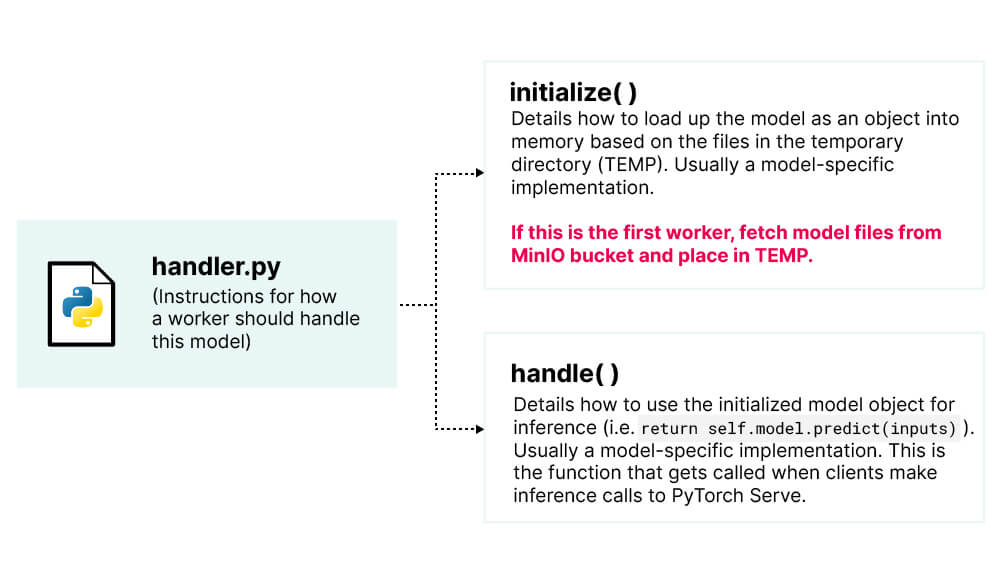
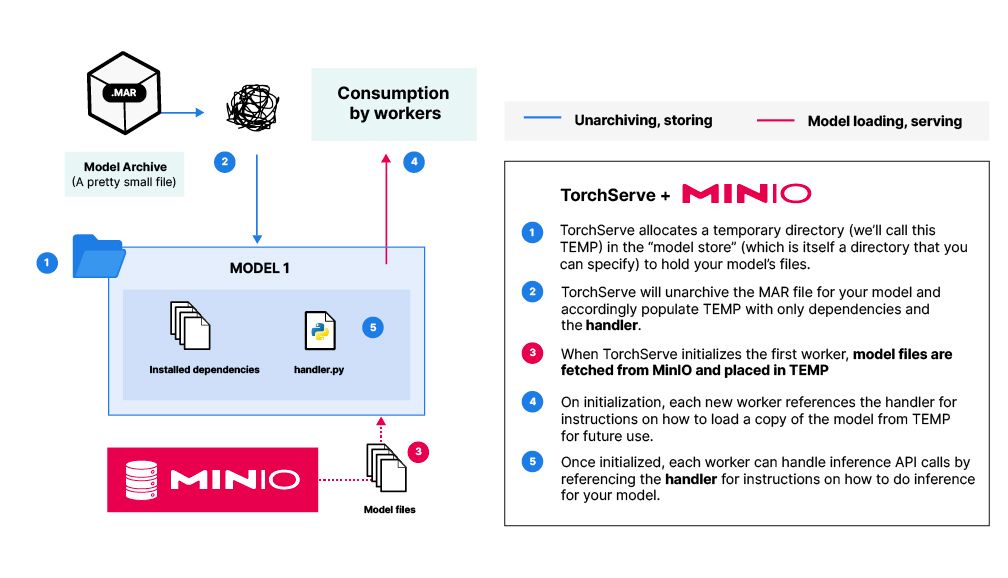
classMyHandler(BaseHandler): ... defload_model_files_from_bucket(self, context): """ Fetch model files from MinIO if not present in Model Store. """ client = self.get_minio_client() properties = context.system_properties object_name_prefix_len = len(CURRENT_MODEL_NAME) + 1 # model_dir is the temporary directory (TEMP) allocated in the Model Store for this model model_dir = properties.get("model_dir") try: for item in client.list_objects(MODEL_BUCKET, prefix=CURRENT_MODEL_NAME, recursive=True): # We don't include the object name's prefix in the destination file path because we # don't want the enclosing folder to be added to TEMP. destination_file_path = model_dir + "/" + item.object_name[object_name_prefix_len:] # only fetch the model file if it is not already in TEMP ifnot os.path.exists(destination_file_path): client.fget_object(MODEL_BUCKET, item.object_name, destination_file_path) returnTrue except S3Error: returnFalse definitialize(self, context): """ Worker initialization method. Loads up a copy of the trained model. """ properties = context.system_properties model_dir = properties.get("model_dir") success = self.load_model_files_from_bucket(context) ifnot success: print("Something went wrong while attempting to fetch model files.") return ... self.model = ... # model specific implementation self.initialized = True ...
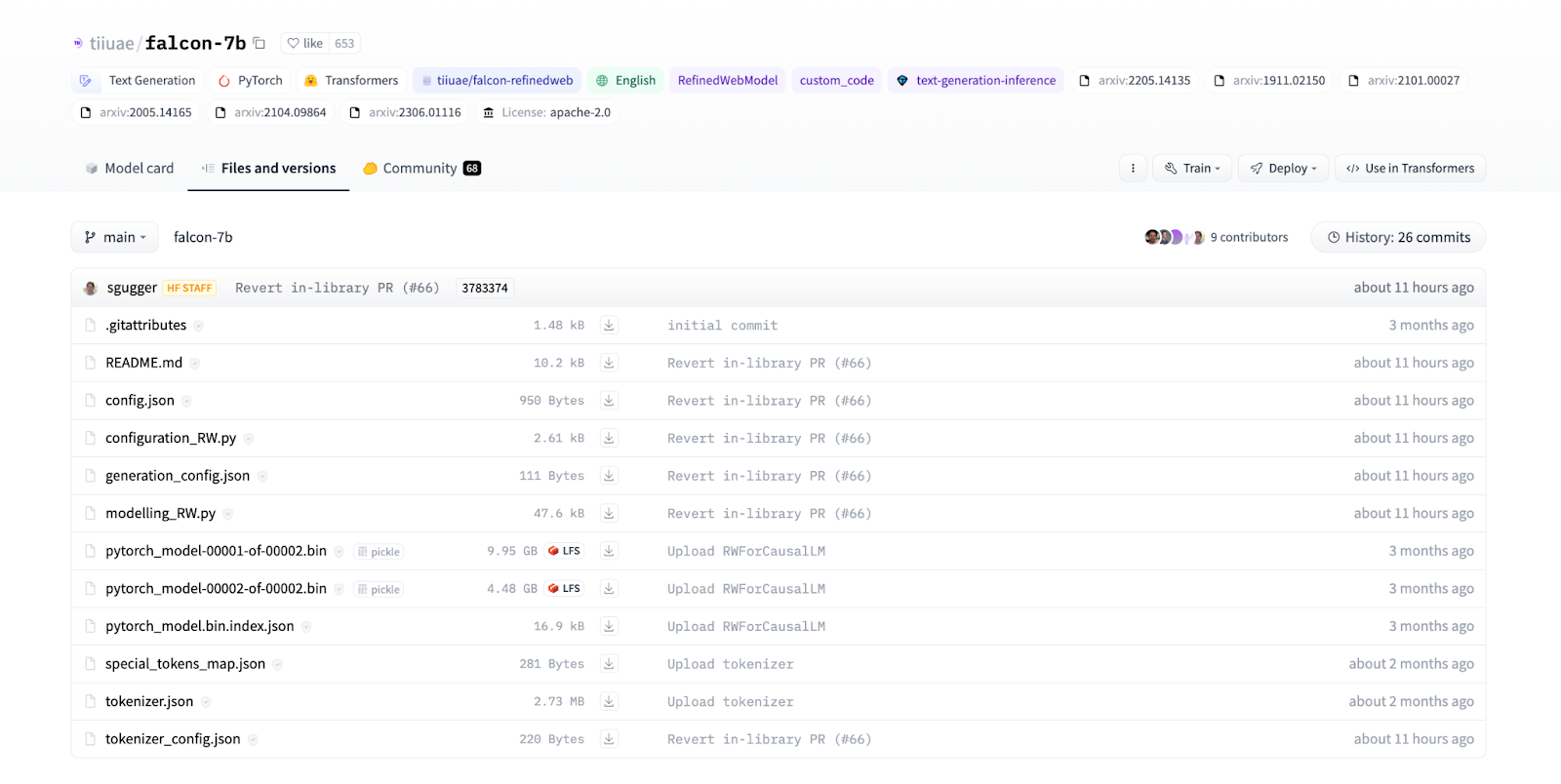
""" PyTorch Serve model handler using MinIO See the full blog post at: For more information about custom handlers and the Handler class: <https://pytorch.ac.cn/serve/custom_service.html#custom-handler-with-class-level-entry-point> """ from minio import Minio from minio.error import S3Error import os import torch from transformers import AutoTokenizer import transformers from ts.torch_handler.base_handler import BaseHandler # In this example, we serve the Falcon-7B Large Language Model (<https://hugging-face.cn/tiiuae/falcon-7b>) # However, you can use your model of choice. Just make sure to edit the implementations of # initialize() and handle() according to your model! # Make sure the following are populated with your MinIO server details # (Best practice is to use environment variables!) MINIO_ENDPOINT = '' MINIO_ACCESS_KEY = '' MINIO_SECRET_KEY = '' MODEL_BUCKET = 'models' CURRENT_MODEL_NAME = "falcon-7b" defget_minio_client(): """ Initializes and returns a Minio client object """ client = Minio( MINIO_ENDPOINT, access_key=MINIO_ACCESS_KEY, secret_key=MINIO_SECRET_KEY, ) return client classMinioModifiedHandler(BaseHandler): """ Handler class that loads model files from MinIO. """ def__init__(self): super().__init__() self.initialized = False self.model = None self.tokenizer = None defload_model_files_from_bucket(self, context): """ Fetch model files from MinIO if not present in Model Store. """ client = self.get_minio_client() properties = context.system_properties object_name_prefix_len = len(CURRENT_MODEL_NAME) + 1 # model_dir is the temporary directory (TEMP) allocated in the Model Store for this model model_dir = properties.get("model_dir") try: # fetch all the model files and place them in TEMP # the following assumes a bucket organized like this: # MODEL_BUCKET -> CURRENT_MODEL_NAME -> all the model files for item in client.list_objects(MODEL_BUCKET, prefix=CURRENT_MODEL_NAME, recursive=True): # We don't include the object name's prefix in the destination file path because we # don't want the enclosing folder to be added to TEMP. destination_file_path = model_dir + "/" + item.object_name[object_name_prefix_len:] # only fetch the model file if it is not already in TEMP ifnot os.path.exists(destination_file_path): client.fget_object(MODEL_BUCKET, item.object_name, destination_file_path) returnTrue except S3Error: returnFalse definitialize(self, context): """ Worker initialization method. Loads up a copy of the trained model. See <https://hugging-face.cn/tiiuae/falcon-7b> for details about how the Falcon-7B LLM is loaded with the use of the Transformers library """ properties = context.system_properties model_dir = properties.get("model_dir") success = self.load_model_files_from_bucket(context) ifnot success: print("Something went wrong while attempting to fetch model files.") return tokenizer = AutoTokenizer.from_pretrained(model_dir) pipeline = transformers.pipeline( "text-generation", model=model_dir, tokenizer=tokenizer, torch_dtype=torch.bfloat16, trust_remote_code=True, device_map="auto", ) self.model = pipeline self.tokenizer = tokenizer self.initialized = True defhandle(self, data, context): """ Entrypoint for inference call to TorchServe. Note: This example assumes the request body looks like: { "input": "<input for inference>" } Note: Check the 'data' argument to see how your request body looks. """ input_text = data[0].get("body").get("input") sequences = self.model( input_text, max_length=200, do_sample=True, top_k=10, num_return_sequences=1, eos_token_id=self.tokenizer.eos_token_id, ) return [sequences]
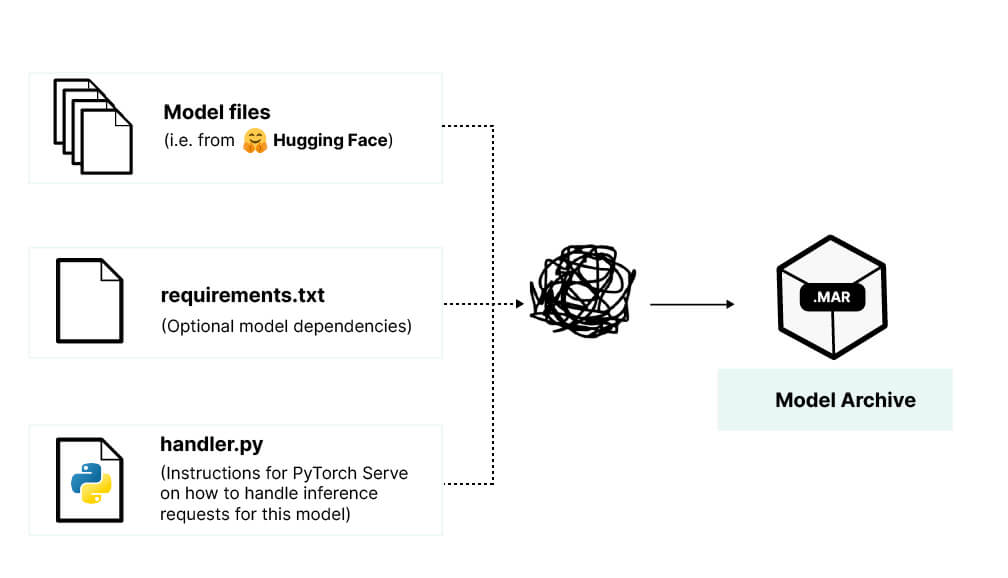
现在我们已经有了自定义处理程序,就可以创建 MAR 文件了。可以在主机环境中直接安装模型特定的依赖项(即 transformers),但这最好将这些依赖项的安装限制在 PyTorch Serve 为你的模型创建的环境中。为了利用这一点,为处理程序特定的依赖项创建一个requirements.txt 文件
minio
torch
transformers
假设您位于与您刚刚创建的处理程序(以及可选的 requirements.txt)相同的目录中,您现在可以使用 torch-model-archiver 工具创建 MAR 文件(我选择名称“falcon-llm”)。
$ curl --header "Content-Type: application/json" \ --request POST \ --data '{"input": "Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\\nDaniel: Hello, Girafatron!\\nGirafatron:"}' \ http://127.0.0.1:8080/predictions/falcon-llm
总结
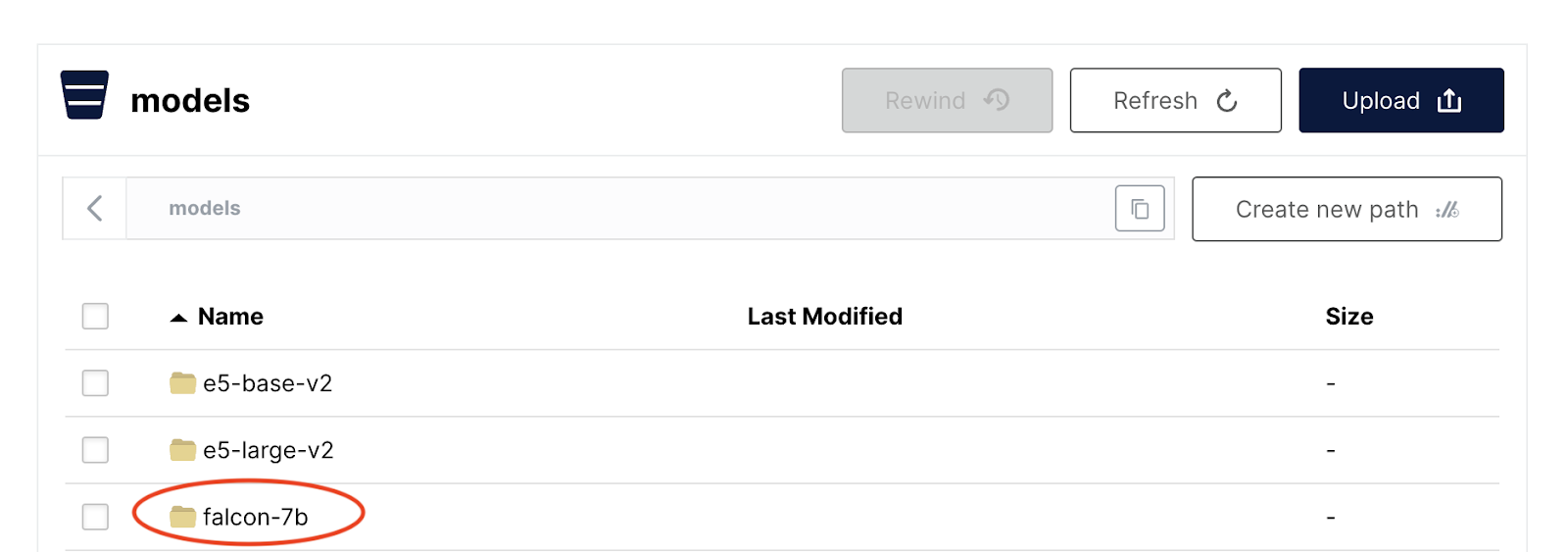
使用 MinIO 对象存储,您的服务基础设施现在更加轻量级,并且对模型架构的更改具有更高的弹性。因此,MAR 文件的通常较长的存档和解压缩时间被缩短了。此外,您的模型及其对应的 MAR 文件现在移动得更少,使您能够节省时间并减少对模型服务中常见的组织开销的担心。