使用 MinIO 和 YOLO 简化对象检测


太长不看(TL;DR)
在这篇文章中,我们将创建一个自定义图像数据集,然后训练一个You-Only-Look-Once(YOLO)模型来执行普遍存在的目标检测任务。然后,我们将使用MinIO Bucket Notifications实现一个系统,该系统可以自动对新图像执行推理。
引言
计算机视觉仍然是人工智能一个极具吸引力的应用领域。无论是识别战场上的元素还是预测作物产量,计算机视觉可以说是人工智能中最具商业价值(和社会重要性)的领域之一。
然而,采用最佳计算机视觉功能的一个速度限制因素往往是与构建数据集和设计一个简单的端到端系统相关的复杂性,该系统将在新图像上执行您的计算机视觉任务。
在这篇博文中,我们将逐步了解如何使用CVAT和MinIO Bucket Notifications等一流工具解决这些问题。在本博文结束时,您将能够在一个自定义数据集上训练一个目标检测模型,并在出现新图像时使用它进行预测。
前提
假设我们希望能够识别卫星图像中存在的飞机类型。我们还假设我们从头开始:没有预构建的数据集,也没有预训练的模型。以下是我们希望在卫星图像中检测和识别的两个飞机样本

注意:本文中概述的步骤可以推广到几乎任何领域。与其检测飞机类型,我们可以对土地利用进行分类或执行回归以预测作物产量。除了传统的图像之外,我们还可以对其他类型的多维数据(如激光雷达点云或 3D 地震图像)进行训练和执行推理;这仅仅是训练数据的外观问题(以及可能使用不同的深度学习模型而不是YOLO)。如果您对特定用例的具体情况有更多疑问,请随时在GitHub 仓库上提一个问题!
步骤 1:获取和管理训练样本
对于这个项目,很大程度上是因为我没有拥有按需成像卫星,所以我访问了谷歌地球上的机场,并对一些飞机可见的区域进行了多次截图。组装这组图像花费了相当长的时间,因此我将它们全部存储在我的MinIO服务器上名为“object-detection”的存储桶中。在生产环境中,将收集到的样本存储在MinIO上的好处变得更加突出。主动-主动复制、最高级别的加密和超快的GET/PUT(仅举几例)意味着您辛辛苦苦收集的样本将具有高可用性、安全性和可靠性。
步骤 2:创建数据集

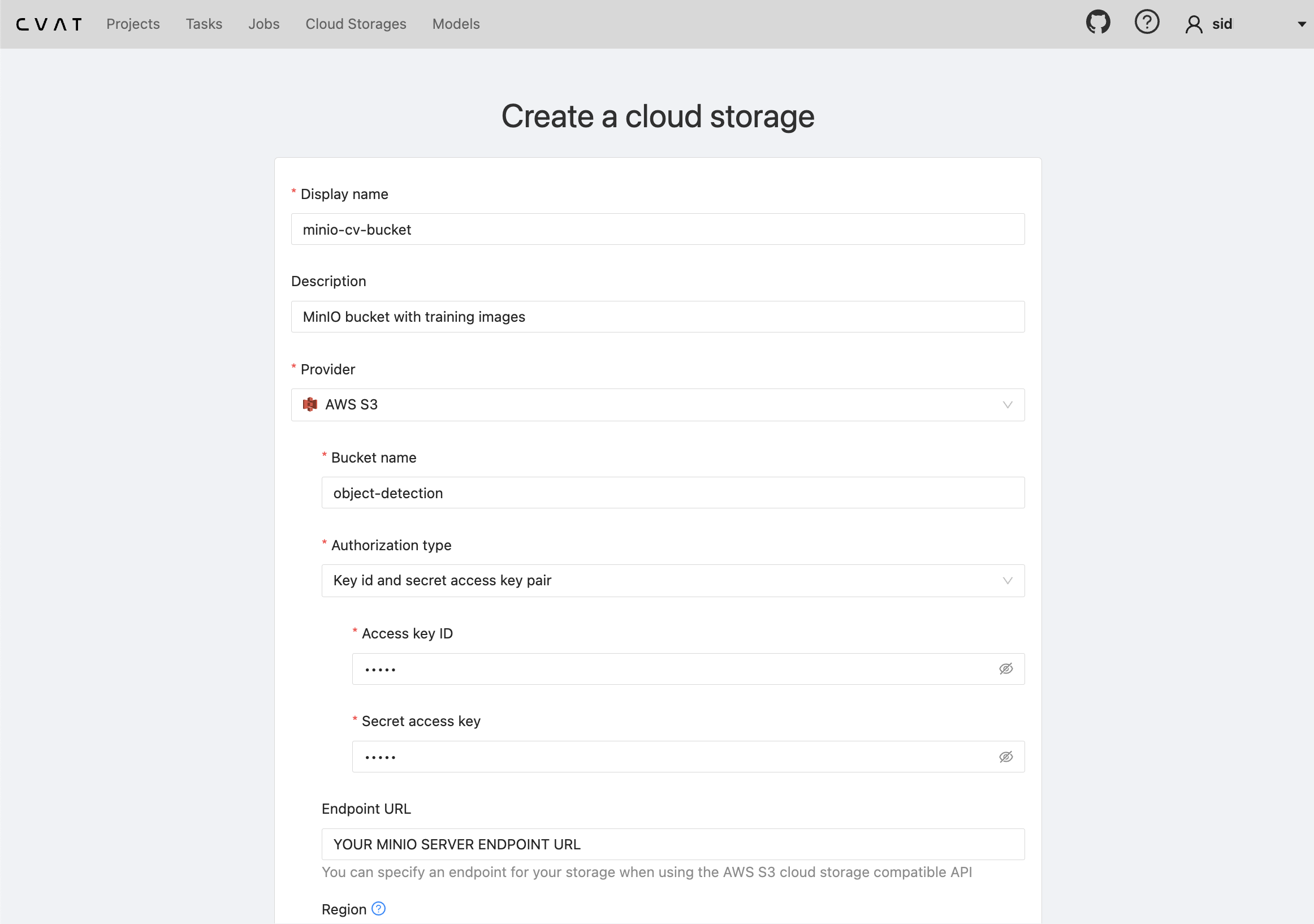
为了训练适合您用例的目标检测模型,需要一个标记(或“注释”)数据集。一个很棒的工具是OpenCV的CVAT。一个很酷的功能是CVAT提供了一个实用程序,可以将您的MinIO存储桶连接为“云存储”,以便将存储桶的图像直接馈送到数据集注释工具。为此,请确保您的MinIO Server的主机可以访问CVAT服务器,尤其是在您在本地或笔记本电脑上本地运行MinIO Server时。另外,需要注意的是,有两种使用CVAT的方法:(1)使用他们在app.cvat.ai提供的网络应用程序,或(2)在本地运行它。无论哪种情况,一旦您打开了CVAT,请在菜单栏中点击“云存储”。从那里,您可以填写一个表单来附加您的(与S3兼容的)MinIO存储桶
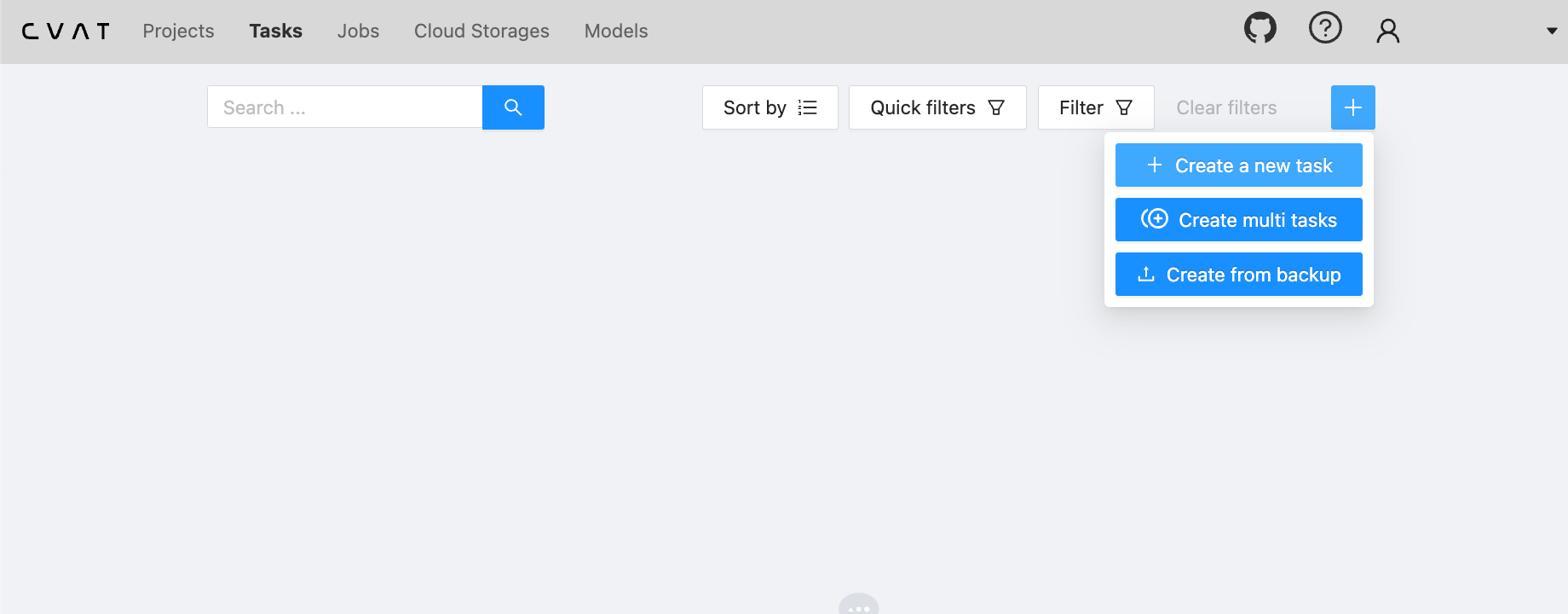
现在让我们在“任务”下创建新的标签任务
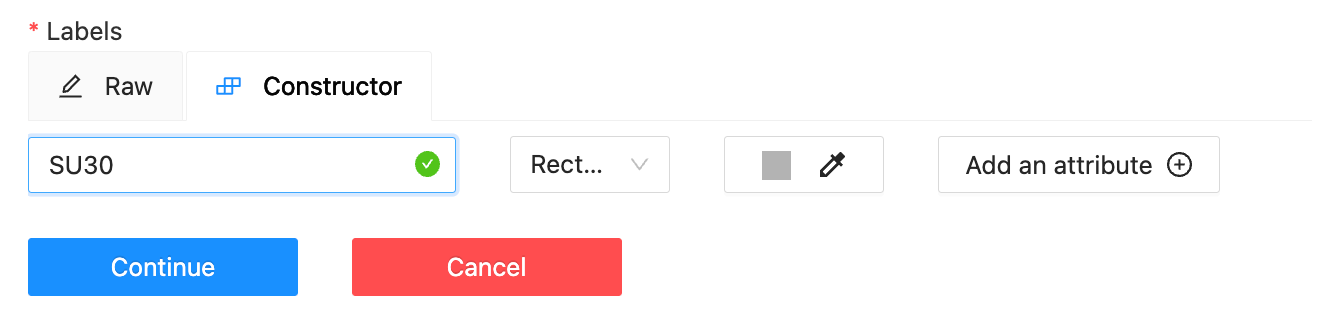
系统会提示您填写一个表单

创建任务时,正确定义类标签非常重要(我定义了两个名为“SU30”和“TU95”的矩形标签,对应于我想要检测的两种飞机)
现在剩下的步骤是将我们之前添加的MinIO存储桶作为数据源附加。在“选择文件”下,点击“云存储”并填写您之前为此源提供的名称。我在上面使用了名称“minio-cv-bucket”。
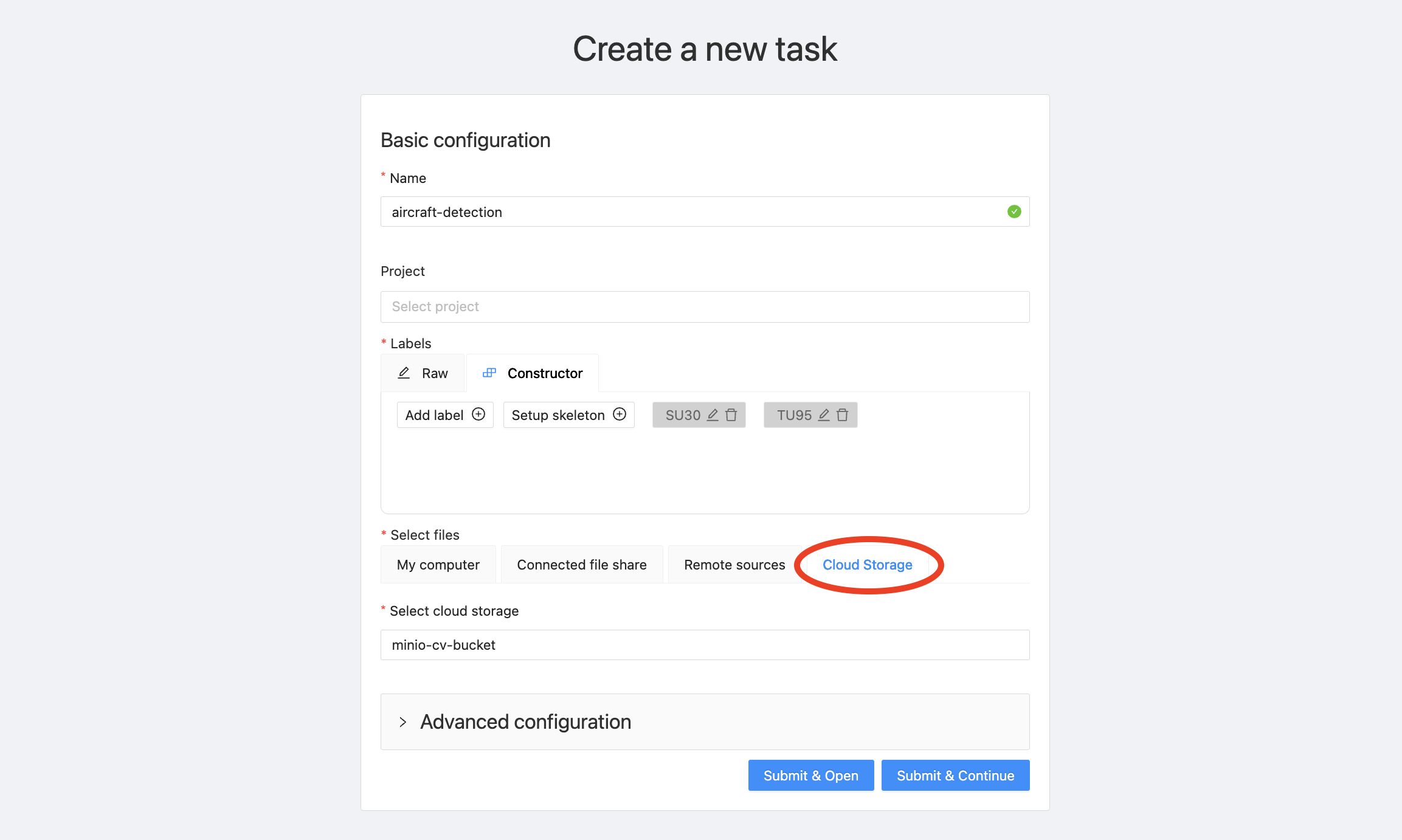
上传过程需要几分钟。完成后,您应该能够在“作业”下看到您的注释作业。
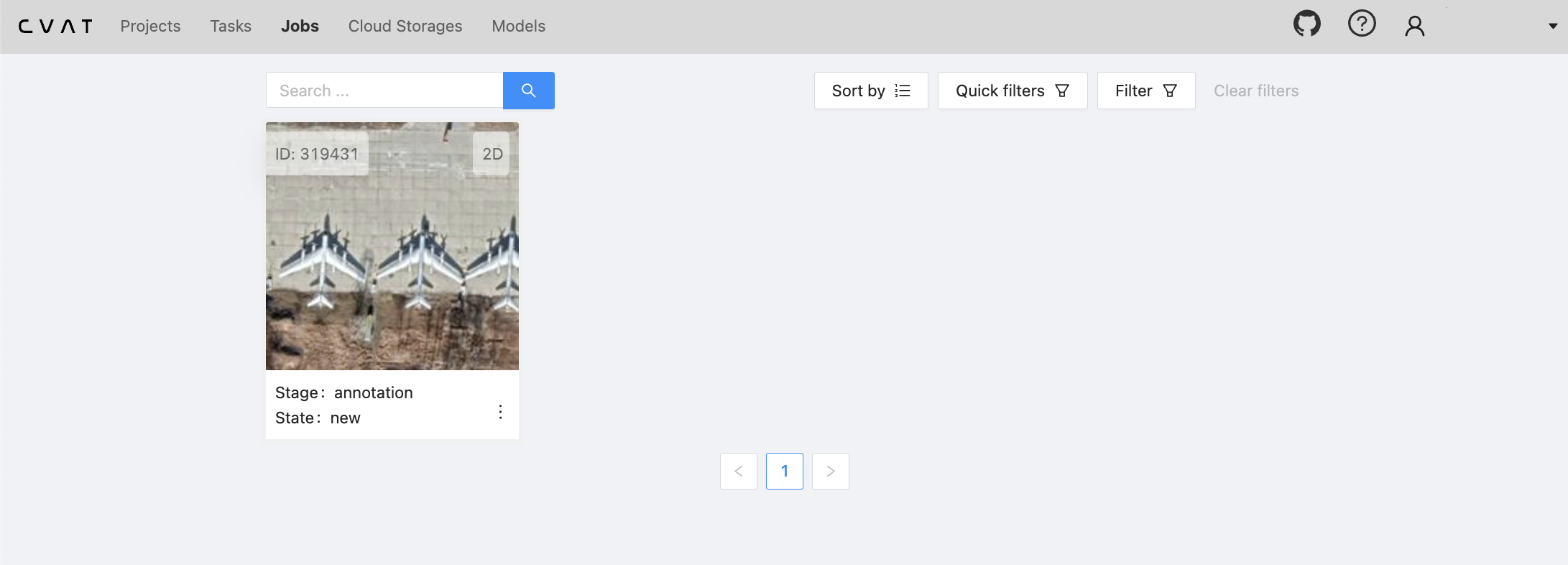
现在,通过点击作业,您可以开始注释每个图像。警告:这可能是一个不成比例地耗时的过程。通常,在具有大量注释需求的生产环境中,最好将此任务卸载到专门的内部团队或第三方数据标注公司。

注释完成后,以YOLO格式导出数据集。
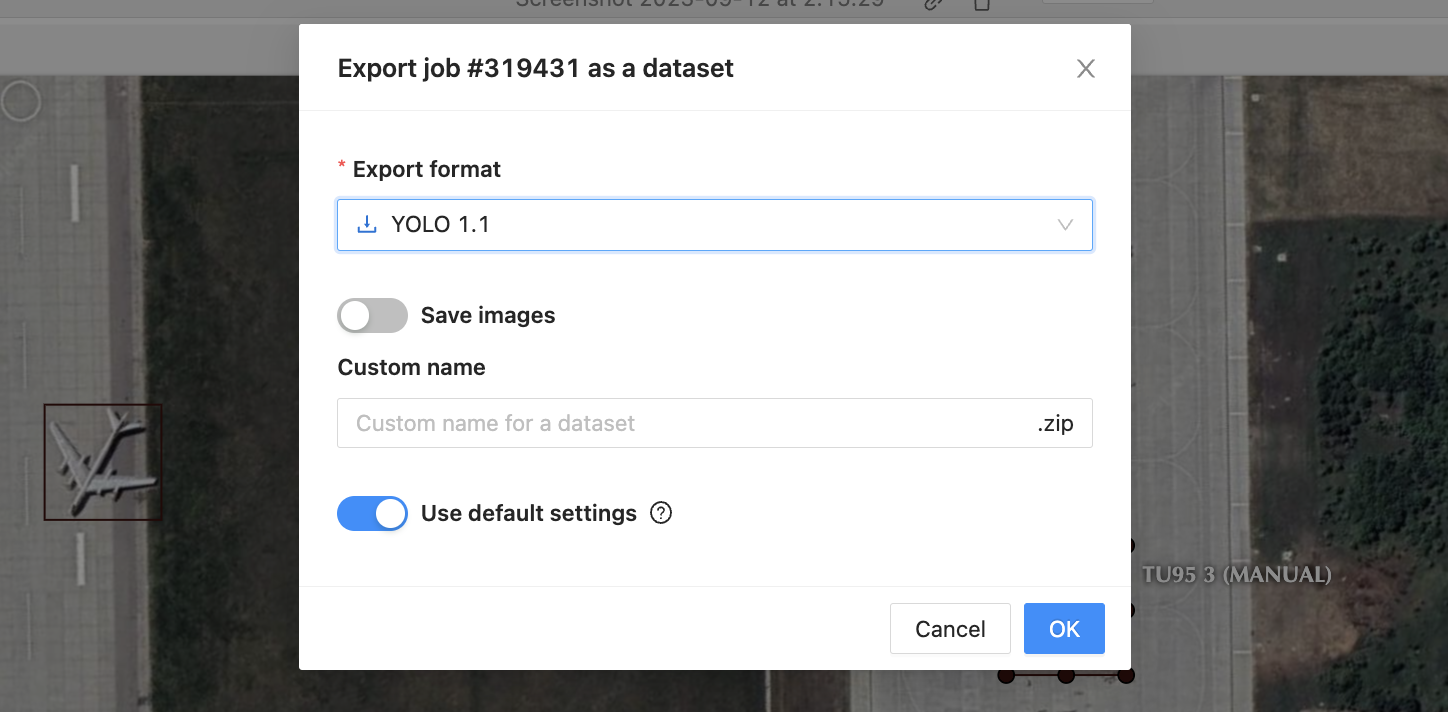
步骤 3:组织训练数据
您导出的数据集将以zip文件的形式存在。解压缩后,YOLO格式的注释文本文件将位于一个封闭的文件夹中。随意查看它们。在YOLO格式中,每个图像的注释都位于一个文本文件中,其中每一行包含边界框的两个角和类别。类别号对应于您在创建任务时定义标签的顺序。因此,在此示例中,0对应于苏-30,1对应于图-95。
此时,创建一个新的工作目录(或进入您已创建的工作目录)。在此目录中,创建一个名为“dataset”的子目录。在“dataset”中,创建目录,以便您的工作目录如下所示
现在,您需要为图像及其对应的注释(文本文件)填充 train、val 和 test 子目录。您可以根据自己的需要检索和拆分样本。一个好的做法是将您的总训练样本分成 80% 的训练集、10% 的验证集和 10% 的测试集。确保在对图像进行分区之前随机打乱它们。
我个人使用 MinIO Client 的 **mc cp** 命令行工具快速从我的“object-detection”存储桶中检索所有图像。或者,如果您已经在本地计算机上的一个位置拥有所有样本图像,则可以直接使用它们。一旦我将所有样本放在一个位置,我便使用 Python 脚本对图像和注释进行随机排序、拆分和移动到 train、val 和 test 目录。 此处提供了脚本以供参考。如果您对如何使用它有任何疑问,请随时在 仓库 中提出问题!
最终,请确保对于放置在 images/train、images/val 或 images/test 中的每个图像,相应的注释 .txt 文件也位于 annotations/ 目录内的对应子目录中。例如
现在,我们的数据已就绪。是时候看看我们的目标检测模型并开始训练了。
步骤 4:目标检测模型
目前在目标识别方面(在性能和易用性方面)的黄金标准是 YOLO(You Only Look Once)类模型。在撰写本文时,YOLOv8 是最新版本,由 Ultralytics 作为开源维护。YOLOv8 提供了一个简单的 API,我们可以利用它来训练模型以使用我们新创建的注释(并最终运行推理)。
让我们下载 YOLOv8
现在,我们可以使用 YOLOv8 CLI 工具或 Python SDK 来进行训练、验证和预测。有关更多信息,请参阅 YOLOv8 文档。
步骤 5:训练
在您的工作目录中,定义一个 YAML 文件,该文件指定数据集的位置以及有关类的详细信息。请注意路径与我之前在工作目录中创建的路径相同。我将我的文件命名为“**objdetect.yaml**”。此外,请注意两个飞机类标签必须按照它们在 CVAT 中的顺序进行定义。
使用以下命令(使用 YOLO CLI 工具)开始在我们的数据集上训练 YOLOv8 模型。请参阅 YOLO 文档,了解有关您可以为训练配置的所有不同选项的更多信息。在这里,我正在启动 100 个 epoch 的训练,并将图像大小设置为 640 像素(所有训练图像将在训练期间相应地进行缩放)
训练需要一段时间,尤其是在使用笔记本电脑(就像我一样)时,所以现在是休息一下(或继续阅读😀)的好时机!
在训练循环结束时,您的训练模型以及其他有趣的图形和图表将存储在名为“runs”的自动生成的目录中。终端输出(如下所示)将指示最新运行结果的具体位置。每次训练模型时,都会在“runs/detect/”中生成类似的目录。
注意:runs/detect/train/weights/ 将包含具有精确训练权重的 PT 文件。请记住此位置以备后用。
步骤 5B:模型验证和测试
您可以使用以下命令运行验证
结果将自动存储在工作目录中的一个文件夹中,路径格式为“runs/detect/val”。
要对测试集执行推理,可以使用以下命令
结果将存储在“runs/detect/predict”中。以下是测试集上的一些预测结果

步骤 6:使用 MinIO 存储桶通知进行新图像推理
现在我们已经训练了一个可以识别卫星图像中某些飞机类型的模型,如何才能以简单的方式将其用于新图像?
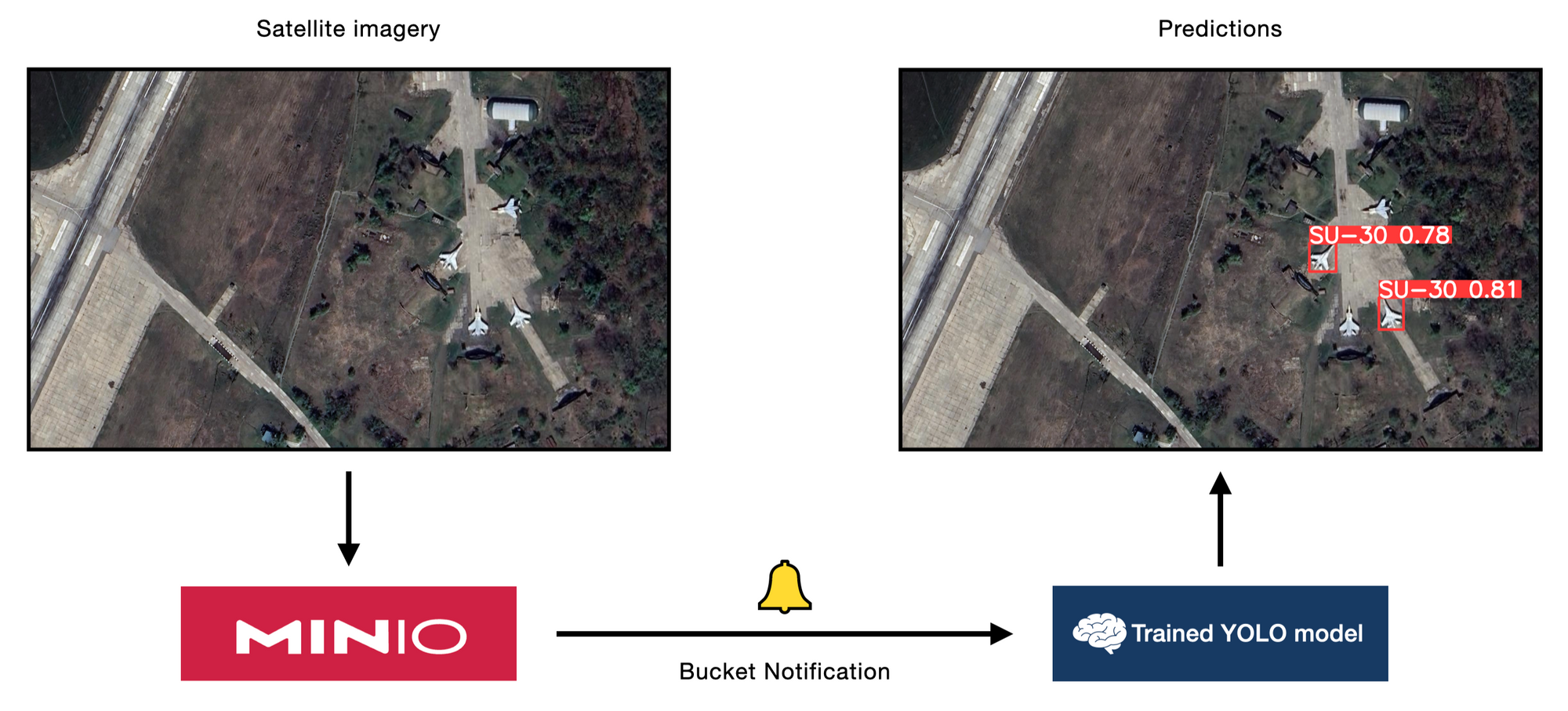
MinIO 存储桶通知是为此目的的完美工具。借助 Webhook,我们可以构建一个系统,在将新图像放入我们的存储桶后自动执行对象检测推理。
从高级别来看,我们有三个步骤。首先,我们需要定义一个可以作为 Webhook 的端点,以使用我们训练的模型对新图像执行对象检测。其次,我们需要为 MinIO 服务器部署配置一些环境变量,以便在发生某些事件时指示它访问我们的 Webhook 端点。第三,我们需要配置我们想要对哪些类型的存储桶事件(例如 PUT)进行操作。让我们一步一步地完成它。
以下是基于 Flask 的简单服务器的代码(detection_server.py),它对添加到 MinIO 存储桶中的新图像运行推理
让我们启动推理服务器
记下 Flask 应用程序正在运行的主机名和端口。
接下来,让我们开始在 MinIO 端配置 Webhook。首先,设置以下环境变量。将 <YOURFUNCTIONNAME> 替换为您选择的函数名称。为简单起见,我使用了 “inference”。此外,请确保端点环境变量设置为推理服务器的正确主机和端口。在本例中,https://:5000 是我们的 Flask 应用程序正在运行的位置。
现在,使用命令 mc admin service restart ALIAS 重新启动 MinIO 服务器,或者如果您是第一次启动服务器,也可以只使用 minio server 命令。有关重新/启动 MinIO 服务器的更多信息,请查看 MinIO 文档。注意:ALIAS 应替换为您 MinIO 服务器部署的别名。有关如何设置别名或查看现有别名的更多信息,请查看 文档。
最后,让我们添加我们要接收通知的存储桶和事件。在我们的例子中,我们希望在我们的存储桶中收到有关 `put` 事件(新对象的创建)的通知。为此目的,我创建了一个全新的空存储桶,名为 “detect-inference”,因此我将用它替换“BUCKET”。
您可以通过运行此命令时是否输出了“s3:ObjectCreated:*”来检查是否已为存储桶通知配置了正确的事件类型
有关将存储桶事件发布到 Webhook 的更详细说明,请查看 文档。我们现在可以尝试对全新图像进行对象检测了!
试用我们的推理系统
这是我要对其进行推理的新图像(标题为“1.png”)

我将新图像放入我的“detect-inference”存储桶中

几乎立即,我就能在我的 Flask 服务器上看到以下结果
请注意,结果列表中每个检测到的边界框都采用 YOLO 格式 [x1, y1, x2, y2, 概率, 类别]。以下是叠加在原始图像上的边界框和预测类别。

注意:对于生产环境和/或大型机器学习模型,最好使用成熟的模型服务框架(如 PyTorch Serve 或 Triton Server)来使推理更健壮和可靠。如果您对此感兴趣,请查看之前关于使用 MinIO 和 PyTorch Serve 优化 AI 模型服务 的文章。
总结
我们做到了!我们介绍了 MinIO 和 CVAT 如何协同工作,以确保我们收集的图像样本安全可用,以及如何创建自定义对象检测数据集。然后,我们针对自定义任务训练了自己的自定义 YOLO 模型。最后,只需 50 多行代码,我们就使用 MinIO 存储桶通知构建了一个推理服务器,该服务器可以将新图像传递给我们自定义训练的对象检测模型。
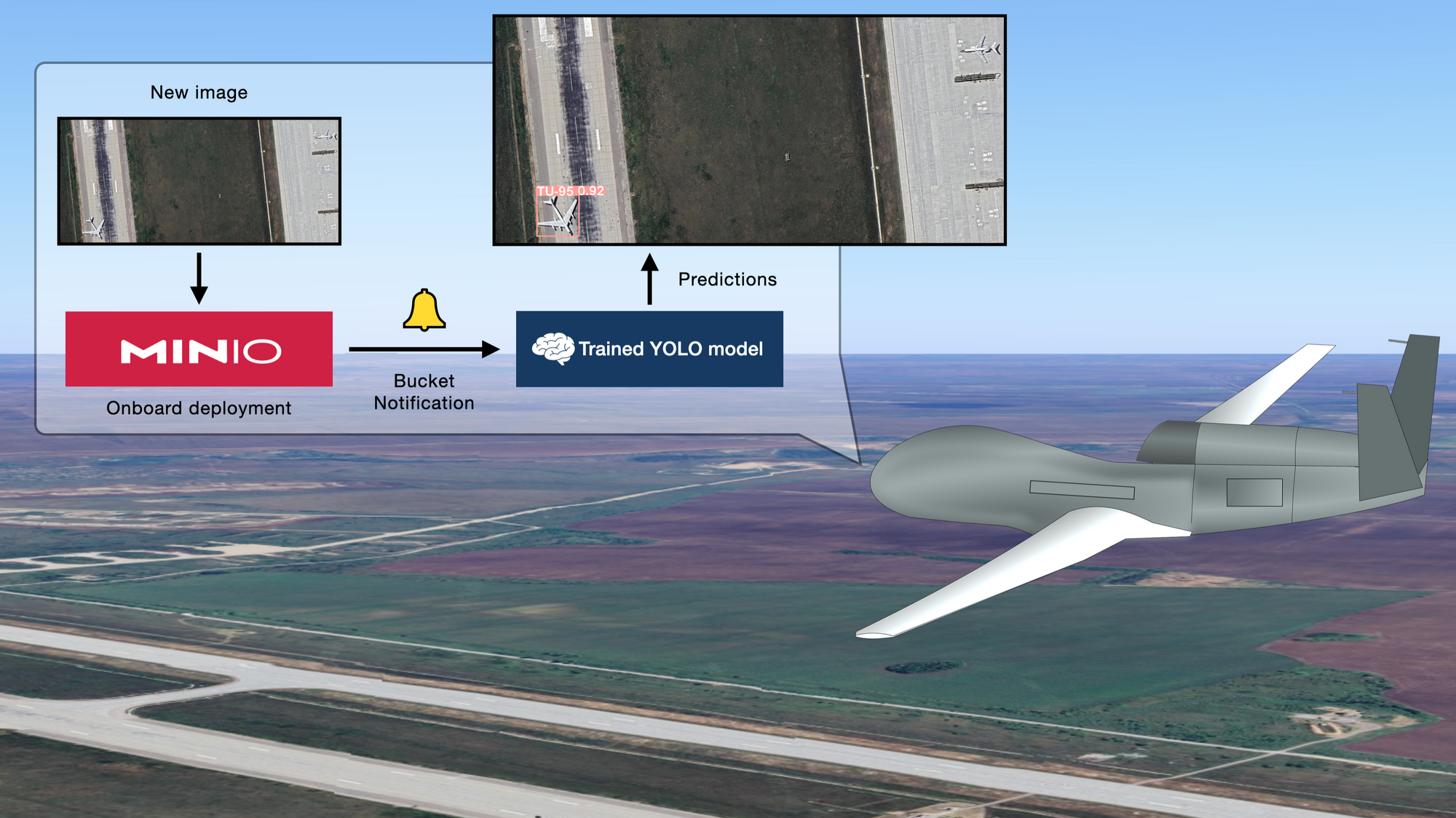
此外,对于大多数关键的计算机视觉应用,最好在边缘进行推理。否则,这些应用将容易受到将新数据上传到公共云并等待云中的推理服务器返回答案相关的延迟的影响,更不用说网络连接故障的风险了。出于这个原因,以 MinIO 作为数据层的计算机视觉管道更有意义。想象一下,一架无人机飞过机场,能够使用完全机载的硬件和软件捕获、存储并使用我们训练的模型处理新的图像。通过本地部署 MinIO 服务器,我们在帖子末尾构建的基于存储桶通知的推理系统非常适合这种情况以及无数其他类似的情况。
如果您有任何疑问,请加入我们的 Slack 频道 或发送邮件至 hello@min.io。我们随时为您提供帮助。