使用 Alluxio、Apache Mesos 和 MinIO 的可扩展基因组数据处理管道
这篇文章来自我们 Guardant Health 的朋友的客座博客。
Guardant Health 是全面液体活检领域的全球领导者。肿瘤学家订购我们的血液检测,以帮助确定他们晚期癌症患者是否符合特定药物的治疗条件,这些药物针对肿瘤 DNA 中的特定基因组改变。每次检测都会产生大量基因组数据,我们将其处理成易于解释的检测结果。因此,我们需要一个端到端的 Data Processing 解决方案,它可以
● 灵活部署在本地和云端:基因组数据高度分布,并且涉及异构格式。我们需要能够灵活地在本地和云端跨不同存储系统存储数据。Mesos、Alluxio 和 MinIO 提供灵活的部署,因为它们都是云原生应用程序,并且与许多存储系统兼容,例如 Amazon S3。
● 可扩展:基因组学是最大的数据生成领域之一。我们正在以艾字节规模工作,因此可扩展性和成本效益是重要的考虑因素。我们需要一个能够将计算与存储分离的解决方案,以便每个组件可以独立扩展。在本篇文章中,我将进一步解释 Alluxio 和 MinIO 如何实现这一点。
● 高效:为了及时向医疗保健提供者提供信息,我们必须在 Data Processing 中实现高性能。我们之前的解决方案使用基于磁盘的存储系统,无法满足我们的性能需求。无论我们的 Data Processing 引擎有多快,处理速度都受到底层存储层的限制。即使当 Data Processing 引擎将数据池化到本地内存以克服 I/O 瓶颈时,可用内存的总量仍然是一个限制因素。Alluxio、MinIO 和 Apache Spark 都积极利用内存资源,通过共同协作,我们能够实现比以前高出几个数量级的性能。
Guardant Health 如何利用 Alluxio、MinIO 和 Spark 管理基因组数据
通过利用 Alluxio、Mesos、MinIO 和 Spark,我们创建了一个端到端的 Data Processing 解决方案,该解决方案高效、可扩展且成本优化。我们将 Alluxio 用作统一的存储层,以连接不同的存储系统,并带来内存性能,同时将 MinIO 作为 Alluxio 的底层存储,以保存冷数据(不经常访问的数据)并将数据同步到 AWS S3。Apache Spark 作为计算引擎。
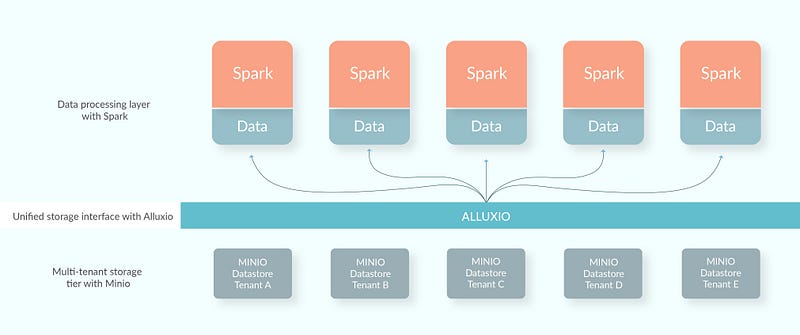
让我们了解一下这些组件分别带来了什么。
Apache Mesos 将 CPU、内存、存储和其他计算资源从机器(物理或虚拟)中抽象出来,使容错和弹性分布式系统能够轻松构建并有效运行。
MinIO 是一款云原生、与 AWS S3 兼容的对象存储服务器。虽然存储传统上被认为很复杂,但 MinIO 通过其云原生、容器友好的架构改变了这一点。部署 MinIO 就像拉取官方 Docker 镜像并启动容器一样简单。容器化部署意味着您可以通过为每个租户简单地启动一个新的 MinIO 实例,在多租户环境中扩展您的 MinIO 部署。
MinIO 专门关注具有弹性、生产级的存储,其功能包括使用擦除编码的位腐烂保护、分布式模式和共享模式。这将基础架构与存储分离,并使您能够完美地利用容器编排领域中的最新技术。
现代应用程序需要不同的存储系统来处理不同的数据类型。但是,随着 Data Processing 的加入,多个存储系统变得难以管理。您要么需要将您的 Data Processing 引擎与每个存储系统集成,从而使它们耦合得太紧密而无法独立扩展;要么需要先收集数据并将其传输到一个公共位置,这会增加开销和延迟。
Alluxio 通过在计算节点的本地存储介质(理想情况下是 RAM)上提供一个分布式统一文件系统来解决此问题。这意味着 Alluxio 创建了一个按需管道,从存储系统到计算节点——所有数据都在一个命名空间和一个接口中。
现在您已经了解了所有组件,让我们概述一下如何设置它们。
先决条件
● 按照这些指南在 Mesos 集群上设置 Alluxio。
● 按照这些指南在集群模式下设置 Alluxio 集群。
● 设置 MinIO 服务器,并了解端点、访问密钥和密钥。
● 设置 Apache Spark。
将 MinIO 设置为 Alluxio 的底层存储
要将 MinIO 配置为 Alluxio 的底层存储,请打开 conf/alluxio-site.properties 文件并添加配置详细信息。
alluxio.master.hostname=localhost
alluxio.underfs.address=s3a://testbucket/test
alluxio.underfs.s3.endpoint=https://:9000/
alluxio.underfs.s3.disable.dns.buckets=true
alluxio.underfs.s3a.inherit_acl=false
alluxio.underfs.s3.proxy.https.only=false
请注意,您需要添加您的 MinIO 服务器端点、访问密钥和密钥。接下来,您需要格式化 Alluxio 日志和工作节点存储目录,以便 master 和 worker 启动。您可以使用以下命令执行此操作
./bin/alluxio format
最后启动 Alluxio
./bin/alluxio-start.sh local
使用 Alluxio 设置 Spark
您需要使用 Spark 特定的配置文件编译 Alluxio 客户端。为此,请使用以下命令从顶层 alluxio 目录构建整个项目
mvn clean package -Pspark -DskipTests
然后,将以下行添加到 spark/conf/spark-defaults.conf。
spark.driver.extraClassPath /pathToAlluxio/core/client/target/alluxio-core-client-1.4.0-jar-with-dependencies.jar
spark.executor.extraClassPath /pathToAlluxio/core/client/target/alluxio-core-client-1.4.0-jar-with-dependencies.jar
有关高级设置,请参考 Alluxio 文档。
集群配置
上面描述的架构已在生产环境中部署,配置如下:
- 集群规模 = 50 多个节点,每个节点大约有 60 个内核,每个节点的内存大小在 512GB 到 1TB 之间。
- Alluxio RAM 大小 > 20TB
- Alluxio HDD 大小 > 200TB
- MinIO 归档存储池约 1.2PB+(并且每天都在增长;)
结论
我们的数据需求正在快速增长,因此,我们的基因组数据处理解决方案必须高效、可扩展且成本优化。借助 Alluxio、MinIO 和 Spark,我们能够创建一个高效、健壮且可扩展的系统,以云原生方式执行大规模数据处理。MinIO 提供了一个可扩展、健壮、多租户的存储选项,可以在商品硬件上运行;Alluxio 提供了一个统一的接口来管理所有数据,同时还带来了更高的性能;Spark 利用 Alluxio 提供的内存中数据来确保快速数据处理。借助这种数据处理解决方案,我们有信心能够继续交付产品,以帮助医疗保健提供者在抗癌斗争中取得胜利。
同时,请帮助我们了解您的用例以及我们如何更好地帮助您!填写我们的 MinIO 部署最佳实践表格(不到一分钟),并有机会在 MinIO 网站上展示您的 MinIO 私有云设计,并将其展示给 MinIO 社区。