Apache Kafka 是一个开源的分布式事件流平台,用于构建实时数据管道和流式应用程序。它最初由 LinkedIn 开发,现在由 Apache 软件基金会维护。Kafka 旨在处理高容量、高吞吐量和低延迟的数据流,使其成为构建可扩展和可靠的数据流解决方案的热门选择。
Kafka 的一些优势包括
可扩展性和速度: 处理大规模数据流和每秒数百万个事件,并通过向集群添加更多 Kafka 代理来水平扩展。容错性: 在 Kafka 集群中的多个代理之间复制数据,确保数据高度可用,并在发生故障时可以恢复,使 Kafka 成为关键数据流应用程序的可靠选择。多功能性: 支持各种数据源和数据接收器,使其具有很强的通用性。它可用于构建各种应用程序,例如实时数据处理、数据摄取、数据流和事件驱动的架构。持久性: 所有发布的消息都会存储一段时间(可配置),允许使用者以自己的速度读取数据。这使得 Kafka 适用于需要保留数据以进行历史分析或为了恢复目的而重放数据的情况。请参阅 Apache Kafka 以获取更多信息。
在 Kubernetes(一个广泛使用的容器编排平台)上部署 Kafka 提供了一些额外的优势。Kubernetes 能够根据需求动态扩展 Kafka 集群,从而实现高效的资源利用,并自动扩展 Kafka 代理以处理变化的数据流量。这确保了 Kafka 能够处理不同的工作负载,而不会造成不必要的资源浪费或性能下降。
它提供简单的部署、管理和监控。将 Kafka 集群作为容器运行,可以简化部署、管理和监控,并使其能够在不同的环境中高度可移植。这使得 Kafka 集群能够在各种云提供商、数据中心或开发环境之间无缝迁移。
Kubernetes 包含用于处理故障和确保 Kafka 集群高可用性的内置功能。例如,它会自动重新调度失败的 Kafka 代理容器,并支持在不停机的情况下进行滚动更新,从而确保 Kafka 能够持续为数据流应用程序提供服务,从而增强 Kafka 部署的可靠性和容错性。
Kafka 和 MinIO 通常用于构建数据流解决方案。MinIO 是一个高性能的分布式对象存储系统,旨在支持云原生应用程序,并提供与 S3 兼容的存储,用于非结构化、半结构化和结构化数据。当用作 Kafka 的数据接收器时,MinIO 使组织能够实时存储和处理大量数据。
将 Kafka 与 MinIO 结合使用的一些优势包括
高性能: MinIO 以 Kafka 流入的速度写入 Kafka 流。一项最近的基准测试 在仅使用 32 个现成的 NVMe SSD 节点的 GET 操作中实现了 325 GiB/s(349 GB/s),在 PUT 操作中实现了 165 GiB/s(177 GB/s)。可扩展性: MinIO 处理大量数据并在多个节点上水平扩展,使其非常适合存储 Kafka 生成的数据流。这使组织能够实时存储和处理海量数据,使其适用于大数据和高速数据流用例。持久性: MinIO 提供持久性存储,允许组织长期保留数据,例如用于历史分析、合规性要求或数据恢复目的。容错性: MinIO 纠删码 跨多个节点的数据,提供容错并确保数据持久性。这补充了 Kafka 的容错功能,使整体解决方案高度可用、可靠和弹性。易于集成: 使用 Kafka Connect(一个用于将 Kafka 连接到外部系统的内置框架),可以轻松地将 MinIO 与 Kafka 集成。这使得将数据从 Kafka 流式传输到 MinIO 进行存储变得非常简单,反之亦然,以便检索数据,从而实现 Kafka 和 MinIO 之间无缝的数据流。我们将在下面的教程中了解这有多么简单。在这篇文章中,我们将逐步介绍如何在 Kubernetes 上使用 Strimzi 设置 Kafka。Strimzi 是一个开源项目,提供运算符来在 Kubernetes 上运行 Apache Kafka 和 Apache ZooKeeper 集群,包括 OpenShift 等发行版。然后,我们将使用 Kafka Connect 将数据流式传输到 MinIO。
先决条件 在开始之前,请确保您拥有以下内容:
一个正在运行的 Kubernetes 集群 kubectl 命令行工具 一个正在运行的 MinIO 集群 mc MinIO 命令行工具Helm 包管理器 安装 Strimzi 运算符 第一步是在您的 Kubernetes 集群上安装 Strimzi 运算符。Strimzi 运算符管理 Kubernetes 上 Kafka 和 ZooKeeper 集群的生命周期。
添加 Strimzi Helm 图表存储库
!helm repo add strimzi https: //strimzi.io/charts/ "strimzi" already exists with the same configuration, skipping
使用发布名称 my-release 安装图表
!helm install my-release strimzi/strimzi-kafka-operator --namespace=kafka --create-namespace 名称:my-release 最后部署时间:4月 10 20 : 03 : 12 2023 命名空间:kafka 状态:已部署 修订版本: 1 测试套件:无 注释: 感谢您 安装 Strimzi Kafka 运算符 -0.34.0 要创建 Kafka 集群,请参阅以下文档。 https: //strimzi.io/docs/operators/latest/deploying.html#deploying-cluster-operator-helm-chart-str
这将安装运算符的最新版本(撰写本文时为 0.34.0)到新创建的 kafka 命名空间中。有关其他配置,请参阅此 页面。
创建 Kafka 集群 现在我们已经安装了 Strimzi 运算符,我们可以创建一个 Kafka 集群。在此示例中,我们将创建一个具有三个 Kafka 代理和三个 ZooKeeper 节点的 Kafka 集群。
让我们创建一个 YAML 文件,如下所示此处
%%writefile deployment/kafka-cluster.yaml apiVersion: kafka.strimzi.io/v1beta2 kind: Kafka metadata: name: my-kafka-cluster namespace: kafka spec: kafka: version: 3.4.0 replicas: 3 listeners: - name: plain port: 9092 type : internal tls: false - name: tls port: 9093 type : internal tls: true config: offsets.topic.replication.factor: 3 transaction.state.log.replication.factor: 3 transaction.state.log.min.isr: 2 default .replication.factor: 3 min.insync.replicas: 2 inter.broker.protocol.version: "3.4" storage: type : jbod volumes: - id: 0 type : persistent-claim size: 100 Gi deleteClaim: false zookeeper: replicas: 3 storage: type : persistent-claim size: 100 Gi deleteClaim: false entityOperator: topicOperator: {} userOperator: {} Overwriting deployment/kafka-cluster.yaml
!kubectl apply -f deployment/kafka-cluster.yaml kafka.kafka.strimzi.io/my-kafka-cluster 已创建
!kubectl -n kafka get kafka my-kafka-cluster
NAME DESIRED KAFKA REPLICAS DESIRED ZK REPLICAS READY WARNINGS
my-kafka-cluster 3 3 True 现在我们已经启动并运行了集群,让我们生成和使用示例主题事件,从 kafka 主题 my-topic 开始。
创建 Kafka 主题 为 kafka 主题 my-topic 创建一个 YAML 文件,如下所示并应用它。
%%writefile deployment/kafka-my-topic.yaml apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaTopic metadata: name: my-topic namespace: kafka labels: strimzi.io/cluster: my-kafka-cluster spec: partitions: 3 replicas: 3 覆盖 deployment/kafka-my-topic.yaml !kubectl apply -f deployment/kafka-my-topic.yaml kafkatopic.kafka.strimzi.io/connect-offsets 创建完成
使用以下命令检查主题状态:
!kubectl -n kafka get kafkatopic my-topic 名称 集群 分区数 副本因子 就绪 my-topic my-kafka-cluster 3 3 True
生产和消费消息 Kafka 集群和主题设置完成后,我们就可以开始生产和消费消息了。
要创建一个 Kafka 生产者 Pod 来向 my-topic 主题发送消息,请在终端中尝试以下命令:
kubectl -n kafka run kafka-producer -ti --image=quay.io/strimzi/kafka: 0.34.0 -kafka -3.4.0 --rm= true --restart=Never -- bin/kafka-console-producer.sh --broker-list my-kafka-cluster-kafka-bootstrap: 9092 --topic my-topic
这将提供一个提示,用于向生产者发送消息。同时,我们可以启动消费者,开始消费发送到生产者的消息。
kubectl -n kafka run kafka-consumer -ti --image=quay.io/strimzi/kafka: 0.34.0 -kafka -3.4.0 --rm= true --restart=Never -- bin/kafka-console-consumer.sh --bootstrap-server my-kafka-cluster-kafka-bootstrap: 9092 --topic my-topic --from-beginning
消费者将重放之前发送到生产者的所有消息,并且如果我们向生产者添加任何新消息,它们也将开始显示在消费者端。
您可以使用以下命令删除 my-topic 主题:
!kubectl -n kafka 删除 kafkatopic my-topic kafkatopic.kafka.strimzi.io "my-topic" 已删除
现在 Kafka 集群已经启动并运行,并带有虚拟主题生产者/消费者,我们可以开始使用 Kafka 连接器将主题直接消费到 MinIO 中。
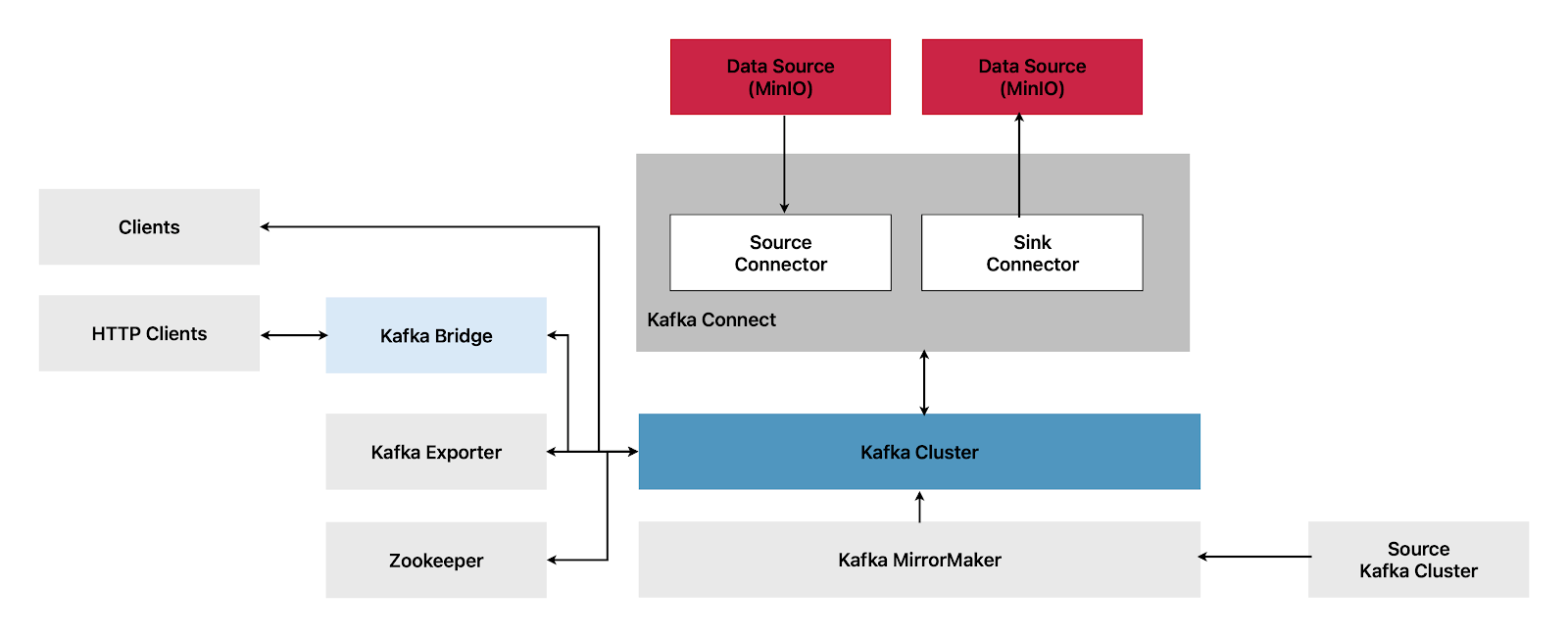
使用 MinIO 设置 Kafka 连接器 接下来,我们将使用 Kafka 连接器将主题直接流式传输到 MinIO。首先,让我们了解一下连接器是什么以及如何设置。以下是不同 Kafka 组件如何交互的高级概述。
Kafka 连接器 Kafka Connect 是一个用于在 Kafka 代理和其它系统之间流式传输数据的集成工具包。另一个系统通常是外部数据源或目标,例如 MinIO。
Kafka Connect 利用插件架构为连接器提供实现工件,这些连接器用于连接到外部系统和操作数据。插件由连接器、数据转换器和转换组成。连接器旨在与特定的外部系统一起使用,并为其配置定义架构。在配置 Kafka Connect 时,您配置连接器实例,然后连接器实例为系统之间的数据移动定义一组任务。
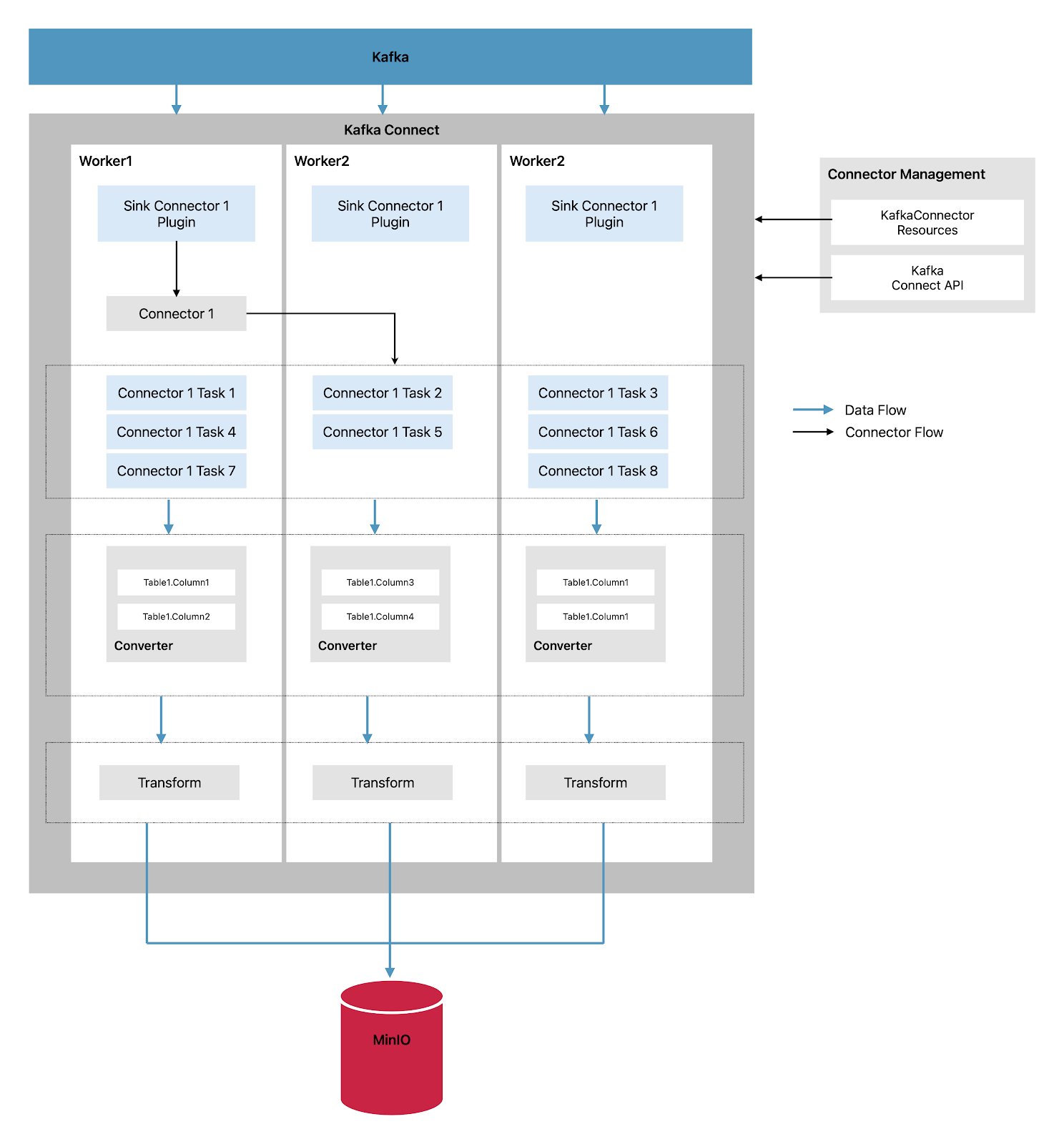
在分布式操作模式下,Strimzi 通过在一个或多个工作 Pod 中分发数据流式传输任务来操作 Kafka Connect。Kafka Connect 集群由一组工作 Pod 组成,每个连接器在一个工作 Pod 上实例化。每个连接器可以有一个或多个任务,这些任务分布在工作 Pod 组中,从而实现高度可扩展的数据管道。
Kafka Connect 中的 Worker 负责将数据从一种格式转换为另一种格式,使其适用于源系统或目标系统。根据连接器实例的配置,Worker 还可以应用转换,也称为 单消息转换 (Single Message Transforms,SMT) ,它可以在数据转换前调整消息,例如过滤某些数据。Kafka Connect 自带了一些内置转换,但也可以根据需要通过插件提供额外的转换。
Kafka Connect 在流式传输数据时使用以下组件
连接器 (Connectors) - 创建任务 任务 (Tasks) - 移动数据 Worker - 运行任务 转换器 (Transformers) - 操作数据 转换器 (Converters) - 转换数据 连接器有两种类型
源连接器 (Source Connectors) - 将数据推送到 Kafka 接收连接器 (Sink Connectors) - 从 Kafka 中提取数据到外部源,例如 MinIO 下面我们将配置一个接收连接器,它从 Kafka 中提取数据并将其存储到 MinIO 中,如下所示
接收连接器从 Kafka 流式传输数据并经历以下步骤
插件提供了接收连接器的实现工件:在 Kafka Connect 中,接收连接器用于将数据从 Kafka 流式传输到外部系统。接收连接器的实现工件,例如代码和配置,由插件提供。插件用于扩展 Kafka Connect 的功能,并启用与不同外部数据系统的连接。 单个 Worker 启动接收连接器实例:在分布式操作模式下,Kafka Connect 作为 Worker Pod 的集群运行。每个 Worker Pod 都可以启动一个接收连接器实例,该实例负责将数据从 Kafka 流式传输到外部数据系统。Worker 管理接收连接器实例的生命周期,包括其初始化和配置。 接收连接器创建任务来流式传输数据:一旦接收连接器实例启动,它就会创建一个或多个任务来将数据从 Kafka 流式传输到外部数据系统。每个任务负责处理一部分数据,并且可以与其他任务并行运行以实现高效的数据处理。 任务并行运行以轮询 Kafka 并返回记录:任务从 Kafka 主题中检索记录,并准备将其转发到外部数据系统。任务的并行处理能够实现高吞吐量和高效的数据流式传输。 转换器将记录转换为适合外部数据系统的格式:在将记录转发到外部数据系统之前,转换器用于将记录转换为适合外部数据系统特定要求的格式。转换器处理数据格式转换,例如从 Kafka 的二进制格式转换为外部数据系统支持的格式。 转换调整记录,例如过滤或重新标记它们:根据接收连接器的配置,可以在将记录转发到外部数据系统之前应用转换(单消息转换,SMT)来调整记录。转换可用于过滤、重新标记或丰富要发送到外部系统的数据等任务。 接收连接器使用 KafkaConnectors 或 Kafka Connect API 进行管理:接收连接器及其任务可以使用 KafkaConnectors 或 Kafka Connect API 进行管理,Kafka Connect API 提供了用于管理 Kafka Connect 的编程访问。这使得在 Kafka Connect 部署中轻松配置、监视和管理接收连接器及其任务成为可能。 设置 我们将创建一个简单的示例,它将执行以下步骤
创建一个生产者,它将从 MinIO 流式传输数据并为某个主题生成 JSON 格式的事件。 构建一个包含 S3 依赖项的 Kafka Connect 镜像。 基于上述镜像部署 Kafka Connect。 部署 Kafka 接收连接器,它消费 Kafka 主题并将数据存储到 MinIO 存储桶中。 将演示数据导入 MinIO 我们将使用 MinIO 上可用的 NYC Taxi 数据集。如果您没有该数据集,请按照 此处的 说明操作。
生产者 以下是一个简单的 Python 代码,它从 MinIO 中消费数据并为主题 my-topic 生成事件。
%%writefile sample-code/producer/src/producer.py import logging import os import fsspec import pandas as pd import s3fs from kafka import KafkaProducer logging.basicConfig(level=logging.INFO) producer = KafkaProducer(bootstrap_servers= "my-kafka-cluster-kafka-bootstrap:9092" ) fsspec.config.conf = { "s3" : { "key" : os.getenv( "AWS_ACCESS_KEY_ID" , "openlakeuser" ), "secret" : os.getenv( "AWS_SECRET_ACCESS_KEY" , "openlakeuser" ), "client_kwargs" : { "endpoint_url" : "https://play.min.io:50000" } } } s3 = s3fs.S3FileSystem() total_processed = 0 i = 1 for df in pd.read_csv( 's3a://openlake/spark/sample-data/taxi-data.csv' , chunksize= 1000 ): count = 0 for index, row in df.iterrows(): producer.send( "my-topic" , bytes(row.to_json(), 'utf-8' )) count += 1 producer.flush() total_processed += count if total_processed % 10000 * i == 0 : logging.info(f "total processed till now {total_processed}" ) i += 1
覆盖 sample-code/src/producer.py
添加基于其构建 Docker 镜像的要求和 Dockerfile。
%%writefile sample-code/producer/requirements.txt pandas== 2.0.0 s3fs== 2023.4.0 pyarrow== 11.0.0 kafka-python== 2.0.2
覆盖 sample-code/producer/requirements.txt
In [ 14 ]: %%writefile sample-code/producer/Dockerfile FROM python: 3.11 -slim ENV PYTHONDONTWRITEBYTECODE= 1 COPY requirements.txt . RUN pip3 install -r requirements.txt COPY src/producer.py . CMD [ "python3" , "-u" , "./producer.py" ]
覆盖 sample-code/Dockerfile
使用上面的 Dockerfile 构建并推送生产者的 Docker 镜像,或者您可以使用 openlake 中提供的镜像 openlake/kafka-demo-producer 。
让我们创建一个 YAML 文件,它将我们的生产者作为作业部署到 Kubernetes 集群中。
%%writefile deployment/producer.yaml apiVersion: batch/v1 kind: Job metadata: name: producer-job namespace: kafka spec: template: metadata: name: producer-job spec: containers: - name: producer-job image: openlake/kafka-demo-producer:latest restartPolicy: Never
正在写入 deployment/producer.yaml
部署 producer.yaml 文件
在 [ 84 ]: !kubectl apply -f deployment/producer.yaml job.batch/producer-job 创建成功
使用以下命令检查日志
In [ 24 ]: !kubectl logs -f job.batch/producer-job -n kafka # stop this shell once you are done <jemalloc>: MADV_DONTNEED does not work (memset will be used instead) <jemalloc>: (This is the expected behaviour if you are running under QEMU) INFO:kafka.conn:<BrokerConnection node_id=bootstrap -0 host=my-kafka-cluster-kafka-bootstrap: 9092 <connecting> [IPv4 ( '10.96.4.95' , 9092 )]>: connecting to my-kafka-cluster-kafka-bootstrap: 9092 [( '10.96.4.95' , 9092 ) IPv4] INFO:kafka.conn:Probing node bootstrap -0 broker version INFO:kafka.conn:<BrokerConnection node_id=bootstrap -0 host=my-kafka-cluster-kafka-bootstrap: 9092 <connecting> [IPv4 ( '10.96.4.95' , 9092 )]>: Connection complete. INFO:kafka.conn:Broker version identified as 2.5.0 INFO:kafka.conn:Set configuration api_version=( 2 , 5 , 0 ) to skip auto check_version requests on startup INFO:kafka.conn:<BrokerConnection node_id= 0 host=my-kafka-cluster-kafka -0. my-kafka-cluster-kafka-brokers.kafka.svc: 9092 <connecting> [IPv4 ( '10.244.1.4' , 9092 )]>: connecting to my-kafka-cluster-kafka -0. my-kafka-cluster-kafka-brokers.kafka.svc: 9092 [( '10.244.1.4' , 9092 ) IPv4] INFO:kafka.conn:<BrokerConnection node_id= 0 host=my-kafka-cluster-kafka -0. my-kafka-cluster-kafka-brokers.kafka.svc: 9092 <connecting> [IPv4 ( '10.244.1.4' , 9092 )]>: Connection complete. INFO:kafka.conn:<BrokerConnection node_id=bootstrap -0 host=my-kafka-cluster-kafka-bootstrap: 9092 <connected> [IPv4 ( '10.96.4.95' , 9092 )]>: Closing connection. INFO:root:total processed till now 10000 rpc error: code = NotFound desc = an error occurred when try to find container "85acfb121b7b63bf0f46d9ef89aed9b05666b3fb86b4a835e9d2ebf67c6943f9" : not found
现在我们已经有了基本的生产者将 JSON 事件发送到 my-topic,接下来让我们部署 Kafka Connect 和相应的连接器,用于将这些事件存储到 MinIO 中。
构建 Kafka Connect 镜像 让我们构建一个包含 S3 依赖项的 Kafka Connect 镜像
%%writefile sample-code/connect/Dockerfile FROM confluentinc/cp-kafka-connect: 7.0.9 as cp RUN confluent-hub install --no-prompt confluentinc/kafka-connect-s3: 10.4.2 RUN confluent-hub install --no-prompt confluentinc/kafka-connect-avro-converter: 7.3.3 FROM quay.io/strimzi/kafka: 0.34.0 -kafka -3.4.0 USER root:root # 添加 S3 依赖项 COPY --from=cp /usr/share/confluent-hub-components/confluentinc-kafka-connect-s3/ /opt/kafka/plugins/kafka-connect-s3/
正在覆盖 sample-code/connect/Dockerfile
使用以上 Dockerfile 构建并推送生产者的 Docker 镜像,或者可以使用 openlake 中提供的镜像 openlake/kafka-connect:0.34.0
在部署 Kafka Connect 之前,我们需要创建存储主题(如果不存在),以确保 Kafka Connect 按预期工作。
创建存储主题 让我们创建 connect-status、connect-configs 和 connect-offsets 主题,并按照以下步骤部署它们
%%writefile deployment/connect-status-topic.yaml apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaTopic metadata: name: connect-status namespace: kafka labels: strimzi.io/cluster: my-kafka-cluster spec: partitions: 1 replicas: 3 config: cleanup.policy: compact
正在写入 deployment/connect-status-topic.yaml
在 [ 73 ]: %%writefile deployment/connect-configs-topic.yaml apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaTopic metadata: name: connect-configs namespace: kafka labels: strimzi.io/cluster: my-kafka-cluster spec: partitions: 1 replicas: 3 config: cleanup.policy: compact
正在写入 deployment/connect-configs-topic.yaml
In [ 74 ]: %%writefile deployment/connect-offsets-topic.yaml apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaTopic metadata: name: connect-offsets namespace: kafka labels: strimzi.io/cluster: my-kafka-cluster spec: partitions: 1 replicas: 3 config: cleanup.policy: compact
正在写入 deployment/connect-offsets-topic.yaml
部署以上主题
In [ ]: !kubectl apply -f deployment/connect-status-topic.yaml !kubectl apply -f deployment/connect-configs-topic.yaml !kubectl apply -f deployment/connect-offsets-topic.yaml
部署 Kafka Connect 接下来,创建一个用于 Kafka Connect 的 YAML 文件,该文件使用以上镜像并在 Kubernetes 中部署它。Kafka Connect 将拥有 1 个副本,并使用我们上面创建的存储主题。
注意:spec.template.connectContainer.env 中定义了凭据,以便 Kafka Connect 将数据存储在 Minio 集群中。其他详细信息(如 endpoint_url、bucket_name)将作为 KafkaConnector 的一部分。
In [ 75 ]: %%writefile deployment/connect.yaml apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnect metadata: name: connect-cluster namespace: kafka annotations: strimzi.io/use-connector-resources: "true" spec: image: openlake/kafka-connect: 0.34.0 version: 3.4.0 replicas: 1 bootstrapServers: my-kafka-cluster-kafka-bootstrap: 9093 tls: trustedCertificates: - secretName: my-kafka-cluster-cluster-ca-cert certificate: ca.crt config: bootstrap.servers: my-kafka-cluster-kafka-bootstrap: 9092 group.id: connect-cluster key.converter: org.apache.kafka.connect.json.JsonConverter value.converter: org.apache.kafka.connect.json.JsonConverter internal.key.converter: org.apache.kafka.connect.json.JsonConverter internal.value.converter: org.apache.kafka.connect.json.JsonConverter key.converter.schemas.enable: false value.converter.schemas.enable: false offset.storage.topic: connect-offsets offset.storage.replication.factor: 1 config.storage.topic: connect-configs config.storage.replication.factor: 1 status.storage.topic: connect-status status.storage.replication.factor: 1 offset.flush.interval.ms: 10000 plugin.path: /opt/kafka/plugins offset.storage.file.filename: /tmp/connect.offsets template: connectContainer: env: - name: AWS_ACCESS_KEY_ID value: "openlakeuser" - name: AWS_SECRET_ACCESS_KEY value: "openlakeuser"
正在写入 deployment/connect.yaml
In [ 87 ]: !kubectl apply -f deployment/connect.yaml kafkaconnect.kafka.strimzi.io/connect-cluster 已创建
部署 Kafka Sink Connector 现在 Kafka Connect 已经启动并运行,下一步是部署 Sink Connector,它将轮询 my-topic 并将数据存储到 MinIO 存储桶 openlake-tmp 中。
connector.class - 指定 Sink Connector 将使用哪种类型的连接器,在本例中为 io.confluent.connect.s3.S3SinkConnector
store.url - 您希望将 Kafka Connect 数据存储到的 MinIO 端点 URL
storage.class - 指定要使用的存储类,在本例中,我们存储在 MinIO 中,因此将使用 io.confluent.connect.s3.storage.S3Storage
format.class - 在 MinIO 中存储数据的格式类型,由于我们希望存储 JSON,因此将使用 io.confluent.connect.s3.format.json.JsonFormat
在 [ 90 ]: %%writefile deployment/connector.yaml apiVersion: kafka.strimzi.io/v1beta2 kind: KafkaConnector metadata: name: "minio-connector" namespace: "kafka" labels: strimzi.io/cluster: connect-cluster spec: class: io.confluent.connect.s3.S3SinkConnector config: connector.class: io.confluent.connect.s3.S3SinkConnector task.max: '1' topics: my-topic s3.region: us-east -1 s3.bucket.name: openlake-tmp s3.part.size: '5242880' flush.size: '1000' store.url: https: //play.min.io:50000 storage.class: io.confluent.connect.s3.storage.S3Storage format.class: io.confluent.connect.s3.format.json.JsonFormat partitioner.class: io.confluent.connect.storage.partitioner.DefaultPartitioner behavior.on.null.values: ignore
覆盖 deployment/connector.yaml 文件
在 [ 89 ]: !kubectl apply -f deployment/connector.yaml kafkaconnector.kafka.strimzi.io/minio-connector 已创建
我们可以通过以下方式查看文件是否已添加到 Minio 的 openlake-tmp 桶中:
在 [ 79 ]: !mc ls --summarize --recursive play/openlake-tmp/topics/my-topic ] 11 ;?\[ 2023-04-11 19 : 53 : 29 PDT] 368 KiB STANDARD partition= 0 /my-topic+ 0 + 0000000000. json [ 2023-04-11 19 : 53 : 30 PDT] 368 KiB STANDARD partition= 0 /my-topic+ 0 + 0000001000. json
[...截断…]
[ 2023-04-11 19 : 54 : 07 PDT] 368 KiB STANDARD partition= 0 /my-topic+ 0 + 0000112000. json [ 2023-04-11 19 : 54 : 08 PDT] 368 KiB STANDARD partition= 0 /my-topic+ 0 + 0000113000. json [ 2023-04-11 19 : 54 : 08 PDT] 368 KiB STANDARD partition= 0 /my-topic+ 0 + 0000114000. json 总大小: 41 MiB 对象总数: 115
我们创建了一个端到端的实现,用于在 Kafka 中生成主题并使用 Kafka 连接器将其直接消费到 MinIO 中。这是一个学习如何将 MinIO 和 Kafka 结合使用以构建流数据存储库的绝佳起点。但是,等等,还有更多。
在我的下一篇文章中,我将解释并向您展示如何利用本教程并将其转变为更高效、更高性能的内容。
使用 Kafka 和 MinIO 实现流式传输成功 这篇博文向您展示了如何开始构建流式数据湖。当然,在从这个起点到生产环境的过程中,还涉及许多其他步骤。
MinIO 是云原生对象存储,为 ML/AI 、分析 、流媒体视频 以及在 Kubernetes 中运行的其他要求苛刻的工作负载奠定了基础。MinIO 可以无缝扩展 ,确保您可以轻松扩展存储以适应不断增长的数据湖。
客户经常使用 MinIO 构建数据湖,并将其公开给各种云原生应用程序,用于商业智能、仪表板和其他分析。他们使用 Apache Iceberg 、Apache Hudi 和 Delta Lake 构建数据湖。他们使用 Snowflake 、SQL Server 或各种数据库将保存在 MinIO 中的数据作为外部表读取。他们使用 Dremio 、Apache Druid 和 Clickhouse 进行分析,以及 Kubeflow 和 Tensorflow 用于 ML。
MinIO 甚至可以 复制 跨云的数据以利用特定的应用程序和框架,同时它使用 访问控制 、版本控制 、加密 和 擦除编码 进行保护。
不过,不要相信我们的一面之词——自己动手试试。您可以 下载 MinIO ,并加入我们的 Slack 频道 。