在过去的几个月里,我们见证了基于对象存储的超高速分析型数据库的托管服务不断涌现。这些托管服务越来越受欢迎,吸引着企业和工作负载,因为企业们正在意识到将闪电般快速的数据准备与对象存储相结合的战略优势,尤其是在 AI 和 ML 应用方面。
这种趋势的典型例子是 MotherDuck 和 ClickHouse 的托管服务 ClickHouse Cloud 的成功。两者都利用对象存储在性能和成本节约方面实现战略性优势。MotherDuck 作为 2023 年 GeekWire 奖年度交易的 决赛选手,已经 筹集了 5250 万美元 的 B 轮融资,使其总融资额达到 1 亿美元。同样,ClickHouse 在 2021 年 筹集了 2.5 亿美元 的 B 轮融资,最近宣布与阿里云在中国大陆 建立了重要的合作伙伴关系。
这些托管服务成功的核心是存储和计算的解耦,这是通过在对象存储之上构建数据产品实现的。我们将看到越来越多的托管服务使用这种架构构建,因为这种模式允许存储和计算独立扩展——有效地为两者解锁无限的和特定于工作负载的扩展。
这种架构正在被超大规模云计算提供商用于这些托管服务,但解耦存储和计算的优势并不局限于它们。一旦云被视为一种运营模式而不是物理位置,超大规模云计算提供商之外也能实现扩展和性能。随着 AI 和 ML 模型对干净、快速和准确数据的 insatiable demand 不断增长,我们必须从这些超大规模云计算提供商身上吸取教训,了解对象存储如何支撑它们的成功。
为此,让我们首先分解这些托管服务到底是什么。
分解成功:从 ClickHouse Cloud 中吸取的教训
ClickHouse 长期以来 承认,用户在私有托管的高性能对象存储(如 MinIO)上为其开源产品体验到的吞吐量更高。他们的产品 ClickHouse Cloud 提供了这种产品的托管服务版本。
ClickHouse Cloud 速度很快,因为它实现了 SharedMergeTree 引擎。SharedMergeTree 表引擎通过利用多个 I/O 线程来访问对象存储数据并异步预取数据,将数据和元数据与服务器分离。
此外,ClickHouse 的 固有设计 也促成了其速度。ClickHouse 按列处理数据,从而提高了 CPU 缓存利用率,并允许使用 SIMD CPU 指令。ClickHouse 可以利用所有可用的 CPU 内核和磁盘来执行查询,不仅是在单个服务器上,而且是在整个集群中。这些架构选择,再加上向量化查询执行,为 ClickHouse 的卓越性能做出了贡献。
释放 MotherDuck 的潜力:基于 DuckDB 的云分析服务
MotherDuck 是一个基于开源 DuckDB 构建的托管云服务。 DuckDB 速度很快,原因有很多,其中一些我们已经描述过。值得注意的是,DuckDB 利用了列存储和向量化查询执行。这种方法允许 DuckDB 比传统的基于行的数据库更有效地处理数据,尤其是在数据探索等分析工作负载方面,例如在为 ML 模型选择特征之前进行数据探索。
DuckDB 的性能不仅仅是宣传;它在测试中证明了其速度,在中等规模的数据集上优于 Postgres 等系统。使 DuckDB 与众不同的是它对简单性的承诺。它不夸耀复杂的功能,而是专注于提供一种快速而直接的方式来访问和分析数据。
解耦的案例研究
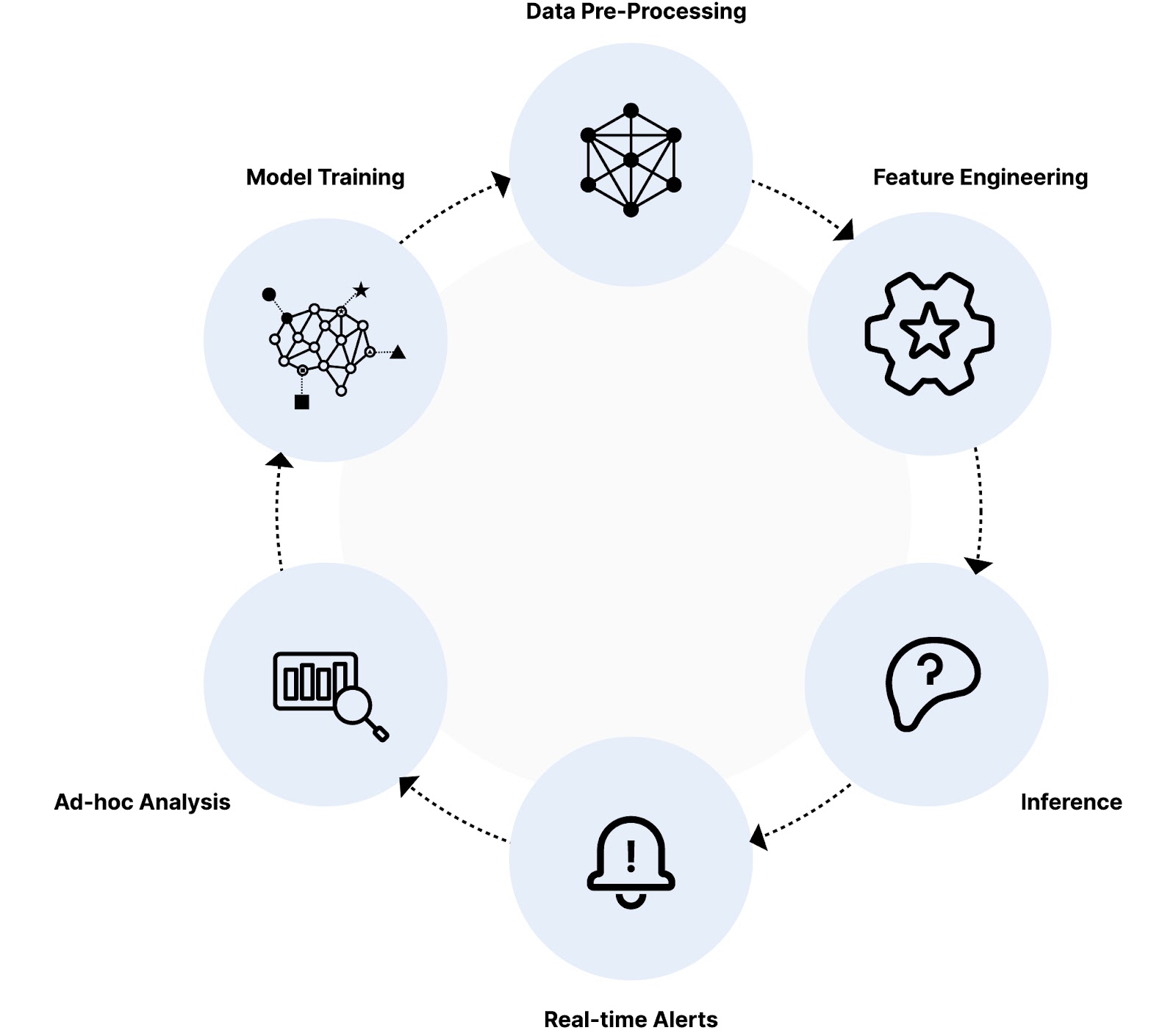
让我们将这种架构应用到一个案例中。一家大型在线银行每天要处理数百万笔交易。每秒钟都会创建数据对象并涌入他们的系统,其中可能潜藏着欺诈活动。为了抓住这些威胁,这家大型银行需要一个强大的 AI 系统来分析这些数据并标记可疑记录。此时,一个非常快速且可扩展的数据库就变得至关重要。
它是这样工作的
- 数据预处理:分析型数据库可以直接查询对象存储中的数据,无需数据摄取,并实时对其进行预处理。这种预处理可能涉及数据清理、转换和特征提取。
- 特征工程:数据库存储并允许从每笔交易中快速计算各种特征。这些特征可能包括交易金额、位置、时间、用户行为模式和使用的设备等。目标是通过将所有内容转换成少量特征来使模型在训练和推理期间能够使用这些特征。
- 推理:在历史数据和欺诈模式上训练的 AI 模型实时分析每笔交易的特征。数据库需要支持高效查询和检索相关数据,以便模型能够快速准确地对每笔交易进行评分。
- 实时警报:根据异常评分,AI 系统会标记可疑交易。数据库需要高效地存储和更新这些信息,以便能够立即向欺诈团队发出警报进行调查。
- 特设分析:分析型数据库允许使用各种工具(如仪表盘、可视化和异常检测算法)来探索和调查可疑交易。人类应该密切关注,确保标记为欺诈的交易确实是欺诈的,以及 AI 模型错过的任何交易。在这两种情况下,都需要一个非常快的分析型数据库来确保快速完成这项工作,并能够从这些数据中快速生成新的、更好的模型。
- 模型训练:这个 AI 模型将不断地得到保留。包括模型本身和每个训练时期在内的许多工件都需要保存到对象存储中。
实施 AI 驱动的欺诈检测系统为银行带来了许多好处。它帮助他们尽早发现和阻止欺诈性交易,减少财务损失。这不仅保护了银行,而且确保了客户拥有更好的体验,因为他们知道自己的账户是安全的。AI 系统不断学习和适应新的欺诈模式,使银行的安全性随着时间的推移而增强。此外,该系统能够处理更多交易而不会减速,支持银行未来的发展。
这只是基于对象存储的快速、可扩展数据库如何赋能 AI 和 ML 项目的一个用例。类似的原则可以应用于其他场景,例如工业流程中的实时异常检测、电子商务中的个性化推荐或交通运输中的动态定价。
为自己的工作负载获取这种架构的优势
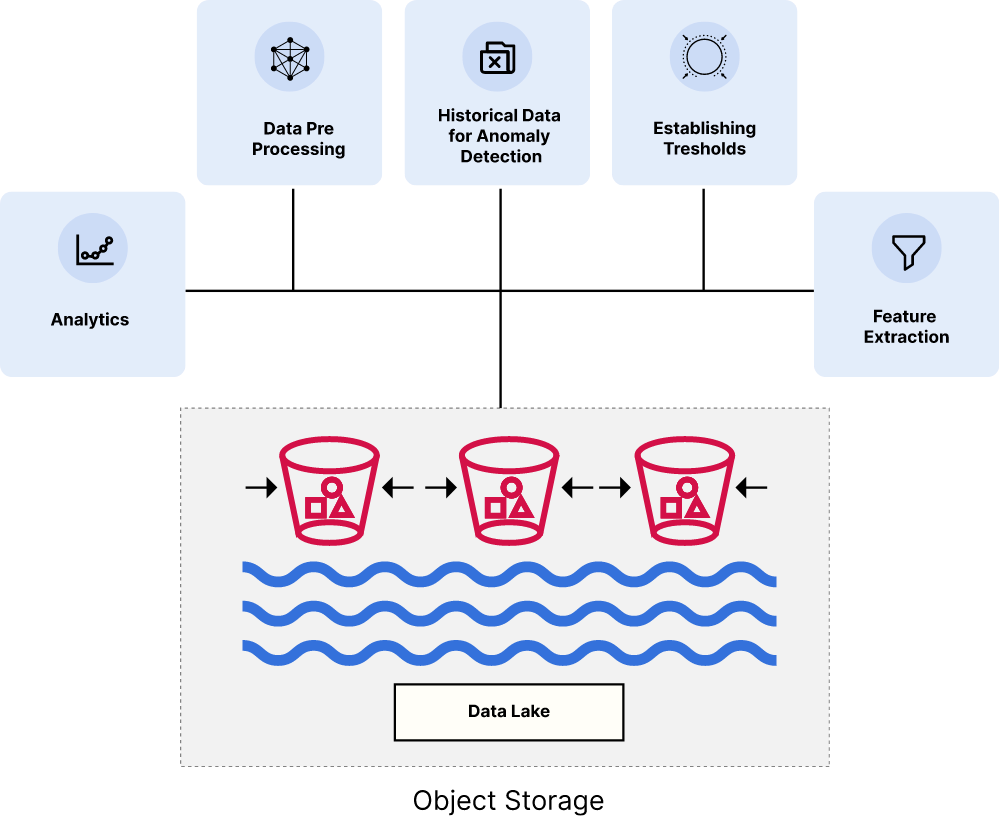
让我们谈谈如何为你的工作负载实现解耦存储和计算的数据湖架构,以实现扩展和性能。你的首要目标必须是选择一个旨在可扩展且云原生的对象存储。以下是一些满足这些标准的要求
- 可扩展性和弹性:云原生设计和对 Kubernetes 编排的支持是绝对必要的,可以实现无缝的可扩展性和弹性。
- 存储效率和弹性: 每个对象、内联擦除编码 和位腐蚀检测确保以现代方式保护数据,以保护数据的完整性。
- 云原生和 REST API 兼容:你必须能够随时随地以相同的、广泛采用的 API 访问数据。这为你的数据湖架构提供了灵活性,并支持系统之间的互操作性。
- 安全和合规性:需要复杂的服务器端加密方案来保护传输中和静止状态的数据,确保数据安全,并符合数据保护法规。
- 即插即用:必须与现代数据堆栈中的所有其他元素配合良好。只有一个对象存储与 Kubeflow 和 MLFlow 一起提供。
为什么你应该私有构建
我们已经确定,云是一种运营模式,而不仅仅是物理位置。它存在于所有数据所在的地方,在公共云和私有云、边缘、Colo、数据中心和遍布全球的裸机上。这种对云的处理方式提供了自由,并避免了供应商锁定,使组织能够保持对工作负载的控制和利用。
也许更重要的是,当云成本意识 正在兴起 时,从云中回迁可以带来巨大的成本节约。例如,在 这份 总拥有成本 (TCO) 评估中,MinIO 展示了令人印象深刻的 61% 成本降低,相当于每月每 TB 23.10 美元,而 AWS S3 的成本为每月每 TB 58.92 美元。这项分析是针对托管在私有云上的 100 PB 的大型对象存储进行的。
当你 私有构建你的湖仓 时,你可以同时获得扩展性、成本节约和性能。
为成功而构建
基于对象存储的超高速分析型数据库的兴起不仅引起了广泛关注,而且也成为了企业深入 AI 和 ML 应用的战略必然。MotherDuck 和 ClickHouse Cloud 的成功案例突出了对象存储在实现性能和成本效益方面的关键作用。这些经验教训将推动越来越多的托管服务进入这个领域,但也为企业提供了通过在任何地方使用高性能对象存储构建数据湖仓来实现自身成功的机会。欢迎加入讨论,发送邮件至 hello@min.io 或加入我们的 Slack 频道。我们很乐意帮助你构建。

