使用 MLFlow 和 MinIO 设置开发机器

关于 MLflow
MLflow 是一个开源平台,旨在管理完整的机器学习生命周期。Databricks 作为内部项目创建了它,以解决他们在机器学习开发和部署过程中遇到的挑战。MLflow 于 2018 年 6 月作为开源项目发布。
作为管理完整生命周期的工具,MLflow 包含以下组件。
- MLflow 跟踪 - 工程师将最常使用此功能。它允许记录和查询实验。它还跟踪每个实验的代码、数据、配置和结果。
- MLflow 项目 - 通过将代码打包成平台无关的格式,允许复制实验。
- MLflow 模型 - 将机器学习模型部署到可以提供服务的环境中。
- MLflow 存储库 - 允许在中央存储库中存储、注释、发现和管理模型。
可以在开发机器上安装所有这些功能,这样工程师就可以随心所欲地进行实验,而不必担心会搞乱生产安装。
所有用于安装和设置 MLflow 的文件都可以在我们的 Github 仓库 中找到。
安装选项
在 MLFlow 文档 中列出了不少于 6 个安装 MLFlow 的选项。这可能看起来有些过分,但这些选项适应了对数据库的不同偏好以及不同的网络复杂程度。
最适合拥有多个团队使用大型数据集并构建本身可能变得相当大的模型的组织的选项如下所示。此选项需要设置三个服务器 - 跟踪服务器、PostgreSQL 数据库和 S3 对象存储 - 我们的实现将使用 MinIO。

跟踪服务器是从工程师的开发机器访问 MLflow 功能的单一入口点。(不要被它的名字所迷惑 - 它包含上面列出的所有组件 - 跟踪、模型、项目和存储库。)跟踪服务器使用 PostgreSQL 来存储实体。实体是运行、参数、指标、标签、注释和元数据。(关于运行的更多信息稍后介绍。)我们实现中的跟踪服务器访问 MinIO 来存储工件。工件的示例包括模型、数据集和配置文件。
现在工程师可以使用现代工具,可以使用容器来模拟生产环境,包括工具选择和网络连接。这就是我将在本文中展示的内容。我将展示如何使用 Docker Compose 将上面描述的服务器安装为在容器中运行的服务。此外,MLflow 的配置设置允许您使用现有实例的 MinIO(如果您愿意)。在本文中,我将展示如何部署一个全新的 MinIO 实例,但我们 Github 仓库 中的文件有一个 `docker-compose` 文件,它展示了如何连接到现有实例的 MinIO。
我们将安装什么
以下是需要安装的所有内容的列表。此列表包括将成为容器中服务的服务器(MinIO、Postgres 和 MLFlow),以及您将需要的 SDK(MinIO 和 MLflow)。
- Docker 桌面
- 通过 Docker Compose 安装 MLFlow 跟踪服务器
- 通过 Docker Compose 安装 MinIO 服务器
- 通过 Docker Compose 安装 PostgresSQL
- 通过 pip install 安装 MLFlow SDK
- 通过 pip install 安装 MinIO SDK
让我们从 Docker 桌面开始,它将作为我们 Docker Compose 服务的主机。
Docker 桌面
您可以在 Docker 的网站上找到适用于您操作系统的 适当的安装。如果您要在 Mac 上安装 Docker Desktop,那么您需要知道 Mac 使用的芯片 - Apple 或 Intel。您可以通过点击 Mac 左上角的 Apple 图标并点击“关于本机”菜单选项来确定这一点。
我们现在准备安装我们的服务
MLFlow 服务器、Postgres 和 MinIO
MLFLow 跟踪服务器、PostgreSQL 和 MinIO 将使用下面显示的 Docker Compose 文件作为服务安装。
有一些值得注意的事情可以帮助您在出现问题时进行故障排除。首先,MinIO 和 PostgreSQL 都使用本地文件系统来存储数据。对于 PostgreSQL,这是 `db_data` 文件夹,对于 MinIO,它是 `minio_data` 文件夹。如果您想重新开始全新的安装,请删除这些文件夹。
接下来,此 Docker Compose 文件是配置驱动的。例如,而不是将 PostgreSQL 数据库名称硬编码为 `mlflow`,该名称来自下面显示的 `config.env` 文件,在 Docker Compose 文件中使用以下语法 - `${PG_DATABASE}`。
此文件中设置了这些服务所需的所有环境变量。此配置文件还包含这些服务相互通信所需的信息。请注意,是环境变量的使用告知 MLflow 跟踪服务器如何访问 MinIO。换句话说,URL(包括端口号)、访问密钥、秘密访问密钥和存储工件的存储桶。这引出了我关于使用 Docker Compose 的最后也是最重要的一点——第一次启动这些服务时,MLflow 跟踪服务将无法工作,因为您需要先进入 MinIO UI,获取密钥并创建跟踪服务将用于存储工件的存储桶。
现在让我们这样做。使用下面的命令首次启动服务。
确保您在 Docker Compose 文件所在的同一目录中运行此命令。
现在我们可以使用 MinIO UI 获取密钥并创建存储桶。
MinIO 控制台
在浏览器中,转到 `localhost:9001`。如果您在 `docker-compose` 文件中为 MinIO 控制台地址指定了其他端口,请改用该端口。使用 `config.env` 文件中指定的根用户和密码登录。
登录后,导航到“访问密钥”选项卡,然后单击“创建访问密钥”按钮。
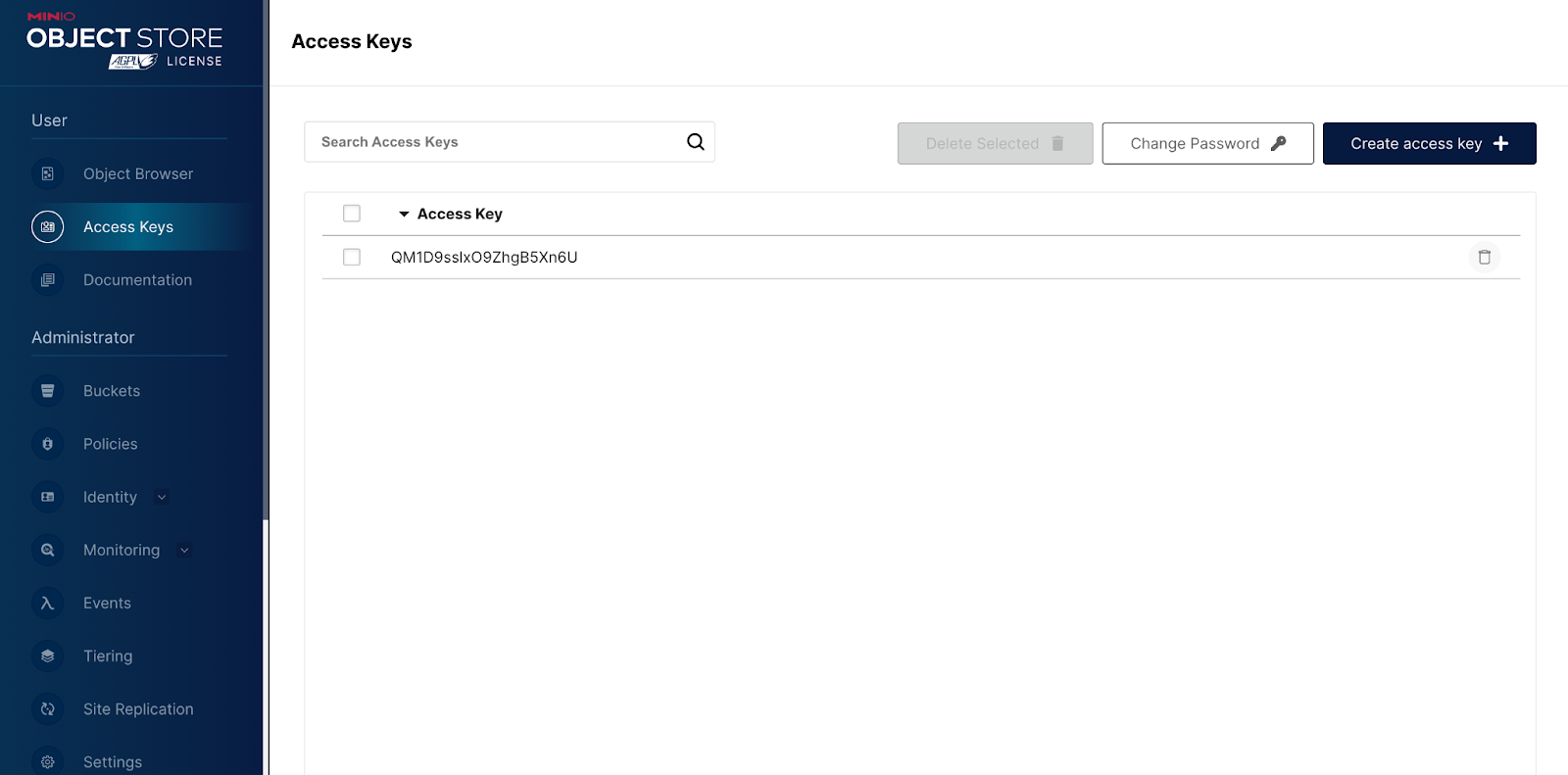
这将带您进入“创建访问密钥”页面。
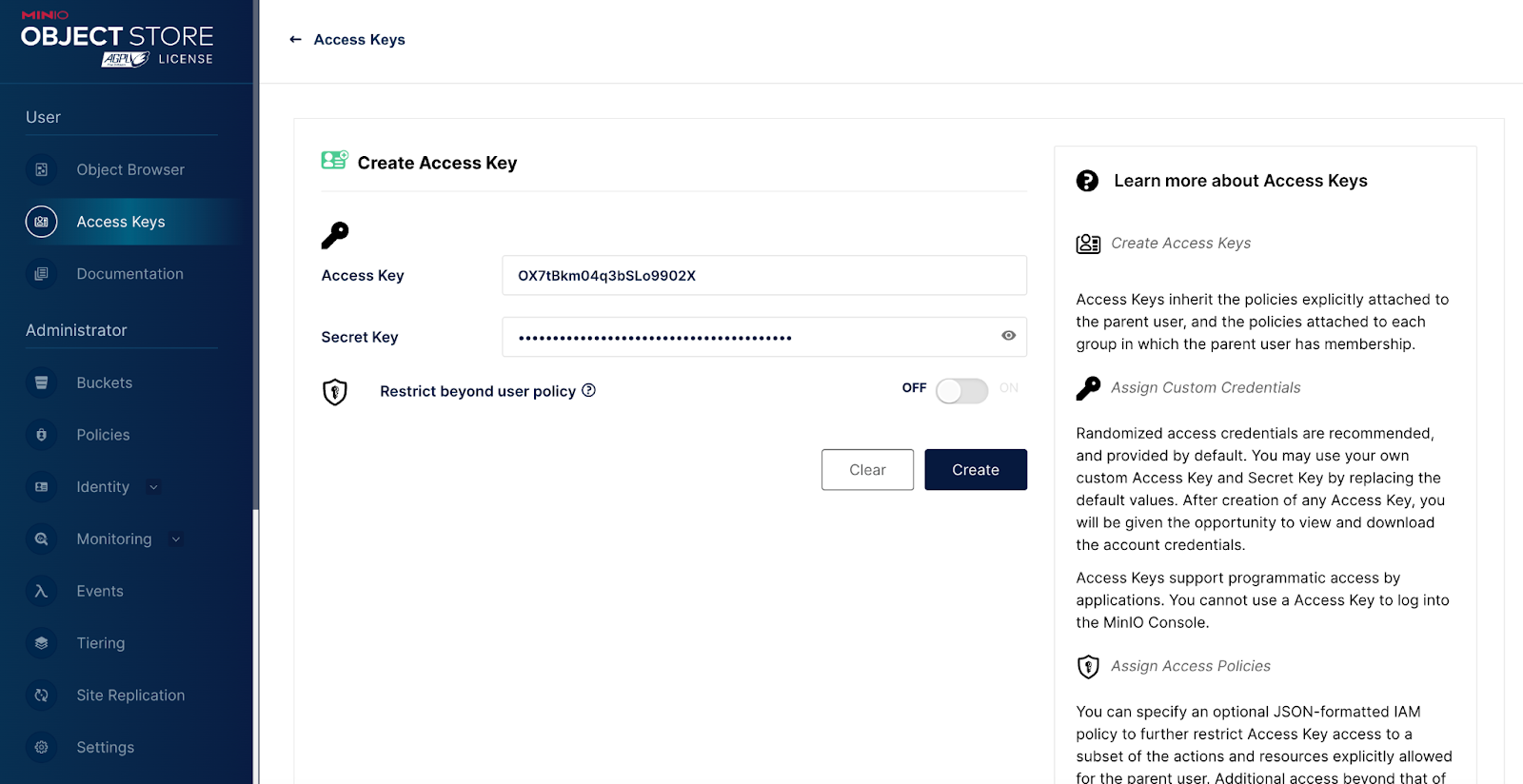
在您单击“创建”按钮之前,您的访问密钥和秘密密钥不会保存。在完成此操作之前,请勿离开此页面。不要担心从这个屏幕复制密钥。单击“创建”按钮后,您将可以选择将密钥下载到您的文件系统(在 JSON 文件中)。如果您想使用 MinIO SDK 管理原始数据,那么您在该页面上创建另一个访问密钥和秘密密钥。

接下来,创建一个名为 `mlflow` 的存储桶。这很简单,进入“存储桶”选项卡,然后单击“创建存储桶”按钮。
获得密钥并创建存储桶后,您可以通过停止容器、更新 `config.env`,然后重新启动容器来完成服务的设置。以下命令将停止并删除您的容器。
重新启动
接下来,让我们启动 MLflow UI 并确保一切正常。
启动 MLflow UI
导航到 `localhost:5000`。您应该看到 MLflow UI。
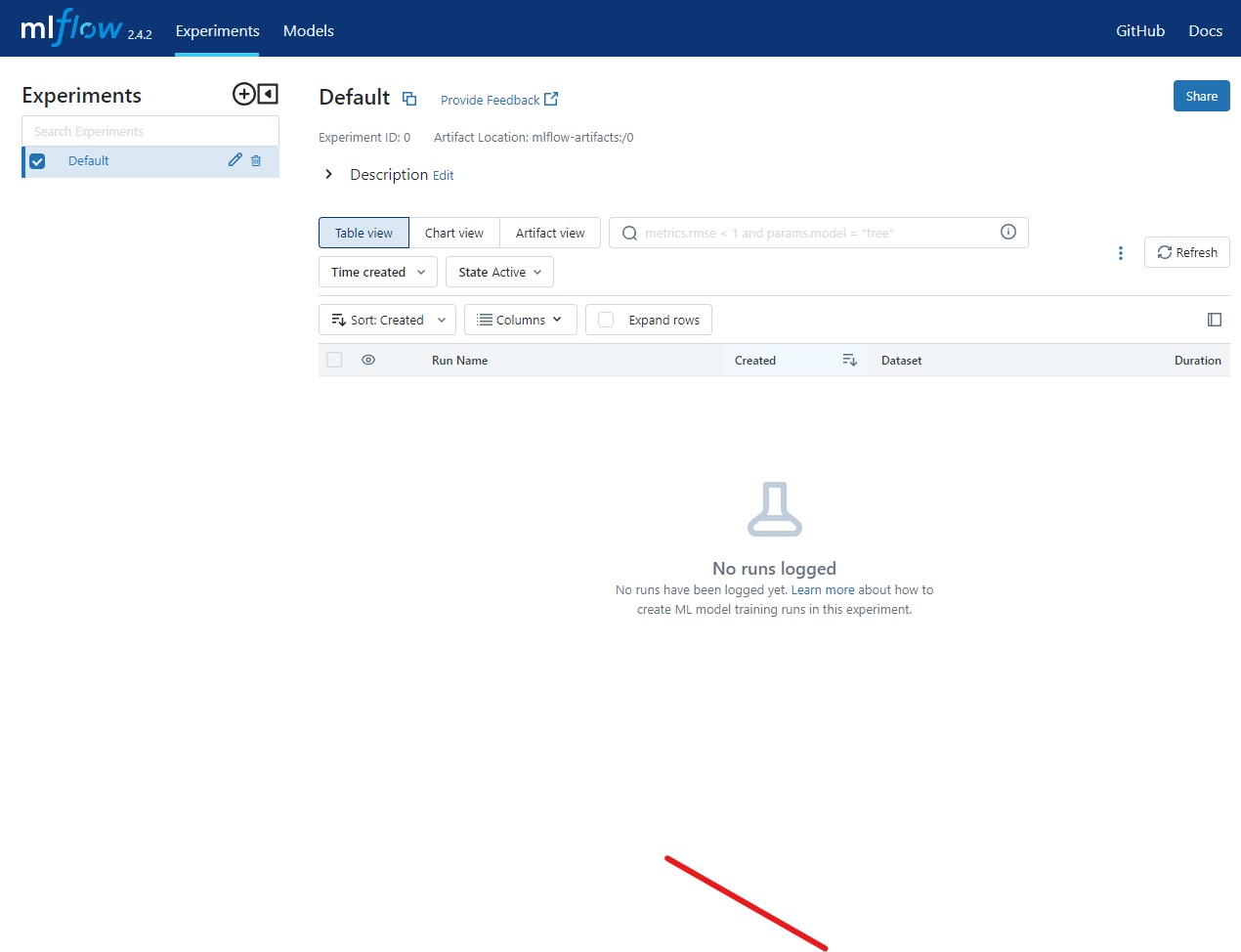
花些时间探索所有选项卡。如果您是 MLflow 的新手,那么请熟悉“运行”和“实验”的概念。
- 运行是指通过代码的传递,通常会导致训练好的模型。
- 实验是标记相关运行的一种方式,以便您可以在 MLflow UI 中看到它们分组在一起。例如,您可能已经使用不同的参数训练了几个模型,以试图获得最佳的准确率(或性能)。使用相同的实验名称标记这些运行将在“实验”选项卡中将它们分组在一起。
安装 MLflow Python 包。
MLflow Python 包是一个简单的 `pip` 安装。我建议在 Python 虚拟环境中安装它。
通过列出 MLflow 库来仔细检查安装情况。
您应该看到下面的库。
安装 MinIO Python 包
您无需直接访问 MinIO 即可利用 MLflow 的功能——MLflow SDK 将与我们上面设置的 MinIO 实例交互。但是,您可能希望直接与此 MinIO 实例交互以管理数据,然后再将其提供给 MLflow。MinIO 是存储各种非结构化数据的绝佳方式。MinIO 充分利用底层硬件,因此您可以保存所有需要的原始数据,而无需担心规模或 性能。MinIO 包括 存储桶复制 功能,以保持多个位置的数据同步。此外,人工智能总有一天会受到监管;当这一天到来时,您将需要 MinIO 的企业功能(对象锁定、版本控制、加密 和 法律锁定)来保护您的数据,并确保您不会意外删除监管机构可能要求的内容。
如果您在虚拟环境中安装了 MLflow Python 包,请在同一个环境中安装 MinIO。
再次检查安装情况。
这将确认 Minio 库已安装,并显示您使用的版本。
总结
这篇文章提供了一个简单易懂的指南,用于在开发机器上设置 MLflow 和 MinIO。目的是节省您在研究 MLflow 服务器和 docker compose 配置方面的时间和精力。
我们尽一切努力确保该指南准确无误。如果您遇到问题,请通过发送邮件到 hello@min.io 或加入我们 general Slack channel 上的讨论告知我们。
您已经准备好开始使用 MLflow 和 MinIO 进行编码和训练模型。