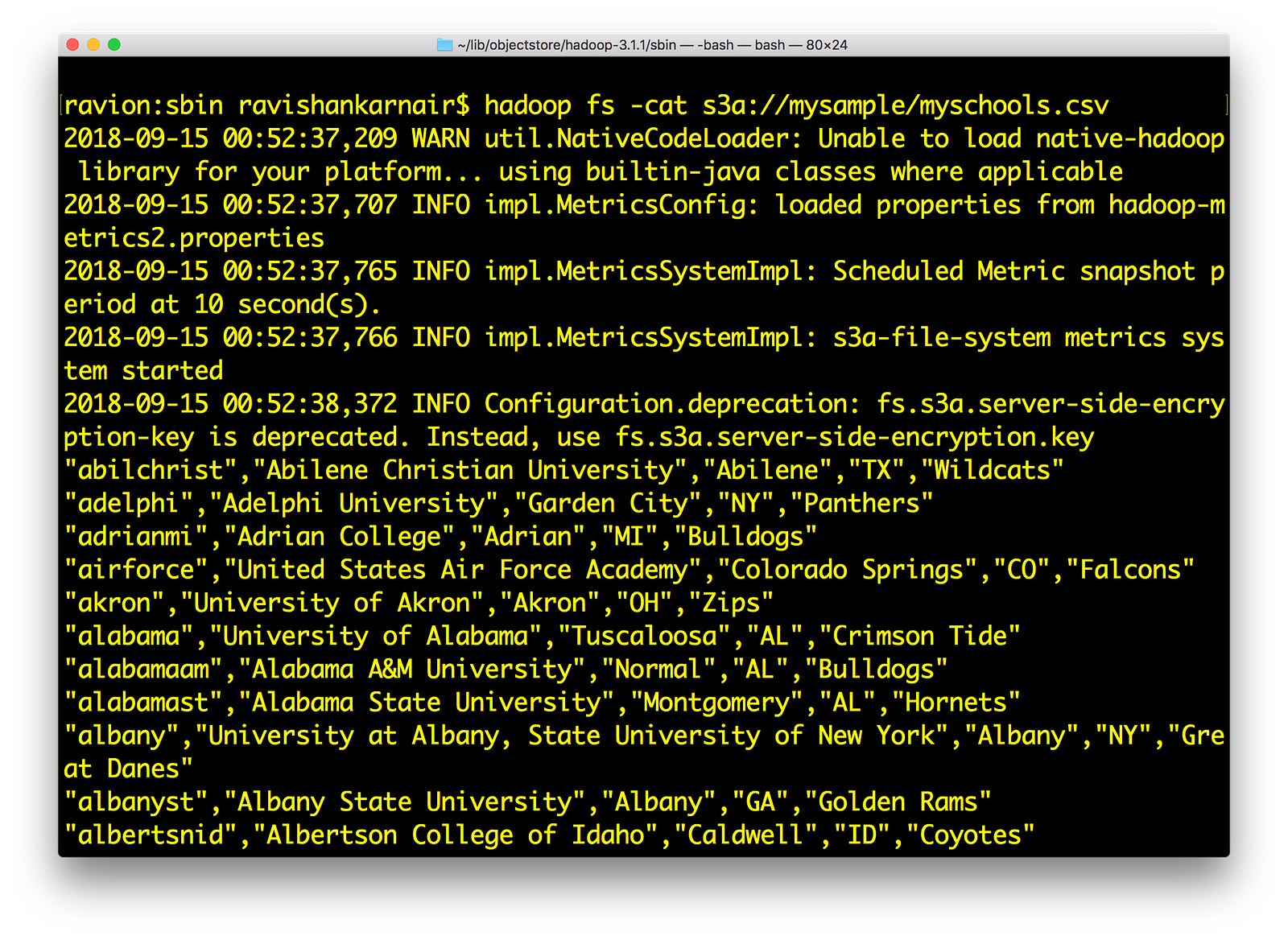
此外,尝试对您可能拥有的任何文件使用 hadoop fs –cat 命令
如果这一切对您都有效,我们就成功地使用 s3a:// 将 Minio 与 Hadoop 集成。
将 Minio 对象存储与 HIVE 3.1.0 集成
- 下载与 Apache Hadoop 3.1.0 兼容的最新版本的 HIVE。我使用了 apache-hive-3.1.0。解压缩下载的 bin 文件。让我们将解压缩的目录称为 hive-3.1.0
2) 首先将您在上面步骤 3 中使用的所有文件(在 Hadoop 集成部分)复制到 $HIVE_HOME/lib 目录
3) 创建 hive-site.xml。确保您已运行 MYSQL 以用作元存储。创建一个用户(在本例中为 ravi)<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://:3307/objectmetastore?createDatabaseIfNotExist=true</value>
<description>元数据存储在 MySQL 服务器中</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>MySQL JDBC 驱动程序类</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>ravi</value>
<description>用于连接到 mysql 服务器的用户名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>ravi</value>
<description>用于连接到 mysql 服务器的密码</description>
</property>
<property>
<name>fs.s3a.endpoint</name>
<description>要连接到的 AWS S3 端点。</description><value>https://:9000</value>
</property>
<property>
<name>fs.s3a.access.key</name>
<description>AWS 访问密钥 ID。</description>
<value>UC8VCVUZMY185KVDBV32</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<description>AWS 密钥。</description>
<value>/ISE3ew43qUL5vX7XGQ/Br86ptYEiH/7HWShhATw</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
<description>启用 S3 路径样式访问。</description>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>s3a://hive/warehouse</value>
</property>
</configuration>
4) 由于是第一次,我们需要运行一次 metatool。将 $HIVE_HOME 和 bin 添加到环境变量中。请参阅上面的步骤 1。
5) 在 minio 中,创建一个名为 hive 的存储桶和一个名为 warehouse 的目录。我们必须有 s3a://hive/warehouse 可用。
6) 引用您的 ~/.profile。请将 MYSQL 驱动程序 (mysql-connector-java-x.y.z.jar) 复制到 $HIVE_HOME/lib。然后运行 metatool 如下
7) 通过 $HIVE_HOME/bin/hiveserver2 start 启动 Hive 服务器和 Meta 存储
$HIVE_HOME/bin/hiveserver2 --service metastore
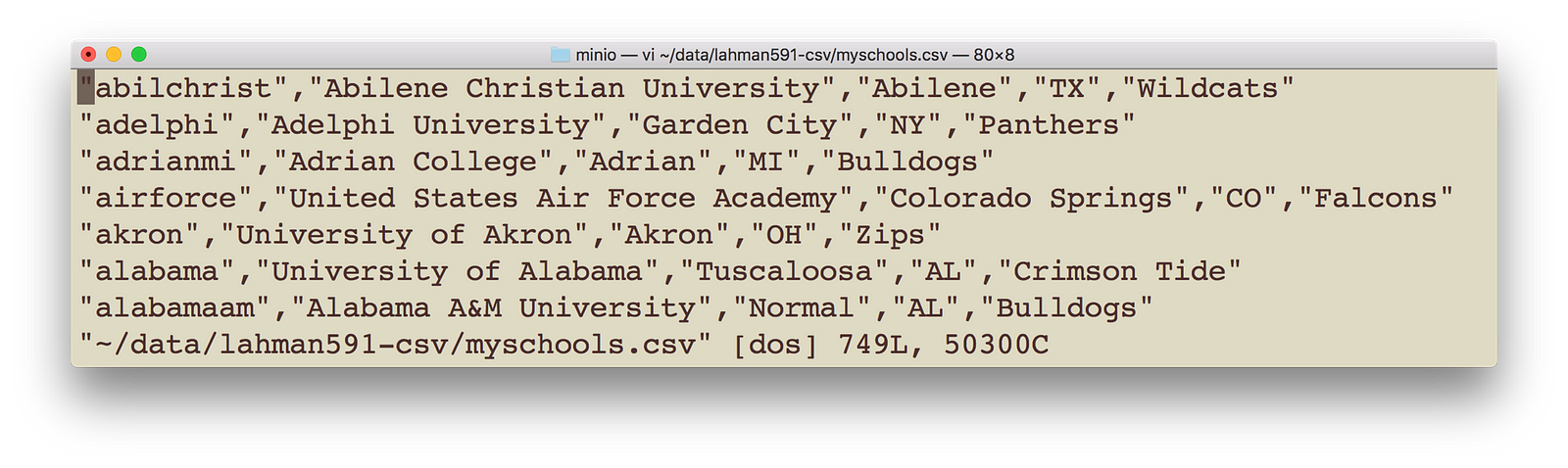
8) 将一些数据文件复制到我们之前创建的 mydemobucket 中。您可以使用上面步骤 6 中的 minio 客户端。我有 myschools.csv,其中包含 schoolid、schoolname、schoolcity、schoolstate 和 schoolnick。该文件如下
使用适当的更改执行以下命令以指向您的数据文件位置和名称。确保将要复制的数据带到本地。
10) 创建一个 HIVE 表,并将数据指向 s3。请注意,您必须给出父目录,而不是文件名。我突出显示了在您给出文件名时可能收到的错误消息
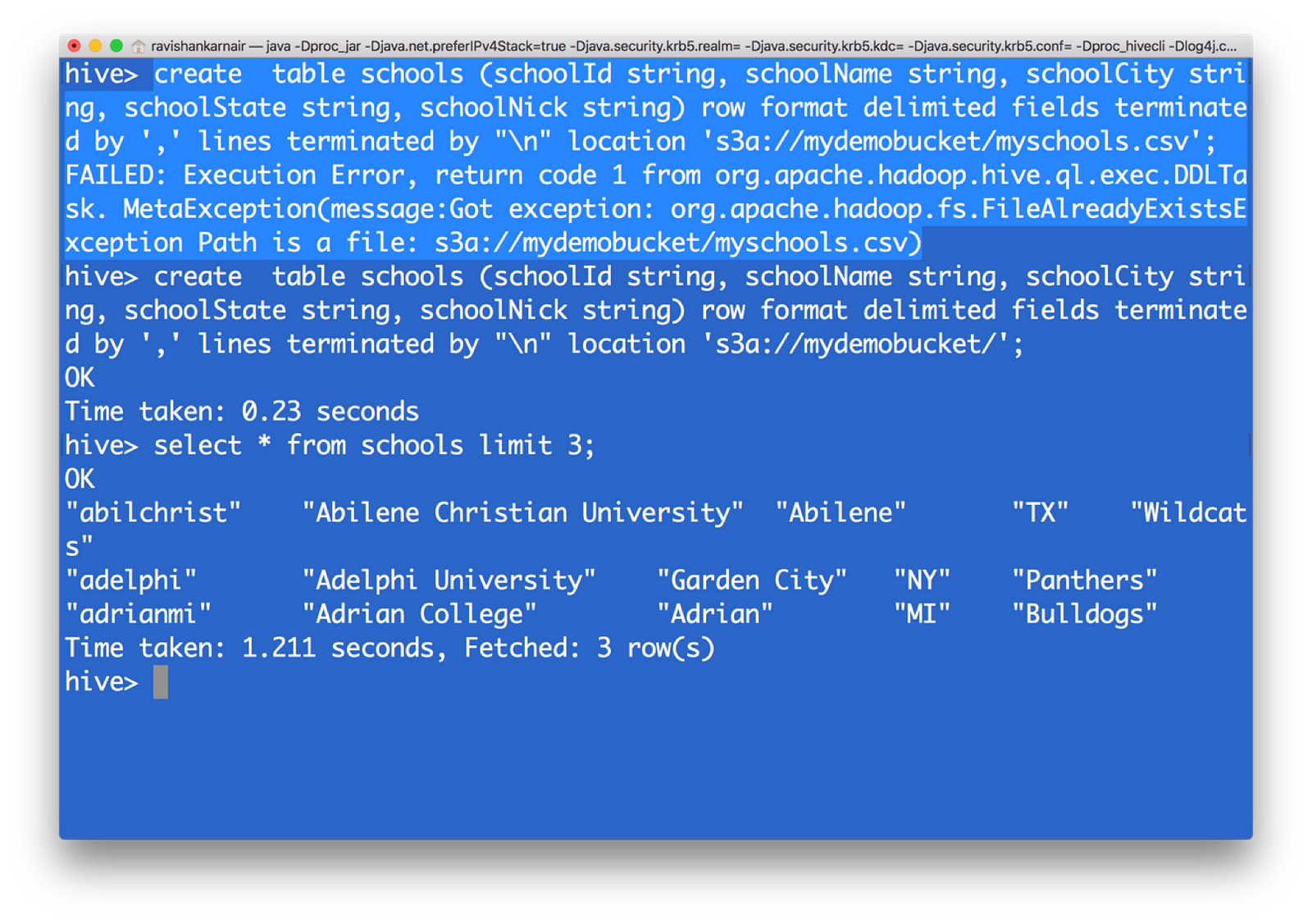
您现在已从 s3 数据创建了一个 HIVE 表。这意味着,在底层文件系统为 S3 的情况下,我们可以创建一个数据仓库,而无需依赖 HDFS。
将 Presto——统一数据架构平台与 Minio 对象存储集成
您现在可能需要另一个重要组件:当您迁移到对象存储时,如何将数据与现有系统结合?您可能希望将组织中 MYSQL 数据库中的数据与 HIVE(位于 S3 上)中的数据进行比较。这里就出现了世界上顶尖且免费(开源)的统一数据架构系统之一——Facebook 的 presto。
现在让我们将 presto 与整个系统集成。从https://github.com/prestodb/presto下载最新版本。按照部署说明进行操作。至少,我们需要 presto 服务器和 presto 客户端来访问服务器。它是一个分布式 SQL 查询引擎,允许您编写 SQL 以从多个系统获取数据,并提供丰富的 SQL 函数集。
- 安装 Presto。您将从根目录获得以下目录结构。在 catalog 目录中,您将提及 Presto 需要查询的连接器。连接器是 Presto 可以查询的系统。Presto 附带了许多默认连接器。
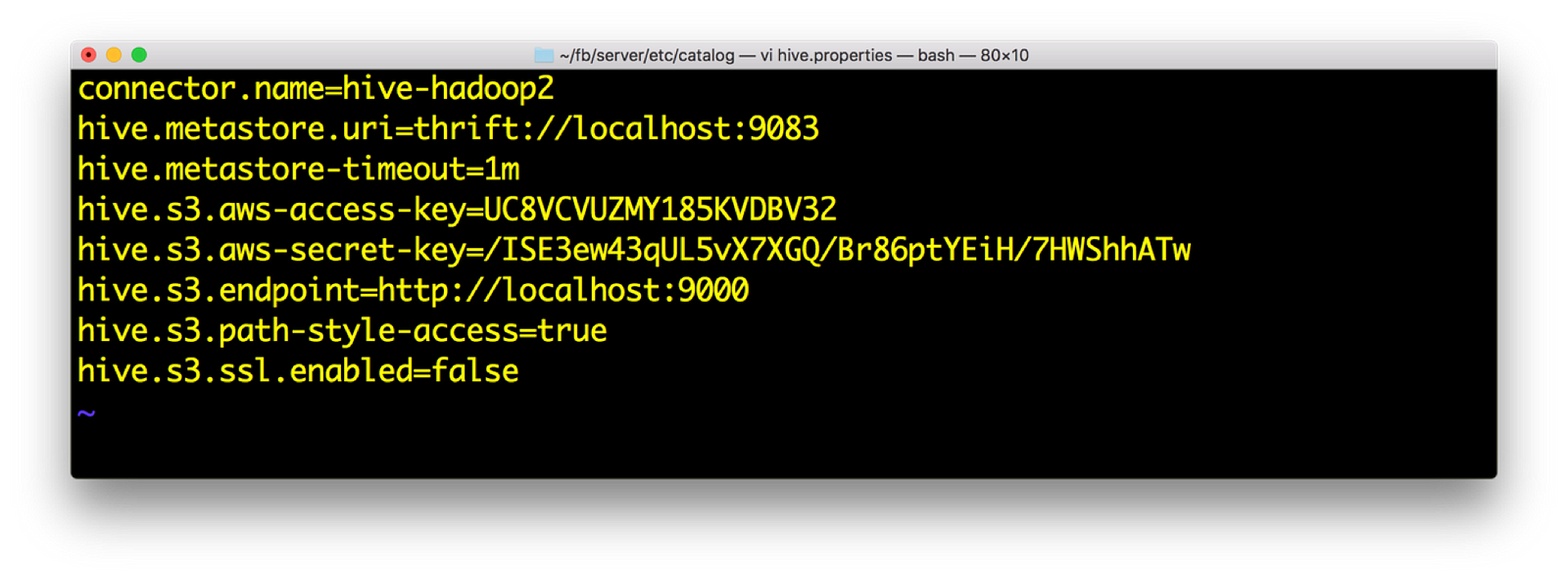
2) 打开 hive.properties。我们应该有以下数据。访问密钥和密钥再次从 minio 启动屏幕获取
4) 运行 Presto 客户端。通过以下命令完成
5) 在 Presto 中,您需要使用 catalogname.databasename.tablename 格式获取数据。我们的目录名称为 HIVE,数据库为 default,表名为 schools。因此

6) 您现在可以将 mysql 目录与 hive 目录连接起来,无缝地统一来自多个系统的数据。请参阅 Presto 中下面的查询(只是一个交叉连接查询示例)

集成 Spark——与 Minio 对象存储的统一分析
在之前的步骤中,我们已经完成了运行 Spark 针对 Minio 的所有先决条件。这包括获取正确的 jar 文件并在 Hadoop 3.1.1 中设置 core-site.xml。值得注意的是,您需要下载不包含 Hadoop 的 Spark 版本。原因是 Spark 尚未针对 3.1.1 Hadoop 进行认证,因此包含 Hadoop 的 Spark 将与 jar 文件存在许多冲突。您可以从 https://archive.apache.org/dist/spark/spark-2.3.1/ 下载不包含 Hadoop 的 Spark
1) 使用前面“与 Hadoop 集成”部分步骤 3 中提到的所有 jar 文件启动 Spark shell。您可以创建一个包含所有已复制 jar 文件的 bin 目录。或者参考您之前使用的 jar 文件。
2) 让我们在 Spark 中创建一个 RDD。输入
spark.sparkContext.hadoopConfiguration.set(“fs.s3a.endpoint”, “https://:9000");
spark.sparkContext.hadoopConfiguration.set(“fs.s3a.access.key”, “UC8VCVUZMY185KVDBV32”);
spark.sparkContext.hadoopConfiguration.set(“fs.s3a.secret.key”, “/ISE3ew43qUL5vX7XGQ/Br86ptYEiH/7HWShhATw”);
spark.sparkContext.hadoopConfiguration.set(“fs.s3a.path.style.access”, “true”);
spark.sparkContext.hadoopConfiguration.set(“fs.s3a.connection.ssl.enabled”, “false”);
spark.sparkContext.hadoopConfiguration.set(“fs.s3a.impl”, “org.apache.hadoop.fs.s3a.S3AFileSystem”);
val b1 = sc.textFile(“s3a://mydemobucket/myschools.csv”)
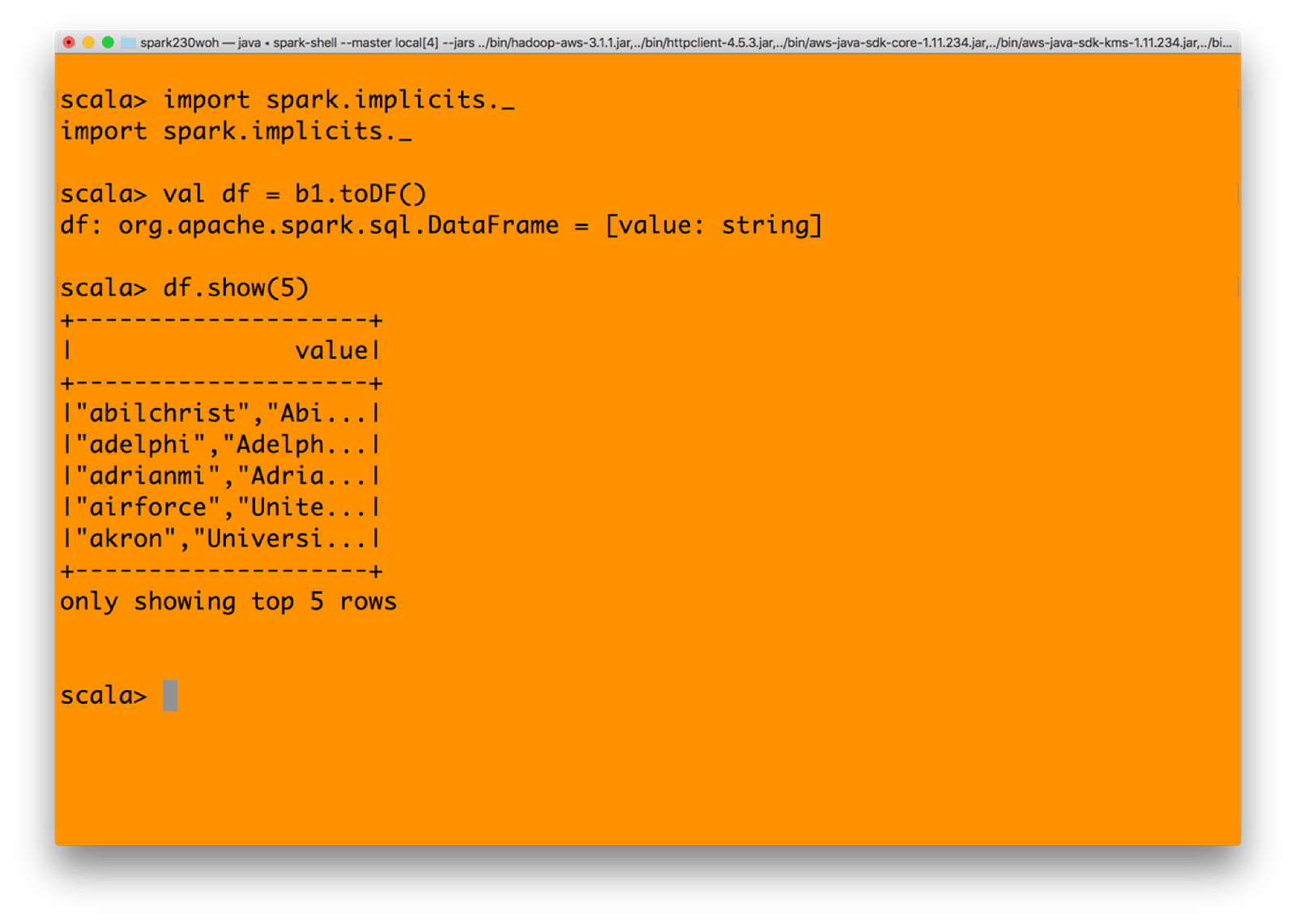
3) 您可以将 RDD 转换为 DataFrame,然后获取值
4) 最后,让我们使用 Spark 通过 s3 协议将数据写回 Minio 对象存储。确保您在执行以下命令之前已创建了一个名为 spark-test 的存储桶。(假设 resultdf 是一个存在的存储桶)
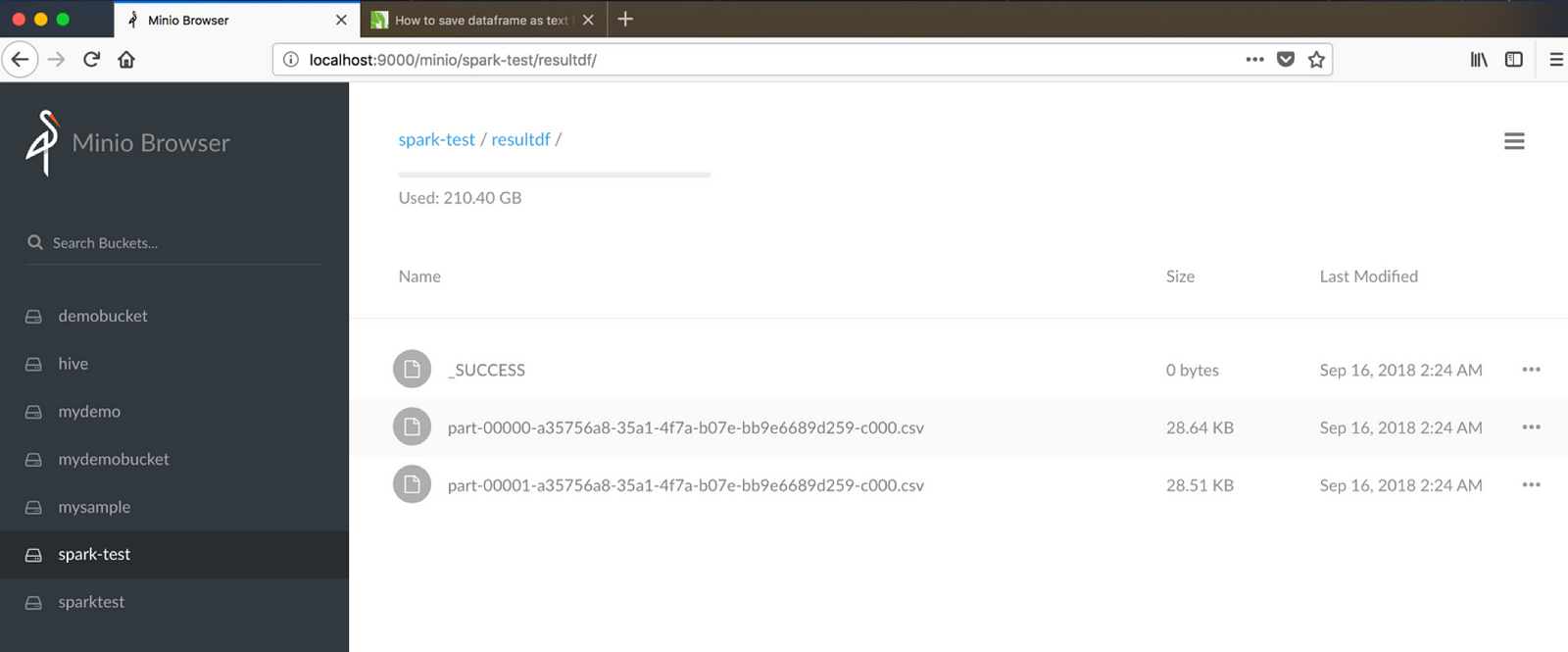
集成 Spark——我们是在写入文件还是对象?
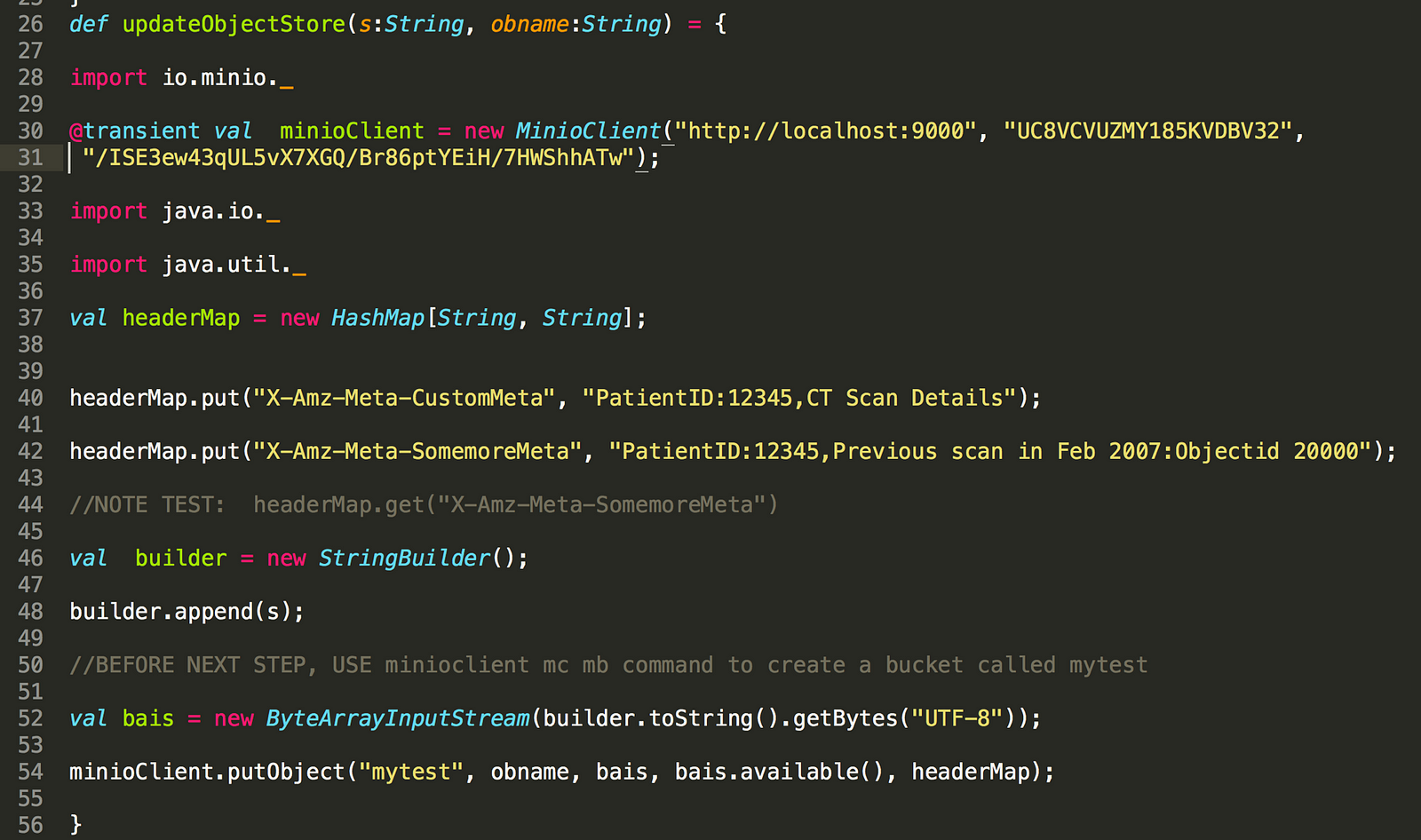
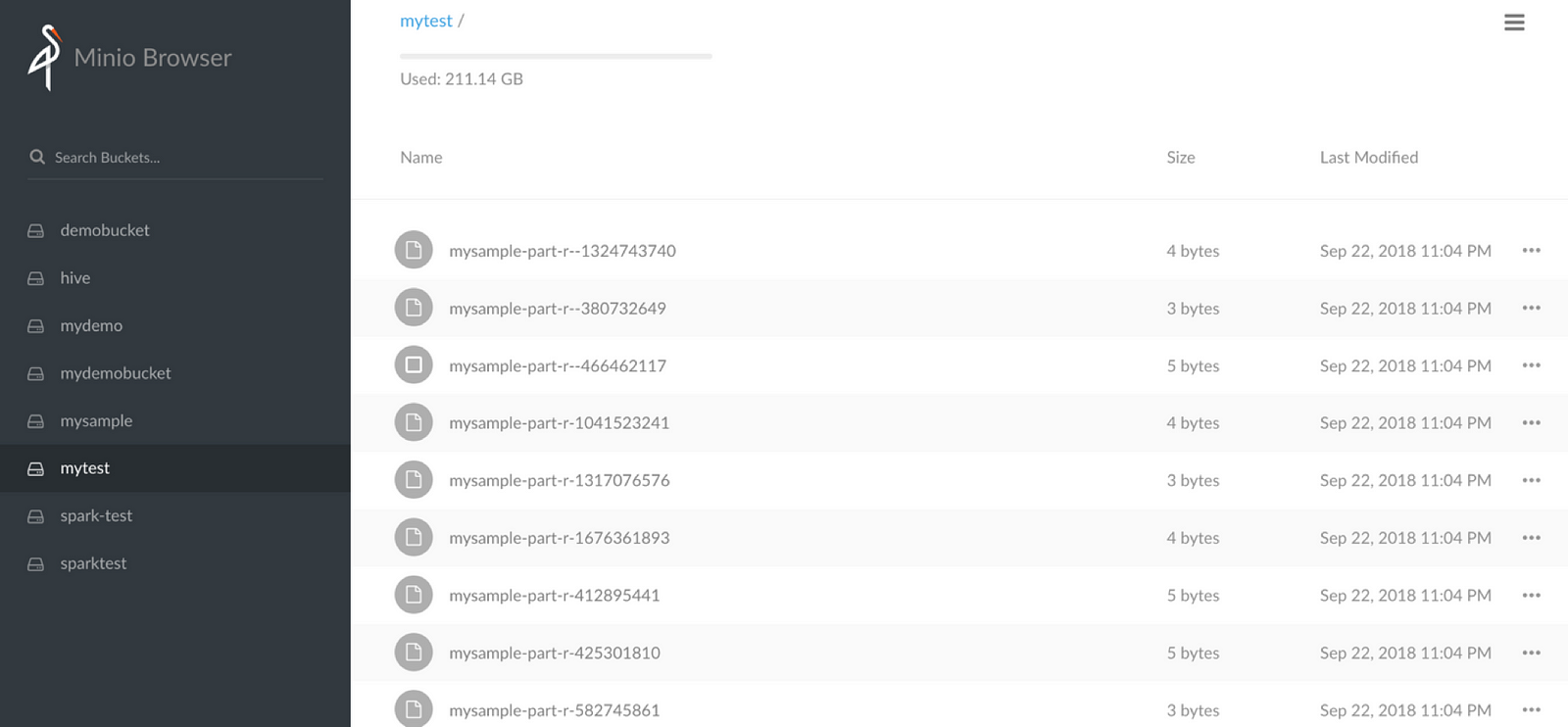
您是否注意到,当我们通过 S3 使用 Spark 写入时,文件会被写入为普通文件——当我们使用底层对象存储 Minio 时,理想情况下不应该这样。我们能否将数据作为对象写入 Minio?以下代码显示了如何操作。诀窍是在您的 Java 或 Scala 代码中集成 Minio 客户端 Java SDK。使用 Spark 的 foreachPartition 函数直接写入 Minio。
首先,编写一个更新 Minio 的函数。
现在,在您的 Spark 代码中使用上述函数,如下所示

总结
我们已经证明,使用 Minio 的对象存储是创建数据湖的一种非常有效的方法。数据湖所需的所有基本组件都通过 s3a 协议与 Minio 无缝协作。
数据湖的整体架构可以是
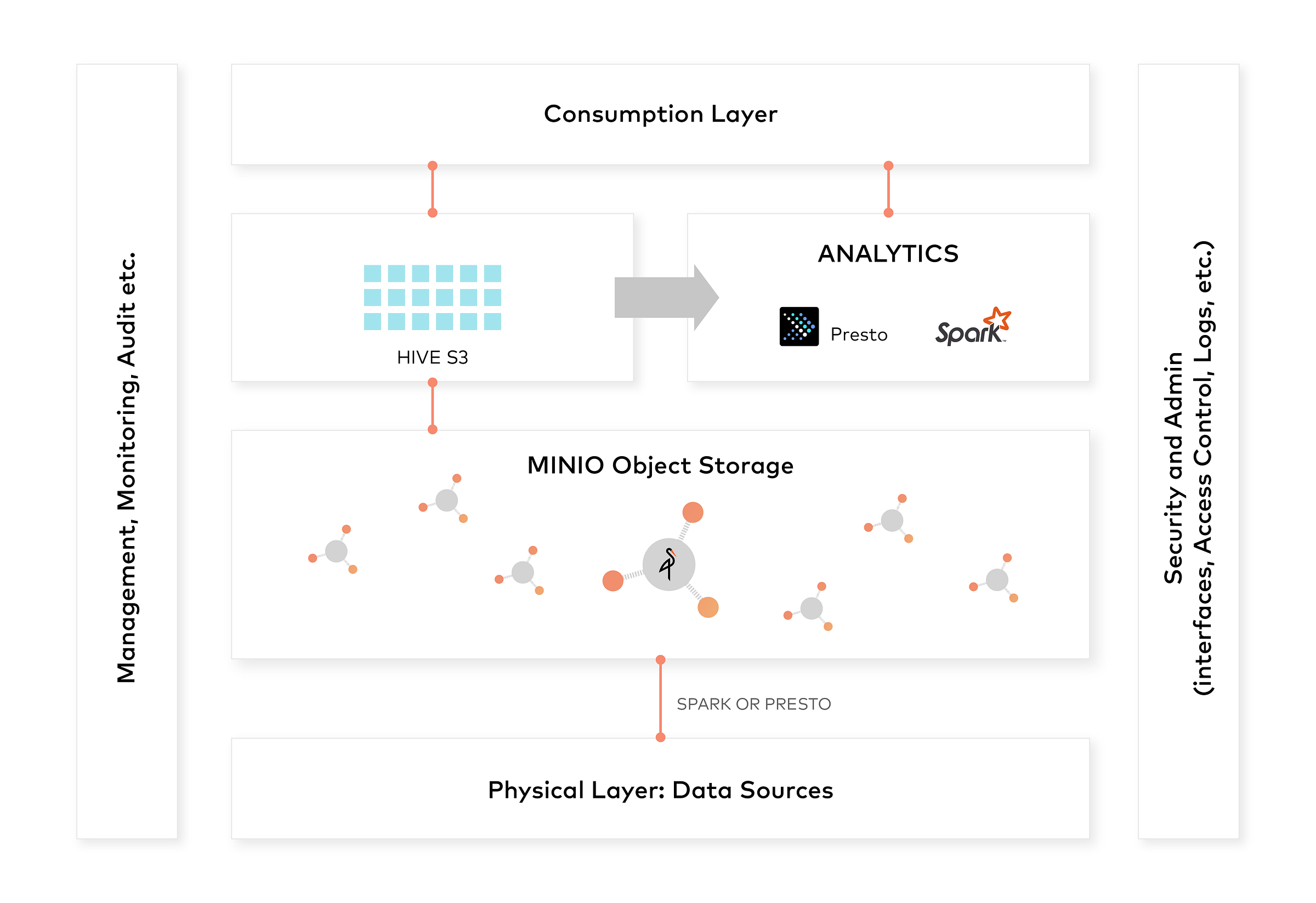
希望您能够探索这些概念并在各种用例中使用它。享受!