MLOps 对于机器学习而言,就像 DevOps 对于传统软件开发一样。两者都是一组旨在改进工程团队(开发或机器学习)和 IT 运维团队(运维)之间协作的实践和原则。其目标是利用自动化简化开发生命周期,从计划和开发到部署和运维。这些方法的主要优势之一是持续改进。
在之前关于 MLOps 工具的文章中,我介绍了 KubeFlow Pipelines 2.0 和 MLflow。在这篇文章中,我想介绍 MLRun,另一个 MLOps 工具,如果您正在为您的组织寻找 MLOps 工具,则应该考虑它。但在深入探讨之前,让我们快速了解一下 MLOps 的现状。
MLOps 的现状
虽然这三种工具都旨在为您的所有 AI/ML 需求提供完整的端到端工具,但它们都始于不同的动机或设计目标。
- KubeFlow 的目标是使 Kubernetes 民主化。KubeFlow 的核心 KubeFlow Pipelines 要求代码通过部署到 Kubernetes Pod 的无服务器函数运行。
- MLflow 最初是一个用于跟踪实验以及与您的 ML 实验相关的所有内容的工具,例如指标、工件(您的数据)和模型本身。MLflow 了解流行的 ML 框架,如果您选择,您可以要求 MLflow 自动捕获它认为重要的所有实验数据。
- MLRun 的使命(使其有别于其他 MLOps 工具)是消除样板代码。它也需要创建无服务器函数,但它更进一步地发展了这个概念,因为它了解流行的 ML 框架——因此,不需要编写 epoch 循环,并且对分布式训练提供了低代码支持。
更多关于 MLRun 的信息
MLRun 是一个开源的 MLOps 框架,最初由专注于数据科学的公司 Iguazio 创建。2023 年 1 月,Iguazio 被麦肯锡公司收购,现在是麦肯锡 AI 部门 QuantumBlack 的一部分。
让我们看一下安装选项以及需要部署的服务。
安装选项
MLRun 网站 推荐三种在本地安装 MLRun 的方法。Iguazio 还维护着一个托管服务。
本地选项
- 本地部署:使用 Docker compose 文件在您的笔记本电脑或单个服务器上部署 MLRun 服务。此选项需要 Docker Desktop,并且比 Kubernetes 安装更简单。它非常适合试验 MLRun 功能;但是,您将无法扩展计算资源。
- Kubernetes 集群:在您自己的 Kubernetes 集群上部署 MLRun 服务。此选项支持弹性扩展;但是,安装起来更复杂,因为它要求您自己安装 Kubernetes。您还可以使用此选项将部署到 Docker Desktop启用的 Kubernetes 集群。
- Amazon Web Services (AWS):在 AWS 上部署 MLRun 服务。此选项是安装 MLRun 的最简单方法。MLRun 软件免费;但是,AWS 基础设施服务需要付费。
托管服务
此外,如果您不介意共享环境,则可以使用 Iguazio 的托管服务。Iguazio 提供 14 天免费试用。
介绍 MLRun 服务
MLRun UI:MLRun UI 是一个基于 Web 的用户界面,您可以在其中查看您的项目和项目运行。
MLRun API:MLRun API 是您的代码将用于创建项目和启动运行的编程接口。
Nuclio:Nuclio 是一个开源的无服务器计算平台,专为高性能应用程序而设计,尤其是在数据处理、实时分析和事件驱动架构中。它抽象了基础设施管理的复杂性,使开发人员能够专注于编写和部署函数或微服务。
MinIO:当您将 MLRun 部署到 Kubernetes 集群时,MLRun 使用 MinIO 进行对象存储。我们将把它包含在我们的本地 Docker compose 部署中,因为在后续文章中,我们需要从对象存储中读取用于模型训练的数据集。我们还将在本文中使用它,当我们创建一个简单的冒烟测试笔记本以确保 MLRun 正常运行时。
安装 MLRun 服务
我在这里将展示的安装与 MLRun 安装和设置指南 中所示的略有不同。首先,我想将 MinIO 包含在此安装中,以便我们的无服务器函数可以从对象存储加载数据集。此外,我想为运行 Jupyter Notebook 和 MLRun API 提供单独的服务。(包含 Jupyter 的 MLRun 的 Docker Compose 文件将 MLRun API 和 Jupyter Notebook 服务打包到同一个服务中。)最后,我把重要的环境变量放在一个 .env 文件中,以便不需要手动创建环境变量。下面显示了 MLRun 服务的 Docker Compose 文件和 config.env 文件。您也可以下载它们以及本文的所有代码 此处。
services:
init_nuclio:
image: alpine:3.18
command:
- "/bin/sh"
- "-c"
- |
mkdir -p /etc/nuclio/config/platform; \
cat << EOF | tee /etc/nuclio/config/platform/platform.yaml
runtime:
common:
env:
MLRUN_DBPATH: http://${HOST_IP:?err}:8080
local:
defaultFunctionContainerNetworkName: mlrun
defaultFunctionRestartPolicy:
name: always
maxRetryCount: 0
defaultFunctionVolumes:
- volume:
name: mlrun-stuff
hostPath:
path: ${SHARED_DIR:?err}
volumeMount:
name: mlrun-stuff
mountPath: /home/jovyan/data/
logger:
sinks:
myStdoutLoggerSink:
kind: stdout
system:
- level: debug
sink: myStdoutLoggerSink
functions:
- level: debug
sink: myStdoutLoggerSink
EOF
volumes:
- nuclio-platform-config:/etc/nuclio/config
jupyter:
image: "mlrun/jupyter:${TAG:-1.6.2}"
ports:
#- "8080:8080"
- "8888:8888"
environment:
MLRUN_ARTIFACT_PATH: "/home/jovyan/data/{{project}}"
MLRUN_LOG_LEVEL: DEBUG
MLRUN_NUCLIO_DASHBOARD_URL: http://nuclio:8070
MLRUN_HTTPDB__DSN: "sqlite:////home/jovyan/data/mlrun.db?check_same_thread=false"
MLRUN_UI__URL: https://:8060
# using local storage, meaning files / artifacts are stored locally, so we want to allow access to them
MLRUN_HTTPDB__REAL_PATH: "/home/jovyan/data"
# not running on k8s meaning no need to store secrets
MLRUN_SECRET_STORES__KUBERNETES__AUTO_ADD_PROJECT_SECRETS: "false"
# let mlrun control nuclio resources
MLRUN_HTTPDB__PROJECTS__FOLLOWERS: "nuclio"
volumes:
- "${SHARED_DIR:?err}:/home/jovyan/data"
networks:
- mlrun
mlrun-api:
image: "mlrun/mlrun-api:${TAG:-1.6.2}"
ports:
- "8080:8080"
environment:
MLRUN_ARTIFACT_PATH: "${SHARED_DIR}/{{project}}"
# using local storage, meaning files / artifacts are stored locally, so we want to allow access to them
MLRUN_HTTPDB__REAL_PATH: /data
MLRUN_HTTPDB__DATA_VOLUME: "${SHARED_DIR}"
MLRUN_LOG_LEVEL: DEBUG
MLRUN_NUCLIO_DASHBOARD_URL: http://nuclio:8070
MLRUN_HTTPDB__DSN: "sqlite:////data/mlrun.db?check_same_thread=false"
MLRUN_UI__URL: https://:8060
# not running on k8s meaning no need to store secrets
MLRUN_SECRET_STORES__KUBERNETES__AUTO_ADD_PROJECT_SECRETS: "false"
# let mlrun control nuclio resources
MLRUN_HTTPDB__PROJECTS__FOLLOWERS: "nuclio"
volumes:
- "${SHARED_DIR:?err}:/data"
networks:
- mlrun
mlrun-ui:
image: "mlrun/mlrun-ui:${TAG:-1.6.2}"
ports:
- "8060:8090"
environment:
MLRUN_API_PROXY_URL: http://mlrun-api:8080
MLRUN_NUCLIO_MODE: enable
MLRUN_NUCLIO_API_URL: http://nuclio:8070
MLRUN_NUCLIO_UI_URL: https://:8070
networks:
- mlrun
nuclio:
image: "quay.io/nuclio/dashboard:${NUCLIO_TAG:-stable-amd64}"
ports:
- "8070:8070"
environment:
NUCLIO_DASHBOARD_EXTERNAL_IP_ADDRESSES: "${HOST_IP:?err}"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- nuclio-platform-config:/etc/nuclio/config
depends_on:
- init_nuclio
networks:
- mlrun
minio:
image: quay.io/minio/minio
#network_mode: "host"
volumes:
#- /d/data:/data
#- ./data:/data
- ~/minio-data:/data
ports:
- 9000:9000
- 9001:9001
#extra_hosts:
# - "host.docker.internal:host-gateway"
environment:
MINIO_ROOT_USER: 'minio_user'
MINIO_ROOT_PASSWORD: 'minio_password'
MINIO_ADDRESS: ':9000'
MINIO_STORAGE_USE_HTTPS: False
MINIO_CONSOLE_ADDRESS: ':9001'
#MINIO_LAMBDA_WEBHOOK_ENABLE_function: 'on'
#MINIO_LAMBDA_WEBHOOK_ENDPOINT_function: 'https://:5000'
command: minio server /data
healthcheck:
test: ["CMD", "curl", "-f", "https://:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
networks:
- mlrun
volumes:
nuclio-platform-config: {}
networks:
mlrun:
name: mlrun |
文件名:compose-with-jupyter-minio.yaml
# MLRun 配置
HOST_IP=127.17.0.01
SHARED_DIR=~/mlrun-data |
文件名:config.env
运行下面显示的 docker-compose 命令将启动我们的服务。
docker-compose -f compose-with-jupyter-minio.yaml --env-file config.env up -d |
服务在 Docker 中运行后,导航到以下 URL 以查看 Jupyter、MinIO、MLRun 和 Nuclio 的控制台。
在结束我们在开发机器上设置 MLRun 的练习之前,让我们创建一个并运行一个简单的无服务器函数,以确保一切正常。
运行一个简单的无服务器函数
在本演示中,我们将使用 Jupyter 服务器。它已经安装了 Python mlrun 库。如果您需要其他库,可以启动一个终端选项卡并安装它们。我们将需要 minio Python SDK。下面的屏幕截图显示了如何启动一个终端窗口并安装 minio 库。
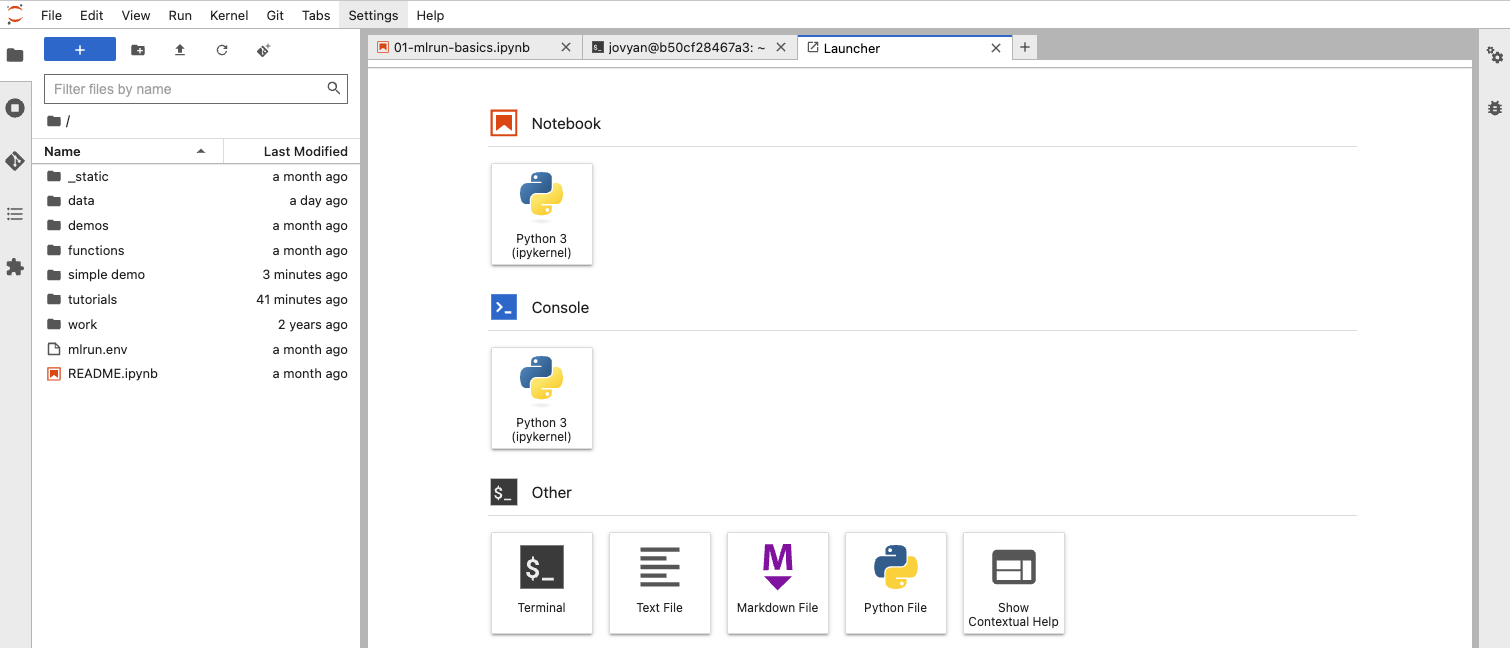
单击“终端”按钮,您将获得一个类似于下面显示的选项卡。
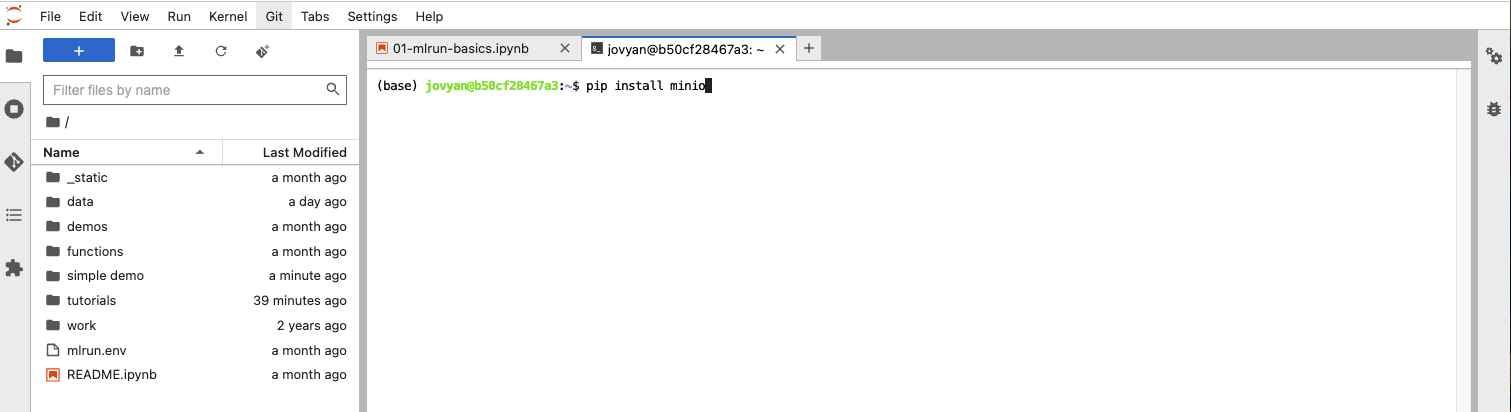
此选项卡的工作原理与 Mac 上的终端应用程序相同。它允许您将任何需要的库安装到 Jupyter 服务中,我们的函数将在其中执行。
安装完库后,创建一个名为“simple demo”的新文件夹并导航到该文件夹。下载本文的示例代码并将以下文件上传到您的新文件夹
- simple_serverless_function.py
- simple_serverless_function_setup.ipynb
- minio.env
- mlrun.env
- minio_utilities.py
我们要发送到 MLRun 的函数位于 simple_serverless_function.py 中,如下所示。函数名称为“train_model”——我们不会在本篇文章中训练实际的模型。我们只想让一个无服务器函数工作。请注意,此函数有一个“mlrun.handler()”装饰器。它包装了函数,使输入和输出能够被解析和保存。此外,它不必是独立的(仅使用其内部定义的资源)——它可以使用模块级别导入的库,而这些库可以是其他代码模块。在我们的例子中,我们有一个位于同一目录中的 minio 实用程序模块。
from typing import Dict
import mlrun
import minio_utilities as mu
@mlrun.handler()
def train_model(data_bucket: str=None, training_parameters: Dict=None):
logger = mu.create_logger()
logger.info(data_bucket)
logger.info(training_parameters)
bucket_list = mu.get_bucket_list()
logger.info(bucket_list) |
文件名: simple_serverless_function.py
从功能上讲,此函数所做的只是记录输入参数,并且为了好玩,我连接到 MinIO 以获取所有存储桶的列表。作为此简单演示的一部分,我想证明 MinIO 的连接性。下面显示了 minio_utilities.py 中的 get_bucket_list() 函数。
import logging
import os
import sys
from typing import Any, Dict, List, Tuple
from dotenv import load_dotenv
from minio import Minio
from minio.error import S3Error
LOGGER_NAME = 'train'
LOGGING_LEVEL = logging.INFO
load_dotenv('minio.env')
MINIO_URL = os.environ['MINIO_URL']
MINIO_ACCESS_KEY = os.environ['MINIO_ACCESS_KEY']
MINIO_SECRET_KEY = os.environ['MINIO_SECRET_KEY']
if os.environ['MINIO_SECURE']=='true': MINIO_SECURE = True
else: MINIO_SECURE = False
def create_logger() -> None:
logger = logging.getLogger(LOGGER_NAME)
#if not logger.hasHandlers():
logger.setLevel(LOGGING_LEVEL)
formatter = logging.Formatter('%(process)s %(asctime)s | %(levelname)s | %(message)s')
stdout_handler = logging.StreamHandler(sys.stdout)
stdout_handler.setLevel(logging.DEBUG)
stdout_handler.setFormatter(formatter)
logger.handlers = []
logger.addHandler(stdout_handler)
return logger
def get_bucket_list() -> List[str]:
logger = create_logger()
# Get data of an object.
try:
# Create client with access and secret key
client = Minio(MINIO_URL, # host.docker.internal
MINIO_ACCESS_KEY,
MINIO_SECRET_KEY,
secure=MINIO_SECURE)
buckets = client.list_buckets()
except S3Error as s3_err:
logger.error(f'S3 Error occurred: {s3_err}.')
raise s3_err
except Exception as err:
logger.error(f'Error occurred: {err}.')
raise err
return buckets |
文件名: minio_utilities.py
下面显示了用于保存 MinIO 连接信息的“minio.env”文件。您需要获取自己的访问密钥和密钥,并将它们放入此文件中。另外,请注意,我使用“minio”作为 MinIO 的主机名。这是因为我们是从与 MinIO 相同的 Docker Compose 网络中的服务进行连接。如果您想从此网络外部连接到此 MinIO 实例,则使用 localhost。
MINIO_URL=minio:9000
MINIO_ACCESS_KEY=lwycuW6S5f7yJZt65tRK
MINIO_SECRET_KEY=d6hXquiXGpbmfR8OdX7Byd716hmhN87xTyCX8S0K
MINIO_SECURE=false |
minio.env 文件
概括来说,我们有一个无服务器函数,它记录传递给它的所有输入参数。它还连接到 MinIO 并获取存储桶列表。现在我们唯一需要做的就是打包我们的函数并将其传递给 MLRun。我们将在 simple_serverless_function_setup.ipynb 笔记本中执行此操作。下面是此笔记本中的单元格。
导入我们需要的库。
下面的单元格使用“mlrun.env”文件通知我们的环境在哪里可以找到 MLRun API 服务。它还将 MLRun 连接到兼容 S3 的对象存储以保存工件。这是我们通过 docker compose 文件创建的 MinIO 实例。
# 设置环境:
mlrun.set_environment(env_file='mlrun.env', artifact_path='s3://mlrun/simple-demo') |
# 远程 MLRun 服务地址
MLRUN_DBPATH=http://mlrun-api:8080
# AWS S3/服务凭证
S3_ENDPOINT_URL=minio:9000
AWS_ACCESS_KEY_ID={请在此处填写 MinIO 访问密钥。}
AWS_SECRET_ACCESS_KEY={请在此处填写 MinIO 密钥。} |
文件名: mlrun.env 文件
接下来,我们创建一个 MLRun 项目。此项目将与我们所有的指标和工件相关联。您在此步骤中使用的项目目录是代码所在的文件夹。
# 创建项目:
project_name='simple-test'
project_dir = os.path.abspath('./')
project = mlrun.get_or_create_project(project_name, project_dir, user_project=False)
print(project_dir) |
set_function() 方法告诉 MLRun 在哪里可以找到您的函数以及您希望如何运行它。handler 参数必须包含使用 mlrun.handler() 装饰器注释的函数的名称。
# 创建无服务器函数。
trainer = project.set_function(
"simple_serverless_function.py", name="trainer", kind="job",
image="mlrun/mlrun",
handler="train_model"
) |
下面单元格创建一些示例模型训练参数。
# 示例超参数
training_parameters = {
'batch_size': 32,
'device': 'cpu',
'dropout_input': 0.2,
'dropout_hidden': 0.5,
'epochs': 5,
'input_size': 784,
'hidden_sizes': [1024, 1024, 1024, 1024],
'lr': 0.025,
'momentum': 0.5,
'output_size': 10,
'smoke_test_size': -1
} |
最后,我们开始运行函数,如下所示。“local”参数告诉MLRun在当前系统上运行函数,在本例中是Jupyter Notebook服务器。如果将其设置为False,则函数将发送到Nuclio。此外,“inputs”参数需要是Dict[str, str]类型;如果使用其他类型,则会报错。
# 运行函数。
trainer_run = project.run_function(
"trainer",
inputs={"data_bucket": "mnist"},
params={"training_parameters": training_parameters},
local=True
) |
在 MLRun UI 中查看结果
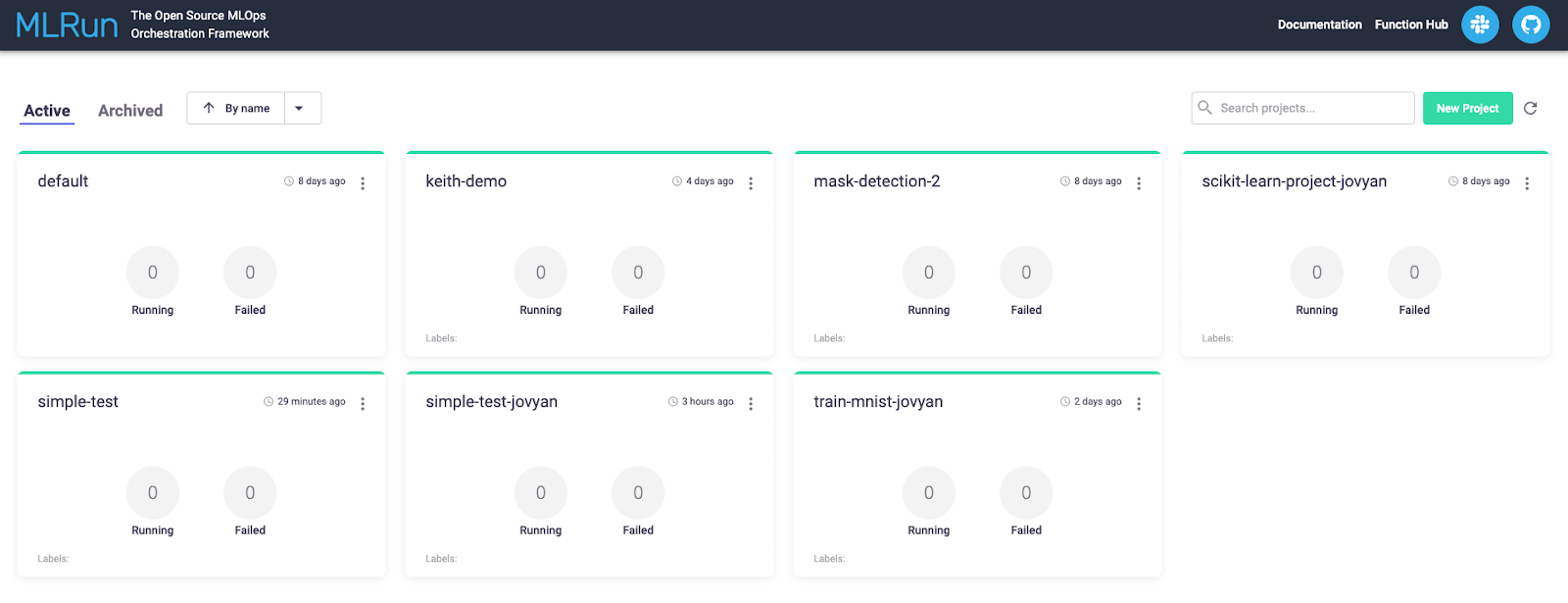
函数完成后,转到 MLRun 主页查找您的项目。点击代表您项目的图块。我们的函数在“简单测试”项目下运行。
下一页将显示您所有运行中与项目相关的所有内容。如下所示。
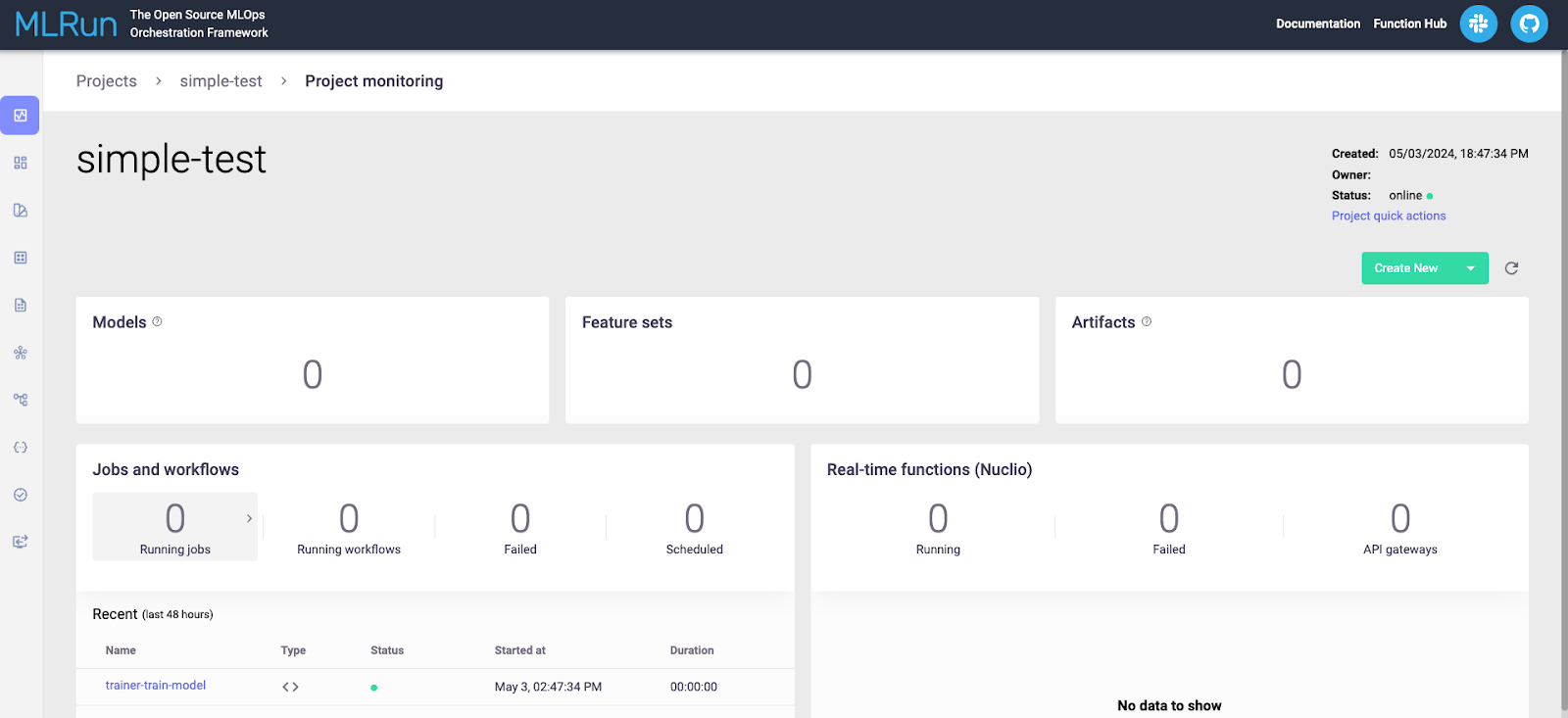
查看“作业和工作流”部分,然后点击您要查看的运行。这将显示有关运行的详细信息,如下所示。
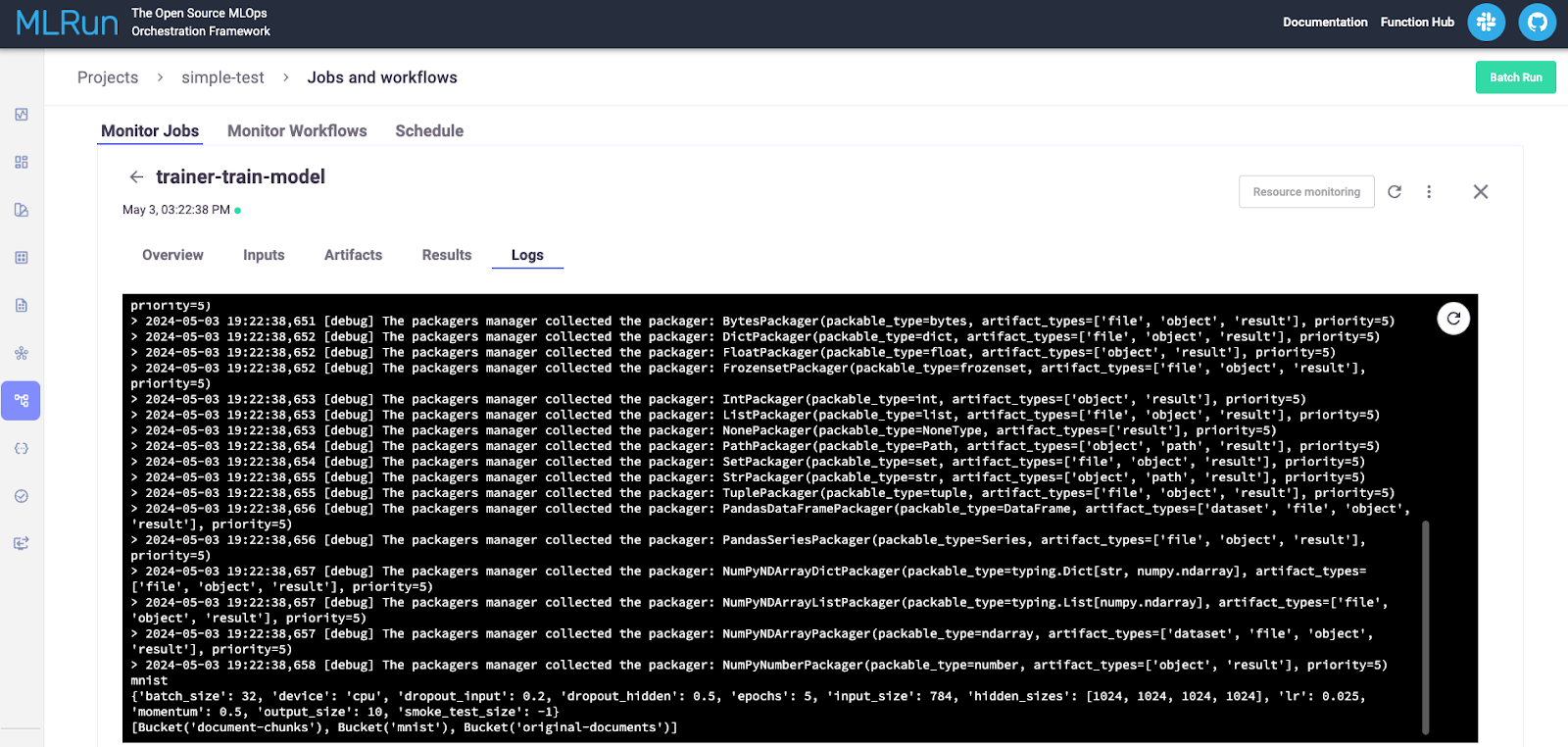
“日志”选项卡对于调试很有用。在这里,我们可以看到我们从简单的函数中记录的消息,这些消息记录了输入参数,连接到 MinIO,然后记录了在 MinIO 中找到的所有存储桶。
总结和后续步骤
在这篇文章中,我们使用 Docker Compose 在开发机器上安装了 MLRun。我们还创建并运行了一个简单的无服务器函数,以了解代码在 MLRun 中运行需要如何构建。我们的代码能够连接到 MinIO 以以编程方式检索存储桶列表。我们还配置了 MLRun 使用 MinIO 进行工件存储。
显然,我们的简单无服务器函数仅仅触及了 MLRun 功能的皮毛。后续步骤包括使用流行框架实际训练模型,使用 MLRun 进行分布式训练,以及探索对大型语言模型的支持。我们将在以后的文章中进行介绍,敬请关注 MinIO 博客。
如果您有任何问题,请务必通过 Slack 与我们联系!
