利用 MinIO 和 lakeFS 进行并行机器学习实验


简介
这篇文章与来自 lakeFS 的 Iddo Avneri 合作撰写。
随着 ML 模型复杂度的不断增加和数据量的不断增长,ML 实践者面临着越来越大的挑战。高效的数据管理和 数据版本控制 现在已成为成功 ML 工作流程的关键部分。
在这篇博文中,我们将深入探讨并行 ML 的强大功能 - 使用不同的参数并行运行实验(例如,使用 不同的优化器,或使用不同的 历元数量),并探讨 lakeFS 和 MinIO 如何为您的 ML 实验提供强大支持,并简化您的开发流程。通过利用 lakeFS(一个开源数据版本控制工具)和 MinIO(一个高性能对象存储解决方案)的功能,您可以充分发挥并行 ML 的潜力,而不会影响性能或可扩展性。
MinIO 提供了一系列独特的优势,使其成为 ML 工作负载的理想选择。作为一个对象存储,MinIO 提供了卓越的可扩展性,使您能够无缝处理 ML 实验生成的大量数据。其分布式架构确保了高可用性和容错性,使您能够以最小的停机时间处理 ML 工作负载。此外,MinIO 与 S3 API 的兼容性使其易于与各种 ML 框架和工具集成,从而在您的 ML 生态系统中实现流畅的工作流程。此外,MinIO 的性能特征完美地补充了 AI/ML 工作负载的需求。MinIO 的 GETs/PUTs 结果在 32 个 NVMe 驱动器和 100GbE 网络的 32 个节点上超过 325 GiB/sec 和 165 GiB/sec。其芯片级加速、原子元数据和 Golang/Golang 汇编代码的组合使其能够在商品硬件上快速运行,将瓶颈推到网络带宽。更重要的是,MinIO 的性能涵盖了从最小(4KB)到最大(50 TiB)的所有对象大小范围。
将 MinIO 与 lakeFS 相结合的主要优势之一是能够实现并行化而不会产生额外的存储成本。lakeFS 利用了一种独特的方法(零克隆副本),其中不同版本的 ML 数据集和模型在不复制数据的情况下得到有效管理。
在本文中,我们将提供一个分步指南,并附带一个 Jupyter 笔记本,以演示这些工具如何协同工作以增强您的 ML 工作流程。无论您是数据科学家、ML 工程师还是 AI 爱好者,本博文都将为您提供利用并行 ML、加速模型开发流程和优化存储利用率所需的技术和工具。
敬请期待即将发布的部分,我们将介绍:
到本文结束时,您将全面了解 lakeFS 和 MinIO 如何彻底改变您管理 ML 数据的方式,简化您的实验流程,并在您的 ML 团队中促进无缝协作,同时最大限度地提高存储基础设施的效率。
步骤 1:设置
我们将利用一个预先打包的环境(Docker 容器),其中包含 MinIO、lakeFS、Jupyter 笔记本和 Spark。您可以在 此 Git 仓库 中了解有关此示例的更多信息。
克隆仓库
并启动环境
您第一次启动环境时,可能需要 20-30 分钟才能启动,具体取决于依赖项(双关语)。第二次启动时,只需要几秒钟🙂
启动环境后,您可以使用 Git 仓库自述文件中引用的链接和密码 登录 Jupyter、lakeFS 和 MinIO。在本示例中,我们将使用 `ML Experimentation/Reproducibility 01 (Dogs)` 笔记本(在 Jupyter UI 中)。笔记本从设置环境开始(例如,配置 lakeFS、MinIO、TensorFlow 等)。您可以跳到

部分,并运行该部分之前的全部单元格
完成后,所有内容都将安装完毕,我们可以开始在 MinIO 之上使用 lakeFS。
步骤 2:零克隆导入
我们需要一个数据集来使用。
在本例中,我们的 MinIO 服务器预先填充了一些示例数据,我们将将其导入到 lakeFS 中。具体而言,我们使用 斯坦福犬数据集, 该数据集位于 MinIO 中的 sample-data 存储桶内。

我们将 导入 MinIO 中的数据到 lakeFS 仓库中。值得注意的是,导入是一个零克隆操作,即不会实际复制任何数据。但是,您将能够访问数据并使用 lakeFS 对其进行版本控制。
运行以下命令后,该命令位于笔记本中。
登录 lakeFS 并查看仓库的内容
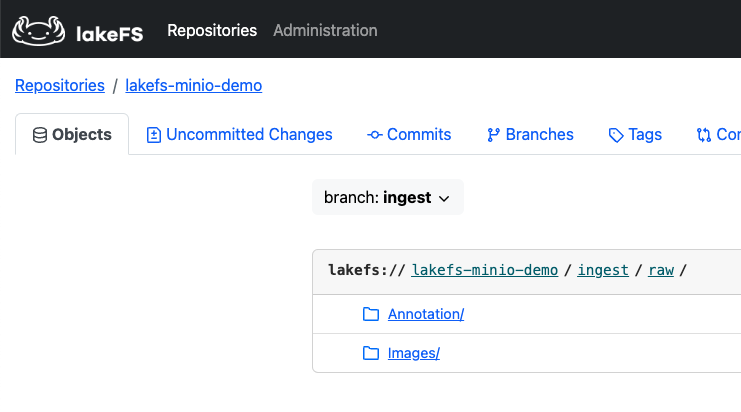
深入了解
为了更好地理解 lakeFS / MinIO 集成,让我们进一步检查 MinIO 中存储桶的内容。
除了我们导入的 sample-data 存储桶之外,lakeFS 仓库也位于一个 MinIO 存储桶之上,在我的情况下是 s3://example/26581964/lakefs-minio-demo(如以下存储命名空间所指定)。
让我们看看 MinIO 中该存储桶的内容。
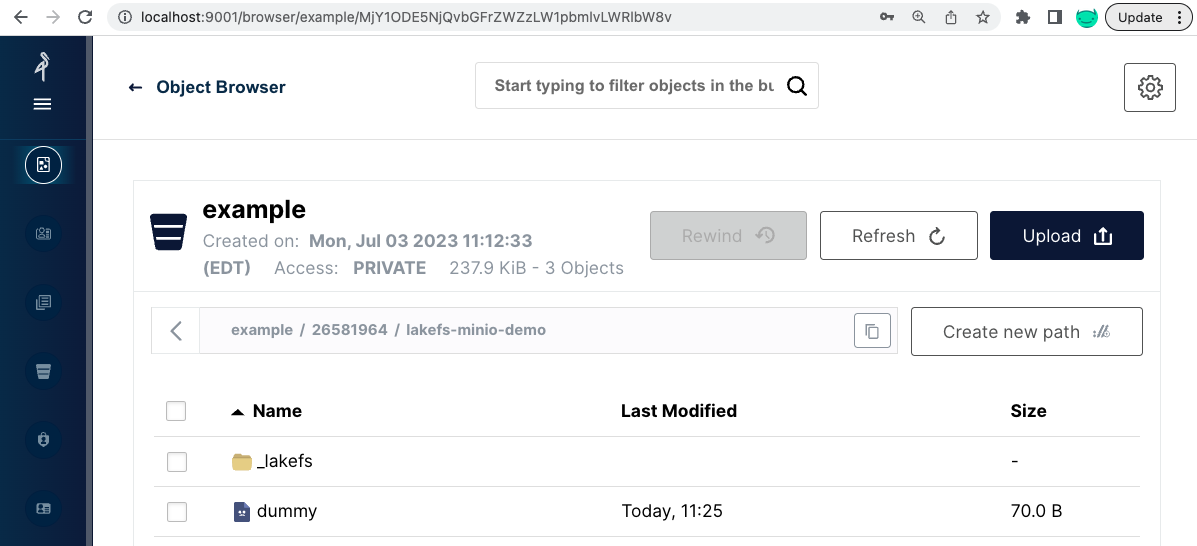
它包含一个单独的 70B 虚拟文件和一个 _lakefs 目录。当 lakeFS 创建仓库时,创建了这个虚拟文件,确保我们有权限写入存储桶。即使我们导入了数千个文件,_lakefs 路径也只包含 2 个文件。
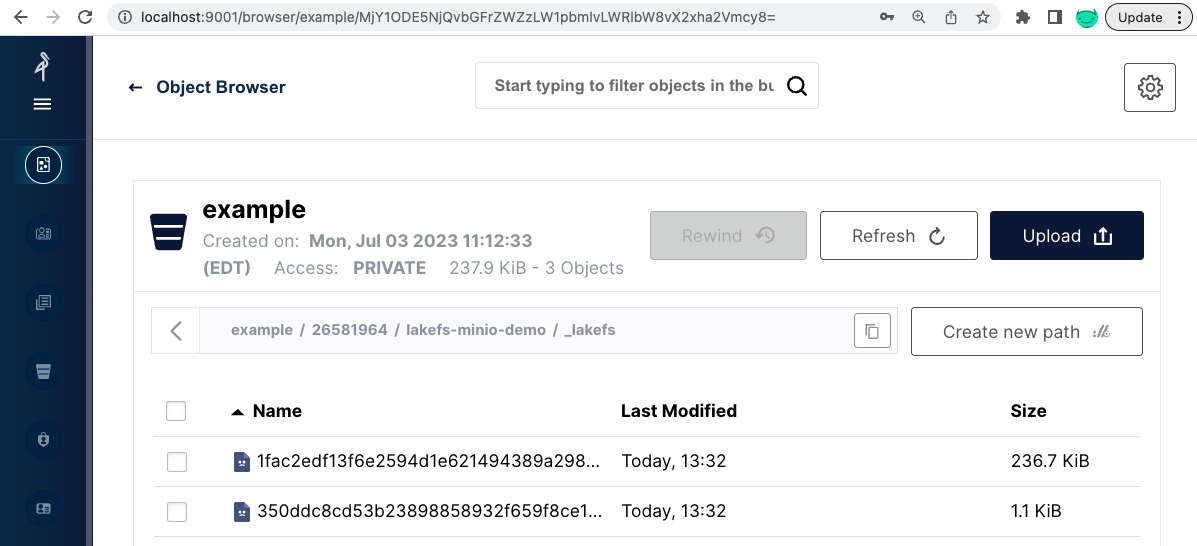
这些只是对我们导入的文件的原始位置的引用 (范围 / 元范围)。
但是,从现在开始,当我们通过 lakeFS 写入新对象时,新文件将位于目录中,而不是我们从其导入的原始目录中。
步骤 3:分支和并行 ML 实验
到目前为止,我们创建了一个 lakeFS 仓库,并将数据从 MinIO 导入到 ingest 分支中的该仓库。现在,导入数据后,我们将为每个实验创建一个分支,并使用略微不同的参数独立运行不同的实验。
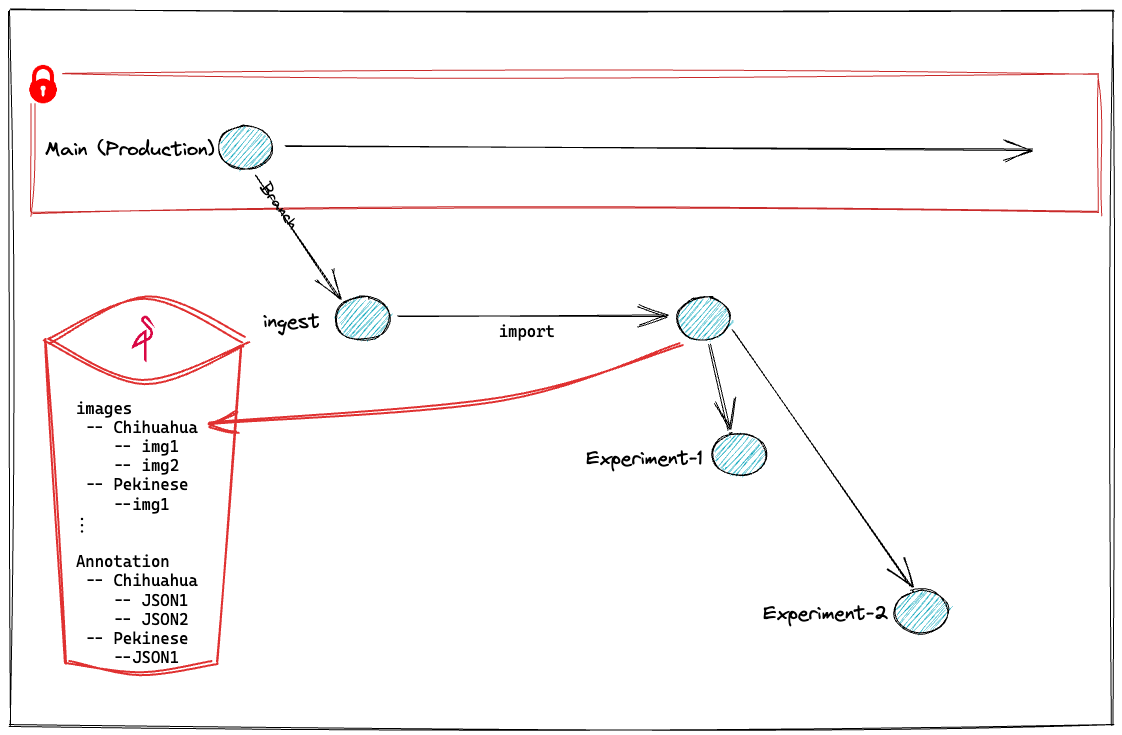
按照接下来的单元格中的笔记本,我们将设置第一个实验的参数,训练模型,运行预测,并将特定的模型配置和工件保存到其分支上。
这些步骤将包括(除其他外)从我们导入数据的 ingest 分支创建分支(例如 experiment-1)
例如,一旦我们完成第一个实验,experiment-1 分支将如下所示
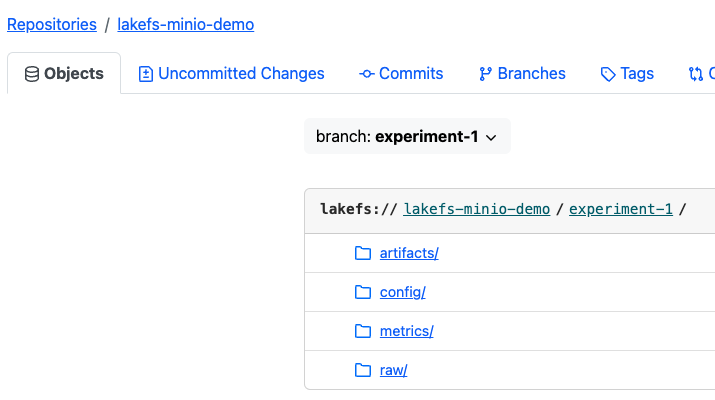
artifacts: 包含模型 .pkl 文件。
config: 包含此模型的参数配置。
metrics: 包含 损失和准确率 模型的指标(在此示例中,我们将使用 稀疏分类交叉熵 来衡量损失)
raw: 包含模型训练所针对的原始数据集。
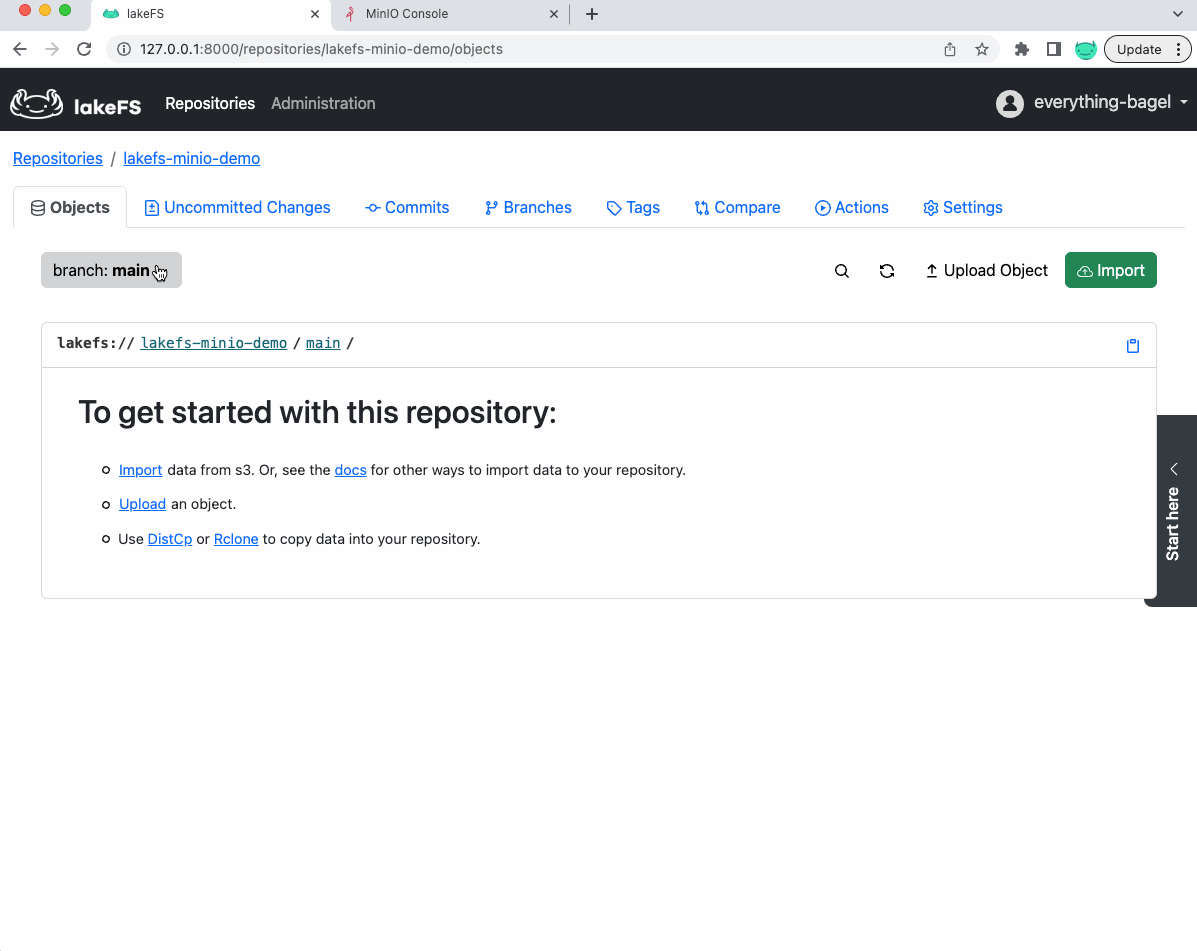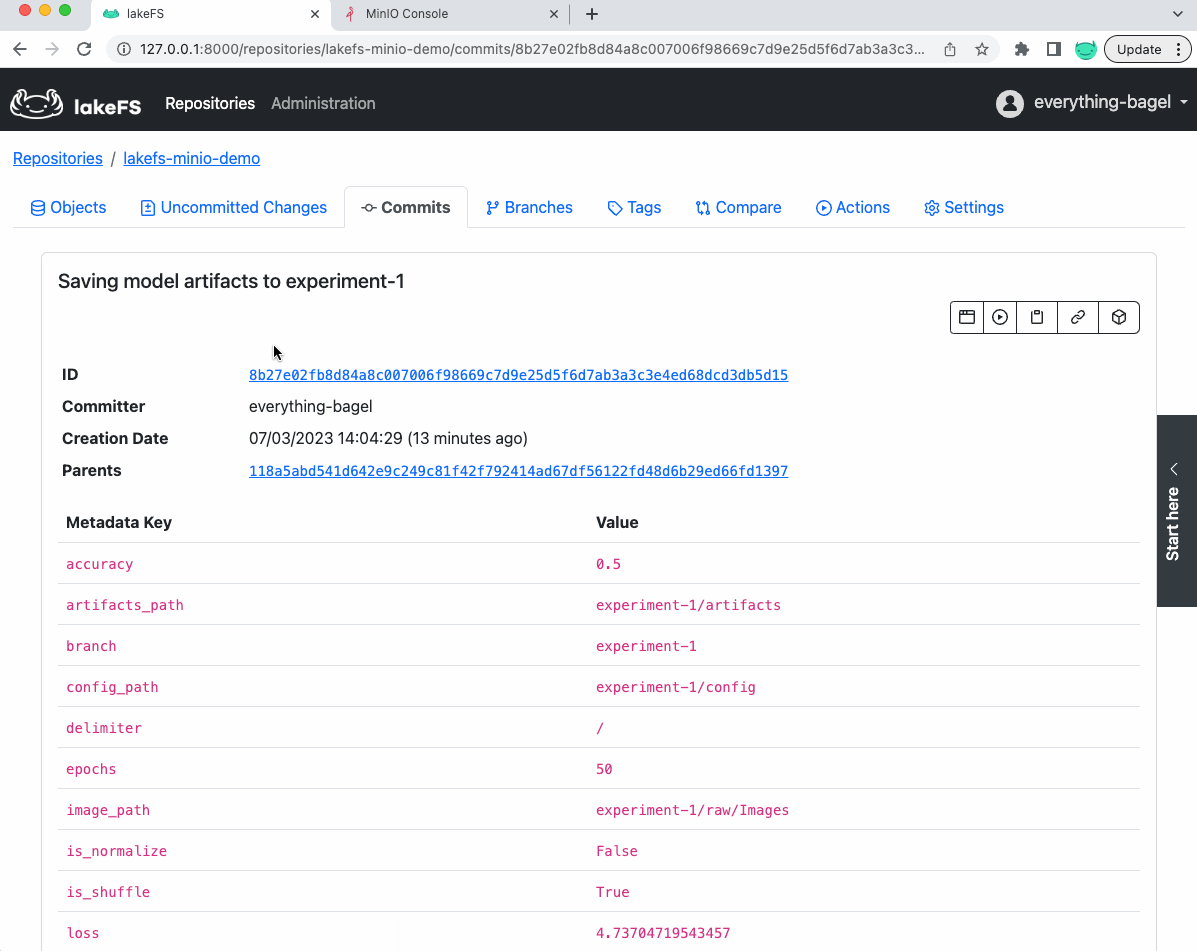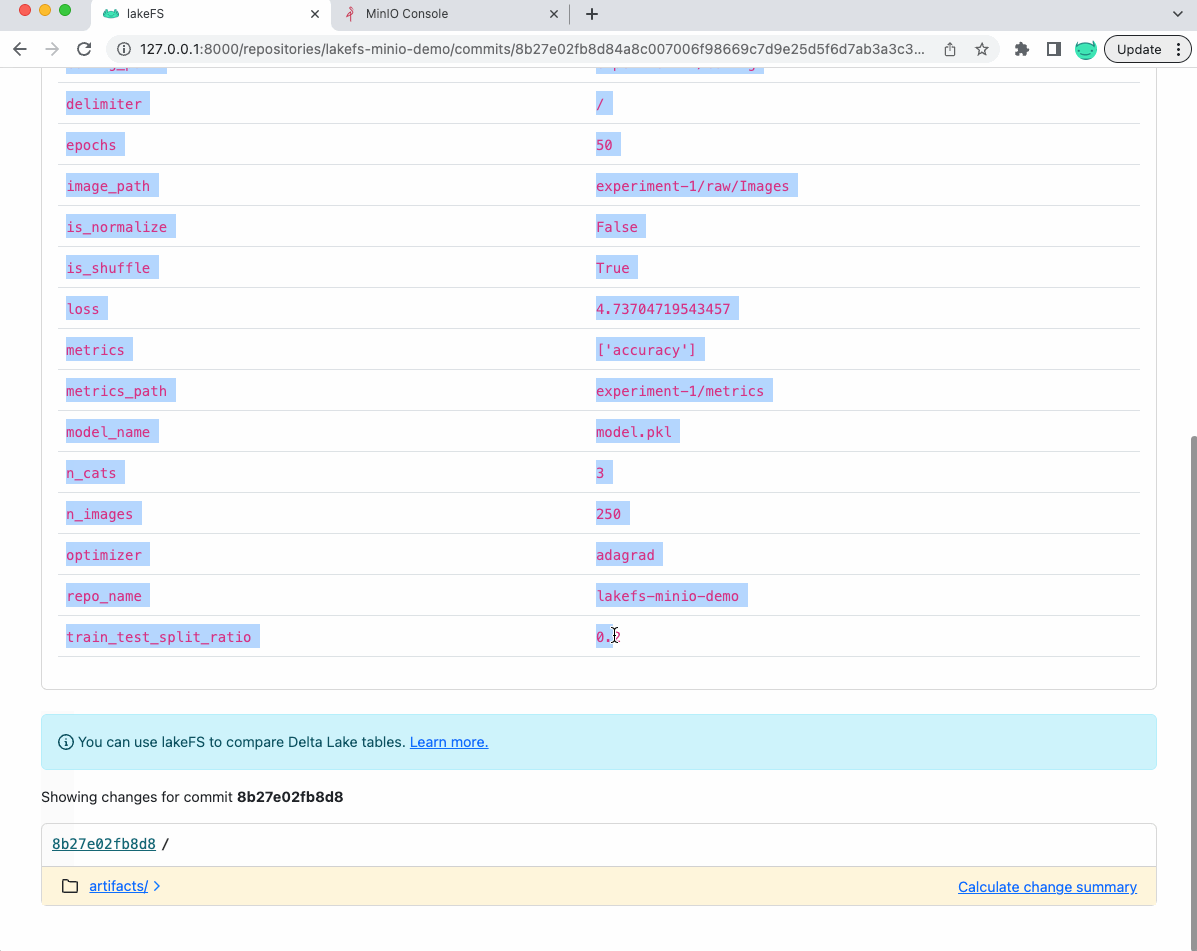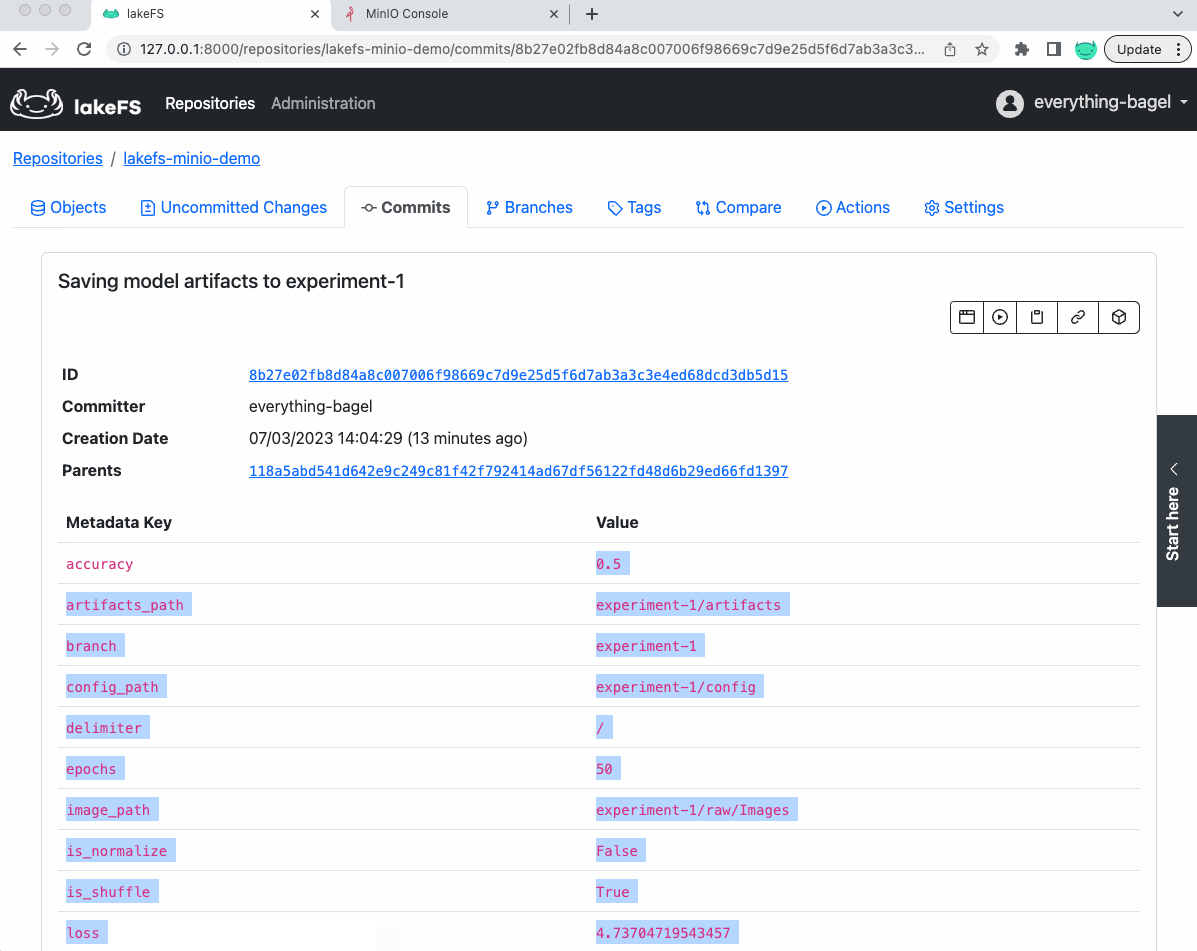
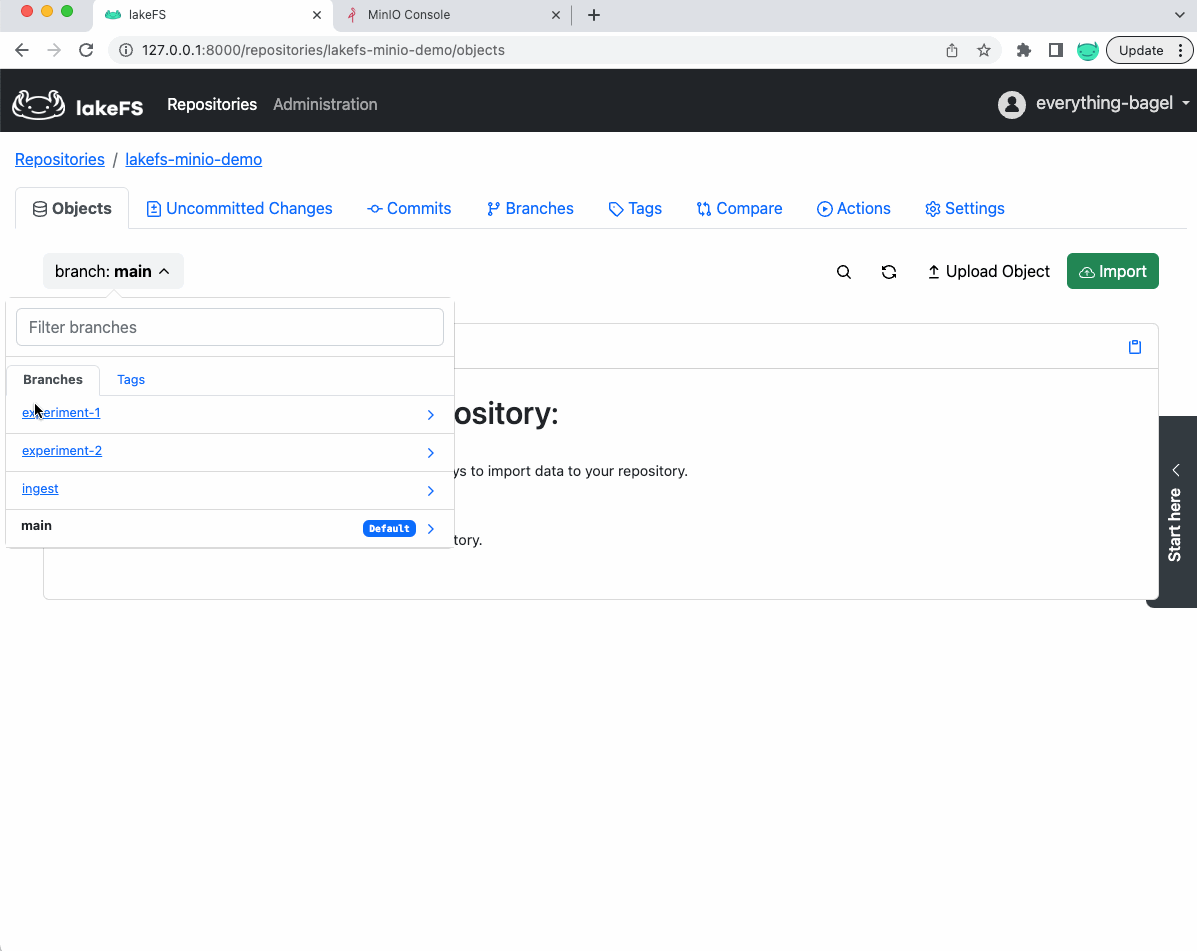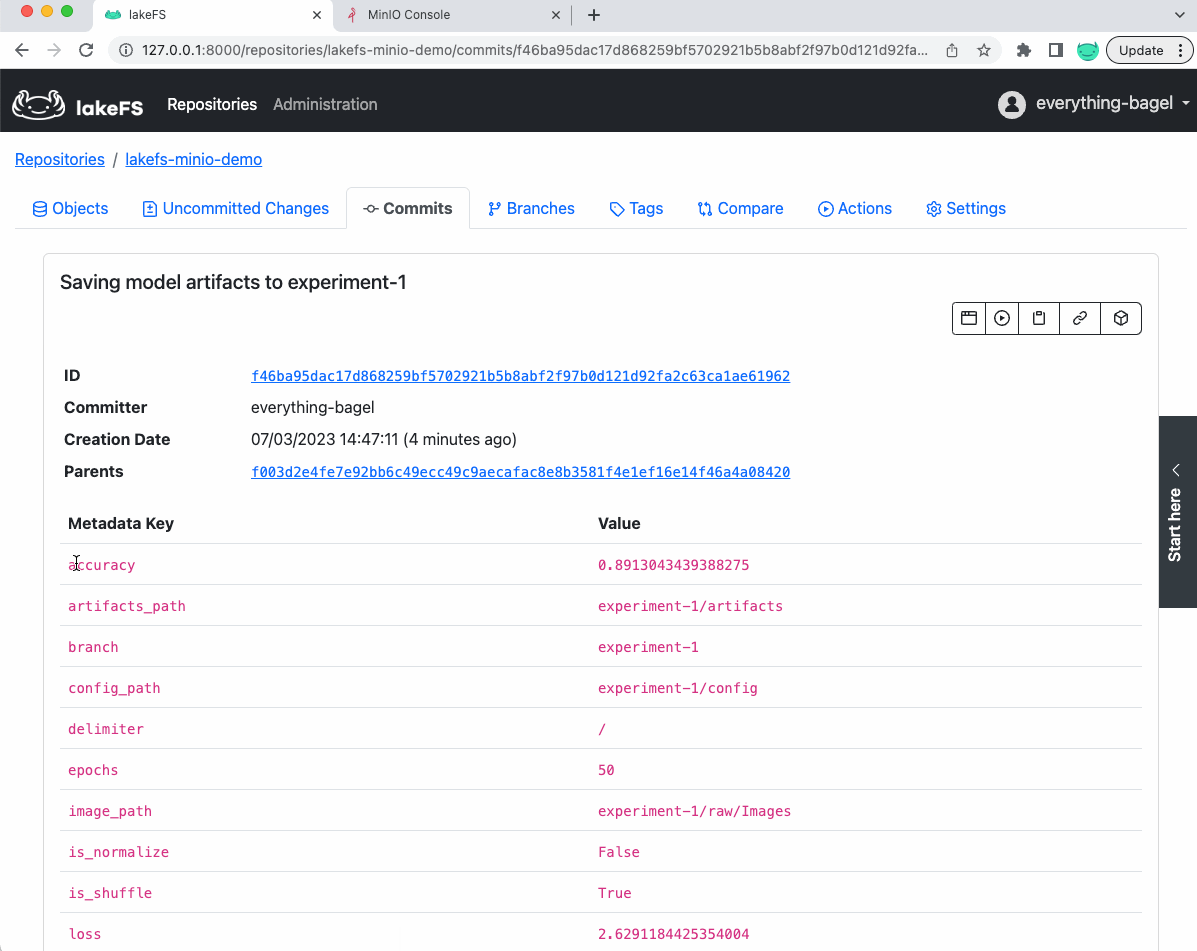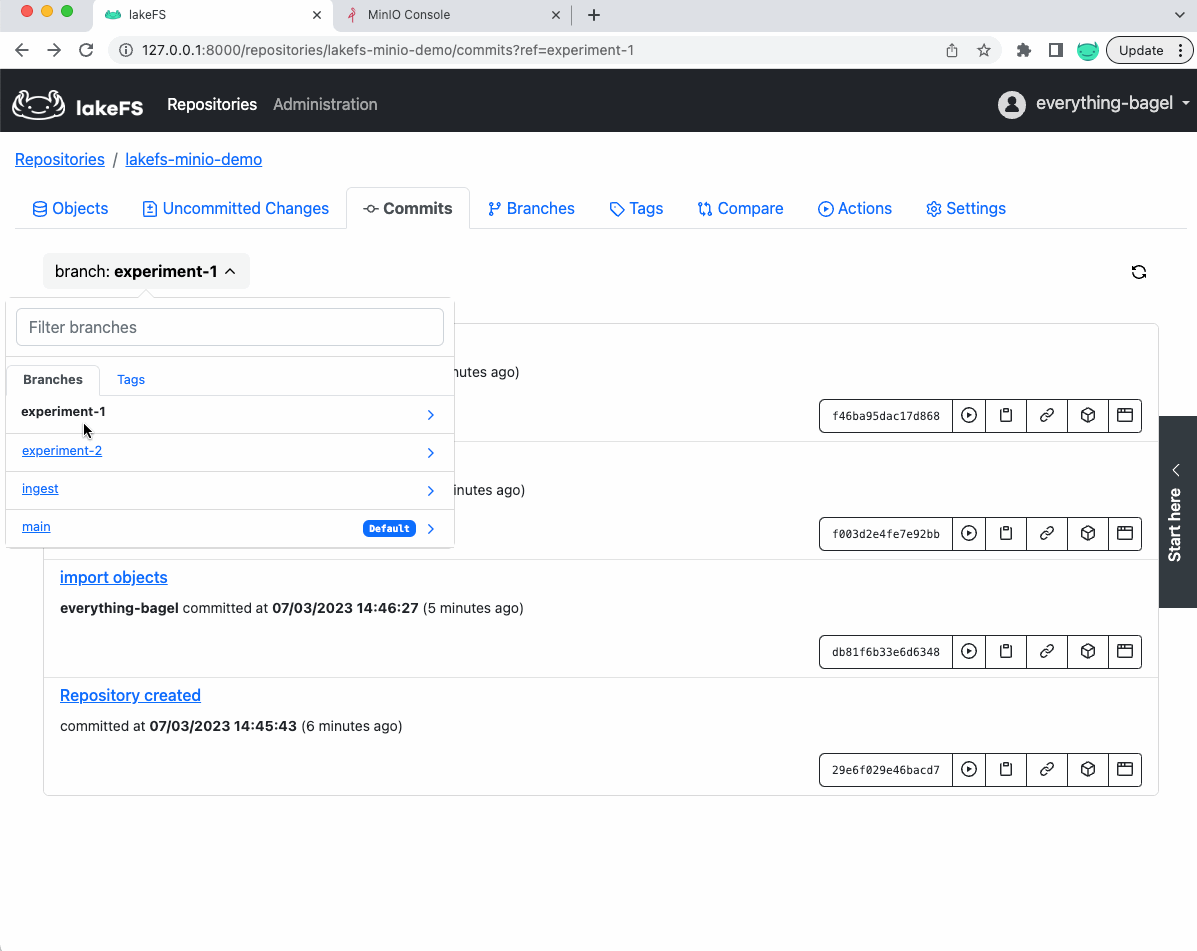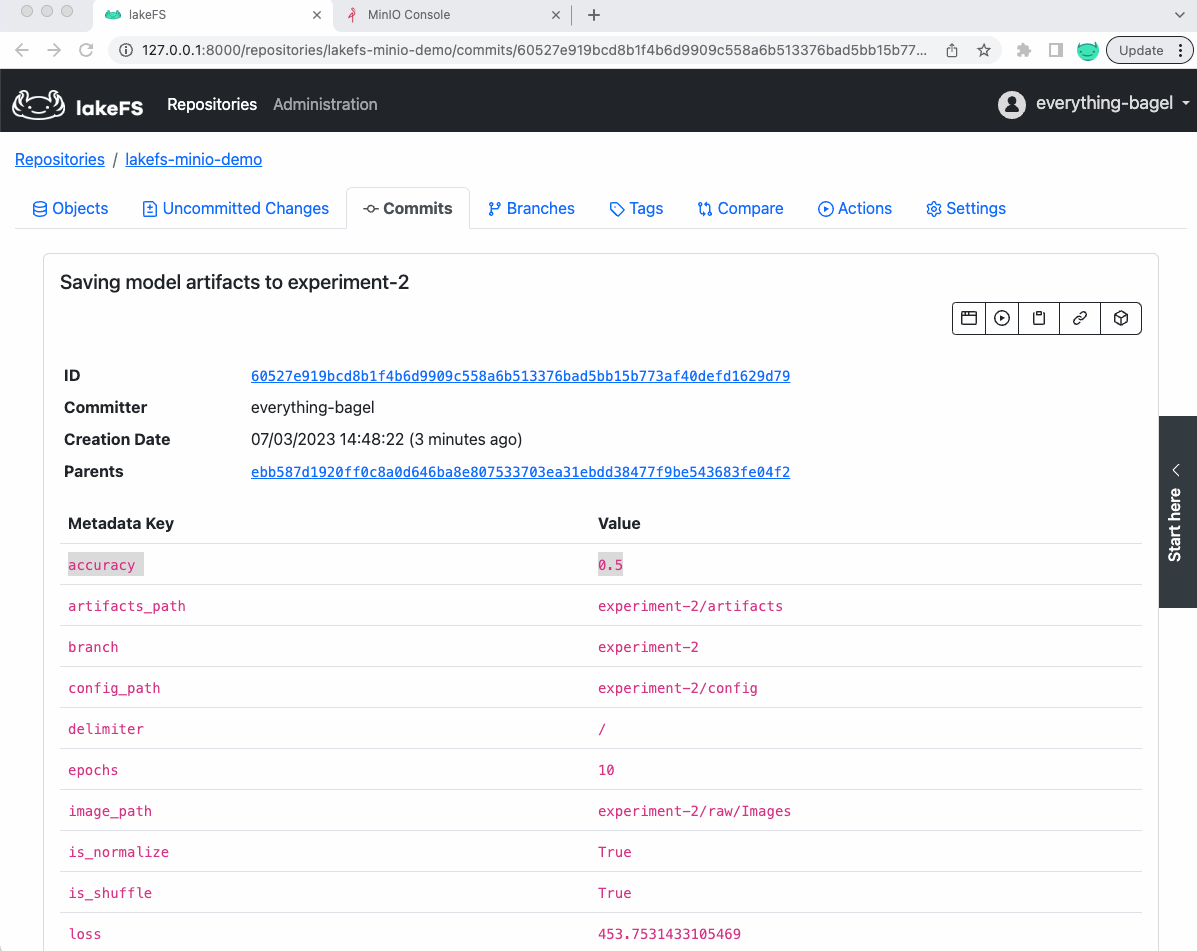
换句话说,我们在单个提交(如下所示)中对数据集、模型、其配置和准确率进行了版本控制,使其易于复制。
此外,如果我们查看 lakeFS 中保存模型的提交,我们会看到指标和参数作为提交的元数据(稍后可用于参考)
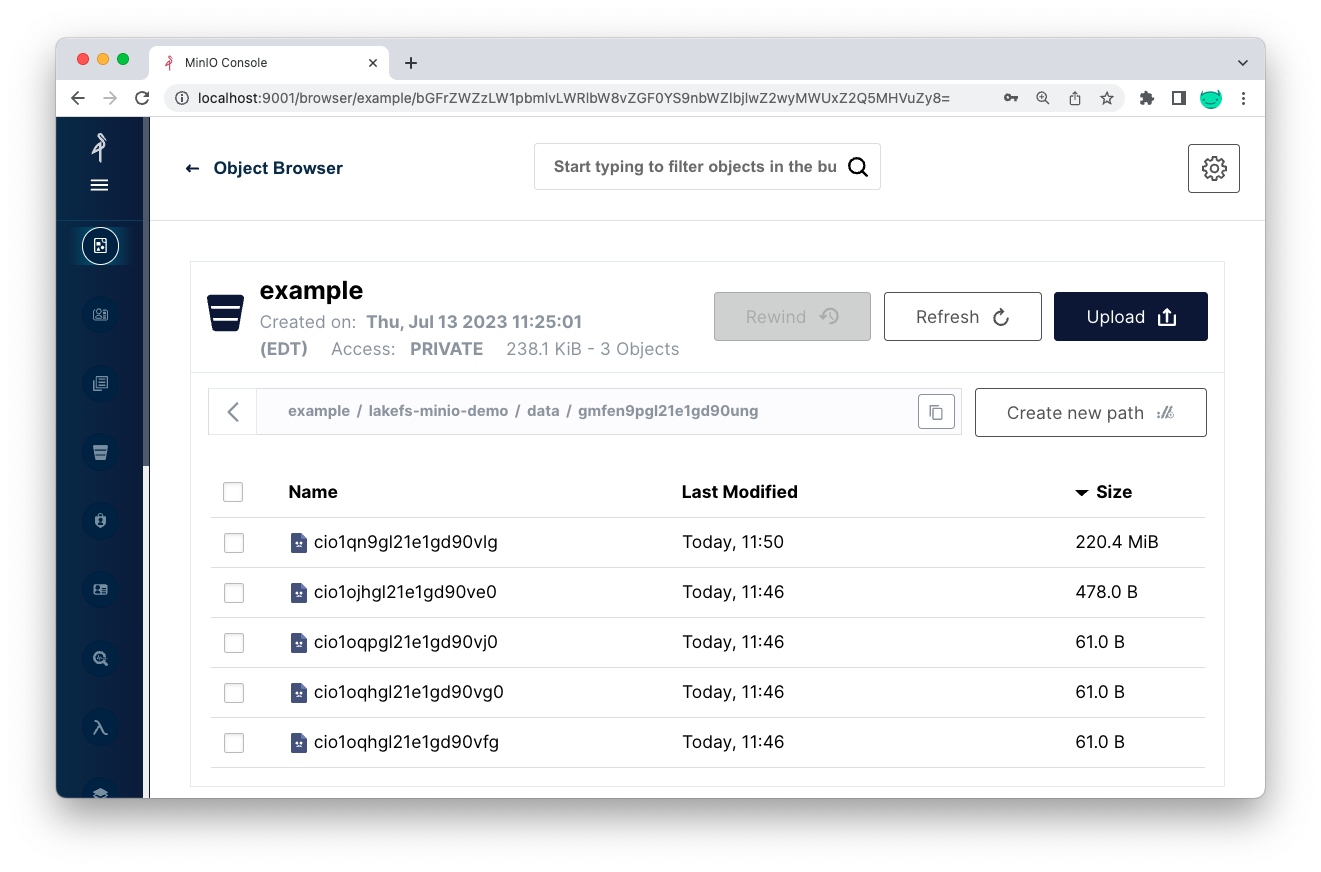
现在,让我们看看底层 MinIO 存储桶中的数据是什么样的
在示例存储桶中,在 lakefs-minio-demo 目录下,现在有一个名为 data 的新文件夹

我们保存的新文件(例如模型 .pkl 文件)保存在 data 路径下
专业提示
您可以点击 lakeFS UI 中任何文件旁边的齿轮,然后选择 object-info 来定位 MinIO 中的特定文件

完成实验 2 后,我们的 lakeFS 存储库将包含 2 个分支,保留每个实验的完整工件、数据和指标
步骤 4:比较和评估结果
两个实验都完成后,我们可以比较它们,并将最佳实验推广到生产环境。
例如
在上面的例子中,实验 1 的准确率要高得多;因此,我想把它推广到生产环境。运行合并操作将把该分支中的数据推广到我的主分支
再次强调,底层 MinIO 存储桶中的数据并没有被复制。但是,现在我有一个包含整个数据集、配置和模型性能的单个生产分支,以及单个参考提交。
想要了解更多?
如果您对 MinIO 有任何疑问,请发送邮件至 hello@min.io 或加入 MinIO 的 通用 Slack 频道 进行讨论。
如果您对 lakeFS 有任何疑问,请发送邮件至 hello@treeverse.io 或加入 lakeFS 的 Slack 频道 进行讨论。